
引言
Flink 在大数据流处理方面具有高吞吐、低延迟等优势,其作为微信大数据平台 Gemini-2.0 的实时流计算引擎,支撑了微信实时推荐、实时数仓、实时风控等多个业务场景的应用。
Gemini-2.0 是微信内部的云原生大数据平台,构建在腾讯云 TKE 容器平台之上,为微信各业务提供大数据及 AI 计算的基础支撑,主要具备如下特性:
– 计算存储完全分离
– 大数据及AI计算框架的统一编排调度
– 优化后的高性能计算组件
– 灵活高效的扩展能力
随着微信业务的飞速发展,大数据应用已经全面走向实时化,业务对流计算引擎的稳定性及性能有更高的要求。微信内部早在 2020 年开始就基于 Flink on K8S 深入打造了云原生、高性能、稳定可靠的实时计算平台,支撑了微信各业务的快速发展。在业务实践及运营过程中,我们发现绝大部分非业务逻辑原因引发的稳定性问题主要有两类:1)因为机器宕机、网络抖动等原因导致作业重启;2)因为调度不均衡导致作业局部反压以及 OOM 等。本文主要介绍微信内部针对这两类问题在内核及应用层的优化实践。
1. 局部故障恢复
1.1 问题
-
Region:只重启涉及失败 Task 的最小连通执行子图
-
Full:重启整个执行图
其中 Region 恢复策略本意也是最小化重启影响的 Tasks,但是考虑数据完整性,它必须连带把失败 Task 的上下游一起取消重启,再借助 Checkpoint 机制进行数据回放,所以只有在执行图非全连通情况下才能做到局部重启,具体表现如下图所示。但是大部分业务场景下,一个 Job 的执行图是全连通的,如下图最右边示例,这就退化成 Full 恢复策略了,实际表现就是牵一发动全身,故障恢复时间较长,数据监控曲线出现断流掉 0 现象。


针对该问题,业界其实也有一些讨论及方案,社区有一个重大特性提案 FLIP-135 就是尝试做有损的快速故障恢复,试图针对单个 Task 故障做快速恢复,从2020年8月提出,之后就没有推进下去。事实上,实际运营中,我们发现绝大部分局部故障都是因为 TaskManager 失联导致的,主要是因为节点宕机、网络抖动、OOM-Kill 等引发,为此,我们需要探索符合自身平台及业务特点的局部故障恢复策略。
1.2 方案
与社区 FLIP-135 提案不一样,为了应对因为节点宕机、网络抖动等原因引发的 TaskManager 失联,我们实现了一种 TaskManager 故障恢复策略,目的是在有 TaskManager 异常退出情况下,保证其他正常 TaskManager 上的 Tasks 继续运行,并快速批量恢复故障 TaskManager 上的 Tasks,做到故障恢复期间不断流并尽可能降低丢数据的时长,具体表现大致如下图所示。

-
执行层面
-
有 tm 故障时,flink 执行图其余部分正常工作,保证不引发连锁反应
-
失败 tasks 被重新下发运行后,flink 执行图恢复原样
-
控制层面
-
感知 TaskManager 异常,再次调度下发异常 TaskManager 上的 Tasks
1.2.1 执行层面实现
当 TaskManager 故障时,其上面运行的所有 Tasks 会失败,之前通过网络与这些失败 Tasks 连接的上下游 Tasks 会被影响,所以具体实现分为两种情况:1)上游 Task 故障,下游 Task 保持与恢复;2)下游 Task 故障,上游 Task 保持与恢复。
1) 上游失败,下游保持与恢复
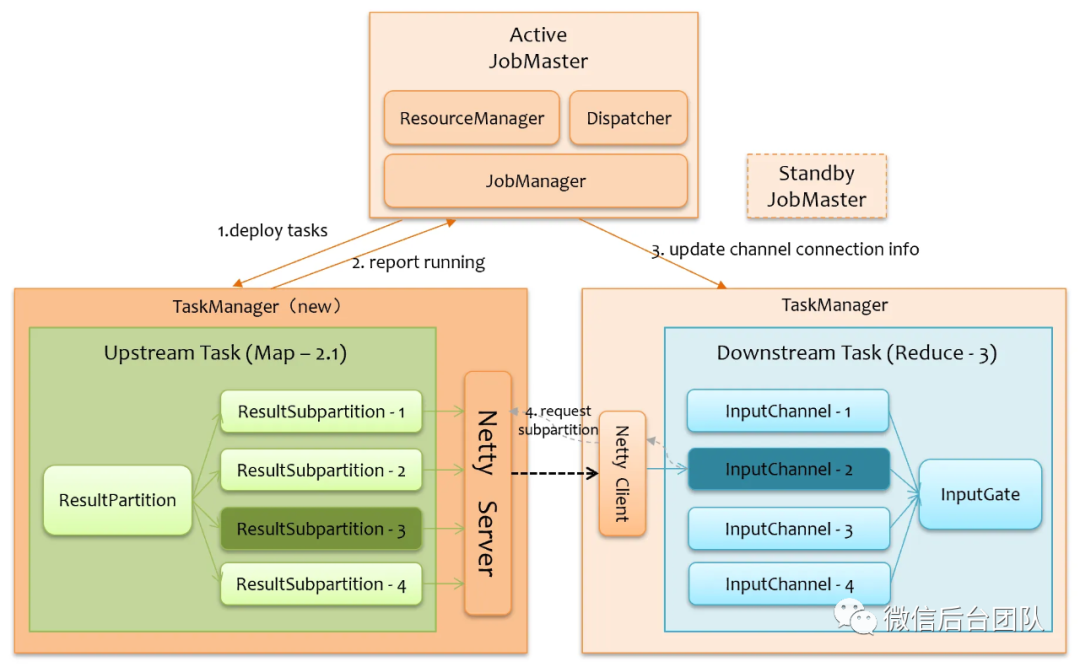
如果是上游失败了,下游会感知到网络连接断开,如下图所示,Flink 会将网络连接异常递交给对应的 InputChannel,当 InputGate 从 InputChannel 拿数据时,会拿到异常进而触发失败。

为了保持住下游,我们实现了新的 InputChannel,当被递交网络连接异常时,它会直接清空其队列中的所有数据,并置为暂停状态,InputGate 不会从暂停状态的 InputChannel 拿数据。如果上游失败的 Task 被重启了,暂停状态的 InputChannel 需要重新恢复连接,如下图所示,JobManager 重新下发上游 Task 后,等其上报运行状态后,由 JobManager 去通知下游,告诉下游 Task 相关新的连接信息,下游 Task 根据新的连接信息,向新的上游发起请求建立数据传输通道,恢复暂停状态的 InputChannel。
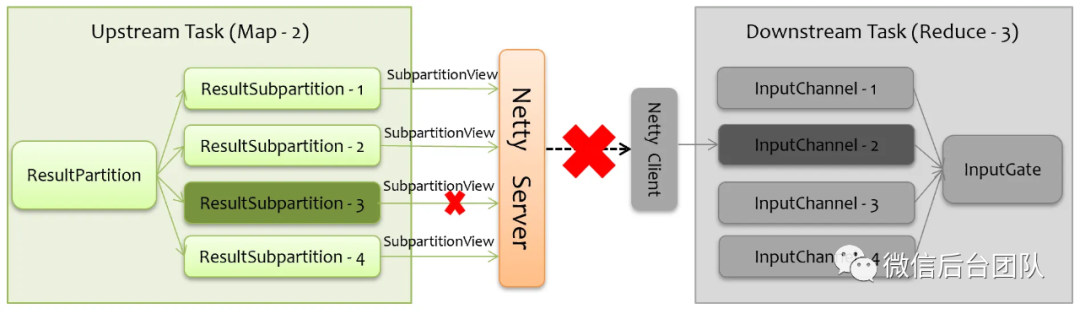
2) 下游失败,上游保持与恢复
如果是下游失败了,上游会感知到网络连接断开,如下图所示,Flink 会将对应的 SubpartitionView 关闭(SubpartitionView 负责读取 Subpartition 的数据),没有了读,ResultSubpartition 中的队列很快会被写满,进而会导致反压。
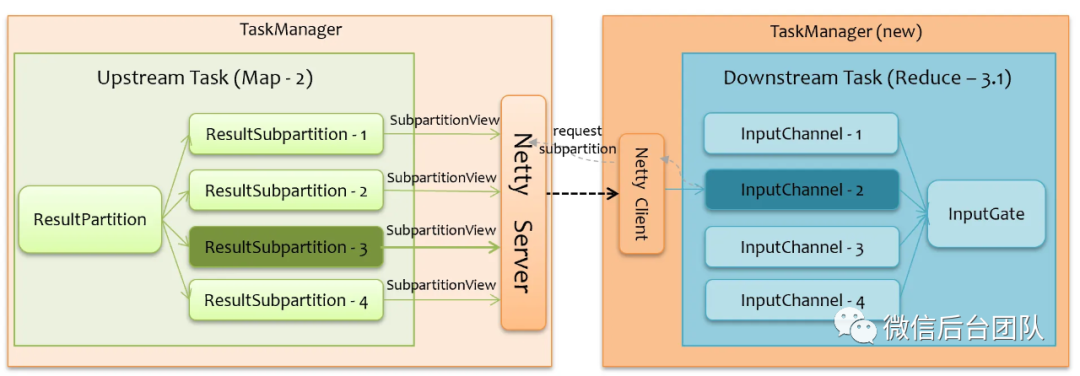
为了保持上游的健康,我们实现了新的 ResultSubpartition 和 SubpartitionView ,当上游感知到网络连接断开时, SubpartitionView 会被关闭,它会进一步去清空 ResultSubpartition 中的队列,并将其置为暂停状态,处于暂停状态的 Subpartition 在被写入数据时会直接丢弃,相当于这期间这一路 Subpartition 是在丢数据的,不然会导致反压。如果下游失败的 Task 被重启了,暂停状态的 Subpartition 恢复写入,如下图所示,因为重新下发下游 Task 时,Task 本身就知道其上游的连接信息,所以不需要 JobManager 介入控制,下游 Task 运行起来后,会主动去连接上游,发起 Subpartition 请求,上游收到请求后,会新建一个 SubpartitionView 并恢复暂停状态的 Subpartition,Subpartition 就会被正常写入数据,SubpartitionView 正常读取。
1.2.2 控制层面实现
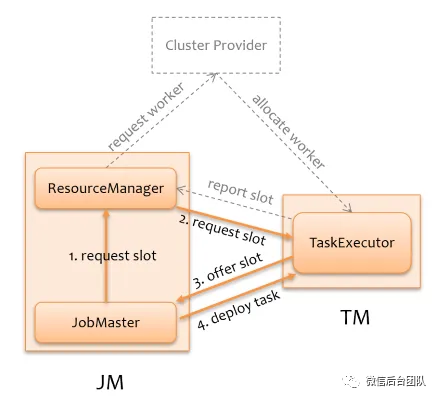
前面提到,当故障时,可以实现上下游不引发连锁反应,恢复还是要靠控制层面这个大脑,控制层面 JobManager 正常情况下在调度下发 Task 前,会从 ResourceManager 申请 Slot 资源,如果资源不足,ResourceManager 会从 Cluster Provider 申请 TaskManager。我们的 Flink 作业是通过 Flink K8S Operator 部署到 K8S 上,如果 TaskManager 异常退出了,K8S 会自动拉起一个新的 Pod 重新运行 TaskManager。所以 JobManager 上的逻辑较简单,只需要负责重新调度故障 TaskManager 上的 Tasks,资源申请逻辑是现成的。具体实现包括两块:
-
故障感知:JM 感知 TM 心跳是否异常
-
异常处理:计算失败的 Tasks,按拓扑排序顺序重新下发
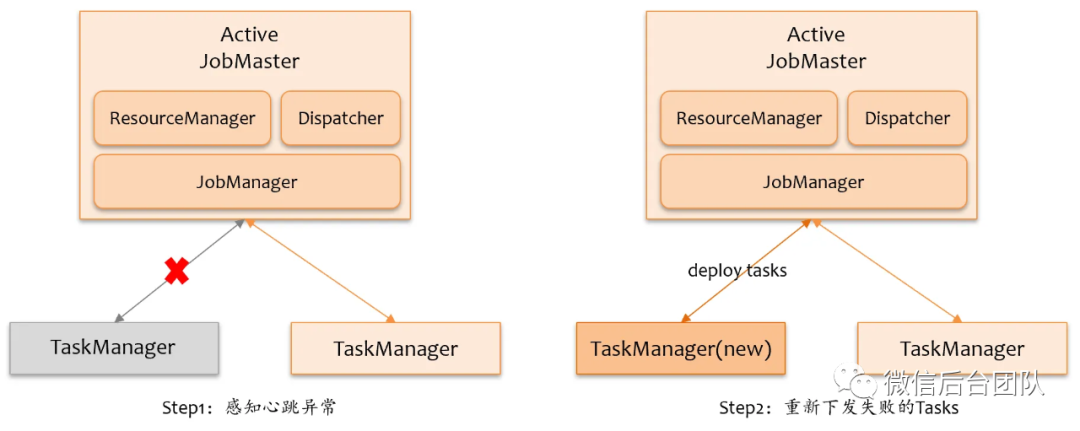
当 JobManager 感知到有 TaskManager 心跳异常时,将异常包装成我们扩展的 TaskManagerLostException,紧接着会进入故障恢复逻辑处理,我们新增了一个 FailoverStrategy 的实现类 RestartTaskManagerFailoverStrategy,它专门针对TaskManagerLostException 类型的异常,只处理异常 TaskManager 上的 Tasks,其他异常,则会退化交给默认的 region 恢复策略处理。
1.3 效果
为了不对 Flink 产生副作用(引入BUG),前面也介绍过,我们是通过实现子类的方式进行扩展,然后通过配置开关决定是否使用我们扩展的故障恢复策略。当前,TaskManager 故障恢复策略仅适用于 Flink 流模式,提交执行的时候会做参数校验。用户使用时只需要带上如下配置即可。
jobmanager.execution.failover-strategy=taskmanager
测试一个由 4 个 TaskManager 运行的简单作业,分别手动杀掉一个 TaskManager 和 两个 TaskManager 的数据消费曲线如下图所示,可以看到 TaskManager 异常时,不会断流(掉0),并在1分钟(JM与TM的心跳时间)左右快速恢复,这对于实时推荐类业务保持实时性是非常有效的。

2. 负载均衡调度优化
2.1 问题

数据源为 64 个分区的 Pulsar Topic,对应 64 个 Slot 处理,FlatMap 和 Sink 因为包含复杂的计算及 IO,需要的并发更大。理想状态是 64 个分区均摊到 16 个 TaskManager 上以保证 Source 端处理的数据量一致。然而实际情况可能如下:
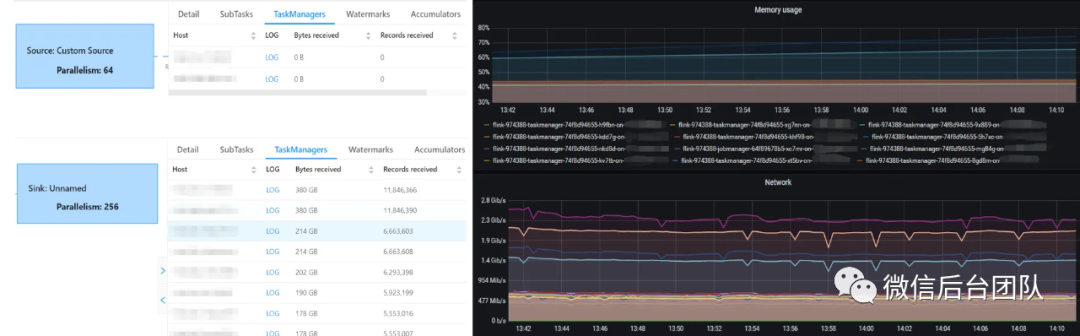
2.2 应用层优化方案
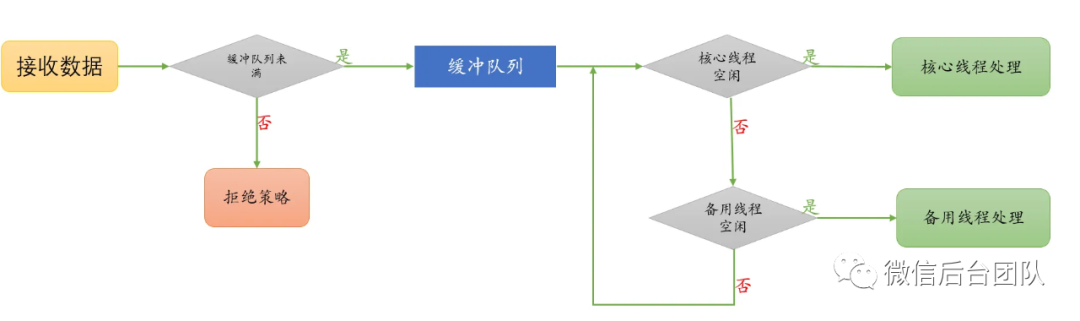
2.3 应用层优化效果
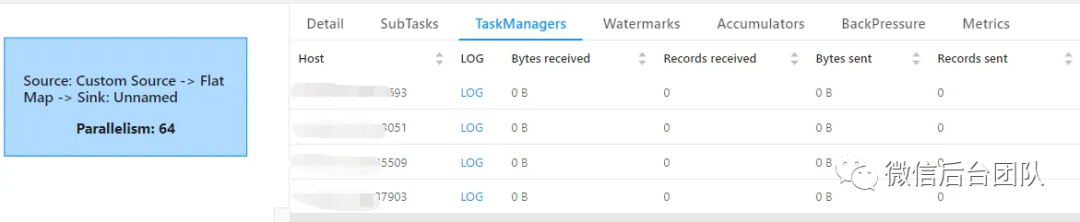
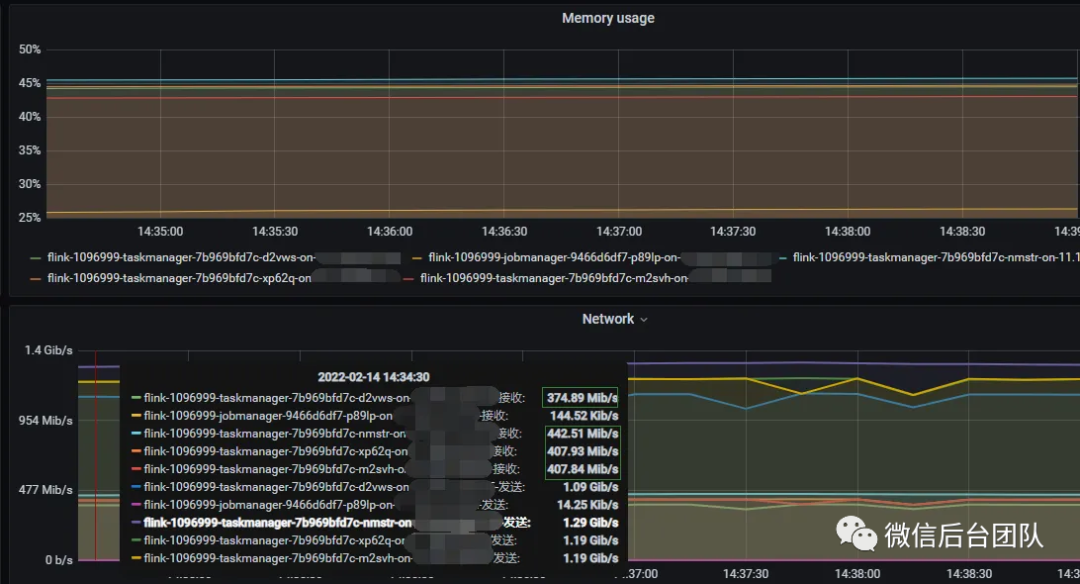
2.4 内核层优化方案
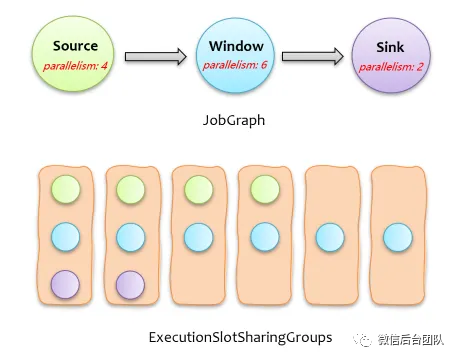
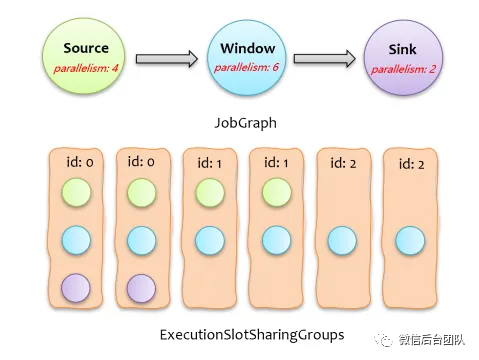
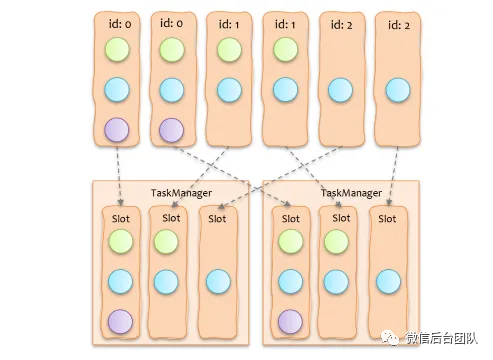
在阐述具体方案前,先通过一个例子简单介绍下社区版 Flink 计算任务分配下发的过程,如下图所示,上面的 JobGraph 在调度下发时,会创建一系列的 ExecutionSlotSharingGroup,每个 ExecutionSlotSharingGroup 包含不同算子的子任务,一个 ExecutionSlotSharingGroup 需要一个 Slot,所以申请 Slot 时,只需按照按 ExecutionSlotSharingGroup 数量来申请即可。
2.5 内核层优化效果
jobmanager.ng-scheduler.balance-match-between-taskmanagers=true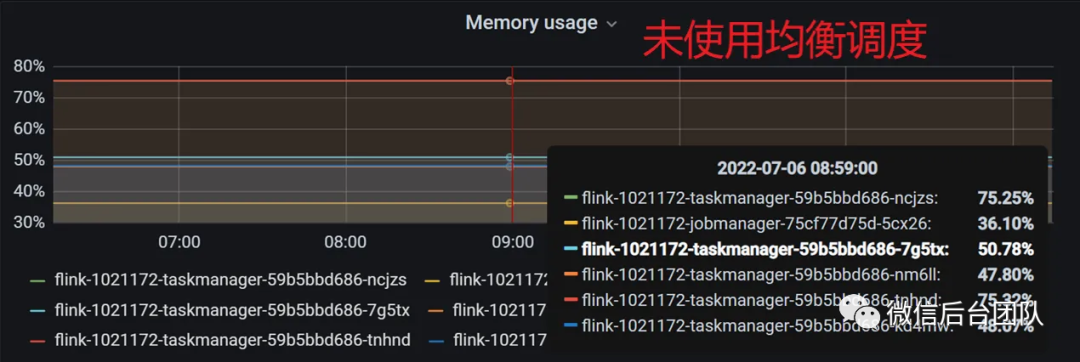

3. 总结
本文主要介绍了微信内部在 Flink 稳定性方面的两个优化:1)在适应实时推荐业务场景下实现了 TaskManager 局部故障恢复策略,目的是应对外部节点宕机、硬件故障、网络抖动等引发的异常退出问题,做到异常时不断流,并快速恢复,保证实时性;2)在调度不均衡问题上探索出了应用层优化方案及内核层优化方案,目的是尽可能使计算任务在各 TaskManagers 上分布均衡,保证作业稳定性并节省资源,其中应用层优化方案需要一定的业务层改造,但是可以降低 Flink 调度的开销,内核层优化方案无需用户改造,用户根据实际需要为不同算子配置并行度即可。
本文转载自微信大数据团队 微信后台团队,原文链接:https://mp.weixin.qq.com/s/kVsyDaGXLG3KWQgX4bAYAg。