
你以为CPU请求只是用来调度的吗? 再想一想。 引入 CPU 份额,并为消除限制奠定基础!


了解 CPU 请求
在上一篇文章中,我谈到了 Kubernetes 资源管理的基础。 在这篇文章中,我们将深入探讨当我们将 CPU 请求配置到 pod 的容器时幕后发生的事情。
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m" # For the last time!资源请求首先用于调度决策,但 CPU 请求还有其他用途吗?
当您在 Pod 的清单中将 X 数量的 vCPU 配置为容器 CPU 请求时,Kubernetes 会为您的容器配置 (1024 * X) CPU 份额。
例如,如果我为我的 CPU 请求配置 250m,Kubernetes 将设置 1024 * 250m = 256 个 CPU 份额。
那么什么是 CPU 份额,它们有什么作用?
了解CPU shares,先说说Kernel的机制,叫做CFS(Completely Fair Scheduler)。
CFS — Completely Fair Scheduler
CFS 是默认的 Linux CPU 调度程序,负责在进程之间公平分配 CPU 时间。
“完全公平”部分并不像听起来那么简单,它使用一些参数来决定每个进程的相对权重(优先级)是多少。 你们中的许多人可能熟悉可以为进程设置的“nice”设置以更改其相对权重。 但目前,Kubernetes 并没有使用 nice 来影响进程的权重,而是为一个 CGroup 配置 CPU 份额。
因此,CPU 份额是 Linux CGroup 的一项功能,旨在为 CFS 确定 CGroup 进程的优先级,以便在拥塞时将更多的 CPU 时间分配给优先级更高的进程。
让我们将单个 CPU 时间范围(例如 1 秒)想象成一个披萨。 每一秒都有一个新的比萨从烤箱里出来,进程从中吃掉他们需要的东西,然后它就消失了。 如果我所有的进程都没有饿到在 1 秒内吃掉所有的披萨,它们就会吃饱直到时间结束,一个新的 CPU-second-pizza 会从烤箱里出来。


当我们的进程很饿并且每秒 1 个披萨不足以养活它们时,并发症就开始了。

当我的所有进程没有足够的 CPU 时间(或披萨)时,CFS 将查看每个 CGroup 拥有的份额,将披萨切成一定份额,并相应地进行拆分。
如果 CGroup 中的许多进程需要的 CPU 多于可用的 CPU,则每个 CGroup 收到的切片将在该 CGroup 中的进程之间平均分配。
因此,例如,如果 5 个 CGroup 中的进程正在请求尽可能多的 CPU,并且每个 CGroup 具有相同数量的 CPU 份额,那么 CPU 时间将在 CGroup 之间平均分配。

另一个例子是(保持所有进程都在请求尽可能多的CPU的状态); 如果我有 3 个 CGroup,每个 CGroup 有 1024 个 CPU 份额,另一个 CGroup 有 3072 个份额,前 3 个 CGroup 将获得 CPU 的 1/6,最后一个 CGroup 将获得一半(3/6)

请记住,所有这一切仅在我缺少 CPU 时才有意义,如果我有 3 个 CGroups,具有 X CPU 份额,需要大量 CPU,而第四个 CGroup 具有 1000X CPU 份额,处于空闲状态,前 3 个 CGroup 将平分 CPU。

我的容器甚至可以在 Kubernetes 上拥有 1,048,576 个 CPU 份额吗? 前提是我的节点有超过 1024 个 CPU 内核,例如 Epiphany-V,但我敢肯定我们大多数人都没有那种节点。
Kubernetes 如何使用这些特性
正如我所说,Kubernetes CPU 请求为我们的容器 CGroups 配置 CPU 份额,
Kubernetes 魔法阻止了共享“过度承诺”; 一方面,调度程序仅在每个节点上调度 CPU 请求总量,使其低于或等于节点上的 CPU 数量。 另一方面,您提供的 CPU 份额最高可达内核数的 1024 倍。 这为 pod 可以使用的最大份额数设置了上限,并且比率保持不变。
您的容器在 Kubernetes 上可以拥有的 CPU 份额总和是集群中可分配 CPU 数量的 1024 倍。
现实生活中的例子
我试图让前面的例子尽可能简单,所以我删除了一些重要的参数,例如:
- 每个 CGroup 中的线程和进程数
- 节点消耗的 CPU(除了正在运行的 Pod)
尽管您可能这么认为,但还有一些其他参数不会生效。 例如:
- 服务质量 (QoS)
- Pod 优先级
- 驱逐
让我们深入了解一下;
线程数
当我们在容器中只运行一个进程时,如果该进程只创建一个线程,它无论如何也不会消耗超过一个核心。 当您为容器设置 CPU 请求时,请始终牢记它们将运行的线程数。
旁注——线程不是免费的,尽量不要使用太多线程,因为每个线程都有自己的开销,而是增加副本的数量。
节点负载
前面的条形图是针对孤立的流程,但并非所有流程都是孤立的。 不用担心! 您的容器的 CGroups 在 CGroups 层次结构中非常低。
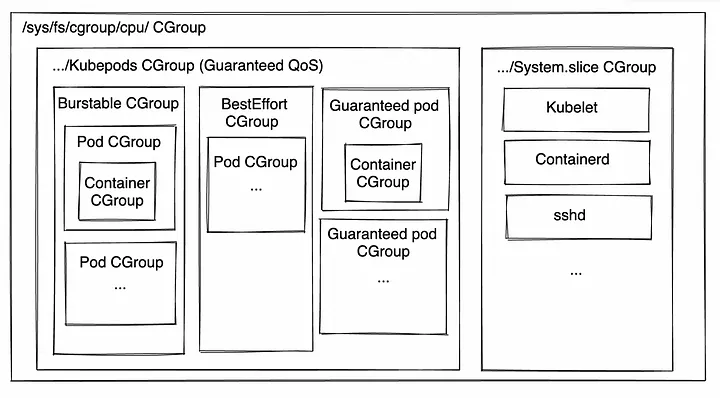
也许在阅读时你已经去检查你的 Kubelet 有多少 CPU 份额以确保它没有被剥夺。 别担心,您的 pod 和容器只是共享“kubepods”CGroup 符合条件的 CPU 时间。 如果节点上的 Kubelet、容器运行时或其他服务需要 CPU 时间,它们将获得它。
设置高 CPU 请求时不要担心,节点的组件开箱即用。
服务质量
Kubernetes 正在根据 QoS 配置 CGroups,目前,它们没有真正的功能,它们的存在是为了将来使用。
就 CPU 时间和优先级而言,CPU 请求是唯一重要的事情。
那么不设置CPU Requests会怎么样呢? 默认情况下,容器将获得 2 个 CPU 份额,并且与配置了 CPU 请求的 Pod 相比,其优先级非常低。
可突发 Pod 和 Best-Effort Pod 的 CPU 时间分配是相同的。 保证将有另一个影响 CPU 时间的参数。 更多内容在下一部分。
底线是 QoS 不会直接影响 pod 的容器将接收的 CPU 时间。 唯一重要的是 CPU 份额(以及限制,如果你仍然使用它们)。
Pod 优先级
“没关系,我设置了 pod 优先级。” — 对不起,但不完全是……
Pod 优先级仅用于确定节点退出的终止顺序,正如我们已经提到的; 没有因 CPU 压力导致的驱逐。
驱逐
驱逐是在节点上运行的一个进程,当节点资源不足时,它会选择并杀死 pod。 逐出只发生在不可压缩的资源,如内存、磁盘空间等。更多在第四部分。
不只是为了调度
我们了解到,CPU 请求不仅用于调度目的,还用于容器的生命周期。 内存请求也有它们的深层,更多内容在第四部分。
此外,我们只讨论了正常的 Kubernetes 行为,还有许多其他选项,例如为每个容器设置独占 CPU 核心的 CPU 固定。 这超出了本文的范围,但我们将来可能会涉及 😄
总结
我们了解到 CPU 请求不仅用于调度,而且在整个容器生命周期中占据很大一部分! 我们了解了设置正确请求以便为每个容器配置正确数量的 CPU 份额的重要性,以及为什么 QoS 等配置不会真正影响我们的工作负载。
记住! CPU 请求配置在容器的整个生命周期内保证有多少 CPU 可用!
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/14203/