
Flink SQL Gateway是一项允许多个客户端从远程并发执行 SQL 的服务。 它提供了一种简单的方法来提交 Flink 作业、查找元数据并在线分析数据。在Flink 1.16版本,官方即将SQL Gateway其合入Flink主线。可正式通过Flink官方包安装与启动Flink SQL Gateway。本为以Flink 1.17版本为例,介绍一种在K8s中启动Flink SQL Gateway,并连接到通过Flink kubernetes operator启动的Flink Session集群上。
当然,在开始一切之前,你需要一些必要的环境:
- 一个K8s集群
- K8s集群安装有kubectl、helm3工具
- k8s集群可以访问docker hub/有一个自建docker仓库,可以将必要的镜像推送到此仓库
基于上述环境,接下来将从如下方面讲述本文内容:
- 部署Flink Kubernetes Operator
- 使用Flink Kubernetes Operator部署Flink session集群
- 使用Flink镜像部署Flink SQL Gateway Deployment,并连接到Flink session集群
- Flink SQL Gateway基本使用
部署Flink Kubernetes Operator
详细资料可参考:https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-release-1.5/,下面简要介绍相关部署步骤:
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.5.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator --set webhook.create=false
查看相关pod以及helm项目可以看到部署成功:



部署Flink Session集群
基于Flink Kubernetes Operator,要部署Flink Session集群还是相对简单的,根据官网介绍,只是不用定义job即可:

下面是一个创建Flink Session集群的例子:
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: default
name: basic-example
spec:
image: flink:1.17
flinkVersion: v1_17
mode: standalone
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink-service-account
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "2048m"
cpu: 1将上述文件保存为flink-sessioncluster.yaml,执行如下命令开始创建:
kubectl apply -f flink-sessioncluster.yaml创建完,即可得到flink session集群:

可以看到该集群的headless service为:basic-example-rest,通过连接至该service的8081端口即可连接到该Flink session集群。
创建Flink SQL Gateway Deployment
有了上述Flink Session集群的连接端口,那么即可通过如下描述文件启动Flink SQL Gateway Deployment
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
jkube.io/scm-tag: HEAD
jkube.io/git-branch: master
labels:
app: flink-sql-gateway
provider: jkube
version: 0.0.1
group: com.iwhalecloud.wdp
name: flink-sql-gateway
spec:
replicas: 1
revisionHistoryLimit: 1
selector:
matchLabels:
app: flink-sql-gateway
provider: jkube
group: com.zh.ch.bigdata
template:
metadata:
annotations:
jkube.io/scm-tag: HEAD
jkube.io/git-branch: master
labels:
app: flink-sql-gateway
provider: jkube
version: 0.0.1
group: com.zh.ch.bigdata
spec:
containers:
- name: flink-sql-gateway
env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: HOSTNAME
valueFrom:
fieldRef:
fieldPath: metadata.name
image: flink:1.17
command:
- /bin/bash
- -c
args:
- /opt/flink/bin/sql-gateway.sh start-foreground -Drest.address=basic-example-rest -Dsql-gateway.endpoint.rest.address=localhost
imagePullPolicy: Always
ports:
- containerPort: 8083
name: http-1
protocol: TCP
securityContext:
privileged: false将上述文件保存为flink-sql-gateway-deployment.yaml,执行如下命令启动
kubectl apply -f flink-sql-gateway-deployment.yaml得到:

查看日志:

现在创建一个NodePort,将该Deployment的8083端口映射到主机端口:
apiVersion: v1
kind: Service
metadata:
labels:
expose: "true"
app: flink-sql-gateway
name: flink-sql-gateway
namespace: default
spec:
type: NodePort
ports:
- name: http1
port: 8083
protocol: TCP
nodePort: 30083
selector:
app: flink-sql-gateway将如上内容保存为flink-sql-gateway-service.yaml,执行如下命令创建
kubectl apply -f flink-sql-gateway-service.yaml得到:

Flink SQL Gateway基本使用
接下来便可通过30083主机端口连接到Flink SQL Gateway,以下是使用Postman的例子:
-
获取Flink版本信息

- 打开一个Session
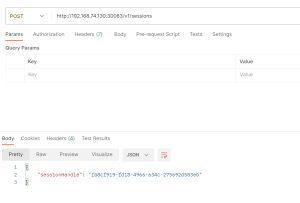
-
记下上述sessionHandle并添加到查询SQL的URL中,如下所示,该SQL为"SELECT 1":

查看flink sql gateway日志:

查看Flink session集群日志:

-
记下上述operationHandle,还可以查询上述SQL的执行结果:

当然,上面只是一个简单的示例,更多Flink SQL Gateway的用法可参考官网:https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sql-gateway/overview/
与此同时,还可以将Flink SQL Gateway Deployment封装为Helm项目,简化部署。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/14314/