
温馨提示
本文部分翻译自2017.3.12 Uber Engineering发布文章《Hudi: Uber Engineering’s Incremental Processing Framework on Apache Hadoop》,随着Hudi的发展其架构发生了变化,但是对于了解Hudi的起源和演变还是非常有帮助的!
随着ApacheParquet和Apache ORC等存储格式以及Presto和Apache Impala等查询引擎的发展,Hadoop生态系统有潜力作为面向分钟级延时场景的通用统一服务层。然而,为了实现这一点,这需要在HDFS中实现高效且低延迟的数据摄取及数据准备。
为了解决这个问题,优步开发了Hudi项目,这是一个增量处理框架,高效和低延迟地为所有业务关键数据链路提供有力支持。
基本概述
Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi数据集通过自定义的InputFormat兼容当前Hadoop生态系统,包括Apache Hive,Apache Parquet,Presto和Apache Spark,使得终端用户可以无缝的对接。
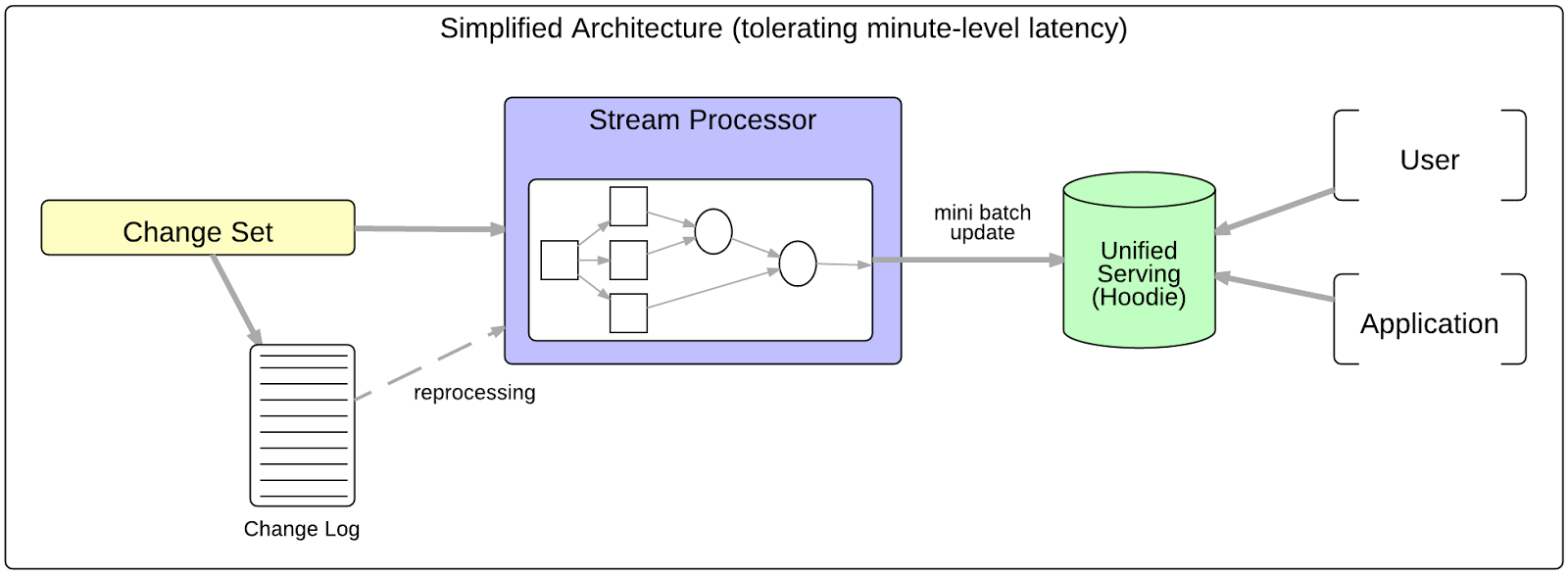

该数据流模型通过时延和数据完整性保证两个维度去权衡以构建数据管道。下图所示的是Uber Engineering如何根据这两个维度进行处理方式的划分。
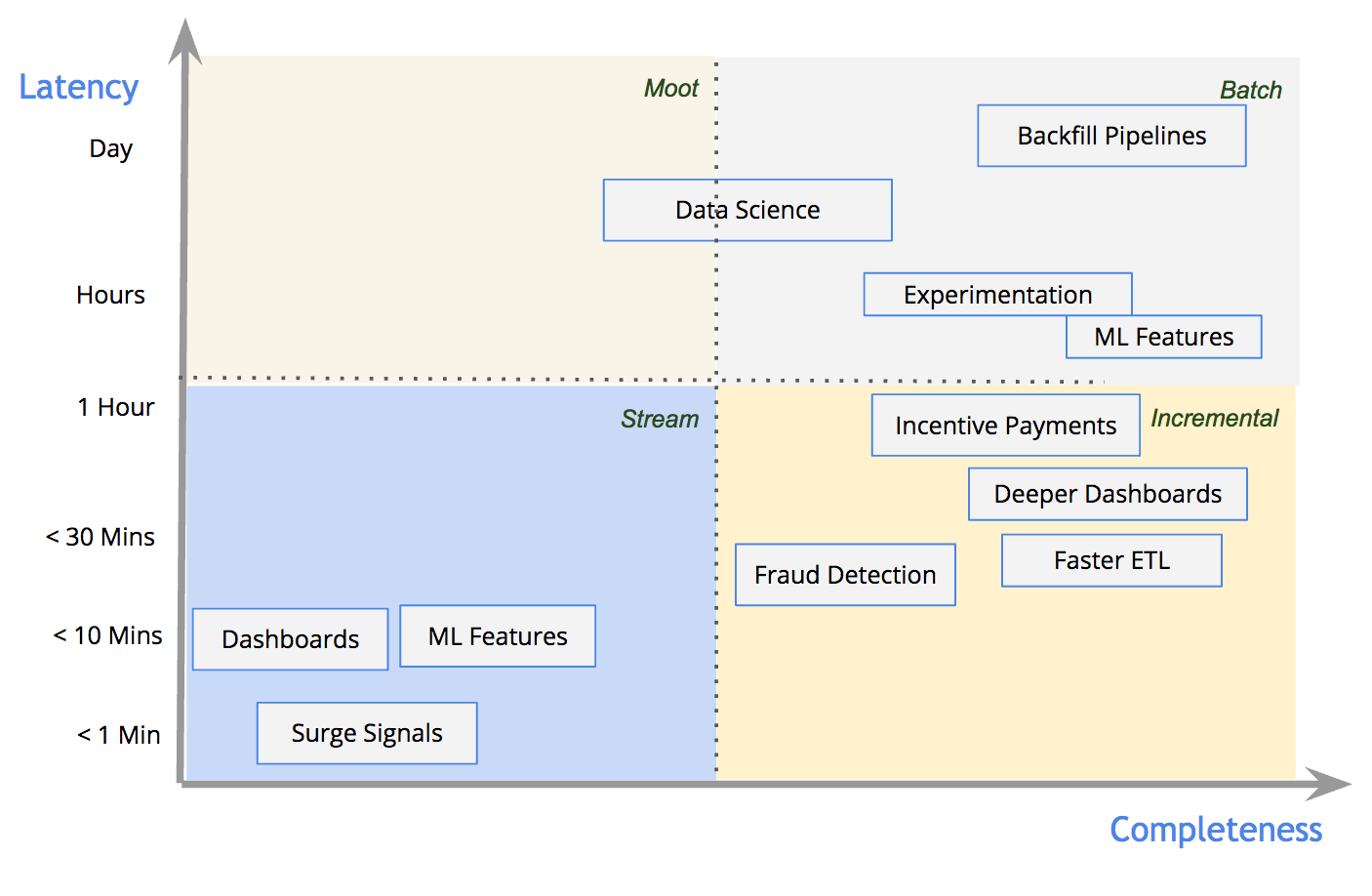
对于很少一些需要真正做到约1分钟的延时的用例及简单业务指标的展示应用,我们基于行级的流式处理。对于传统的机器学习和实验有效性分析用例,我们选择更加擅长较重计算的批处理。对于包含复杂连接或者重要数据处理的近实时场景,我们基于Hudi以及它的增量处理原语来获得两全其美的结果。
架构设计
存储
Hudi将数据集组织到一个basepath下的分区目录结构中,类似于传统的Hive表。数据集被分成多个分区,这些分区是包含该分区数据文件的目录。每个分区都由相对于基本路径的partitionpath唯一标识。在每个分区中,记录分布到多个数据文件中。每个数据文件都由唯一的fileId和生成该文件的commit来标识。在更新的情况下,多个数据文件可以共享在不同commit时写入的相同fileId。
每条记录都由记录键唯一标识,并映射到fileId。一旦记录的第一个版本被写入到文件中,记录键和fileId之间的映射是永久的。简而言之,fileId标识一组文件,其中包含一组记录的所有版本。
Hudi存储由三个不同的部分组成:
- 元数据:Hudi将数据集上执行的所有活动的元数据作为时间轴维护,这支持数据集的瞬时视图。它存储在基路径的元数据目录下。下面我们概述了时间轴中的行动类型:
-
提交:单个提交捕获关于将一批记录原子写入数据集的信息。提交由一个单调递增的时间戳标识,这表示写操作的开始。
-
清除:清除数据集中不再在运行查询中使用的旧版本文件的后台活动。
-
压缩:协调Hudi内不同数据结构的后台活动(例如,将更新从基于行的日志文件移动到柱状格式)。
- Index: Hudi维护一个索引来快速将传入的记录键映射到fileId,如果记录键已经存在。索引实现是可插拔的,以下是当前可用的选项:
-
存储在每个数据文件页脚中的Bloom过滤器:首选的默认选项,因为它不依赖于任何外部系统。数据和索引总是彼此一致的。
-
Apache HBase:对一小批keys的高效查找。这个选项可能会在索引标记期间节省几秒钟的时间。
- 数据:Hudi以两种不同的存储格式存储所有输入的数据。实际使用的格式是可插拔的,但基本上需要以下特征:
-
扫描优化的柱状存储格式(ROFormat)。默认为Apache Parquet。
-
写优化的基于行的存储格式(WOFormat)。默认是Apache Avro。

图5:Hudi存储内部。上面的Hudi Storage图描述了一个YYYYMMDDHHMISS格式的提交时间,可以简化为HH:SS。
优化
Hudi存储针对HDFS的使用模式进行了优化。压缩是将数据从写优化格式转换为扫描优化格式的关键操作。由于压缩的基本并行单元是重写单个fileId,所以Hudi确保所有数据文件都以HDFS块大小文件的形式写出来,以平衡压缩并行性、查询扫描并行性和HDFS中的文件总数。压缩也是可插拔的,可以对其进行扩展,以弥补较旧的、更新频率较低的数据文件,从而进一步减少文件总数。
摄取路径
Hudi是一个Spark库,目的是作为流摄取作业运行,并以小批量(通常是一到两分钟的顺序)摄取数据。然而,根据延迟需求和资源协商时间,摄取作业也可以使用Apache Oozie或Apache airflow作为计划任务运行。
下面是带有默认配置的Hudi摄入的写路径:
-
Hudi从所涉及的分区(意思是,从输入批处理分散开来的分区)中的所有parquet文件加载Bloom过滤器索引,并通过将传入的键映射到现有文件以进行更新,将记录标记为更新或插入。这里的联接可能在输入批处理大小、分区分布或分区中的文件数量上发生倾斜。它是通过在join键上执行范围分区和子分区来自动处理的,以避免Spark中对远程shuffle块的2GB限制。
-
Hudi组每个分区插入,分配一个新的fileId,并附加到相应的日志文件,直到日志文件达到HDFS块大小。一旦达到块大小,Hudi将创建另一个fileId,并对该分区中的所有插入重复此过程。
-
调度程序每隔几分钟就会启动一个有时间限制的压缩过程,它会生成一个优先级排序的压缩列表,并使用当前的parquet文件压缩fileId的所有avro文件,以创建该parquet文件的下一个版本。
-
压缩是异步运行的,锁定被压缩的特定日志版本,并将对该fileId的新更新写入新的日志版本。在Zookeeper中获取锁。
-
压缩是根据被压缩的日志数据的大小进行优先级排序的,并且可以通过压缩策略插入。在每次压缩迭代中,日志量最大的文件首先压缩,而小的日志文件最后压缩,因为重写parquet文件的成本不会分摊到文件更新的次数上。
-
-
如果有一个文件存在,Hudi会将fileId的更新追加到它相应的日志文件中;如果没有,则会创建一个日志文件。
-
如果摄取作业成功,则在Hudi元时间轴中记录一次提交,这将自动地将inflight文件重命名为提交文件,并写出关于分区和创建的fileId版本的详细信息。
相关优化
如前所述,Hudi努力使文件大小与底层块大小对齐。根据柱状压缩的效率和要压缩的分区中的数据量,压缩仍然可以创建小的parquet文件。这最终会在下一次的摄取迭代中自动修正,因为对分区的插入被打包为对现有小文件的更新。最终,文件大小将增长到压缩后的底层块大小。
失败恢复
当由于间歇性错误导致摄取任务失败时,Spark会重新计算RDD并进行自动解析。如果失败的数量超过Spark中的maxRetries,则摄取作业失败,下一次迭代将再次重试摄取相同的批。以下是两个重要的区别:
-
导入失败会在日志文件中写入部分avro块。
- 这是通过在提交元数据中存储关于块和日志文件版本的开始偏移量的元数据来处理的。在读取日志时,跳过不相关的、有时是部分写入的提交块,并在avro文件上适当地设置了seek位置。
-
压缩失败可能会写入部分拼parquet文件。
- 这是由查询层处理的,它根据提交元数据过滤文件版本。查询层只会为最后完成的压缩挑选文件。下一个压缩迭代将回滚失败的压缩并再次尝试。
查询路径
commit meta timeline使能够在hdfs上的相同数据同时做读优化视图和实时视图;这些视图允许客户端在数据延迟时间和查询执行时间之间进行选择。Hudi为这些视图提供了一个自定义的InputFormat,并包括一个Hive注册模块,该模块将这两个视图注册为Hive metastore表。这两种输入格式都理解fileId和提交时间,并过滤文件,只选择最近提交的文件。然后,Hudi对这些数据文件进行分割,以运行查询计划。InputFormat的详细内容如下:
-
HoodieReadOptimizedInputFormat:提供一个扫描优化的视图,它过滤掉所有日志文件,只选择压缩的parquet文件的最新版本。
-
HoodieRealtimeInputFormat:提供一个更实时的视图,除了选择压缩的parquet文件的最新版本外,还提供了一个RecordReader,以便在扫描期间将日志文件与相应的parquet文件合并。
这两个InputFormats都扩展了MapredParquetInputFormat和VectorizedParquetRecordReader,因此读取parquet文件所做的所有优化仍然适用。Presto和SparkSQL在Hive metastore表上可以开箱即用,只要所需的hoodie-hadoop-mr库在classpath中。

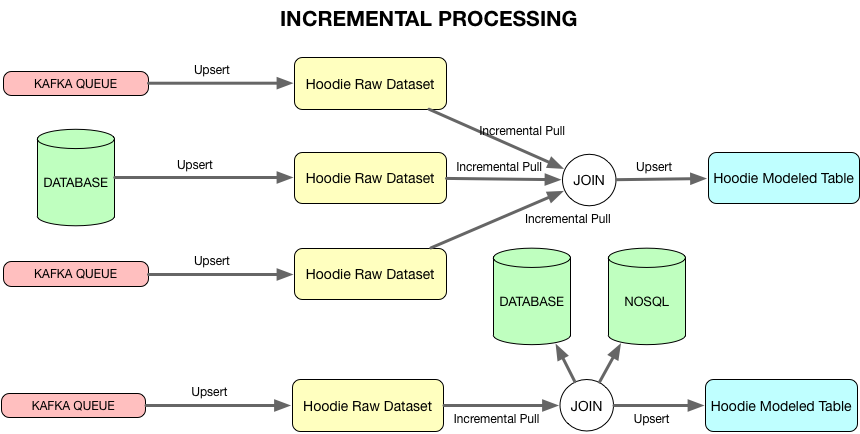
增量处理
如前所述,建模的表需要在HDFS中处理和服务,以便HDFS成为统一的服务层。构建低延迟模型表需要链化HDFS数据集的增量处理能力。由于Hudi维护关于提交时间和为每个提交创建的文件版本的元数据,增量变更集可以在开始时间戳和结束时间戳内从特定于Hudi的数据集中提取。
这过程以同样的方式作为一个正常查询,除了特定的文件版本,查询时间范围内而不是最新版本,和一个额外的谓词的提交时间推到文件扫描检索只在请求的持续时间改变的记录。可以获得更改集的持续时间是由可以保留多少个未清理的数据文件版本决定的。
这使得带有水印的流到流连接和流到数据集连接能够在HDFS中计算和插入建模的表。
关于当前版本的Hudi
本文中描述的大多数技术都是指Hudi的当前一代(称为“读时合并”),该技术仍在积极开发中。在接下来的几个月里,Hudi将取代上一代(称为“写时复制”)存储系统。上一代通过消除日志文件和降低延迟来简化体系结构。几个月来,这一直在为优步的数据获取和表格建模提供动力。
随着Hudi继续推动延迟的边界,以更快地在HDFS中吸收,在我们向外扩展时,不可避免地会有一些识别瓶颈的迭代。我们打算研究的一些潜在瓶颈与嵌入式全局不可变索引加速索引和设计自定义可索引日志存储格式有关,以优化磁盘寻址合并。因此,我们欢迎您的反馈,并鼓励您为我们的项目做出贡献。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/1954/