
举个例子
对象创建是OOP中最基本的操作。即使在最微不足道的用例中,也很难计算我们创建的对象的数量(有意或幕后)。
每个对象都是在堆上创建的,在垃圾收集之前都会占用一些空间。长时间运行的程序会占用堆。类似地,同时运行的线程将成倍增加所使用的内存。
下面举一个简单的例子:
我有一个应用程序,它返回给我大量的数据点来绘制一个图表。数据点包含两个信息——数据和该点在图上的样子:
public class DataPoint {
private double data;
private Point point;
public DataPoint(double data, Point point) {
this.data = data;
this.point = point;
}
public void setData(double data) {
this.data = data;
}
public void setPoint(Point point) {
this.point = point;
}
public double getData() {
return data;
}
public Point getPoint() {
return point;
}
}每个点含有形状和颜色信息:
public class Point {
private String color;
private String shape;
public Point(String color, String shape) {
this.color = color;
this.shape = shape;
}
public void setColor(String color) {
this.color = color;
}
public void setShape(String shape) {
this.shape = shape;
}
public String getColor() {
return color;
}
public String getShape() {
return shape;
}
}现在来随机产生一些数据点:
public class Main {
public static void main(String[] args) {
int N = 10;
DataPoint[] dp = new DataPoint[N];
for(int i=0; i<N; i++) {
double data = Math.random(); // or whatever data source
Point point = data > 0.5 ? new Point("Green", "Circle") : new Point("Red", "Cross");
dp[i] = new DataPoint(data, point);
}
System.out.println(N);
}
}
看起来简单,工作很好。让我们看看在创建这个DataPoint数组时使用的内存数量。
idea中在输出部分打断点进行调试:

导出进程的内存使用情况
使用jhat进行分析,打开localhost:7000
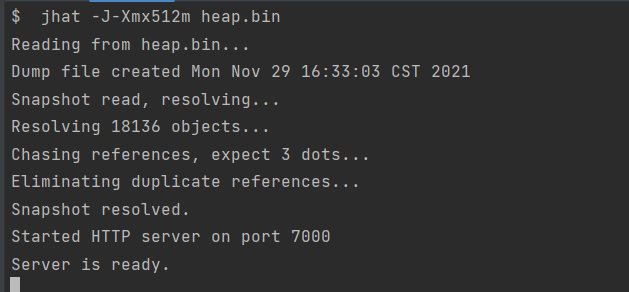
可以发现每个DataPoint对象占用的内存为32 bytes

而DataPoint中的Point同样占用 32bytes

所以说,一个DataPoint对象占用32 bytes,DataPoint中的Point同样占用32 bytes,总内存占用为(32+32)N = 64N bytes,当然,我们上述设置的N为10,如果N为1000那么就占用64KB,如果是100个线程,那么就占用了6.4MB.
有什么问题
实际上只有两种不同的点——绿圆和红十字,但我们创建了N点对象。
使用享元模式解决上述问题
我们可以发现在上述问题中,其实最大的问题就是冗余,我们需要避免冗余值。为此,我们定义如下两个关键名词:
-
重复属性——对象的多个实例中可能保持相同的属性。
-
唯一属性——随着对象的每个实例而改变的属性。
在我们的场景中,数据点对象的每一半都包含相同的point值(概率地)。享元模式告诉我们对象中可能大量重复的部分,应该使用共享或者重用的模式,而不是重复,特别针对如下场景:
-
重复属性特别多,比如本例子中Point对象。
-
重复属性可以接受的值数量有限。比如说布尔类,它只能接受true或false两个值。
有很多方法可以实现这一点。让我们看看实现享元模式的几种方法。
使用静态工厂
我们为Point对象的两个可能实例分别公开一个静态工厂方法。我们分别对Point和Main进行如下修改:
class Point {
private String color;
private String shape;
private static Point GREEN_CIRCLE = new Point("Green", "Circle");
private static Point RED_CROSS = new Point("Red", "Cross");
private Point(String color, String shape) {
this.color = color;
this.shape = shape;
}
public static Point getGreenCircle() {
return GREEN_CIRCLE;
}
public static Point getRedCross() {
return RED_CROSS;
}
}public class Main {
public static void main(String[] args) {
int N = 10;
DataPoint[] dp = new DataPoint[N];
for(int i=0; i<N; i++) {
double data = Math.random(); // or whatever data source
Point point = data > 0.5 ? Point.getGreenCircle() : Point.getRedCross();
dp[i] = new DataPoint(data, point);
}
System.out.println(N);
}
}
同样我们分析一下内存使用情况:


我们可以发现,DataPoint引用的Point在整个程序中只占用64 bytes,其不会随着DataPoint的增长而增长。那么总的内存占用为:(32N+64)bytes
使用枚举类
我们对程序进行如下修改:
enum Point {
GREEN_CIRCLE("Green", "Circle"),
RED_CROSS("Red", "Cross");
private final String color;
private final String shape;
Point(String color, String shape) {
this.color = color;
this.shape = shape;
}
}同样我们分析一下内存使用情况:

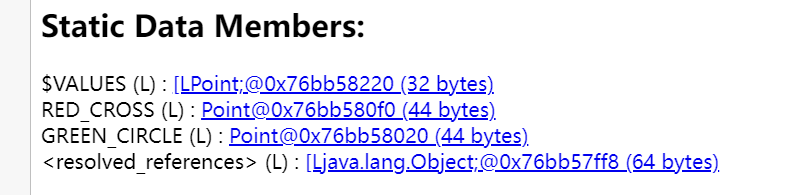
同样,DataPoint引用的Point在整个程序中只占用120bytes,其不会随着DataPoint的增长而增长。那么总的内存占用为:(32N+120)bytes
很明显,静态工厂和枚举都只会创建2个Point对象的副本,不管DataPoint重复多少次。
缓存
以上两个例子在所有变量都已知的情况下运行得很好。另一种情况是,其中一个字段可以获得比预期更多的值。但是,除非变化的字段发生变化,否则对象的其他值不会发生变化。
让我们举一个不同的例子。假如我们的Point是一个动态变化的值,其有一个id属性用于唯一确定其属性,由于其有限性,我们可以先判断来的数据中是否是已知的Point值,如果没有则缓存,有则使用原来的Point。
class PointCache {
public static Map<String, Point> pointMap = new HashMap<>();
public Point getPoint(String pointId) {
Point point;
if(pointMap.containsKey(pointId)) {
point = pointMap.get(pointId);
} else {
point = new Point(/*properties*/);
pointMap.put(pointId, point);
}
return point;
}
}一旦我们创建了Point对象,我们就会根据它的唯一id将其缓存到映射中,这样我们就不会再初始化相同的Point。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/2553/