
摘要:本文整理自 Apache Flink PMC 李劲松(之信)在 9 月 24 日 Apache Flink Meetup 的分享。主要内容包括:
-
介绍 Flink Table Store
-
应用场景
-
Demo
-
后续挑战
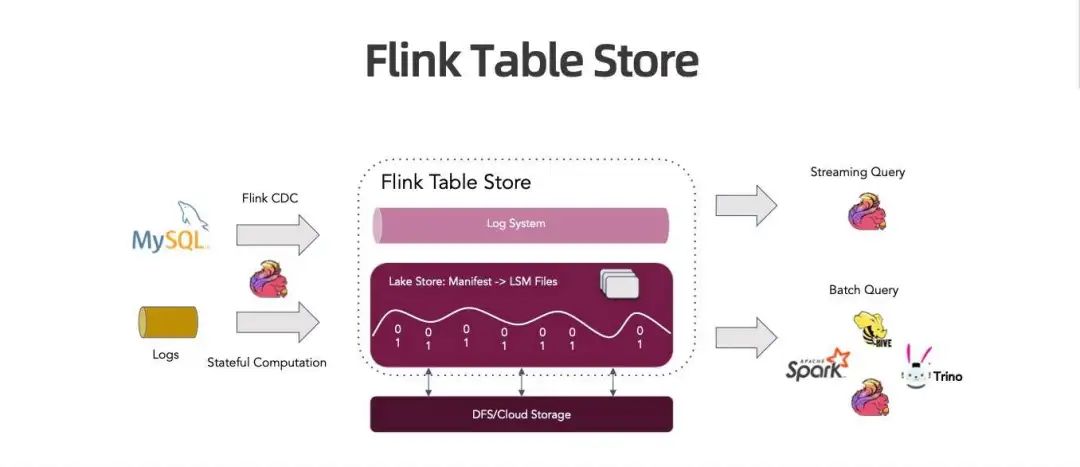
介绍 Flink Table Store
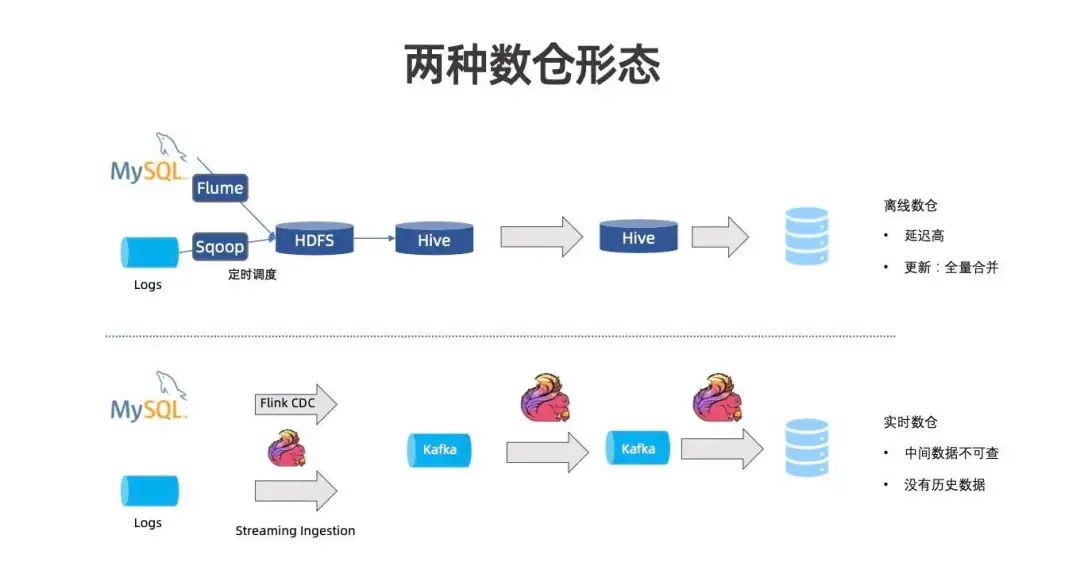

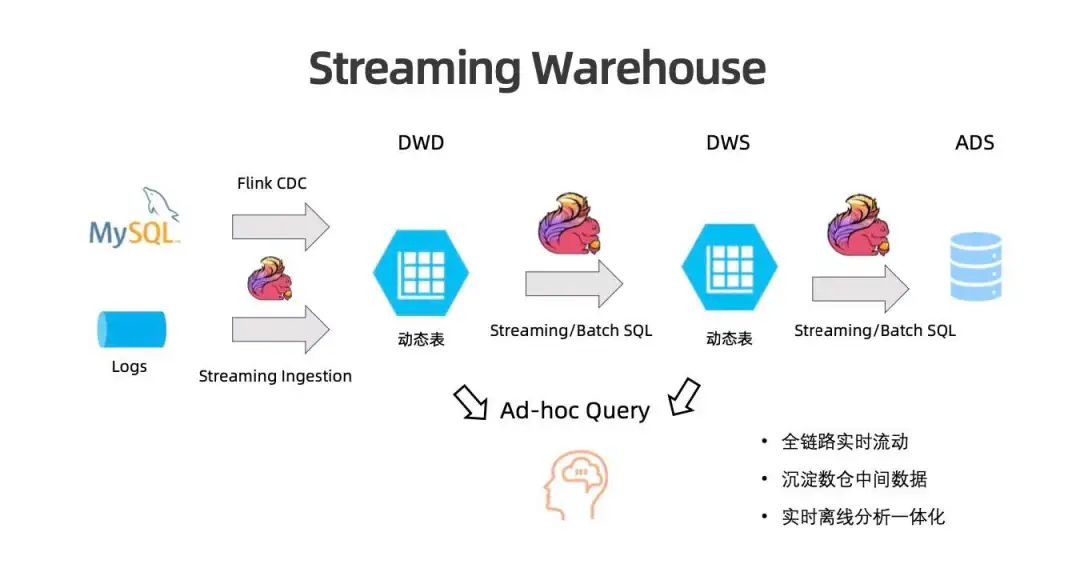

-
Table Format:能存储全量数据,能够提供很强的更新能力以处理数据库 CDC 和流处理产生的大量更新数据, 且能够面向 Ad-Hoc 提供高效的批查询。 -
Streaming Queue:流读、流写,能在存储上建立增量处理 Pipeline。 -
Lookup Join:面向 Flink 维表 Join 提供 Lookup Join 的能力。

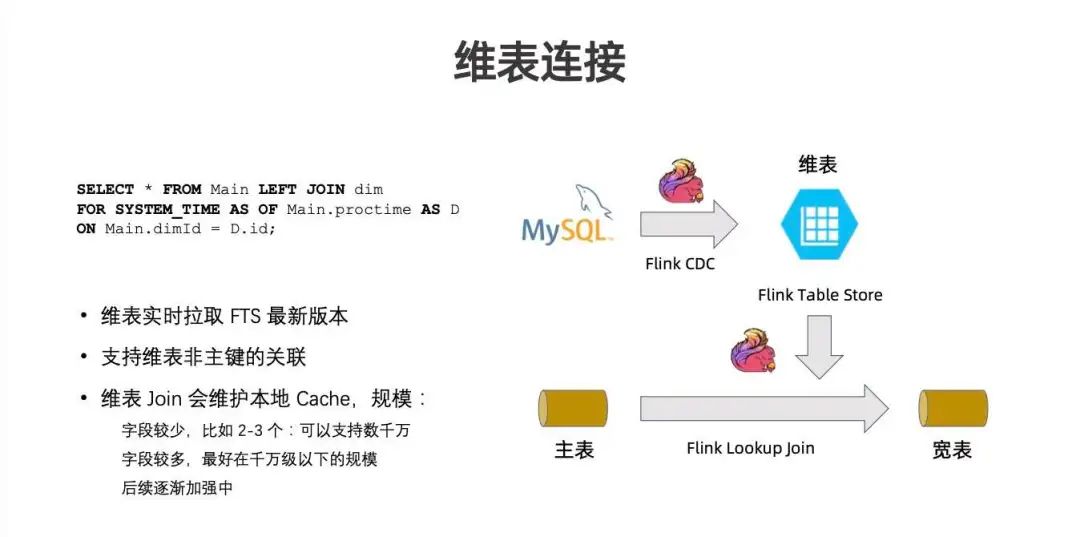
应用场景


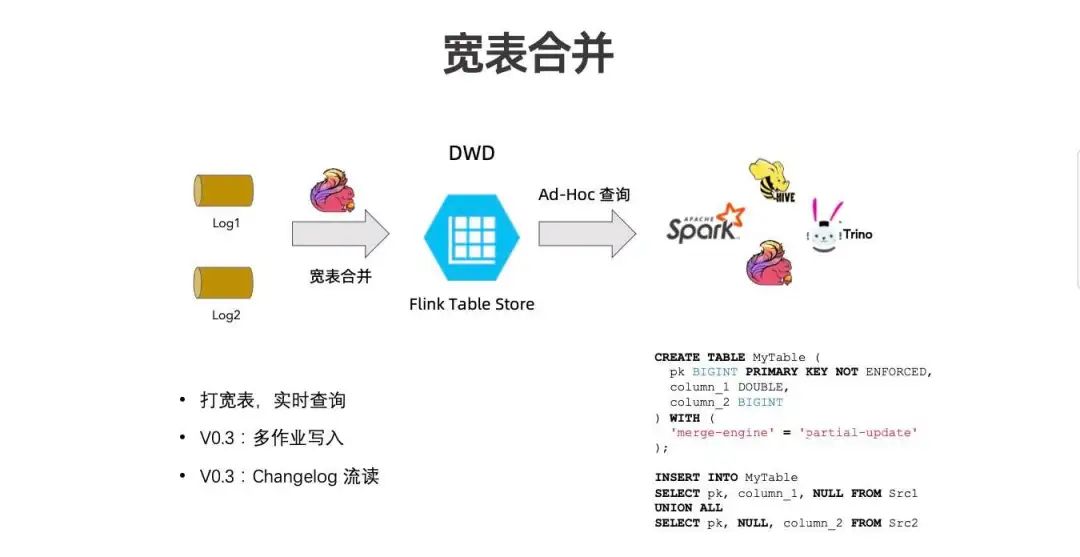
Demo

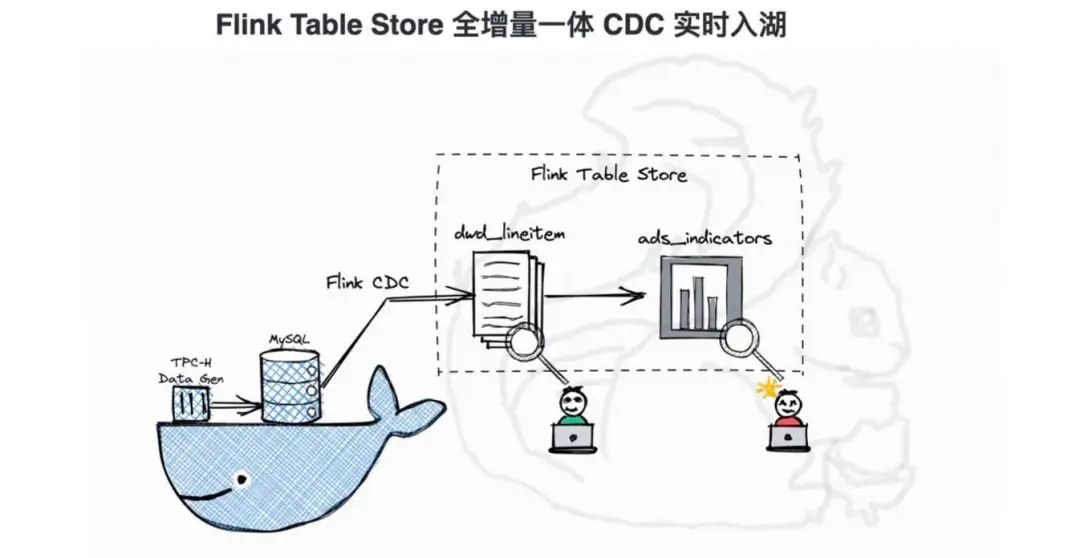
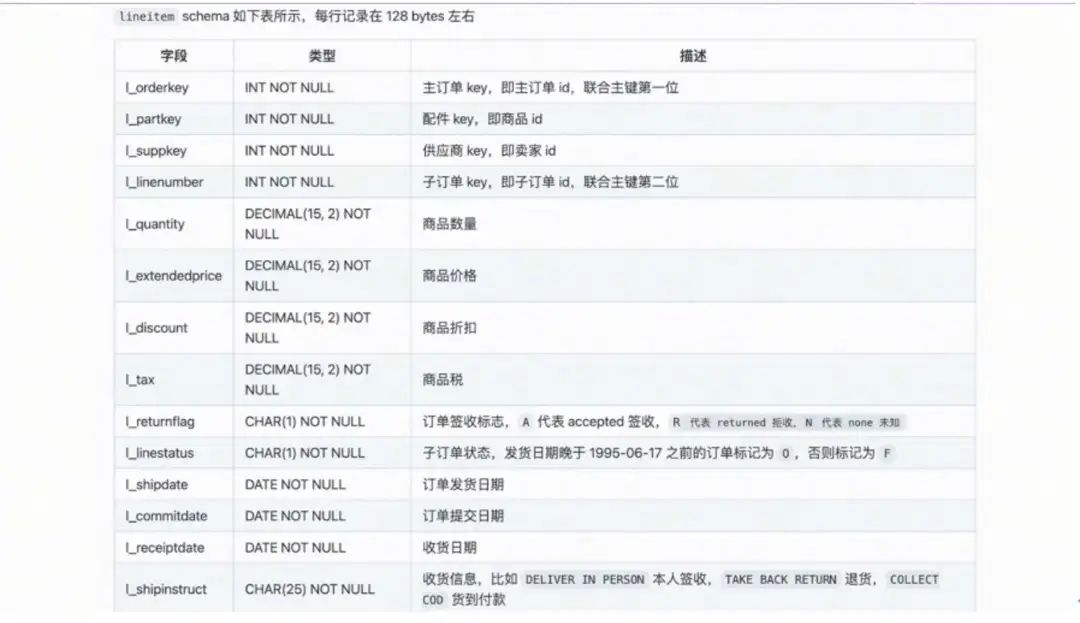
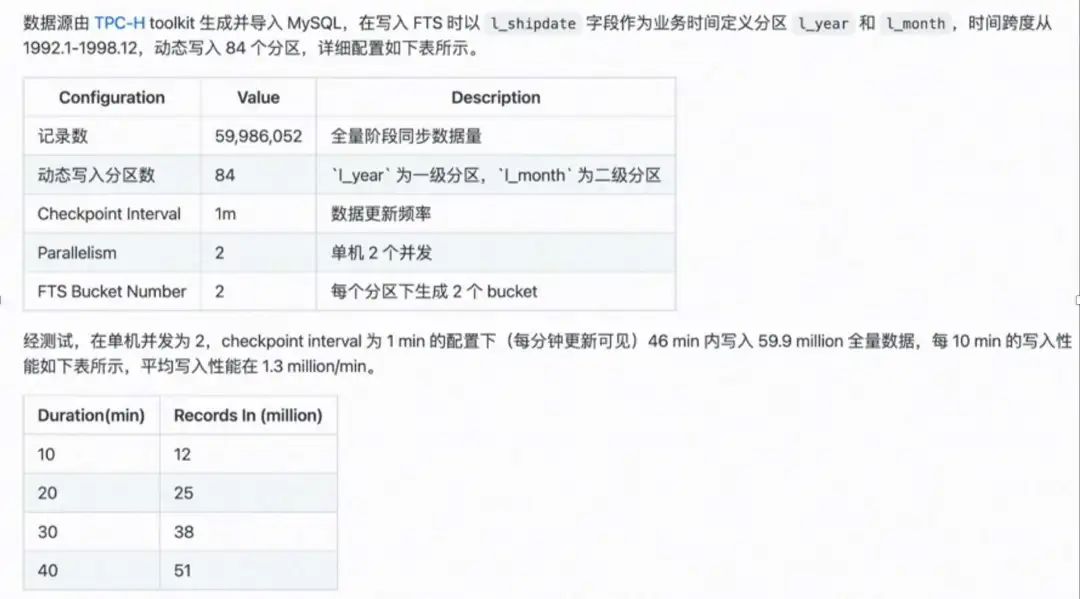
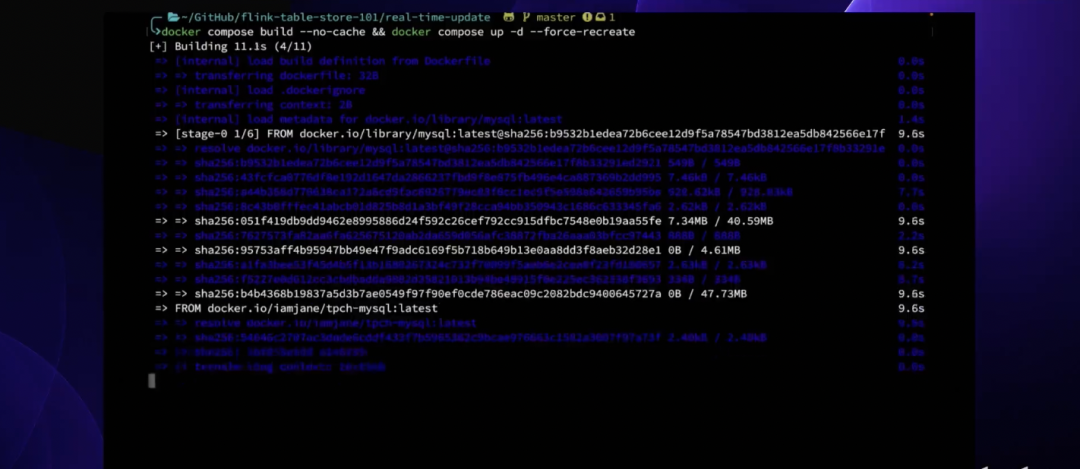
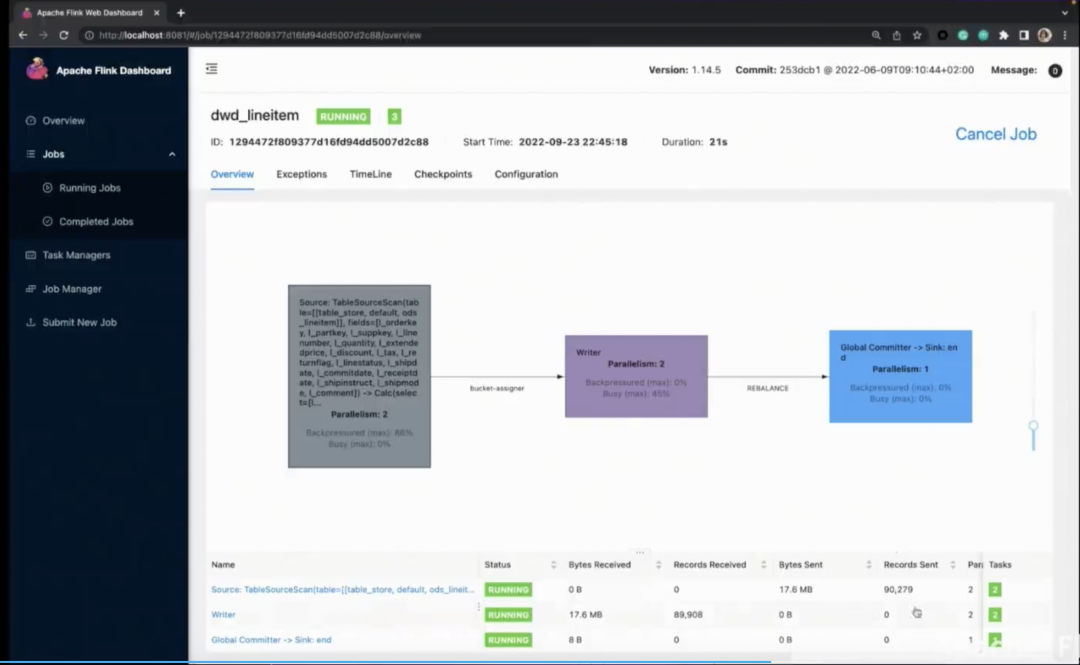
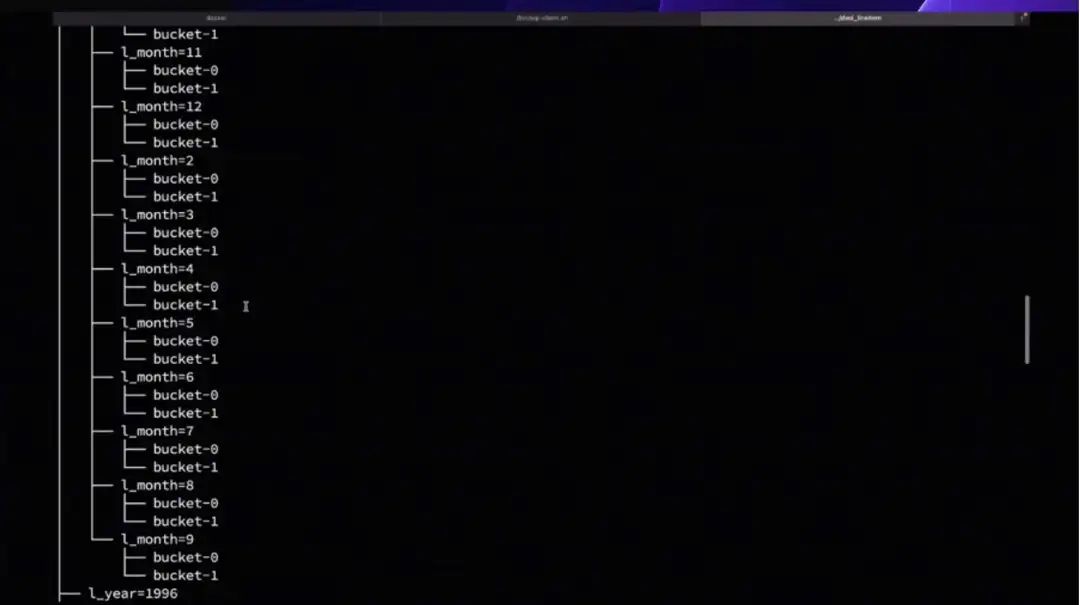
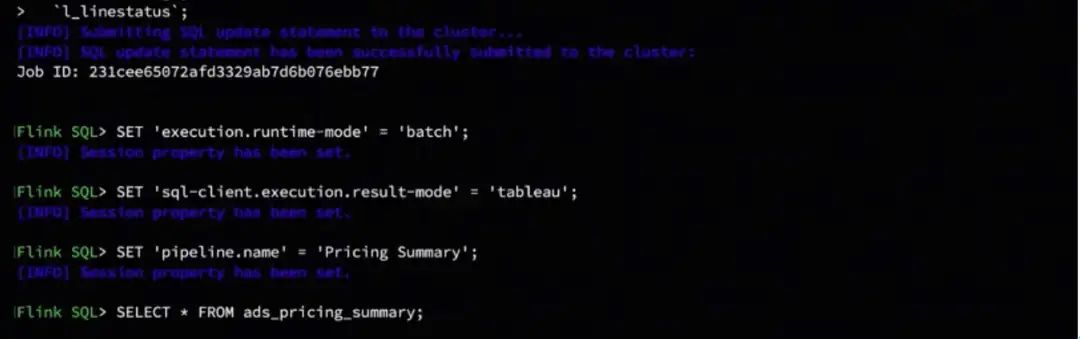
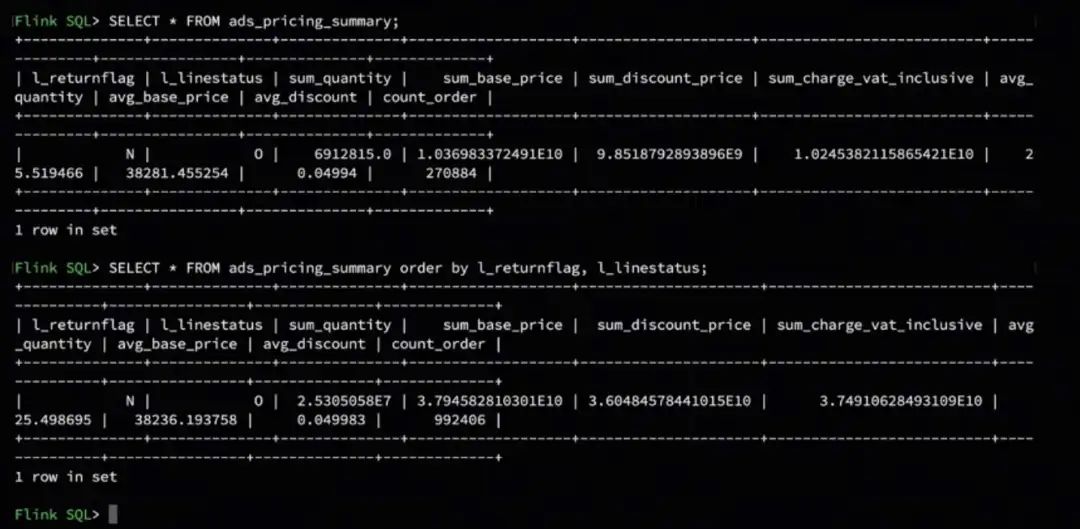
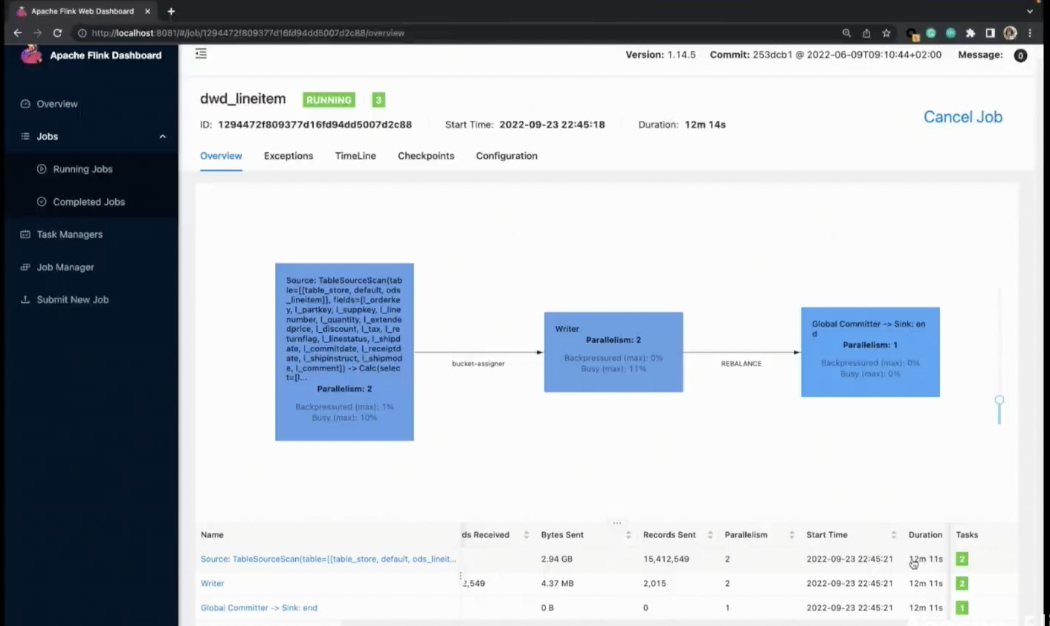
将 Flink-Table-Store-101 克隆到本地,然后切换到 Real- Time-Update 目录下,启动容器。此处会先构建自定义 MySQL 镜像,在 Container 启动之后,自动生成 5900 万+条数据,并通过 load data info 导入到 MySQL lineitem 表。生成的数据总共切分为 16 个 chunk ,大约需要 1 分钟左右可生成完毕。数据生成完毕后导入 chunk,大约需要 15 分钟。

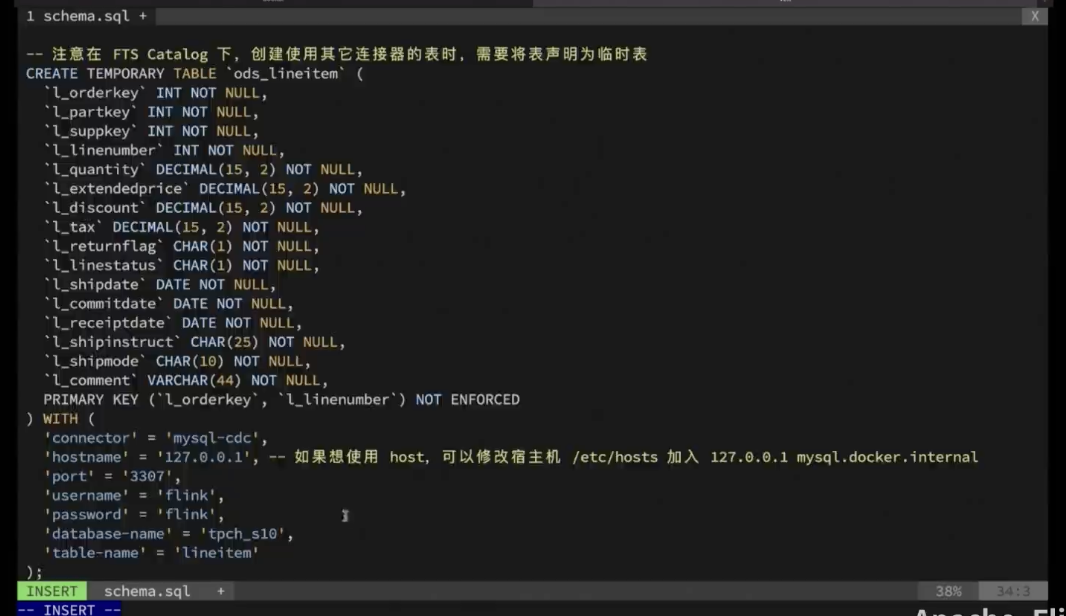
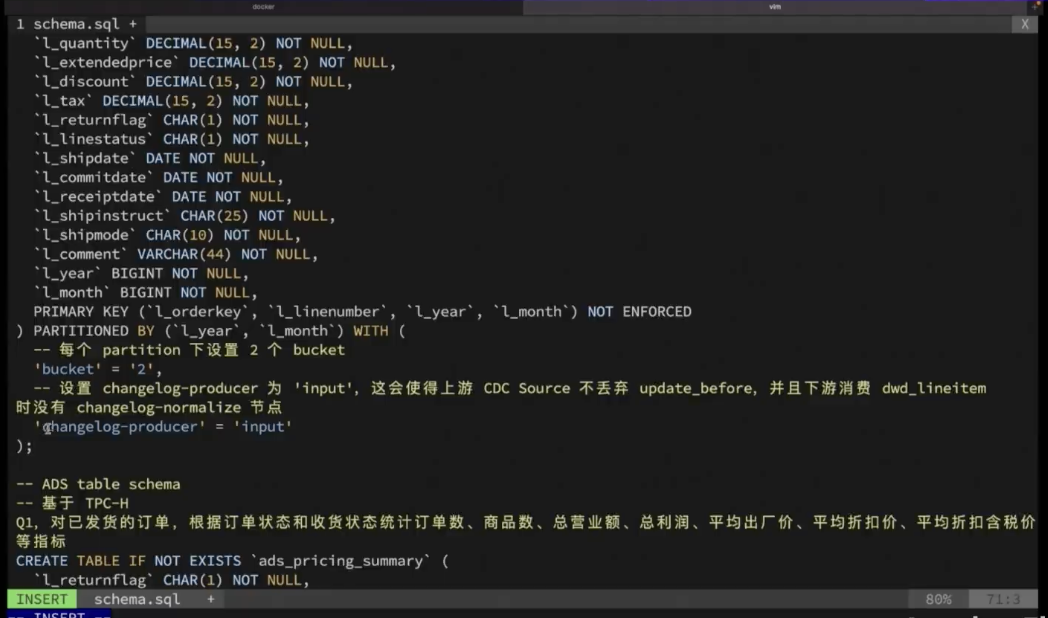
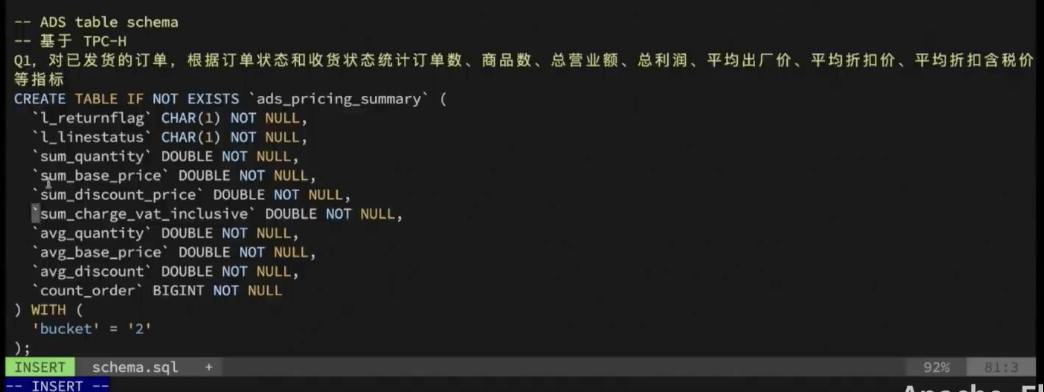






后续挑战

-
第一,存储管控。我们希望通过 Flink CDC、Flink SQL 流批一体计算加上 Flink Table Store 存储打造闭环,通过 Flink SQL 来管控运维、执行 Pipeline 的 一整套系统,需要运维管控元数据的工作,这也是 Flink 1.17 的重点推进方向。 -
第二,流计算准确性。想要完全分层次的 Streaming Pipeline ,本质上要求存储能够自己产生完整的 Changelog ,则流计算中的手动去重、莫名其妙的数据正确性等问题都能够自然而然得到解决。 -
第三,Join 。Join 在逻辑上存在诸多问题,维表 Join 需要额外系统,但有时语义不满足,因为维表更新并不触发计算。而且维表 Join 具有一定的随机性,会破坏完整的 Changelog 定义。另外,双流 Join 需要保存全量明细,代价太高。 -
第四,物化视图一致性。构建 Streaming Data Warehouse 本质上是构建一系列物化视图,而如果Streaming Data Warehouse 的每个 Table 都可查,一致性却无法保障,最终呈现的也是不一致的视图。

-
第一,好用的流存储。比如多作业写同时写入、Compaction 分离,比如完整的 Streaming Data Warehouse API 设计,包括完整的 DDL、Update、Delete 语法、Time Travel API 支持。以上能力将与 Flink 社区一起在 1.17 版本中重点攻克。 -
第二,准确的流存储。存储本身能够产生完整的 Changelog ,下游的流计算易用性才能真正得到提高。 -
第三,可连接的流存储。继续增强 Lookup Join ,实现二级索引以更好地 Join,实现维表对齐能力,解决维表不确定性。
■ Flink Table Store 目前已经发布 0.3.0:https://flink.apache.org/news/2023/01/13/release-table-store-0.3.0.html
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/12424/