
欢迎来到第22期“论文与代码通讯”。本周,我们讨论:
- 语言建模的最新进展,
- 用于样式化 3D 网格的文本驱动方法,
- 3D物体检测的进步,
- 新的最先进的结果,
- 等等
语言建模的最新进展
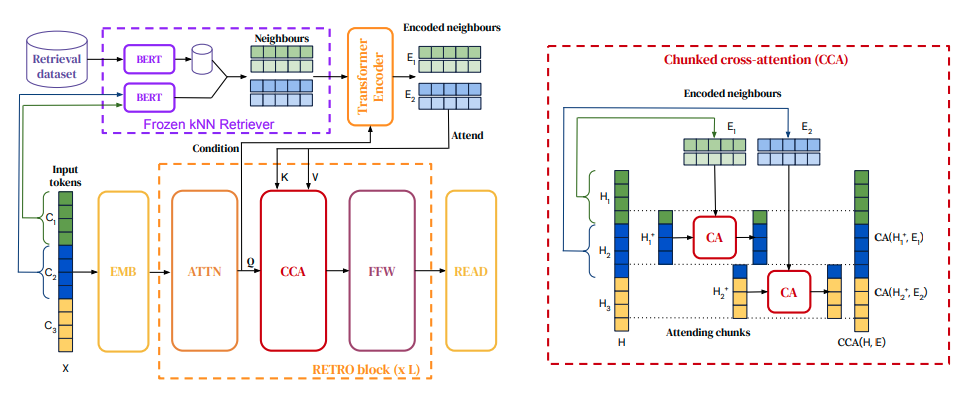

采用基于检索的 NLP 的一系列新方法正在成为提高语言模型能力的有效替代方法。 沿着这些思路,Borgeaud 等人. (2021) 最近提出了 RETRO,这是一种利用 2 万亿token数据库的检索增强型 Transformer。 自回归模型以基于与先前标记的相似性从大型语料库中检索的文档块为条件。 与之前的增强方法(如 REALM)类似,所提出的模型在知识密集型任务(如问答)上表现得特别好。 有关 RETRO 架构的概述,请参见上图。
如果您对这个领域感兴趣,这里有一些值得注意的近期文章供您查看:
- REALM: Retrieval-Augmented Language Model Pre-Training
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Relevance-guided Supervision for OpenQA with ColBERT
- Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval
- End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
语言模型的有效扩展
在效率领域,Du 等人 (2021) 使用稀疏激活的专家混合架构提出了一系列称为 GLaM(通用语言模型:https://paperswithcode.com/paper/glam-efficient-scaling-of-language-models?from=n22)的模型以有效地扩展语言模型。 GLaM 是一个 1.2 万亿参数模型,旨在提高容量的同时大幅降低训练成本。 该模型比 GPT-3 大 7 倍,消耗的能量仅为用于训练 GPT-3 的能量的 1/3,在 29 个 NLP 任务中的zero-shot和one-shot 能均有所提高。
Gopher:一个 2800 亿参数的模型
人们也有兴趣更仔细地研究大规模语言模型的缩放特性和行为。 DeepMind 最近发布了一个名为 Gopher(https://paperswithcode.com/paper/scaling-language-models-methods-analysis?from=n22) 的 2800 亿参数模型,该模型在 152 项不同的任务上进行了评估,范围从阅读理解到逻辑和数学推理。 在阅读理解和事实检查等问题中观察到可扩展性的最大收益,而其他推理任务则收益较小。 这项综合研究旨在对模型的行为和训练数据集进行更深入的分析,同时讨论模型的缩放特性、偏差、缓解和安全性。
使用文本描述对物体进行3D渲染
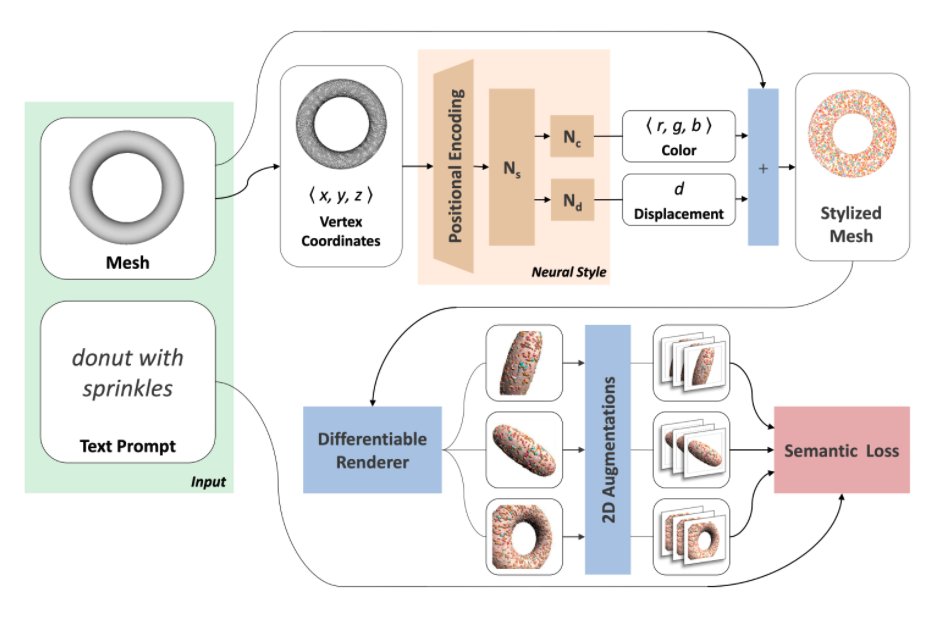
Michel 等人 (2021) 的一篇新论文提出了一个 Text2Mesh框架,它通过预测符合目标文本提示的颜色和几何细节来风格化 3D 网格。 通过渲染多个视图并应用 CLIP 嵌入的 2D 增强来优化神经风格网络的权重。
如上图所示,渲染和增强图像与目标文本之间的 CLIP 相似度被用作更新神经网络权重的信号。 该模型能够生成各种不同的局部几何位移,以合成各种风格。 该系统还能够生成域外风格化输出。 详细介绍:https://threedle.github.io/text2mesh/
三维物体检测的进展
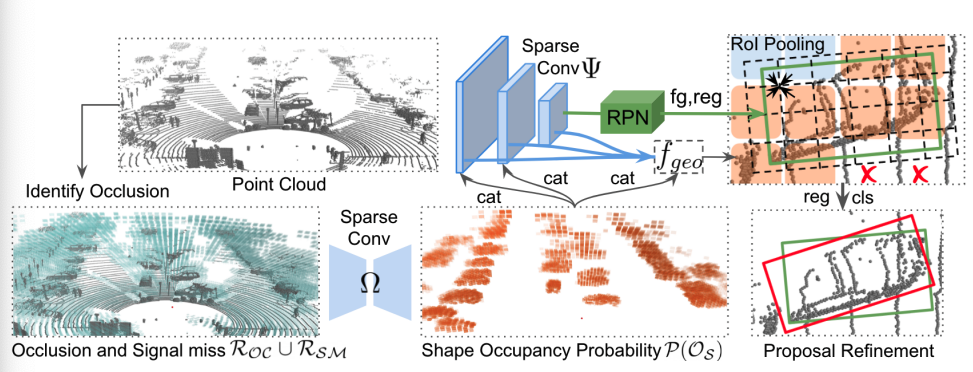
先进的 LiDAR 传感器提供丰富的 3D 数据,支持 3D 场景理解。 然而,在实践中,由于遮挡和信号丢失,LiDAR 点云是 2.5D。 这给 3D 感知带来了挑战,因为 LiDAR 点云仅覆盖部分底层形状。 为了解决这个问题,Xu 等人 (2021) 引入了基于 LiDAR 的 3D 对象检测模型 BtcDet,该模型能够学习对象形状先验并估计点云中部分遮挡的完整对象形状。
如上图所示,该模型首先识别遮挡区域,然后估计占用概率以指示区域是否包含对象形状。 模型使用这些信息生成高质量的 3D 建议。 最后,最终的边界框是通过提案细化模块生成的。 BtcDet 在多个基准测试中展示了其有效性,包括在 KITTI Cars 基准测试中的最新结果。
新的带有代码的论文
? Mask2Former 提出了一种用于图像分割任务(全景、实例或语义)的掩蔽注意力掩蔽变换器,并在 COCO 和 ADE20K 等多个基准测试中取得了最先进的结果。
? GANgealing 引入了新的 GAN 监督学习框架,在图像到图像的对应方面具有竞争力。
? GLIP 提出了一种用于学习对象级、语言感知和语义丰富的视觉表示的基础语言图像预训练模型。 在 COCO 和 Flickr30k 上分别实现了用于对象检测和短语接地的高性能。
?Point-BERT 提出了一种学习 Transformers 以将 BERT 推广到 3D 点云的新范式。 它使用掩蔽点建模来预训练点云 Transformer 模型,该模型在 ModelNet40 和 ScanObjectNN 等基准数据集上有所改进。
最新研究数据集和工具
数据集
ValueNet 一个新的大规模高价值数据集,其中包含人类对约 21K 文本场景的态度。
CALVIN 一个开源模拟基准,用于学习长期语言条件下的机器人操作任务。
PTR 一个新的大规模诊断视觉推理数据集,用于研究基于部分的概念、关系和物理推理。
工具
NL-Augmenter 任务敏感的自然语言增强框架。
MegBA 用于大规模捆绑调整的高性能分布式库。
PantheonRL 一个新的多智能体强化学习库,用于动态训练交互,例如循环和临时训练。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/2839/