
背景
我们在使用Flink开发实时任务时,都会用到框架本身提供的DataStream API,这使得用户不能不用Java或者Scala甚至Python来编写业务逻辑;这种方式虽然灵活且表达性强,但对用户具有一定的开发门槛,并且随着版本的不断更新,DataStream API也有很多老版本不兼容的问题。所以Flink SQL就成了广大开发用户的最佳选择,之所以Flink推出SQL API,主要是因为SQL有如下几个重要特性:


- 声明式API:用户只关心做什么,而不关心怎么做;
- 自动优化:屏蔽底层API的复杂性,自动做优化;
- 简单易懂:SQL应用于不同行业和领域,学习成本较低;
- 不易变动:语法遵循SQL标准规范,不易变动;
- 流批统一:同样的SQL代码,可以用流和批的方式执行。
虽然Flink提供了SQL能力,但还是有必要基于Flink SQL打造属于自己的平台,目前搭建SQL平台的方式有如下几种:
- Flink原生API:使用Flink提供的SQL API,封装一个通用的pipeline jar,利用flink shell脚本工具提交sql任务;
- Apache Zeppelin:一款开源产品,利用notebook方式管理sql任务,目前已经与Flink集成,且提供了丰富的SDK;
- Flink Sql Gateway:Flink官方出品的一个Sql网关,用Rest方式执行Flink Sql。
第一种方式缺乏灵活性,且大量提交任务时,有性能瓶颈;而Zeppelin虽然功能强大,但页面功能有限,如果要基于Zeppelin打造SQL平台,要么使用SDK,要么对Zeppelin做重度的二次开发;所以Flink Sql Gateway比较适合做平台化建设,因为它是一个独立的网关服务,方便与公司现有系统集成,完全与其它系统解耦,本文也主要阐述Flink Sql Gateway的实践与探索。
Flink Sql Gateway 简介
架构

如上图所示,Flink Sql Gateway的架构比较简单,主要组件是SqlGatewayEndpoint,它是基于Flink的RestServerEndpoint实现的一个Netty服务,通过自定义实现多种handler来完成sql任务的创建和部署,以及管理的能力。SqlGatewayEndpoint内部主要由SessionManager(会话管理)组成,SessionManager维护了一个session map,而session内部主要是一些上下文配置和环境信息。
- SqlGatewayEndpoint:基于RestServerEndpoint实现的Netty服务,对外提供Rest Api;
- SessionManager :会话管理器,管理session创建与删除;
- Session:一个会话,里面存放着任务所需要的Flink配置和上下文环境信息,负责任务的执行;
- Classpath:Flink Sql Gateway启动时会加载flink安装目录的classpath,所以flink sql gateway 基本上没有除flink以外的相关依赖。
执行流程
sql gateway其实只是一个普通的NIO服务器,每个Handler都会持有SessionManager的引用,因此可以共同访问同一个SessionManager对象。当请求到达时,Handler会获取请求中的参数,如SessionId等,去SessionManager中查询对应的Session,从而执行提交sql、查询任务状态等工作。请求流程如下图所示:

创建 session,这是使用sql gateway的第一步,SessionManager会把用户传入的任务执行模式、配置、planner引擎方式等参数封装成Session对象,放入map中,并返回sessionid给用户;
用户持有sessionid,发起sql request的请求,gateway根据sessionid找到对应的Session对象,开始部署sql job到yarn / kubernetes;
功能
任务部署
Flink Sql Gateway作为Flink的客户端,任务部署直接运用了Flink的能力,而 Flink目前支持三种部署模式:
- in Application Mode,
- in a Per-Job Mode,
- in Session Mode。
三种模式有如下两个区别:
集群生命周期和资源隔离:
per-job mode的集群生命周期与job相同,但有较强的资源隔离保证。
应用程序的main()方法是在客户端还是在集群上执行:
session mode和per-job mode在客户端上执行,而application mode在集群上执行。

从以上可以看出,Application Mode为每个应用程序创建一个会话集群,并在集群上执行应用程序的 main() 方法,所以它是session mode和per-job的一个折中方案。
目前为止,Flink只支持jar包任务的application mode,所以想要实现sql任务的application mode,需要自己改造实现,后面会讲实现方法。
SQL 能力
Flink Sql Gateway支持的Sql语法如下:

Flink Sql Gateway支持所有Flink Sql语法,但本身也有一些限制:
- 不支持多条sql执行,多条insert into执行会产生多个任务;
- 不完整的set支持,对于set语法支持存在bug;
- Sql Hit支持不是很友好,写在sql里比较容易出错。
平台化改造
SQL 的 application mode 实现
前面说到,flink不支持sql任务的application mode部署,只支持jar包任务。jar 包任务的application mode实现如下图所示:

- flink-clients解析出用户的配置和jar包信息;
- ApplicationConfiguration里指定了main方法的入口类名和入参;
- ApplicationDeployer负责把Jobmanager启动,并且启动时执行Flink Application的main方法。
通过以上流程可以看出,要实现sql的application mode,实现通用执行sql的pipeline jar是关键:
实现一个执行sql的通用pipeline jar包,并且预先传到yarn或者k8s,如下所示:

在ApplicationConfiguration中指定
pepeline jar的main方法入口和参数:

多 Yarn 集群支持
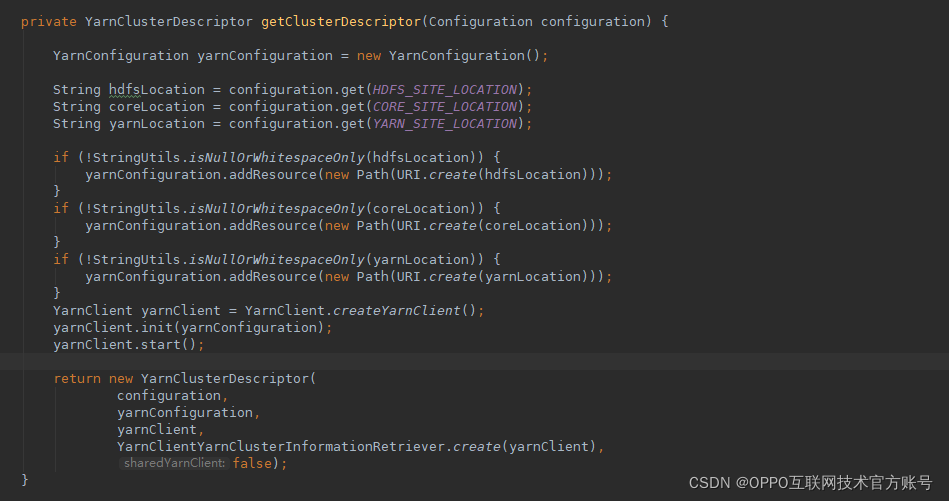
目前Flink只支持单Yarn环境的任务部署,对于拥有多套Yarn环境的场景,需要部署多套Flink环境,每个Flink对应一个Yarn环境配置;虽然这种方式能解决问题,但并不是最优的解决方案。熟悉Flink应该都知道,Flink使用 ClusterClientFactory的SPI来生成与外部资源系统(Yarn/kubernetes)的访问介质(ClusterDescriptor),通过ClusterDescriptor可以完成与资源系统的交互,比如YarnClusterDescriptor,它持有YarnClient对象,可以完成与Yarn的交互;所以对于多Yarn环境,我们只要保证YarnClusterDescriptor 里持有的YarnClient对象与Yarn环境一一对应即可,代码如下图所示:
作者简介
Zheng OPPO高级数据平台工程师
主要负责基于Flink的实时计算平台开发, 对Flink有较丰富的研发经验, 也曾参与过Flink社区的贡献。
本文转载自OPPO互联网技术官方账号,原文链接:https://blog.csdn.net/weixin_59152315/article/details/121976257。