
摘要:
本文介绍了 Flink CDC 利用 Kafka 进行 CDC 多源合并和下游同步更新的实践分享。
前言
本文主要是针对 Flink SQL 使用 Flink CDC 无法实现多库多表的多源合并问题,以及多源合并后如何对下游 Kafka 同步更新的问题,因为目前 Flink SQL 也只能进行单表 Flink CDC 的作业操作,这会导致数据库 CDC 的连接数过多。
但是 Flink CDC 的 DataStream API 是可以进行多库多表的同步操作的,本文希望利用 Flink CDC 的 DataStream API 进行多源合并后导入一个总线 Kafka,下游只需连接总线 kafka 就可以实现 Flink SQL 的多源合并问题,资源复用。
环境
版本
| 组件 |
版本 |
| Flink |
1.13.3 |
| Flink CDC |
2.0 |
| Kafka |
2.13 |
| Java |
1.8 |
| Dinky |
0.5.0 |
CDC预览
我们先打印一下 Flink CDC 默认的序列化 JSON 格式如下:
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1643273051, file=mysql_bin.000002, pos=5348135, row=1, server_id=1, event=2}}ConnectRecord{topic='mysql_binlog_source.gmall.spu_info', kafkaPartition=null, key=Struct{id=12}, keySchema=Schema{mysql_binlog_source.gmall.spu_info.Key:STRUCT}, value=Struct{before=Struct{id=12,spu_name=华为智慧屏 14222K1 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},after=Struct{id=12,spu_name=华为智慧屏 2K 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},source=Struct{version=1.4.1.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1643273051000,db=gmall,table=spu_info,server_id=1,file=mysql_bin.000002,pos=5348268,row=0,thread=3742},op=u,ts_ms=1643272979401}, valueSchema=Schema{mysql_binlog_source.gmall.spu_info.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}可以看到,这种格式的 JSON,传给下游有很大的问题,要实现多源合并和同步更新,我们要解决以下两个问题。
①总线 Kafka 传来的 json ,无法识别源库和源表来进行具体的表创建操作,因为不是固定的 json 格式,建表 with 配置里也无法指定具体的库和表。
②总线 Kafka 传来的 json 如何进行 CRUD 等事件对 Kafka 流的同步操作,特别是 Delete,下游kafka如何感知来更新 ChangeLog。
查看文档
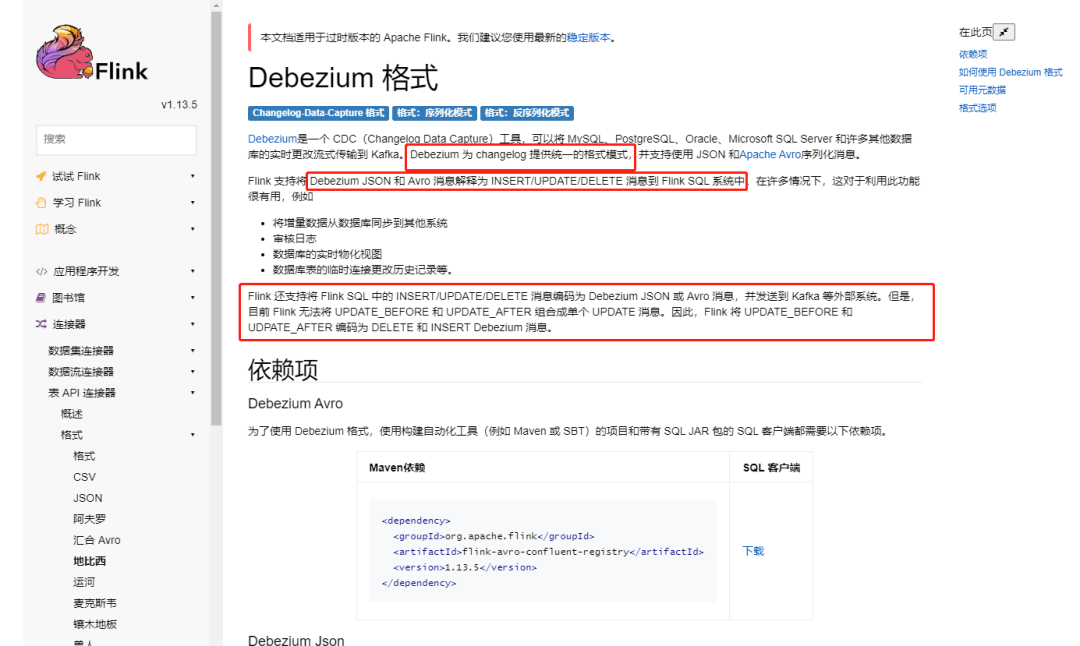

我们可以看到红框部分,基于 Debezium 格式的 json 可以在 Kafka connector 建表中可以实现表的 CRUD 同步操作。只要总线 Kafka 的 json 格式符合该模式就可以对下游 kafka 进行 CRUD 的同步更新,刚好 Flink CDC 也是基于Debezium。
那这里就已经解决了问题②。
剩下问题①,如何解决传来的多库多表进行指定表和库的识别,毕竟建表语句没有进行 where 的设置参数。
再往下翻文档:
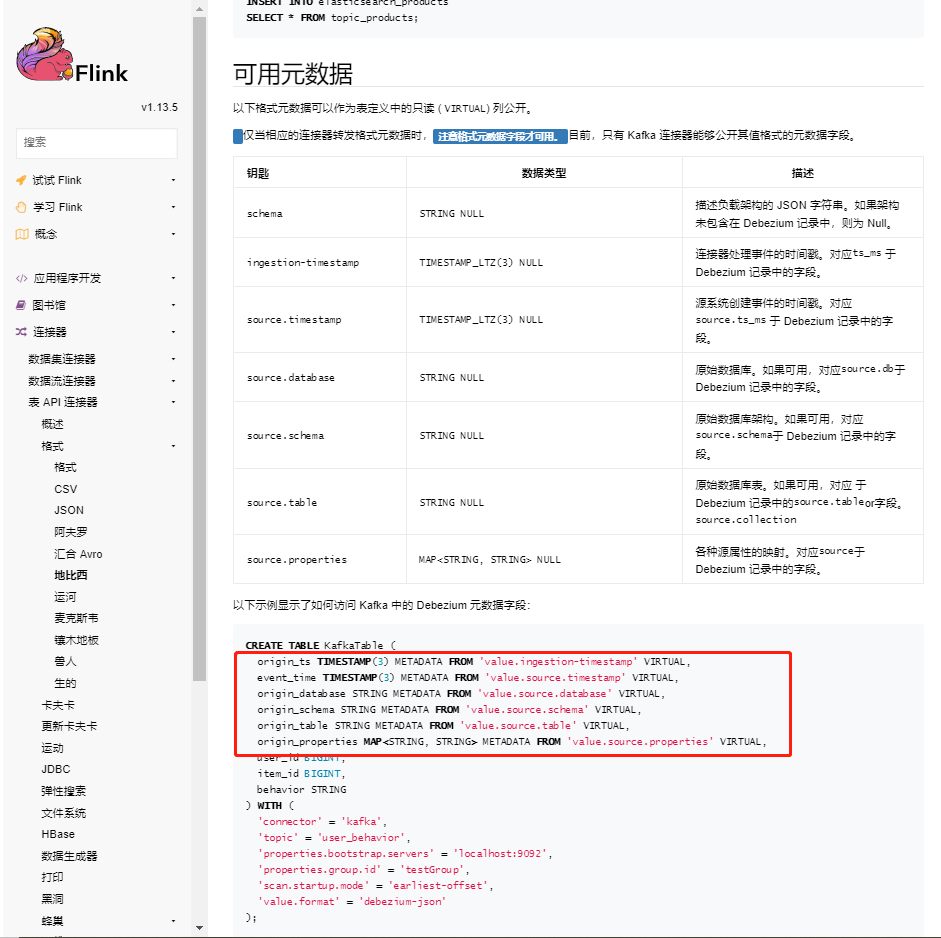
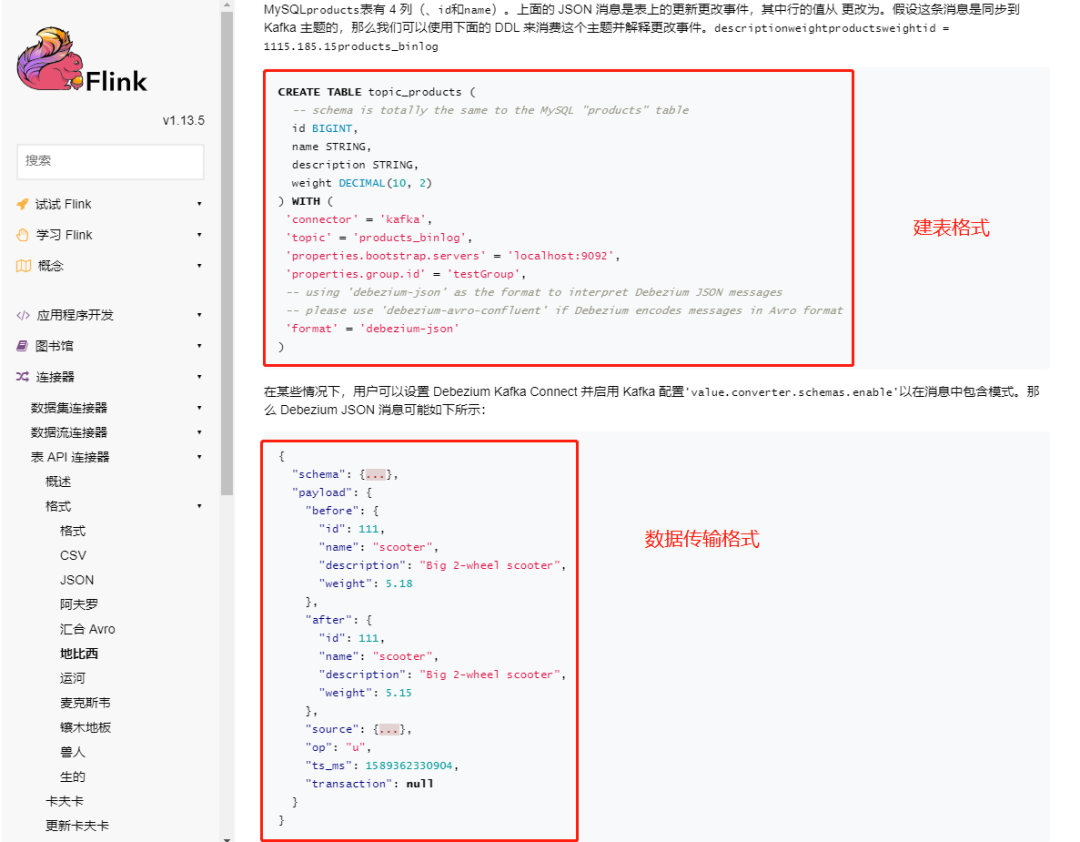
可以看到,基于 Debezium-json 格式,可以把上面的 schema 定义的 json 格式的元数据给取出来放在字段里。
比如,我把 table 和 database 给放在建表语句里,那样我就可以在 select 语句中进行库和表的过滤了。
如下:
CREATE TABLE Kafka_Table ( origin_database STRING METADATA FROM 'value.source.database' VIRTUAL, //schema 定义的 json 里的元数据字段 origin_table STRING METADATA FROM 'value.source.table' VIRTUAL, `id` INT, `spu_name` STRING, `description` STRING, `category3_id` INT, `tm_id` INT) WITH ( 'connector' = 'kafka', 'topic' = 'input_kafka4', 'properties.group.id' = '57', 'properties.bootstrap.servers' = '10.1.64.156:9092', 'scan.startup.mode' = 'latest-offset', 'debezium-json.ignore-parse-errors' = 'true', 'format' = 'debezium-json');select * from Kafka_Table where origin_database='gmall' and origin_table = 'spu_info'; //这里就实现了指定库和表的过滤操作那这样问题②就解决了。那我们现在就要做两个事情:
①写一个Flink CDC的DataStream项目进行多库多表同步,传给总线Kafka。
②自定义总线Kafka的json格式。
新建 FlinkCDC 的 DataStream 项目
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;public class FlinkCDC { public static void main(String[] args) throws Exception { //1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //1.1 设置 CK&状态后端 //略 //2.通过 FlinkCDC 构建 SourceFunction 并读取数据 DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder() .hostname("10.1.64.157") .port(3306) .username("root") .password("123456") .databaseList("gmall") //这个注释,就是多库同步 //.tableList("gmall.spu_info") //这个注释,就是多表同步 .deserializer(new CustomerDeserialization()) //这里需要自定义序列化格式 //.deserializer(new StringDebeziumDeserializationSchema()) //默认是这个序列化格式 .startupOptions(StartupOptions.latest()) .build(); DataStreamSource<String> streamSource = env.addSource(sourceFunction); //3.打印数据并将数据写入 Kafka streamSource.print(); String sinkTopic = "input_kafka4"; streamSource.addSink(getKafkaProducer("10.1.64.156:9092",sinkTopic)); //4.启动任务 env.execute("FlinkCDC"); } //kafka 生产者 public static FlinkKafkaProducer<String> getKafkaProducer(String brokers,String topic) { return new FlinkKafkaProducer<String>(brokers, topic, new SimpleStringSchema()); }}自定义序列化类
import com.alibaba.fastjson.JSONObject;import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;import io.debezium.data.Envelope;import org.apache.flink.api.common.typeinfo.BasicTypeInfo;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Field;import org.apache.kafka.connect.data.Schema;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord;import java.util.ArrayList;import java.util.List;public class CustomerDeserialization implements DebeziumDeserializationSchema<String> { @Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { //1.创建 JSON 对象用于存储最终数据 JSONObject result = new JSONObject(); //2.获取库名&表名放入 source String topic = sourceRecord.topic(); String[] fields = topic.split("\\."); String database = fields[1]; String tableName = fields[2]; JSONObject source = new JSONObject(); source.put("database",database); source.put("table",tableName); Struct value = (Struct) sourceRecord.value(); //3.获取"before"数据 Struct before = value.getStruct("before"); JSONObject beforeJson = new JSONObject(); if (before != null) { Schema beforeSchema = before.schema(); List<Field> beforeFields = beforeSchema.fields(); for (Field field : beforeFields) { Object beforeValue = before.get(field); beforeJson.put(field.name(), beforeValue); } } //4.获取"after"数据 Struct after = value.getStruct("after"); JSONObject afterJson = new JSONObject(); if (after != null) { Schema afterSchema = after.schema(); List<Field> afterFields = afterSchema.fields(); for (Field field : afterFields) { Object afterValue = after.get(field); afterJson.put(field.name(), afterValue); } } //5.获取操作类型 CREATE UPDATE DELETE 进行符合 Debezium-op 的字母 Envelope.Operation operation = Envelope.operationFor(sourceRecord); String type = operation.toString().toLowerCase(); if ("insert".equals(type)) { type = "c"; } if ("update".equals(type)) { type = "u"; } if ("delete".equals(type)) { type = "d"; } if ("create".equals(type)) { type = "c"; } //6.将字段写入 JSON 对象 result.put("source", source); result.put("before", beforeJson); result.put("after", afterJson); result.put("op", type); //7.输出数据 collector.collect(result.toJSONString()); } @Override public TypeInformation<String> getProducedType() { return BasicTypeInfo.STRING_TYPE_INFO; }}OK,运行 flinkCDC 项目,同步的数据库表插入一条记录,得出以下自定义格式后的 JSON:
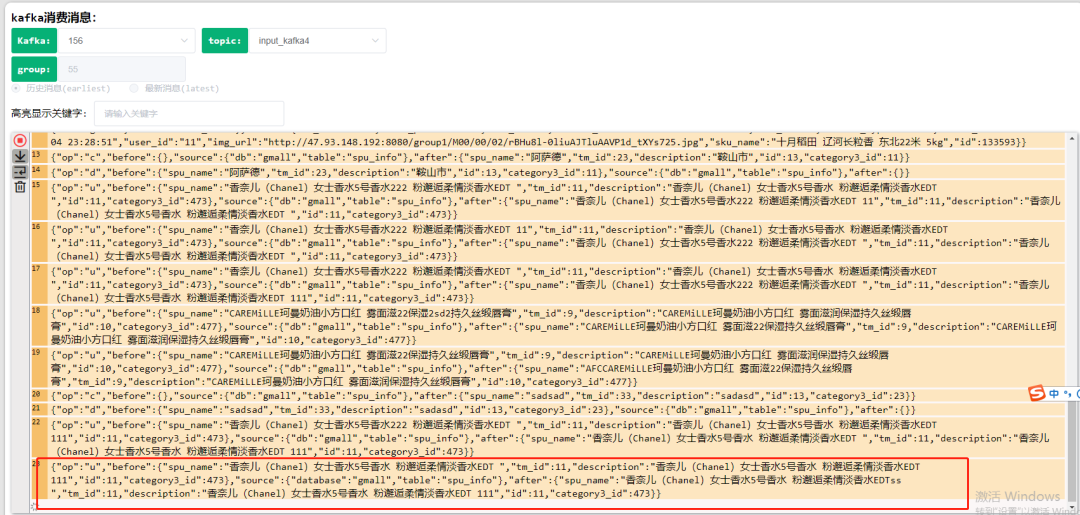
{ "op": "u", "before": { "spu_name": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT ", "tm_id": 11, "description": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT 111", "id": 11, "category3_id": 473 }, "source": { "database": "gmall", "table": "spu_info" }, "after": { "spu_name": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDTss ", "tm_id": 11, "description": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT 111", "id": 11, "category3_id": 473 }}PS:没放 schema{}这个对象,看文档说加了识别会影响效率。
总线 Kafka
Dinky 开发及提交作业
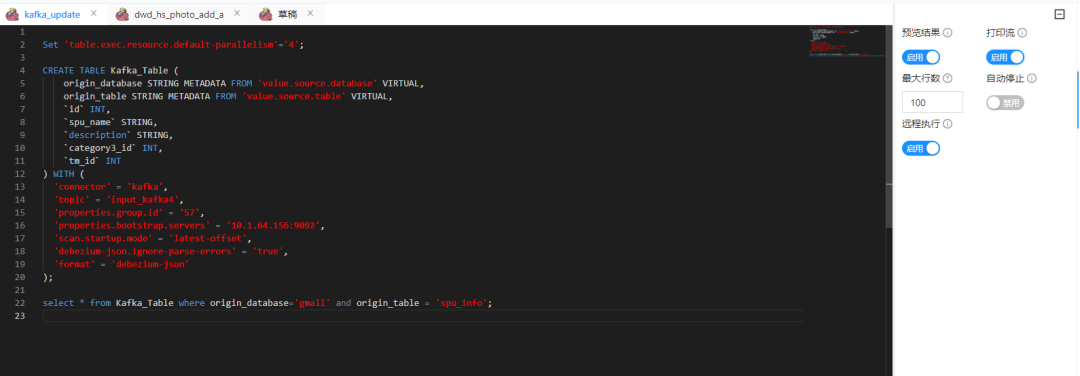
PS:yarn-session 模式,记得开启预览结果和打印流,不然观察不到数据 changelog
查看结果
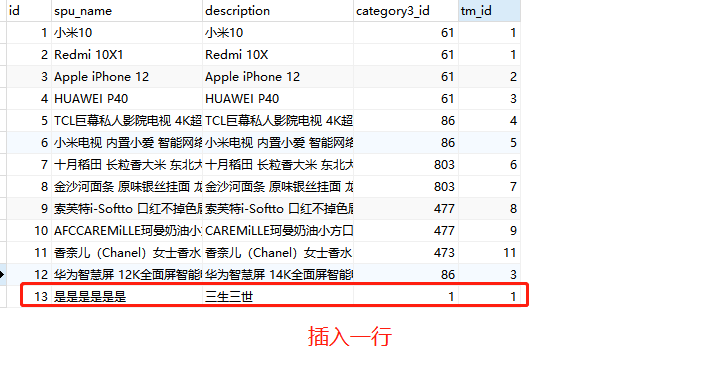
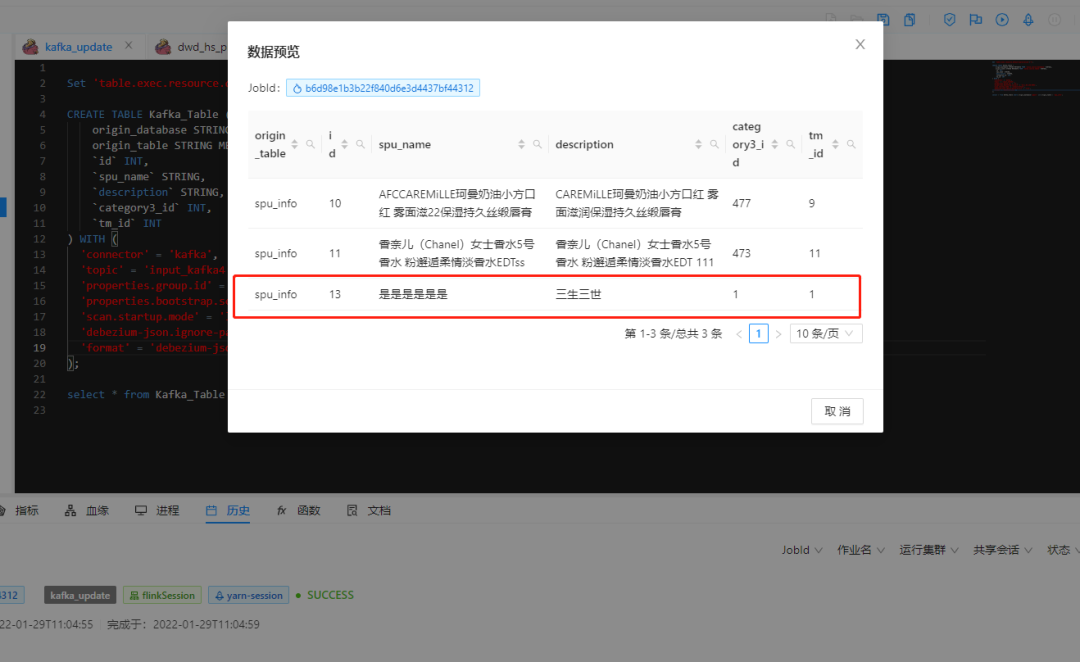
可以看到在指定库和表中新增一条数据,在下游 kafka 作业中实现了同步更新,然后试试对数据库该表的记录进行 delete,效果如下:
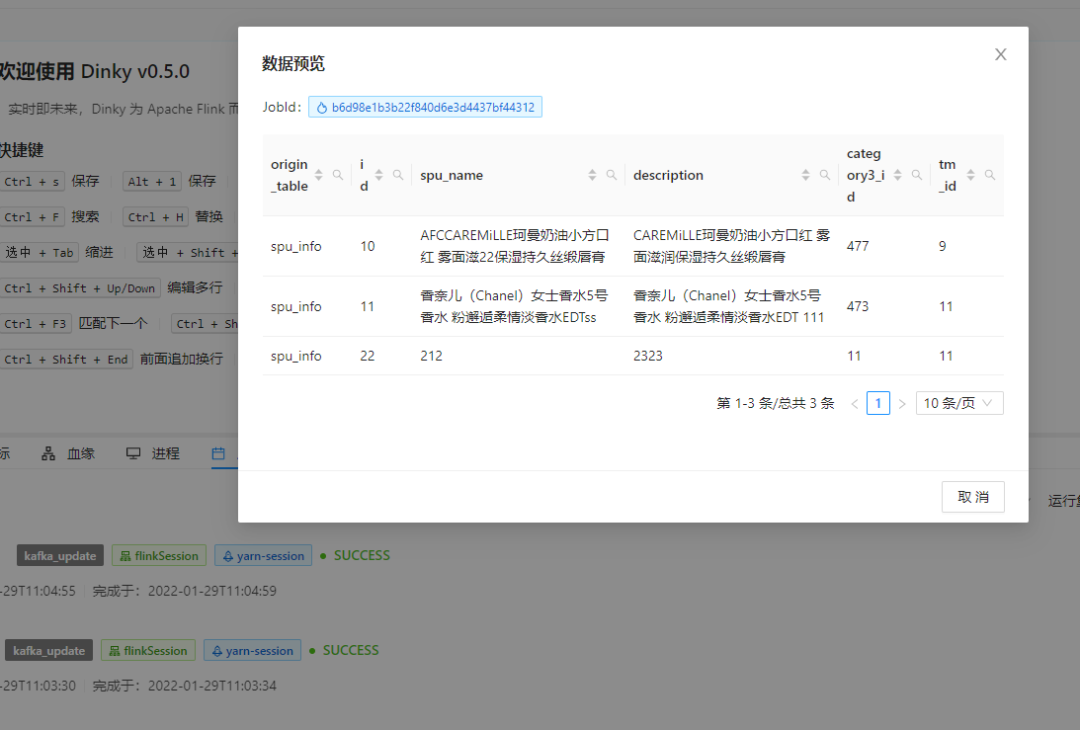
可以看到"是是是.."这条记录同步删除了。
此时 Flink CDC 的记录是这样:

原理主要是 op 去同步下游 kafka 的 changeLog 里的 op。
我们浏览一下 changeLog:(Dinky 选中打印流即可)
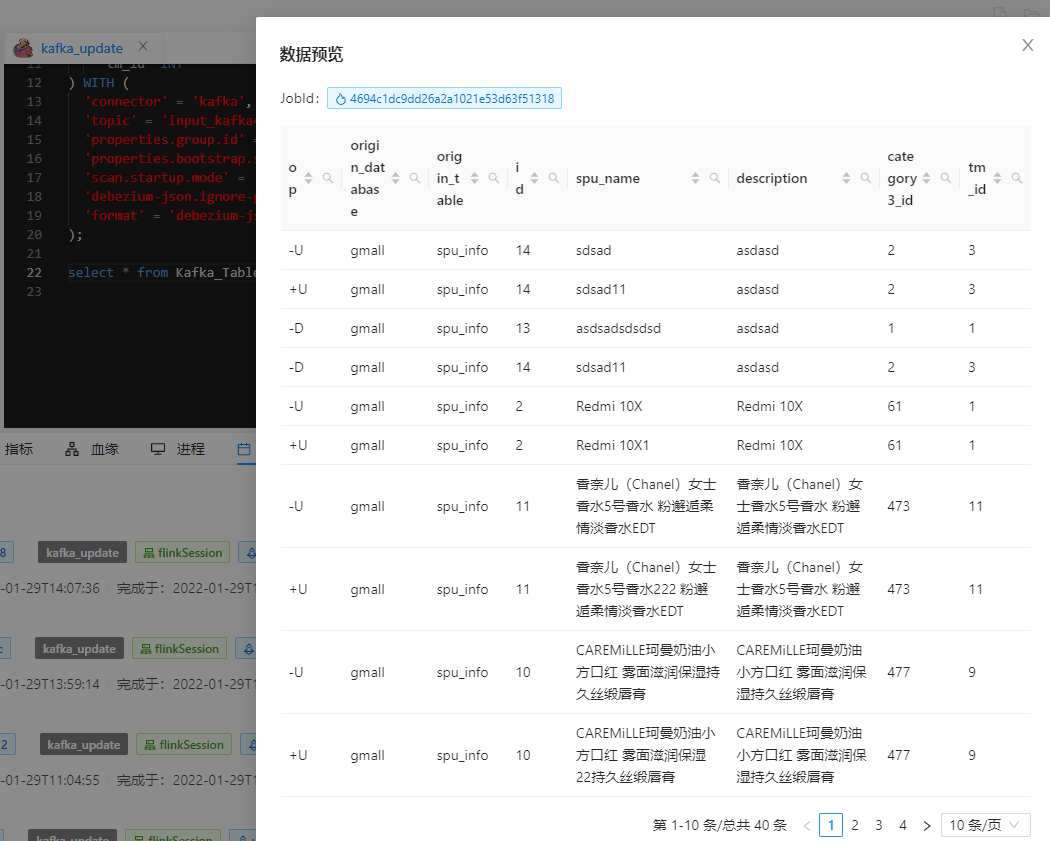
可以看到,op 自动识别总线 kafka 发来的 JSON 进行了同步来记录操作。
后续我们就可以插入 upsert-kafka 表进行具体的表操作了。
完成!这样只需建一个 DataStream 的总线 jar,在 Dinky 中进行提交,后续下游的作业只需要 kafka 去接总线 kafka 就可以进行 Flink CDC 在 Flink SQL 里的多源合并和同步更新。
总结
灵感和代码来自于尚硅谷,请支持 Dinky 和尚硅谷,另外是在测试环境进行,生产环境调优自行解决,如有更好的实践欢迎对文档进行补充,感谢!
本文转载自谢帮桂 DataLink数据中台,原文链接:https://mp.weixin.qq.com/s/9EUHpPNoPH1TG0ReaZnIAg。