
本文整理自移动软件开发工程师谢磊在 Flink Forward Asia 2021 平台建设专场的演讲。本篇内容主要分为四个部分:
-
实时计算平台建设
-
中移信令业务优化
-
稳定性实践
-
未来方向的探索


中移(苏州)软件技术有限公司是中国移动通信有限公司的全资子公司,公司定位为中国移动云设施的构建者、云服务的提供者、云生态的绘制者。公司以移动云为运营中心,产品和服务在电信、政务、金融、交通等领域都有广泛应用。
实时计算平台介绍

实时计算引擎在移动云的演进分为几个阶段:
-
2015 年到 16 年,我们使用的是第一代实时计算引擎 Apache Storm;
-
17 年我们开始调研 Apache Spark Streaming,它可以与自研框架进行整合,降低了运维压力和维护成本;
-
18 年,用户对云计算的需求越来越多,Storm 和 Spark已经无法很好地满足业务。同时我们研究了流计算比较出名的几篇文章,发现 Apache Flink 已经比较完整地具备了文中提到的一些语义;
-
19 年 – 20 年,我们开始实现云服务,并把实时计算平台上线至公有云和私有云;
-
20 年 – 21 年,我们开始调研实时数仓,并将 LakeHouse 上线移动云。
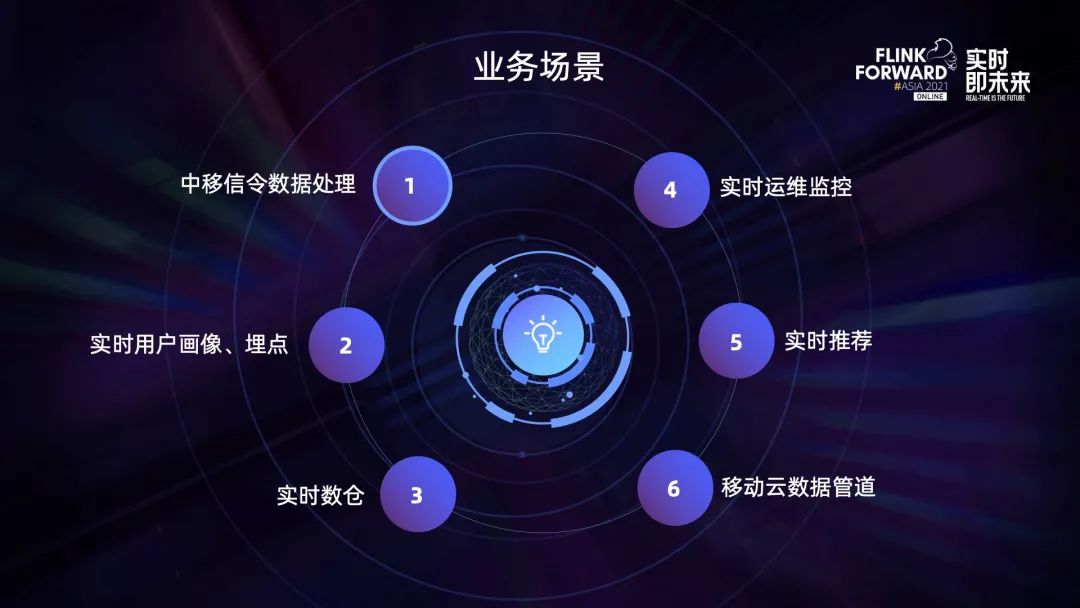
目前 Flink 主要用于中移信令数字的处理、实时用户画像和埋点、实时数仓、实时运维监控、实时推荐以及移动云的数据管道服务。

中移的实时计算平台功能分为三大部分。
-
第一部分是服务管理,支持了任务生命周期的托管、Flink 和 SQL 作业、Spark Streaming 作业以及引擎多版本的支持;
-
第二部分是 SQL 的支持,提供了在线 Notebook 编写、SQL 语法检测、UDF 管理和元数据管理;
-
第三部分是任务运维,支持实时任务的日志检索、实时性能指标采集以及消息延迟报警和任务反压报警等。
本文主要分享两个核心设计:引擎多版本的设计和实时任务日志检索。
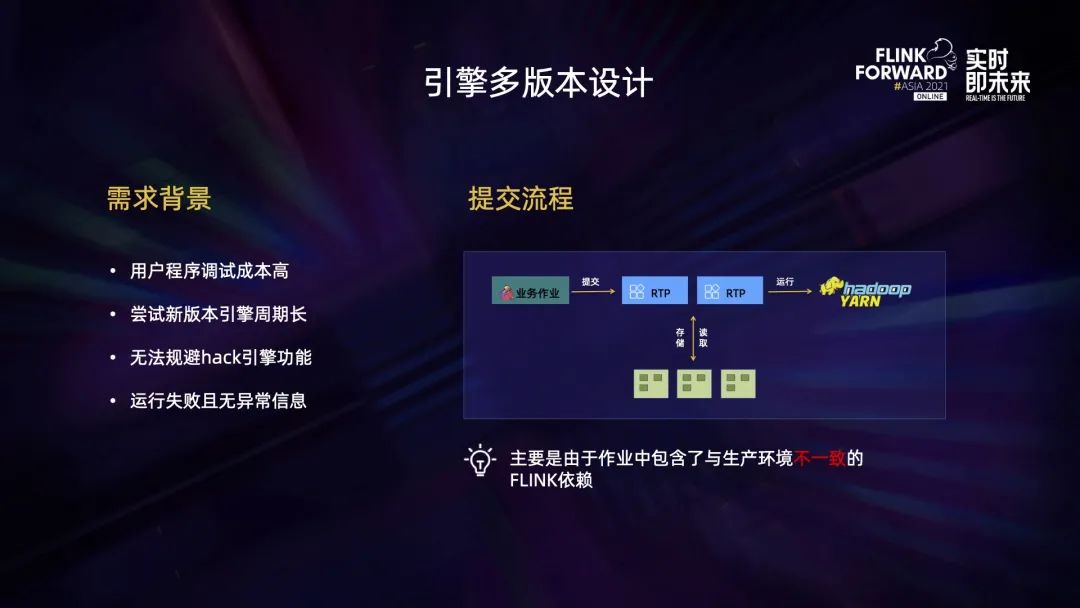
在日常有任务场景中,我们发现用户程序调试成本比较高,用户尝试新版本引擎的周期也比较长,此外无法规避用户 hack 引擎的功能以及有些任务运行失败但是没有异常信息,因此我们引入了引擎多版本设计。
多版本提交的流程如下:用户的任务首先会提交到 rtp 服务,rtp 服务将用户程序上传到 HDFS 保存,需要提交的时候再从 HDFS 拉回来提交到 Yarn 集群。此类任务存在一个共性——作业中包含 Apache Flink 的核心包,这会导致很多问题。

因此,首先我们会与业务沟通,使作业包里面不包含 Flink 的 core 包,但是这样的收益比较小,所以我们在平台侧做了一次检测,在用户在上传 jar 包的过程中主动检测用户包里是否包含 core 包。如果发现作业包含了非法核心包,则会阻止用户提交。
如此简单的操作,却为公司带来了很大的收益:
-
第一,极大降低了一些低价值 bug 的定位成本;
-
第二,作业升级和回退版本更加方便;
-
第三,提高了作业的稳定性和安全性。
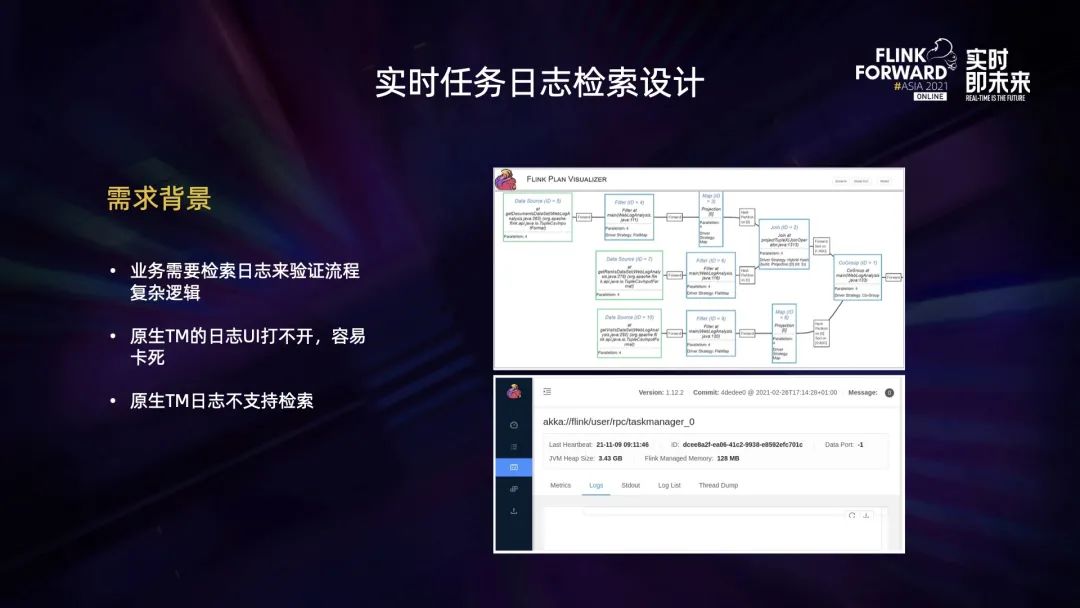
在日常业务场景中,我们需要通过日志检索来验证流程的复杂逻辑。此外,原生 TM 的 UI 日志打不开,容易卡死。以及 TM UI 不支持检索,如上图所示,当业务逻辑非常复杂的时候,Flink UI 无法提供以上功能。因此我们设计了实时任务日志检索功能。

实时任务日志检索的设计上需要考虑以下几个问题:如何采集作业程序日志,并将 TM 分布在不同的机器上?如何不侵入作业进行采集日志?如何限制作业打印大量无用日志?
-
针对第一个问题,我们采用的push模式来降低采集日志的压力;
-
针对第二个问题,参考 spring 中的 AOP 机制,我们使用 AspectJWeaver,切入点是 log4j 的 input 或 event,之后把日志发送到 Sender;
-
针对第三个问题,我们采用的是 RateLimiter 来进行限流。

上图是实时任务日志检索的整体设计。我们在原生的 TaskManager 下面加了 AOP 层,日志会先通过 TaskManager 发送 task,再发送到 AOP。整个 AOP 对用户无感知,因为采用了切面的方式。之后再发送到 RateLimiter,再到 Sender,由 RateLimiter 进行限流的操作。接着日志继续发送到 Kafka,做检索的时候日志会被发送到 Elestic Search。
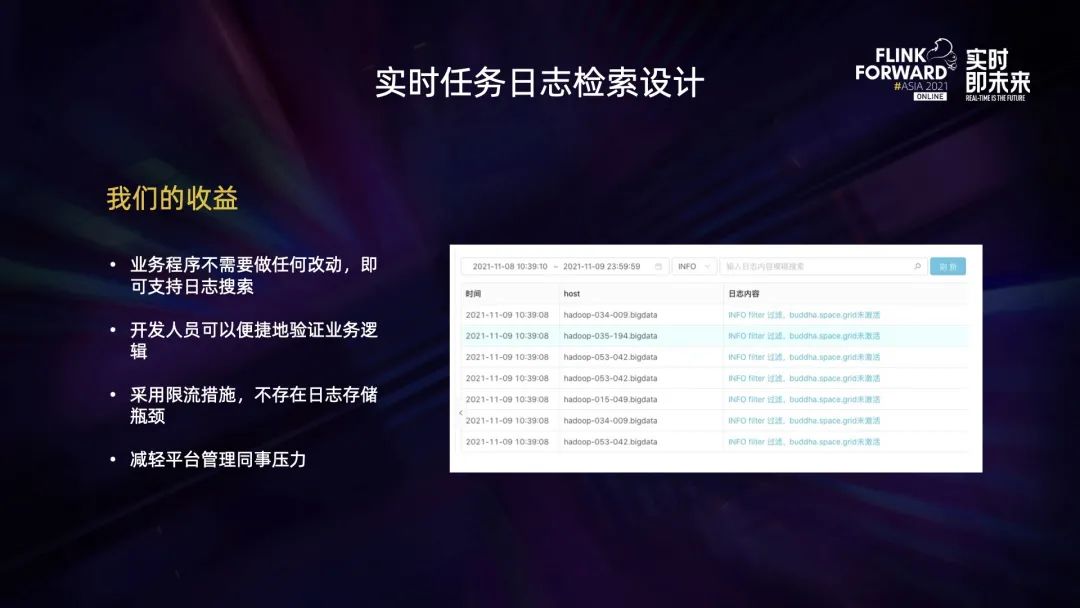
有了实时任务日志检索之后,业务程序不需要做任何改动就可以支持日志的检索。同时,开发人员可以便捷地验证业务逻辑。得益于限流措施,也不会存在日志存储瓶颈。此外,也减轻了平台管理的压力。
中移信令业务优化

中国移动信令业务的出现是为了解决各级政府部门有关于移动用户资源数据的需求,包括旅游部门、应急部门、交通行业等,如交通规划、交通调查、旅游景区等重点区域的人口流量监测、流动人口监测管理等等。
依赖于中国移动手机用户的高覆盖率,利用移动通信网络区域服务技术以及 GIS 技术,通过对移动用户信令数据的统计,对城市人口数量、流动性等要素进行分析预测,为城市规划、交通规划、管理、资源配置、外来人口管理、政策制定等政府管理行为提供决策数据支持。
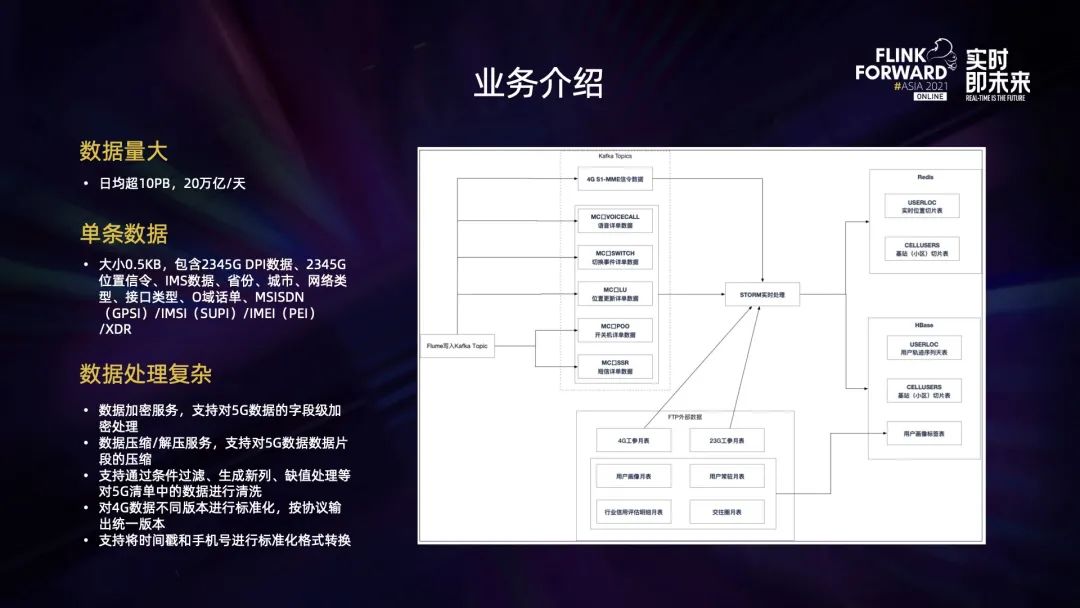
业务日均数据大概是 10PB,20 万亿/天,单条数据大小 0.5KB,包含了 2345G 上网数据、位置信令、省份城市、网络类型、接口类型等等。数据处理也比较复杂,要做数据加密、压缩以及版本的统一等。上图是处理信令数字时的条件和业务逻辑等。
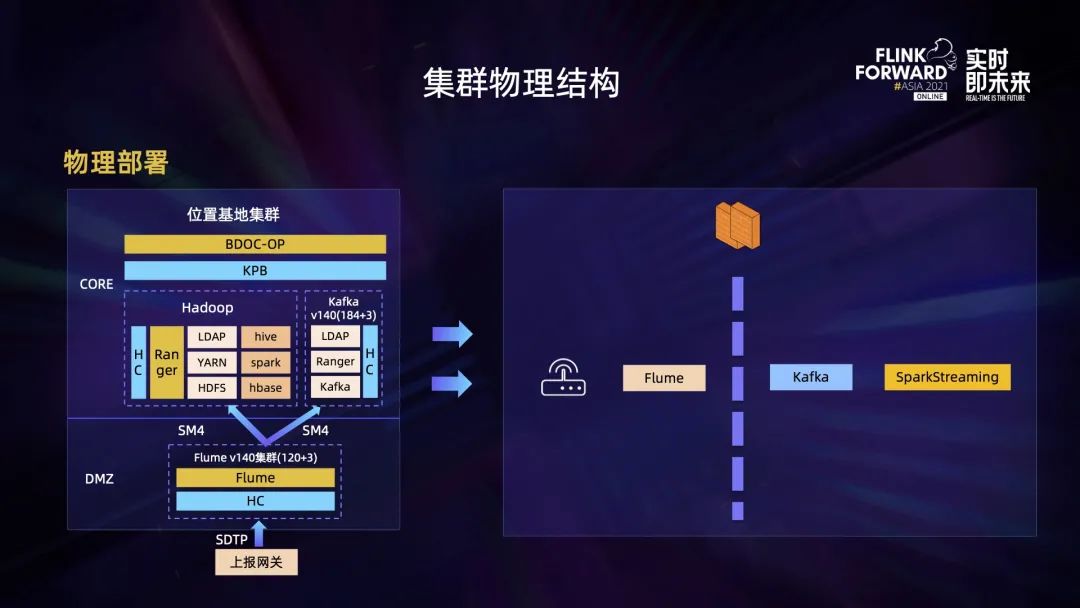
将需求化繁为简,应对到集群上,就是一个上报网关。它会将各地的信令数据进行上传,由 Flume 集群进行数据接收,再传输到 Hadoop 集群。上图可以看到,Flume 与 Hadoop 之间存在一面物理墙。
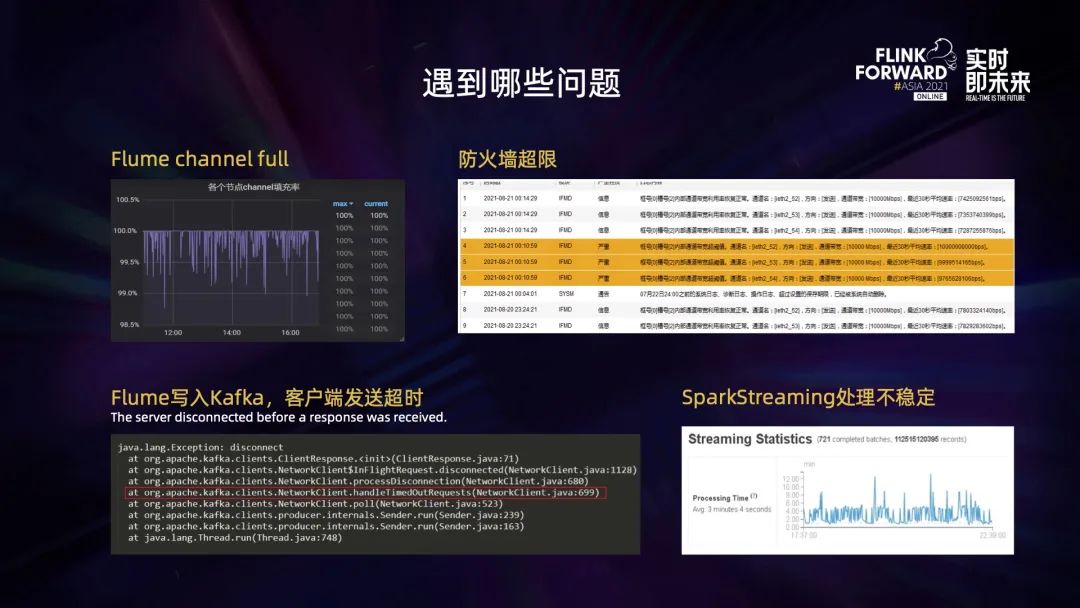
随着数据量增大,我们也遇到了很多问题:
-
第一,Flume 集群会一直报警提示 Flume channel full;
-
第二,防火墙超限,也会进行报警;
-
第三,Flume 在写 Kafka 的时候,Kafka 发送端会发送超时报警;
-
第四,下游处理信令数据的时候,Spark Streaming 处理是不稳定的。

上述问题总结起来可以分为两大类:
-
第一类是写入性能问题。Kafka 在写入的时候频繁超时,生产性能存在瓶颈。以及 Flume 在发送数据时无法达到网卡的上限速度;
-
第二类是架构设计问题。架构涉及的组件比较多导致维护的成本比较高;此外,组件职责不清晰,比如 Flume 中存在数据清洗的逻辑;还有 Spark 逻辑和处理逻辑复杂,存在多处 shuffle,处理性能不稳定。

首先要解决的是 PRO 写入 Kafka 超时的问题。为了解决这个问题,我们进行了以下优化:
-
优化了防火墙端口;
-
优化了 Kafka 服务器的一些性能参数;
-
在 Kafka 服务器端进行了一些性能参数调优。
但是这并不能彻底解决 Flume 写入 Kafka 超时的问题,于是我们把重点聚焦到客户端。首先是客户端的参数如何优化,尤其是 batch.size、buffer.memory 和 request.time.out 如何调优。其次是如何达到单机网络最大数网速,即单机情况下设置多少客户端并发合适。

经过实践我们发现,当 batch.size 为 256 兆,buffer.memory 为 128 兆时,性能会达到最优,但此时并没有达到网卡的最大速度。

于是我们进行了第二轮测试,增加了 compression.type,期望通过压缩发送的数据来提高发送带宽,但是结果并不符合我们的期望。
这是由于 Kafka 在低版本的时候存在一个问题,参数在它的验证脚本里的每个值都是一样的,所以它的压缩比会比较大。但是实际的生产环境中每条数字都是不一样的,所以压缩比非常小。

另外一个问题是如何达到网卡的最大速度?最简单的方式是增加并行度,但是并行度并不是越大越好。经过实践发现,并发度为 4 的时候能达到网卡的最大速度,超过 4 以后平均耗时会明显增加,也会导致 Kafka 写入超时。
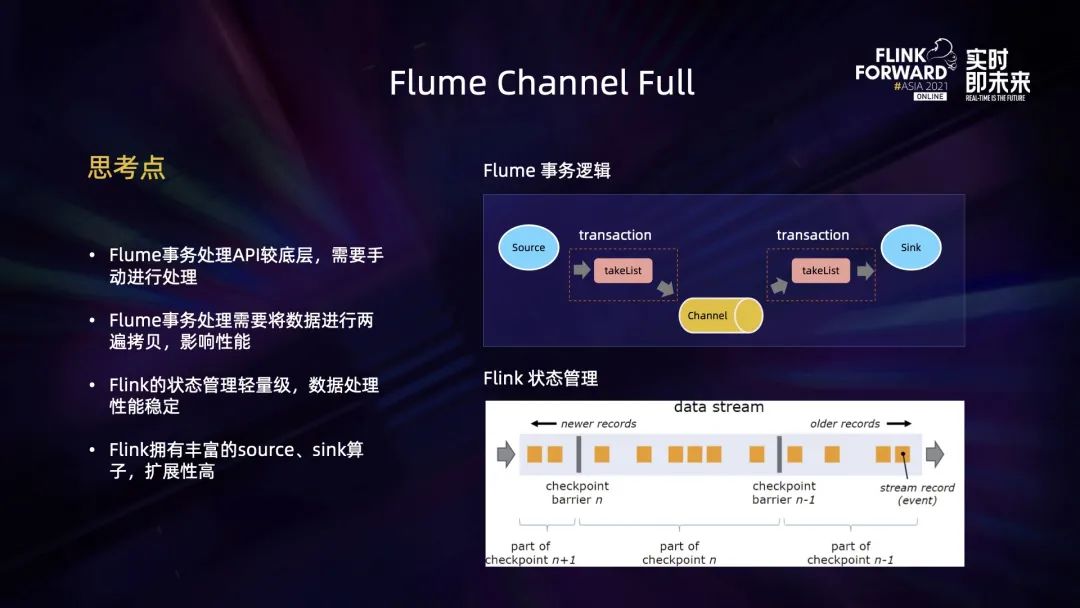
第二点是 Flume channel full 的问题。
扩展服务的时候,服务的事务 API 处理是比较底层的,需要手动进行处理。此外服务的事务处理数据的时候,需要将数据进行拷贝。如上图所示,当数据从 source 发送到 channel 的时候,会把一份数据先 copy 到内存里,从 channel 再发送到 sink 的时候,又会从 channel 再 copy 到内存。这个过程中的两次 copy 浪费了资源。而 Flink 做事务的时候是借助于状态管理,因而它的处理性能是比较稳定的。另外,Flink 拥有丰富的 source 和 sink,扩展性比较强。
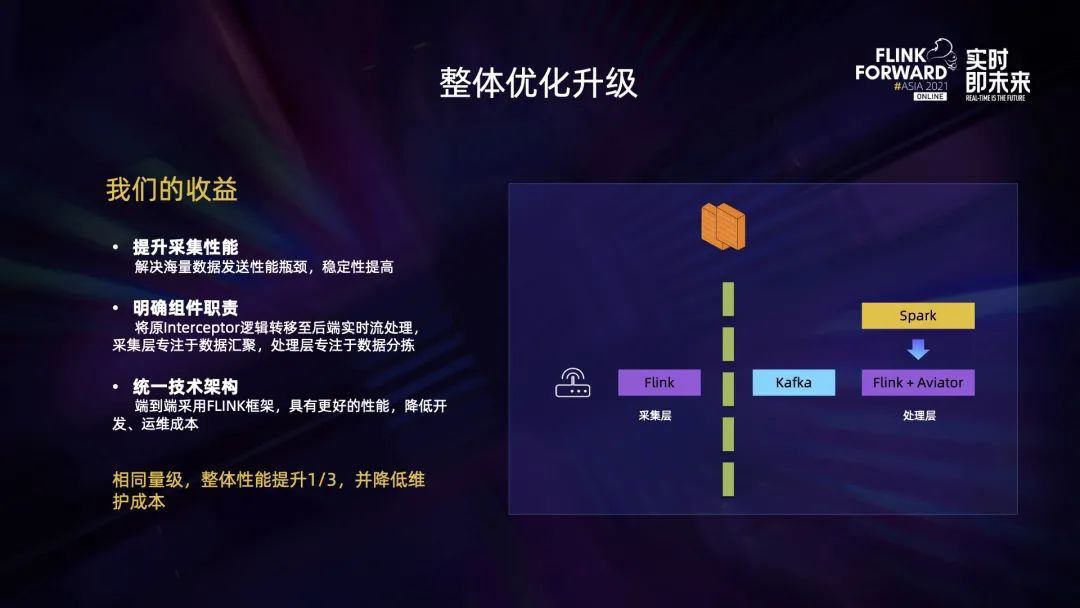
因此,我们决定使用 Flink 代替 Flume 来解决问题。替换成 Flink 以后,提升了采集性能,解决了海量数据发送性能瓶颈,稳定性显著提高。同时,明确了组件职责,我们将原有的服务中存在的逻辑全部转移至后端实时数据分解,让采集层专注于数据汇聚,处理层专注于数据分拣。另外,我们统一了技术栈,端到端采用了 Flink 框架,获得了更高的性能,也降低了开发和运维成本。
最终整体性能提升了 1/3 且降低了维护成本。
稳定性实践

作业稳定性主要指服务故障以及处理方案,服务故障主要包括作业运行失败、作业消费延迟、作业出现 OOM 以及作业异常重启。对应的处理方案是可以将作业进行物理隔离,服务进行降级,加强资源监控以及对服务进行拆分。
而平台维护人员最关心的是整体性的问题。

如果 ZooKeeper 集群中有一台服务器出现了网络服务瞬断,它也会引起大批量的任务重启。Flink JobManager 会通过 ZooKeeper 来进行 leader 的选举和发现 CheckpointID 的计数器管理。
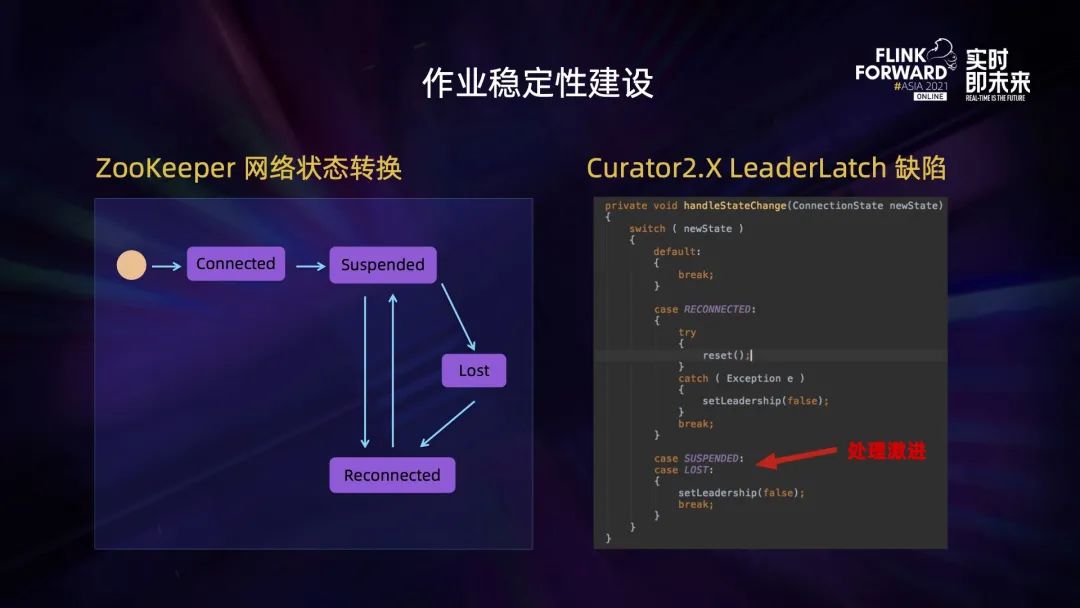
于是我们分析了 ZooKeeper 网络状态的转换。客户端在连接 ZooKeeper 集群的时候,它的状态先是 connected 状态,网络瞬断后它会变成 Suspended 状态,Suspended 状态会转换为 lost 状态,还会继续转换为 reconnected 状态。Flink 在使用 ZooKeeper 的时候会依赖一个 curator2.0 组件,然而这个组件存在一个缺陷,遇到 Suspended 状态就会直接将 leader 丢弃,这会导致大部分作业进行重启,这对于我们的业务来说是不可接受的。

官方直到 Flink 1.14 版本才对此问题进行修复。在之前的版本下,需要重新写 LeaderLatch,同时如果使用的是 Flink 1.8 版本,还需要同时修改 ZooKeeperCheckpointIDCounter。
未来方向的探索

未来,我们主要会在这两个方向进行持续探索:
-
第一,资源利用方向。包括 Elastic Scaling 调研和 K8s Yunikorn 资源队列调研。我们发现 Flink 上云之后存在着资源队列的问题,所以需要将用户的资源进行分队列管理;
-
第二,数据湖方向。首先是统一流批服务网关,做实时数仓的时候可能会采用不同的引擎,比如 Flink 和 Spark,它们属于两套不同的服务,所以需要做统一流批的服务网关。其次是数据血缘、数据资产和数据质量服务化。
本文转载自谢磊@中国移动,原文链接:https://mp.weixin.qq.com/s/5pNpAEjlWlyrkCrKi2QVSA。