


分享嘉宾:向阿鲲 哔哩哔哩
编辑整理:曾新宇 对外经贸大学
出品平台:DataFunTalk
导读:大家好,我是来自哔哩哔哩OLAP平台的向阿鲲。今天主要是跟大家分享B站基于Iceberg + Alluxio助力湖仓一体项目的落地与实践,分享内容可能会涉及到不少技术细节。
我主要从以下四个方面进行展开:
-
B站湖仓一体项目的背景介绍
-
B站基于 Iceberg 湖仓一体一系列优化与落地实践
-
Alluxio的实践
-
未来规划
B站湖仓一体项目的背景
当前B站每天会有pb级的数据进入Hadoop,从而衍生出大量的数据分析、BI报表、数据探索等需求。传统的SQL on Hadoop 不管是hive、spark还是 presto 都很难满足业务的性能需求。如果要出仓到像ES、Hbase、MySQL、Clickhouse等,不仅会增加额外的数据开发、数据冗余、数据服务开发等成本,数据的稳定性和可靠性也会随之降低。SQL on Hadoop 本质上是一套数据湖方案,它不仅支持海量数据存储,拥有开放的存储格式,支持开放的数据处理引擎和湖内的ETL流转等。当前我们急需一套技术架构,在拥有数据湖灵活性的同时又具备数仓的高效性,所以我们开始探索基于 Iceberg 推动从数据湖架构到湖仓一体架构的演进。
02
基于 Iceberg 湖仓一体的优化与落地实践
下面是湖仓一体项目架构图,大体分为三部分:
最左边的部分是数据的摄入,主要分两块:一块是实时数据的摄入,主要是通过Flink消费Kafka数据,然后落到Iceberg表里面。第二块是Spark通过ETL把数据落到Iceberg表里。
第二部分是存储的优化,我们有一个内部服务Magnus,会起一些相应的spark job针对iceberg表进行一些存储优化。
第三部分是交互式分析。目前我们交互式分析引擎主要是用的Trino,然后借助Alluxio作为一个缓存加速。
首先跟大家简单介绍一下Iceberg。
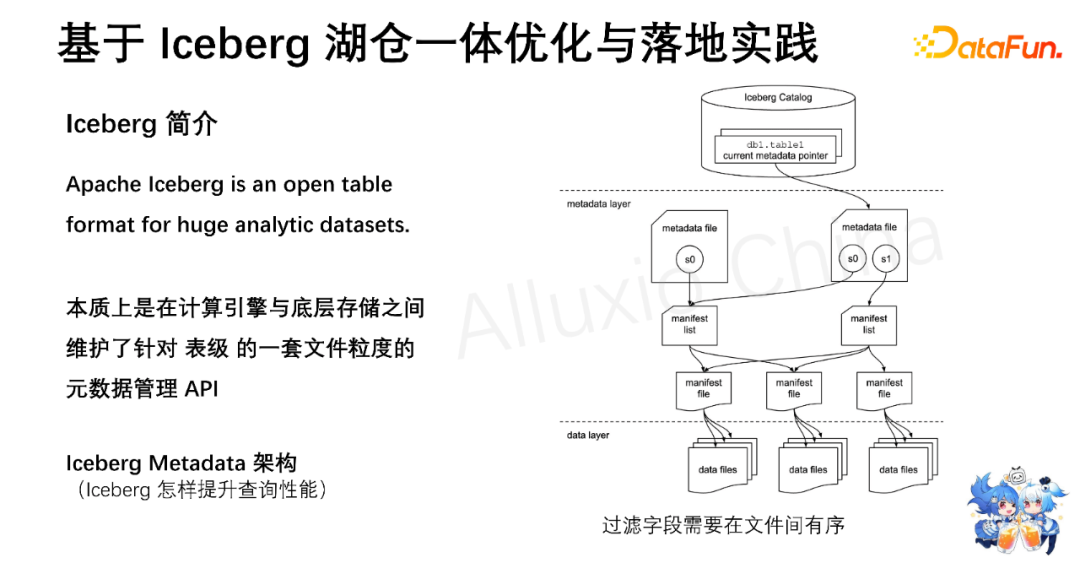
“Apache Iceberg is an open table format for hug analytic datasets.”这是在Iceberg官网上的一句话,Iceberg是针对海量数据的开放表格式。我理解本质上 Iceberg其实是在计算引擎与底层的存储之间维护了针对表级的一套文件粒度的元数据管理API。
右图是Iceberg的一个元数据架构图,我们可以看到架构图分为三层:
第一层 catalog,目前实现主要分为两种是Iceberg——一种是Hadoop Catalog,一种是Hive Catalog,目前我们使用的是Hive Catalog。也就是说我们会把一些table的scheme信息保存在Hive Metastore里面,Metadata location地址也会保存在这个Hive Metastore里面。
第二层是元数据层。元数据层主要分为三类文件:第一类是metadata file(这是一个json文件),第二类manifest list文件,第三类是manifest file文件。后两种是avro格式文件,metadata file文件会保存表的schema信息和分区信息,它会包含一个或多个的快照引用,快照引用会指向manifest list文件。manifest list文件会包含一个或多个的manifest file文件,也就是说每一个manifest file文件在manifest list里面是一条一条的记录,这条记录会保存这个manifest file的文件路径,也会保存这个manifest file对应的数据文件的分区范围,也就是分区的一个min/max值。当然,它还会保存一些其他的元信息。manifest file文件会包含一个或多个的数据文件(data file),每个数据文件在manifest file里面是一条或多条的记录,每条记录都会保存data file所在的文件地址和data file本身的大小和记录数,最重要的是它会保存data file的每一个字段的最大最小值。
Iceberg怎样提升查询性能?也即如何通过在manifest file里面引用的data file的每个字段的min/max值来加速查询。
假设我们是通过计算引擎Trino,在SQL的plan阶段就可以利用元信息的每个字段的min/max值进行高效过滤,把不在这个查询范围的数据文件直接过滤掉,不用等到实际执行阶段再去做实际数据的过滤,这样对查询性能会有一个极大的提升。这里有个前提条件,即通过字段的min/max值过滤需要过滤字段在文件间是有序的。怎么做到文件间有序?下面我介绍一种最常见的做法——通过一种线性排序对数据进行组织优化:我们可以通过spark的cluster by对表的某一个或多个字段进行分区类的数据全排序。这种方式的优点是不需要额外的存储冗余,就可以利用排序字段在Iceberg元数据文件级别上的Min/MAX值进行高效的过滤。不足是通常只有排序的一个字段会有比较好的过滤效果,通过其他字段过滤往往效果不佳。

下面介绍另外一种对数据组织排序的方式:Z-order,这是最近比较流行的一种排序方式。
Z-order是在图像处理以及数仓中使用的一种排序方式。Z-order的曲线可以是一条无限长的一维曲线,穿过任意维度的所有空间。左边有一个二维曲线图,右边是一个三维的,三维可能比较抽象,我们后面可能主要是针对二维进行展开,三维可以进行一些类比。对于每一条数据的多个排序字段可以看作是数据的多个维度,多维数据本身是没有天然顺序的。但是Z-order通过一定的规则将多维数据映射成一维数据,然后构建Z-value。
上图是二维图,包含两个字段x跟y。x、y中间生成的这个值,我们就把它叫做Z-value,它的生成规则是根据这些排序字段按照交错的比特位去生成的。红色表示y,蓝色表示x,也就是y取一位x取一位,这样构成的Z-value值就变成一维的值了。为什么是叫z-order排序?因为它构成曲线是z字形的。z字形的曲线有什么特点?在z字形的曲线上,根据z-order生成的一维z-value是有序的。第一个点是六个零对应的二进制表示的是0。第二个点是5个零加个1,它对应的是1,后面依次对应的是234567…。也就是说沿着z字形的曲线是有序的。
Z-order的映射规则保证了按照一维数据排序后的数据可以同时根据多个字段进行聚集,也就是说这个曲线是有序的。假如把这份数据做一个切割,比如从中间把这个数据切成四份。其实它根据Z-value在每一个文件里面的Z-order是有序的。同时对于我们x跟y来说它其实也是有聚集的。像我们第一个文件x它只包含0~3的范围,y也只包含0~3的范围。
下面将Z-order跟线性排序做一个比较。还是刚才那个例子,x的取值范围是0~7,y的取值范围也是0~7。假如我们用线性排序,根据x、y做一个range的分区。假如把它也是分到四个文件里面。最后分到文件的效果,就应该是下面这个样子。也就是我们看一下在文件一里面x的取值范围是0~1。文件二里面x的取值范围2~3,文件三是4~5,文件四是6~7,y的取值范围的话都是0~8。因为这是一个线性的排序。假如我们现在通过x=5去过滤,我们可以看到这边只需要读取文件三就行了。因为文件三的x的取值范围是4~5,也就是文件一、文件二、文件四都不需要读取,可以直接skip掉。假如我们现在想通过y=2去过滤,因为y的取值不管在哪个文件里面都是0~8,所以这四个文件都需要读取。在这种情况下过滤是没有任何过滤效果的。
我们也是根据x、y 进行Z-order的排序。刚才提到的切割,切割之后分在四个文件里面,也在第一个文件里的话,x取值就是0~3,y的取值也是0~3,这是我们第一个文件。第二个文件x取值4~7,y取值也是0~3,对应的第二个文件。第三个文件和第四个文件也是类似的。同样的我们用x=5去过滤的话,可以看到在第二个文件跟第四个文件里面,因为它的取值范围是4~7,包含x=5这个范围,所以两个文件需要读。在文件一和文件三中x取值范围是0~3,所以我们可以直接skip掉,不用去读这个文件。相应地,如果我们用y=2去过滤,可以只用读文件一和文件二。因为y的取值范围是0~3,所以这两个文件是需要读的。相应的文件三、文件四就可以直接跳过了。
总结:
通过Z-order排序之后,不管是用x还是y过滤都能过滤50%的数据。实际应用场景中,数据分区里面数据文件如果切分得更多,过滤效果也会更好,会超过50%。
Spark 本身支持 range partition,也就是支持范围分区。范围分区主要分为两个阶段:第一阶段是对排序字段进行采样,获取指定分区(spark.sql.shuffle.partitions)个数的采样点(默认 200),并将采样值按大小依次排列,采样会尽量使得数据均匀分布在每个区间。第二阶段是实际数据读取、shuffle、写入阶段,shuffle 前,每条记录的排序字段跟采样点的值进行比较,把数据分别落入 0~199 个对应区间,从而实现了排序字段在文件间的有序。
Z-Order也是沿用了 range partition 的思想,在采样阶段,分别计算需要排序的多个字段的采样点,并将采样数据依次跟排序字段的采样点进行比较,获取对应字段分区下标值,多个字段下标值即可生成 z-value,然后通过所有 z-value 计算指定分区个数的采样点。shuffle 前,对每条记录的多个排序字段分别获取采样点的下标,生成 z-value,最后是将 z-value 跟分区的采样点进行比较,落入对应分区,即可实现 Z-Order 排序。
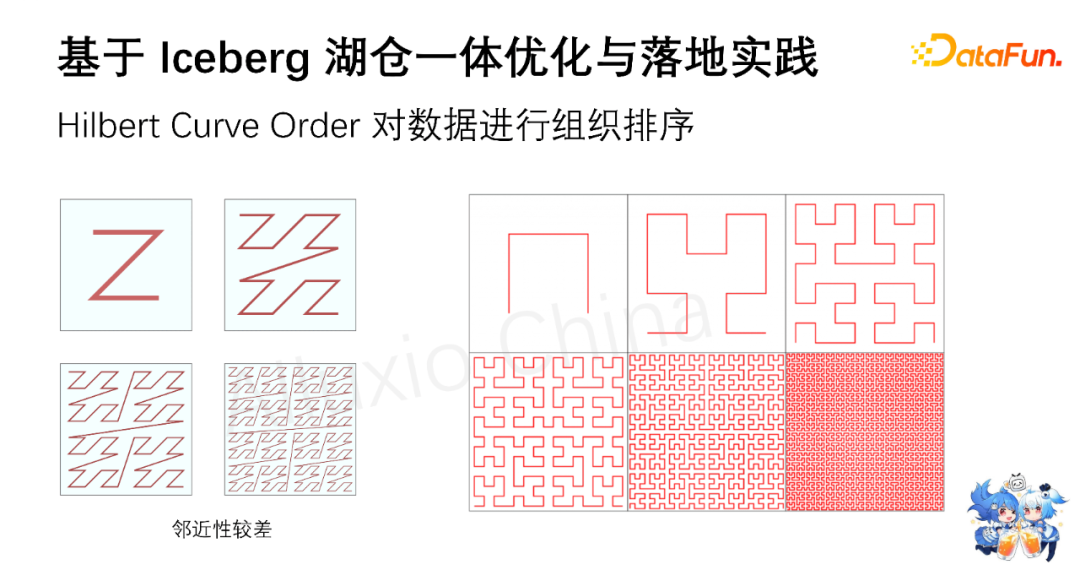
右边的这个曲线是HIlbert Curve Order,也就是希尔伯特曲线。
为什么要介绍这种排序?是因为Z-order会有一个小小的缺陷,它的邻近性比较差,邻近性是什么意思?我们每一个数据点连线的跨度比较长,也就是邻近性会比较差。具体在案例中是怎么体现呢?我们以刚才那个x取值是0~7的范围为例。刚才把这边分成四个文件,理想的情况下是所有的数据都是均匀地分布在每个文件,但实际应用场景中可能数据切分得并不是那么均匀。假如我们这边实际是X取值可能是等于7的一个取值,它划分到下面这个文件里面来了。原本下面这个文件X取值的话可能是0~3。因为这个x=7的取值划分到这个下面文件,导致我们下面这个文件的X取值范围就变成0~7了。假如通过X在0~7的这个范围里面,不管用哪个值去过滤,这个文件都不能被过滤掉,也就是使得过滤效果会有一定的影响。
希尔伯特曲线的每一个点不会有很大的跨度,也就是避免了Z-order邻近性比较差的问题。
总结:Z-order跟Hilbert曲线的优缺点
优点首先是无需额外的存储冗余。第二点是支持对多个字段进行组织排序,多个字段分别过滤时都会有比较好的文件级别的过滤效果。通常排序字段是2~4个时可能过滤效果会比较好。当排序字段超过4个的时候,过滤效果可能会变差,排序字段越多,效果可能会变得越差。另外,过滤的本质是利用字段Min/Max值去做过滤,它并不能做到比较准确的判断。
针对Z-order的这个缺陷,我们引入了BloomFilter索引。
首先介绍一下BloomFilter是什么。
BloomFilter是一个很长的二进制向量,元素可以通过多个Hash函数计算后,将多个整形结果在对应的向量比特位上置为一,可以判断某个元素是否在这个集合里面。BloomFilter的优点是空间效率和查询时间都非常高效,非常适用于检索一个元素是否在一个集合里面。它的缺点是首先会存在一定的误判率,也就是说实际某个元素不在这个集合里面,但可能会被误判为存在这个集合。另外,BloomFilter只适合等值判断,比如等于in或not null的判断,对于 >、>=、
由于bloomfilter的一些缺陷,我们引入了Bitmap索引。Bitmap是将一组正整型数据映射到对应的比特位,相对于BloomFilter,它是不存在哈希冲突的。
下面介绍Bitmap索引的几个实现,首先介绍等值编码的实现。我们假设有一个数据文件,有三个字段。我们现在想根据订单的总价格这个字段,构建一个Bitmap。Bitmap构建的结果是下图的右侧所示。对应的横轴0~8,也就是这个字段在文件里面的一个下标。纵轴对应的就是字段的各个基数值按从小到大的排序(我们可以把这些基数值存在一个有序数组里面)。对应比特为一的代表这个数据在这个文件里面的位置,比如这个2对应这个文件里面的第3行,所以它的下标也是在2的那个位置设置为1,其他的也是类似的。

假如我们现在想去获得Bitmap等于18的值,我们怎么去获得?
刚才提到我们可以在有序数组里面首先去判断这个18存不存在,存在的话我们只要把这个18取出来就行了。假如我们想去做一个范围过滤,比如算价格小于200这个结果,如果是根据等值编码算的话,其实我们需要是把所有的bitmap都取出来,然后做一个bitmapOr的运算,也就是把所有结果做一个并集。这种返回的结果就是小于200的结果。如果基数很大,比如百万级甚至更大,这个计算量就很大,成本也就很高了。

针对等值编码缺陷,我们可以引入一个叫Range Encoded的编码。左边是刚等值编码,右边是RangeEncoded的编码,它的编码规则是什么?它是所有大于该取值的值,在对应行号的比特位置为1,比如我们这个2的位置,这边比2大,下面的这些18、20,我们把这个下面全部都置为1,最终生成的结果是如右图所示。

如果根据RangeEncoded编码再去计算,假如我们现在想去算一个取值等于20,只需要把20对应的bitmap以及比20小的bitmap取出来,然后做andNot操作。对于小于或小于等于运算,比如我们想算小于19的,只要把就是比19小最接近19的那个bitmap取出来,对应的结果就是bitmap的结果了。对于大于或者大于等于这些也是类似的(可以注意一下最后一行都是为1的,也就是notnull取值的bitmap,这里对应的其实订单价格全部非空,所以取值全为1)。这个优点是最多值取两个bitmap就可以计算任意的等值,大于/大于等于、小于/小于等于的过滤条件,和字段基数大小没有任何关系。它的不足是构建bitmap的时候仍然要生成对应基数个数的bitmap,存储的索引文件会过大。
针对RangeEncoded的缺陷,我们又引入了BIT-SLICED 编码。
假设 lo_ordtotalprice 取值区间为 0-255 的连续值,我们就需要256 个 Bitmap 来表示每个取值。如果用十进制 slice来表示的话,需要三个 Slice 位来表示 0~ 255,取值20的行号映射 Bitmap 为 100000000,我们把它对应的每个slice 位 (个位) – 0(20的个位), (十位) – 2(20的十位), (百位) – 0 ((20的十位))都置为100000000。如果我们希望获取等于 20 的 bitmap,只需将三个位置的 bitmap 取出做and 运算,全为 0,表示不存在,否则结果即为 20 对应的Bitmap。从这里可以看到,只需 3个(slices)* 10(0-9) = 30 个 bitmap 表示 0~255 的取值。
将BIT-SLICED ENCODED BITMAP与RANGEENCODED进行结合的话,BIT-SLICEDENCODE减少了BITMAP 存储的个数,RANGEENCODE减少了计算需要读取的BITMAP个数(也就是最多只需要读取2 个BITMAP就能完成计算)(存储所需的BITMAP个数:如果是0~255的连续值,只需28 (10 * 3 -3(个重复)+ 1) 个BITMAP)。更进一步的,如果我们用二进制切片的话,按照基数取值范围(0-255),总共需要9 (比特位需要用8个slice位,每个slice都是0/1,最后一个是全1,只需要1个表示就可以:8*2 –8 + 1)个bitmap,如果基数取值是在int表示的范围内,最多也不超过32个bitmap就可以存储整个的int的取值范围了。
下面介绍一下bitmap最终的一个实现,总体是通过BIT-SLICED ENCODED 与RANGEENCODED结合并使用二进制切片。
实现的过程是:对字段A构建bitmap索引时,先读取对应数据文件,依次读取每一行,将A的值保存在以A字段作为key,A的行号构成的List作为值的有序MAP中。将MAP的key作为字典(字典是有序的,就可以进行二分查找)以及每个List经过bit-sliced编码之后的bitmap都保存在索引文件中。Bitmap对应的取值是字典的下标,即从0开始到最大基数的连续取值,所需bitmap个数log2(基数),由于保存了字典信息,bitmap索引可以支持各种非嵌套数据类型。比如正常bitmap可能只支持int类型。这样我们就可以支持像String或者 Double等类型。
下面总结下Bitmap的优缺点。
优点:不仅支持等值过滤,>、>=、 不足:Bitmap 索引通常会比 BloomFilter 大不少,会有一定的存储和读取的开销。
下面看一下我们在Iceberg上经过一系列的优化之后做的一个SSB的测试。SSB有13个query,然后我们是加了TPC-H的q5.1、q5.2,总共五个测试结果。主要分为四类,第一类是basic,basic是指我们把数据导入之后没经过任何优化;第二类是z-order+min/max;第三类z-order+bloomfilter;第四类z-order+bitmap索引。从这个图里面可以看出,就在z-order+min/max不能达到比较好过滤效果的时候,用z-order +bitmap可以做到一个比较好的补充。然后从整个查询时间跟读取文件的数量的测试结果来看,它总体的查询时间有1~10倍的性能提升,扫描文件数有1~400倍的减少。这对应的是我们线上的一个实际的例子,也是一个百亿数据的查询。最开查询耗时是13s多,读取了一百亿的数据。经过我们的优化,结合z-order与bitmap索引,最终整个查询的耗时只花了一点几秒,实际数据读取量只读取了三十几万条数据。最后看一下CPU耗时,之前CPU耗时花费了17 min+,后面CPU耗时只花费了一点几秒,大大节省了计算资源。
03
Alluxio的实践
1. Alluxioa引入的背景
随着我们在Iceberg的一些改造,元数据文件也逐渐增大。同时为了降低新增索引文件的一个读取开销以及Hadoop集群抖动等因素对文件读取的一个影响,我们引入了Alluxio。
目前,Alluxio 主要用来存储 Iceberg的元数据,即其自身的 metadata,以及我们新增的索引文件数据和目前我们正在做的 cube 功能,cube 文件也会保存在 Alluxio 中。我们只存储 Iceberg 元数据的考量:第一个原因是我们早期的业务量不大,用了独立的Hadoop 集群用来保存Iceberg表的数据。在大多数情况下我们能够保证集群的稳定,然后数据读取基本也能满足业务的性能需求。第二点是因为Iceberg元数据有版本的概念,可以直接通过元数据保存的文件路径去读取元数据,不需要担心元数据过期导致元数据读取不一致的问题。在我们业务开展前期的使用Alluxio成本就大大降低了,我们不用担心读取这个文件它可能会失效。
这边是我们在引入Alluxio之前做了一个基准测试,主要是分四种情况:第一种情况是在引入之前;第二种是引入Alluxio之后,引入之后第一次读取相当于是没有命中缓存;第三种是读取远程worker节点的性能;第四个就是读取本地worker的一个性能。我们得到的以下结果:在引入Alluxio之后,我们第一次读取开销可能会有10%~25%的性能损失,这个随着文件增大会减小。缓存生效之后,去读取远程worker文件,有1.5倍到2倍的这样一个性能提升。读取缓存在本地worker文件,有5~10倍的性能提升。文件越大,性能提升也会越大。
2. Alluxio上线后的收益
在我们上线之前,遇到过一个问题:我们通过Trino去访问Iceberg元数据,它一个偶发的抖动会导致性能急剧下降。在我们引入Alluxio之后,访问metastore抖动问题基本上没有出现过了,这就保证了查询的稳定。目前我们单个元数据文件也并不是很大,都是kb级到几十M不等。我们通过历史查询耗时的分析,发现Alluxio对元数据访问整体有不错的性能提升。
04
未来规划
首先我们在Iceberg上希望对预计算进行支持。预计算最主要的场景是针对一些聚合查询或者说是多表关联的一些查询。我们希望对一些高频的聚合查询进行预先构建cube,然后通过计算引擎直接把查询下推至cube里面,通过cube去响应。
第二点是星型模型的优化。星型模型主要是事实表跟一个或多个维表join,会通过维表的多个关联字段进行过滤。这种情况我们考虑把维表的过滤字段作为虚拟列保存在事实表里面,然后直接下推到事实表。这样就可以起到一个比较好的过滤效果。
第三点就是用Alluxio进行热点数据的缓存,最主要两点考量。第一点是为了保证线上的SLA,第二点是想加速热点数据访问的一个性能。
最后是智能化的数据优化。主要是通过分析历史的查询,自动去优化数据的一些排序、索引等信息。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

向阿鲲
哔哩哔哩OLAP平台资深开发工程师
负责B站OLAP平台,湖仓一体方向:Iceberg/Trino 内核研发、优化探索实践,智能化管理平台设计、开发,以及业务接入支持、优化等相关工作。
本文转载自 向阿鲲 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/pKk4hLN06P_sguQAmV5-Bw。