
消息在系统中传输所需的时间对 Apache Kafka® 等分布式系统的性能起着重要作用。 在 Kafka 中,生产者的延迟通常定义为客户端生成的消息被 Kafka 确认所需的时间。 正如一句老话所说,时间就是金钱,为了让系统运行得更快,最好尽可能减少延迟。 当生产者能够更快地发送消息时,整个系统都会受益。
每个 Kafka 主题包含一个或多个分区。 当Kafka生产者向主题发送记录时,它需要决定将其发送到哪个分区。 如果我们大约同时向同一个分区发送多条记录,它们可以作为一个批次发送。 处理每个批次需要一些开销,批次内的每条记录都会产生该成本。 小批量的记录具有更高的每条记录有效成本。 通常,较小的批次会导致更多的请求和排队,从而导致更高的延迟。
批处理在达到特定大小 (batch.size) 或经过一段时间 (linger.ms) 后完成。 batch.size 和 linger.ms 都是在生产者中配置的。 batch.size 的默认值为 16,384 字节,linger.ms 的默认值为 0 毫秒。 一旦达到 batch.size 或至少 linger.ms 时间过去,系统将尽快发送批次。
乍一看,似乎将 linger.ms 设置为 0 只会导致生成单记录批次。 然而,通常情况并非如此。 即使 linger.ms 为 0,生产者也会在大约同时将记录生产到同一分区时将记录分组。 这是因为系统需要一点时间来处理每个请求,并且在系统无法立即处理它们时会批量形成。
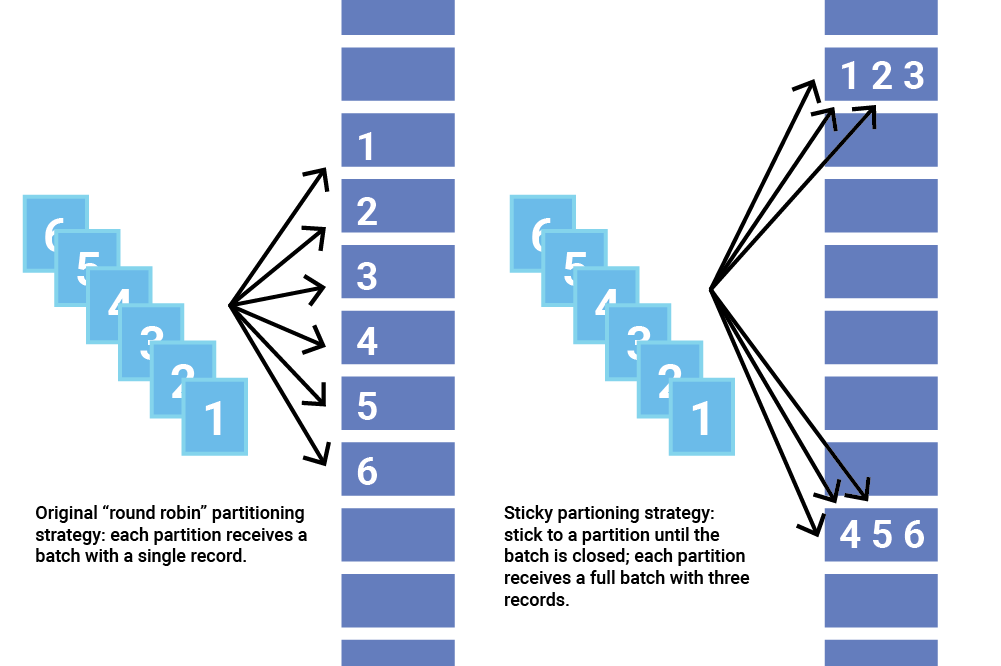
决定批次如何形成的部分原因是分区策略; 如果记录不发送到同一个分区,它们不能一起形成一个批处理。 幸运的是,Kafka 允许用户通过配置 Partitioner 类来选择分区策略。 Partitioner 为每条记录分配分区。 默认行为是散列记录的键以获取分区,但某些记录的键可能为空。 在这种情况下,Apache Kafka 2.4 之前的旧分区策略是循环遍历主题的分区并向每个分区发送一条记录。 不幸的是,这种方法不能很好地批处理,实际上可能会增加延迟。
由于小批量可能会增加延迟,因此使用空键对记录进行分区的原始策略可能效率低下。 这在 Apache Kafka 2.4 版中发生了变化,它引入了粘性分区,这是一种将记录分配给已证明具有较低延迟的分区的新策略。
Sticky partitioning strategy
粘性分区器通过选择单个分区来发送所有非键记录,解决了将没有键的记录分散成较小批次的问题。 一旦该分区的批次被填满或以其他方式完成,粘性分区程序会随机选择并“粘”到一个新分区。 这样,在更长的时间内,记录大致均匀地分布在所有分区中,同时获得更大批量的额外好处。

Basic tests: Producer latency
量化我们的性能改进的影响很重要。 Apache Kafka 提供了一个名为 Trogdor 的测试框架,它可以运行不同的基准测试,包括测量生产者延迟的基准测试。 我使用名为 Castle 的测试工具使用 small_aws_produce.conf 的修改版本运行 ProduceBench 测试。 这些测试使用了三个brokers和 1-3 个生产者,并在带有 SSD 的 Amazon Web Services (AWS) m3.xlarge 实例上运行。
包含的大多数测试都按照以下规范运行,您可以通过使用此示例任务规范替换默认任务规范来修改 Castle 规范。 一些测试运行的设置略有不同,下面提到了这些。
| Duration of test | 12 minutes |
| Number of brokers | 3 |
| Number of producers | 1–3 |
| Replication factor | 3 |
| Topics | 4 |
linger.ms |
0 |
acks |
all |
keyGenerator |
{"type":"null"} |
useConfiguredPartitioner |
true |
No flushing on throttle (skipFlush) |
true |
为了获得最佳比较,将 taskSpecs 中的 useConfiguredPartitioner 和 skipFlush 字段设置为 true 很重要。 这确保分区分配有 DefaultPartitioner,并且批次不是通过刷新而是通过填充批次或 linger.ms 触发发送。 当然,您应该将 keyGenerator 设置为仅生成空键。
在几乎所有将原始 DefaultPartitioner 与新改进的粘性版本进行比较的测试中,后者(粘性)的延迟与原始 DefaultPartitioner(默认)相同或更少。 当将具有 3 个每秒产生 1,000 条消息的集群的第 99 个百分位 (p99) 延迟与具有 16 个分区的主题进行比较时,粘性分区策略的延迟约为默认策略的一半。 以下是三个运行的结果:
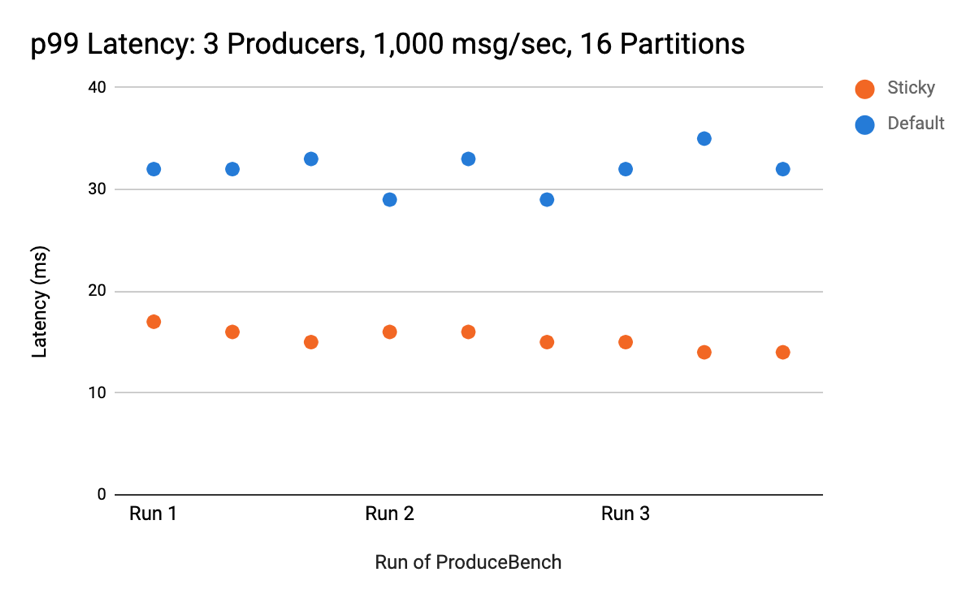
随着分区的增加,延迟的减少变得更加明显,这与一些大批量比许多小批量导致更低延迟的想法一致。 差异很明显,只有 16 个分区。
下一组测试保持三个生产者每秒生产 10,000 条消息不变,但增加了分区数量。 下图显示了 16、64 和 128 个分区的结果,表明默认分区策略的延迟以更快的速度增加。 即使在有 16 个分区的情况下,默认分区策略的平均 p99 延迟也是粘性分区策略的 1.5 倍。
使用不同键进行延迟测试和性能测试
如前所述,等待 linger.ms 可能会给系统注入延迟。 粘性分区程序旨在通过将所有记录发送到一个批次并可能更早地填充它来防止这种情况。 在吞吐量相对较低的情况下使用 linger.ms > 0 的粘性分区程序可能意味着延迟的惊人减少。 当使用一个每秒发送 1,000 条消息且 linger.ms 为 1,000 的生产者运行时,默认分区策略的 p99 延迟是五倍。 下图显示了 ProduceBench 测试的结果。
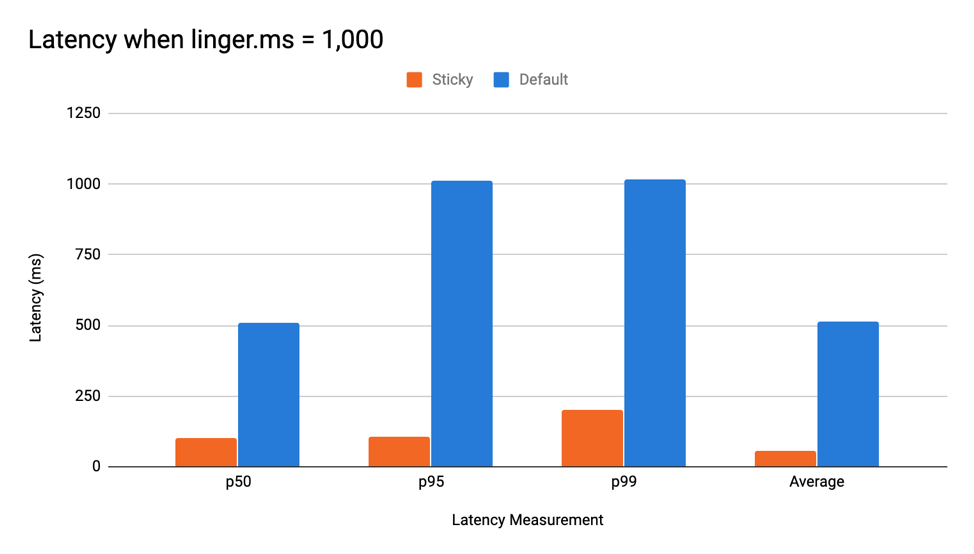
粘性分区器有助于提高客户端在生成无密钥消息时的性能。但是当生产者生成无密钥和有密钥消息的混合时,它是如何执行的呢?使用随机生成的密钥以及混合密钥和无密钥的测试表明延迟没有显着差异。
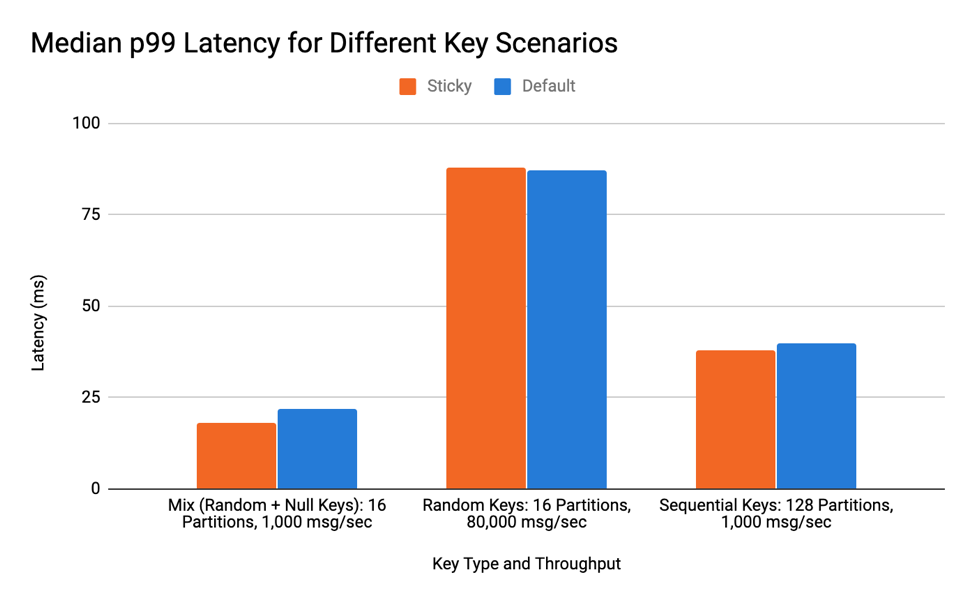
在这种情况下,我检查了随机键和空键的混合。这会看到稍微好一点的批处理,但由于键控值忽略了粘性分区器,所以好处不是很明显。下图显示了三个运行的中值 p99 延迟。在测试过程中,延迟没有显着差异,因此中位数提供了“典型”运行的准确表示。
测试的第二个场景是高吞吐量情况下的随机密钥。由于实现粘性分区器稍微改变了代码,重要的是要看到运行一些额外的逻辑不会影响产生的延迟。由于此处没有发生粘性行为或批处理,因此延迟与默认值大致相同是有道理的。随机密钥测试的中值结果如下图所示。
最后,我测试了我认为对于粘性分区实现最糟糕的场景——具有大量分区的顺序键。由于在创建新批次的时间附近会出现额外的逻辑位,并且此场景几乎在每条记录上都创建了一个批次,因此检查这是否不会导致延迟增加至关重要。如下图所示,没有显着差异。
CPU utilization for producer bench tasks
在执行这些基准测试时,需要注意的一件事是粘性分区程序在许多情况下会降低 CPU 使用率。
例如,当运行三个生产者每秒向 16 个分区产生 10,000 条消息时,观察到 CPU 使用率显着下降。 下图中的每条线代表节点使用的 CPU 百分比。 每个节点既是生产者又是经纪人,节点的行是叠加的。 在具有更多分区和更低吞吐量的测试中可以看到 CPU 的这种减少。

Sticking it all together
粘性分区器的主要目标是增加每批中的记录数,以减少批次总数并消除多余的排队。 当每个批次中有更多记录的批次较少时,每条记录的成本较低,并且使用粘性分区策略可以更快地发送相同数量的记录。 数据显示,在使用空键的情况下,这种策略确实减少了延迟,并且当分区数量增加时效果会更加明显。 此外,使用粘性分区策略时,CPU 使用率通常会降低。 通过坚持分区并发送更少但更大的批次,生产者看到了巨大的性能改进。
最好的部分是:这个生产者只是内置在 Apache Kafka 2.4 中!
原文链接:https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner/
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/2430/