
摘要:本文为Flink Forward 2021,Fanshu Jiang & Lu Niu | Software Engineers, Stream Processing Platform Team在大会上做的分享。下述为相关视频。
在 Pinterest,流数据处理支持广泛的实时用例。 近年来,由 Flink 提供支持的平台通过提供近乎实时的内容激活和指标报告,已被证明对业务具有巨大价值,并有可能在未来解锁更多用例。 然而,为了利用这种潜力,我们需要解决开发者速度的问题。
从编写第一行代码到生产中的稳定数据流可能需要数周时间。 由于要调查的日志和指标的数量以及可调整的配置的多样性,对 Flink 作业进行故障排除和调整可能特别耗时。 有时,需要深入了解 Flink 内部结构,才能在开发过程中找到问题的根源。 这不仅会影响开发人员的速度并创建低于标准的 Flink 入门体验,而且还需要重要的平台支持,从而限制了流媒体用例的可扩展性。
为了使调查更容易、更快,我们构建了一个 Flink 诊断工具 DrSquirrel,用于显示和汇总工作症状,提供对根本原因的洞察,并提出具有可操作步骤的解决方案。 自发布以来,该工具为开发人员和平台团队带来了显着的生产力提升。
Flink 作业故障排除有哪些挑战?
大量分散的日志和指标,其中只有少数很重要。
对于故障排除,工程师通常:
- 从 YARN UI 滚动 查看一系列JM/TM 日志
- 检查数十个作业/服务器指标仪表板
- 搜索和验证作业配置
- 单击 Flink Web UI 作业 DAG 以查找检查点对齐、数据倾斜和背压等详细信息
然而,我们花时间研究的 90% 的统计数据要么是良性的,要么只是与根本原因无关。 拥有一个仅汇总有用信息并仅显示与故障排除相关的一站式服务,可以节省大量时间。
这是不好的指标,现在呢?
一旦程序员发现不好的指标,这是一个常见的问题,因为需要更多的推理才能找到根本原因。 例如,检查点超时可能意味着不正确的超时配置,但也可能是背压、s3 上传缓慢、GC 错误或数据倾斜的结果; 丢失 TaskManager 日志可能意味着坏节点,但通常是堆或 RocksDB 状态后端 OOM 的结果。 理解所有这些推理并彻底验证每个可能的原因需要时间。 但是,80% 的问题修复都遵循某种模式。 这让我们想知道——作为一个平台团队,我们是否应该以编程方式分析统计数据并告诉程序员要调整什么而不让他们进行推理?
故障排除文档远远不够
我们为客户提供故障排除文档。 但是,随着故障排除用例数量的增加,文档变得太长而无法快速找到问题的相关诊断和说明。 工程师还必须手动应用 if-else 诊断逻辑来确定根本原因。 这给自助诊断增加了很多摩擦,并且仍然依赖平台团队进行故障排除。 此外,每当平台推出新的工作健康要求时,该文档并不擅长号召性用语。 我们意识到需要一个更好的工具来有效地共享故障排除要点并强制执行集群作业健康要求。
Dr. Squirrel,故障排除自助诊断工具
鉴于上述挑战,我们构建了 DrSquirrel——一种用于快速问题检测和故障排除指导的诊断工具,旨在:
- 将故障排除时间从几小时缩短到几分钟
- 将开发人员进行调查所需的工具从多种减少到一种; 和
- 将故障排除所需的 Flink 内部知识从中等降低到很少
简而言之,我们将有用的信息汇总在一个地方,执行工作健康检查,明确标记不健康的信息,并提供根本原因分析和可操作的步骤来帮助解决问题。 让我们来看看一些功能亮点。
更高效的日志查看方式
对于每次作业运行,Dr Squirrel 都会突出显示直接触发重启的异常(即 TaskManager 丢失、OOM),以帮助从海量日志池中快速找到相关异常以进行关注。 它还收集在不同部分中包含堆栈跟踪的所有警告、错误和信息日志。 对于每个日志,Squirrel 博士都会检查内容以查看是否可以找到错误关键字,然后在故障排除指南中提供指向我们逐步解决方案的链接。


所有日志都可以使用搜索栏进行搜索。 最重要的是,Dr Squirrel提供了两种更有效地查看日志的方法——时间轴视图和独特的异常视图。 如下所示,如果需要更多详细信息,Timeline 视图允许您按时间顺序查看带有类名和预先填充的 ElasticSearch 链接的日志。
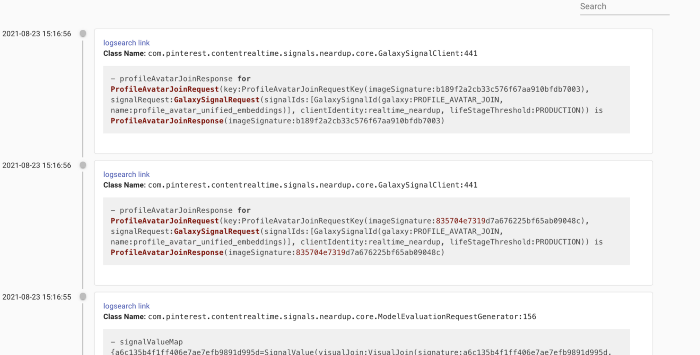
只需单击一下,我们就可以切换到“唯一异常”视图,其中相同的异常与元数据(例如第一次、最后一次和总出现次数)一起分组在一行中。 这简化了识别最常见异常的过程。
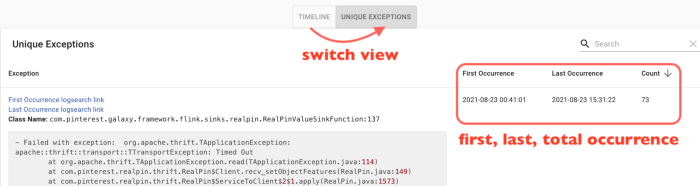
作业健康一目了然
Dr Squirrel 提供了一个健康检查页面,让工程师,无论是初学者还是专家,都能自信地判断工作是否健康。 Squirrel 博士没有显示简单的指标仪表板,而是监视每个指标 1 小时,并明确标记是否满足我们的平台稳定性要求。 对于平台团队来说,这是一种有效且可扩展的方式来沟通和执行被认为是稳定的内容。
健康检查页面由多个部分组成,每个部分都侧重于工作健康的不同方面。 需要快速浏览这些部分才能很好地了解整体工作状况:
- 基本作业统计部分监控基本统计信息,例如吞吐量、完全重启率、检查点大小/持续时间、连续检查点失败、过去 1 小时内的最大并行度。 当指标未通过健康检查时,它们会被标记为失败并排在最前面。
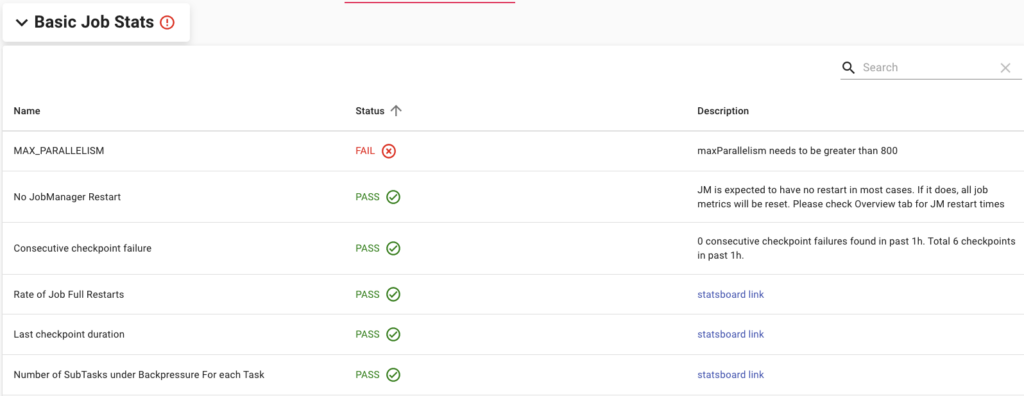
背压任务以细粒度跟踪每个算子的背压情况。 一分钟内没有背压显示为绿色方块,否则为红色方块。 每个算子60个方格,代表过去1小时的背压情况。 这样可以轻松确定背压发生的频率以及哪个operator最早启动。
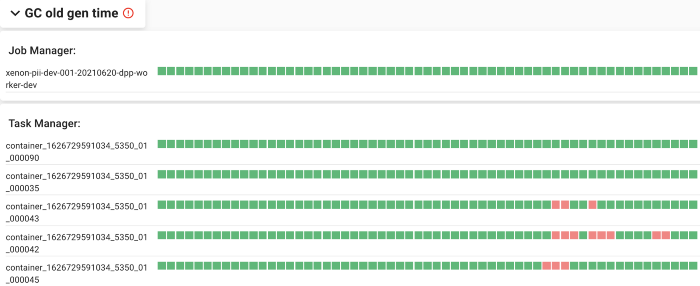
GC Old Gen Time 部分具有与背压相同的可视化功能,可概述 GC 是否发生得太频繁以及是否可能影响吞吐量或检查点。 同样的可视化,GC和背压是否同时发生,GC是否有潜在的背压的可能性就一目了然了。
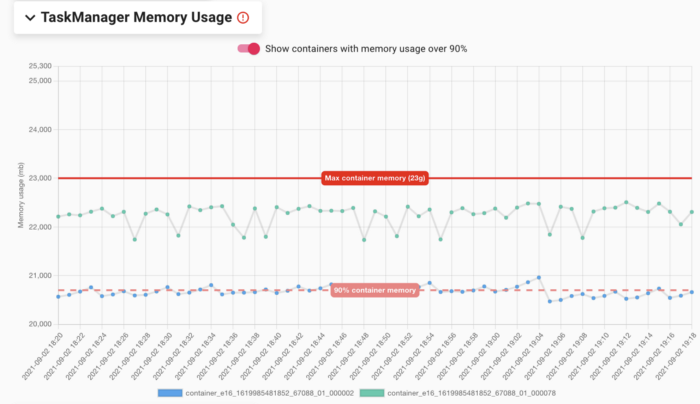
JobManager/TaskManager Memory Usage 跟踪 YARN 容器内存使用情况,这是我们通过在工作节点上运行的守护进程收集的 Flink Java 进程的常驻集大小(RSS)内存。 RSS 内存更准确,因为它包括 Flink 内存模型中的所有部分以及 Flink 未跟踪的内存,例如 JVM 进程堆栈、线程元数据或通过 JNI 从用户代码分配的内存。 我们在图中标记了配置的最大 JM/TM 内存,以及 90% 的使用阈值,以帮助用户快速发现哪些容器接近 OOM。
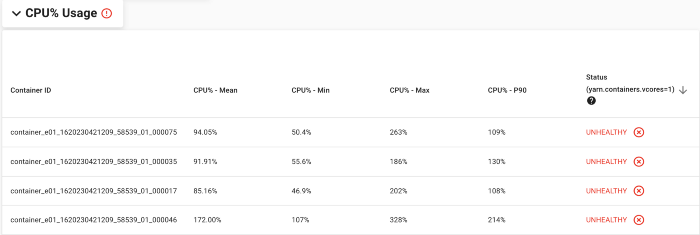
CPU% Usage 部分显示使用的 CPU 容量比分配给它们的 vcore 多的容器。 这有助于监控和避免多租户 Hadoop 集群中的“嘈杂邻居”问题。 非常高的 CPU% 使用率可能会导致一个用户的工作负载影响另一用户工作负载的性能和稳定性。
有效配置
Flink 作业可以在不同级别进行配置,例如执行级别的代码内配置、作业属性文件、客户端级别的命令行参数和系统级别的 flink-conf.yaml。 工程师在不同级别配置相同参数以进行测试或热修复的情况并不少见。 使用覆盖层次结构,最终生效的值并不明显。 为了解决这个问题,我们构建了一个配置库,它计算出作业运行时使用的有效配置值,并将这些配置呈现给 Dr. Squirrel。
可查询的集群工作健康度
提供丰富的工作统计数据,Dr. Squirrel 成为了解集群工作健康状况并深入了解平台改进的资源中心。 例如,前 10 个重启根本原因是什么,或者有多少作业遇到内存问题或背压。
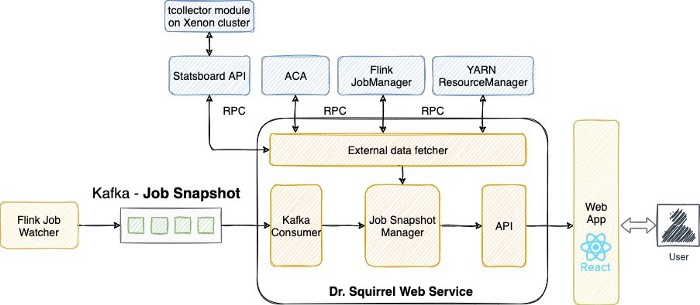
系统架构
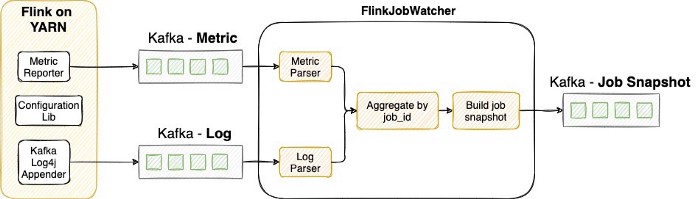
从上面的功能可以看出,指标和日志都集中在一个地方。 为了以可扩展的方式收集它们,我们在 Flink 自定义构建中添加了 MetricReporter 和 KafkaLog4jAppender,以持续向 kafka 主题发送指标和日志。 KafkaLog4jAppender 还用于过滤掉对我们很重要的日志——警告、错误和带有堆栈跟踪的信息日志。 紧随其后的是 FlinkJobWatcher——一个 Flink 作业,它在一系列解析和转换后连接来自同一作业的指标和日志。 然后 FlinkJobWatcher 每 5 分钟创建一次作业健康状况快照,并将其发送到 JobSnapshot Kafka 主题。
越来越多的 Flink 用例引入了大量的日志和指标。 FlinkJobWatcher 作为 Flink 作业可以完美地处理不断增加的数据规模,并通过简单的并行性调整使吞吐量与用例数量保持一致。
一旦 JobSnapshot 可用,需要获取更多数据并合并到 JobSnapshot 中。 为此,我们使用 dropwizard 构建了一个 RESTful 服务,该服务不断读取 JobSnapshot 主题并通过 RPC 提取外部数据。 外部数据源包括 YARN ResourceManager 用于获取静态数据(如用户名和启动时间)、Flink REST API 用于获取配置、称为Automated Canary Analysis(ACA)的内部工具,用于将时间序列指标与具有细粒度标准的阈值进行比较,以及 一些其他内部工具允许我们显示自定义指标,例如 RSS 内存和 CPU% 使用率,这些指标是从工作节点上运行的守护程序收集的。 React 还构建了一个漂亮的 UI,使工作健康易于探索。
未来工作
- 我们将继续提升 Dr. Squirrel 的工作诊断能力,帮助我们向完全自助解决问题更近一步:
- 容量规划:监控和评估吞吐量、内存和 vcore 的使用情况,以找到最有效的资源设置。
- 与 CICD 集成:我们正在运行 CICD 管道以自动验证并将更改从开发者推送到生产者。 Dr.Squirrel 将与 CICD 整合,随着 CICD 推出新的变化,为工作健康状况提供更多信心。
- 警报和通知:通过健康报告摘要通知工作所有者或平台团队。
- 每个作业的成本估算:根据预算规划和意识的资源使用情况显示每个作业的成本估算。
致谢
感谢 Hannah Chen、Nishant More 和 Bo Sun 对这个项目的贡献。 非常感谢 Ping-Min Lin 设置初始 UI 工作和 Teja Thotapalli 在 SRE 端进行基础设施设置。 我们还要感谢 Ang Zhang、Chunyan Wang、Dave Burgess 的支持,感谢我们所有的客户团队提供宝贵的反馈和故障排除方案,帮助我们使工具变得强大。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/3061/
赞
赞!