
-
网易数帆大数据简介 -
统建中台:先设计后开发 -
见招拆招:运动式治理 -
治理体系:现代数据治理


-
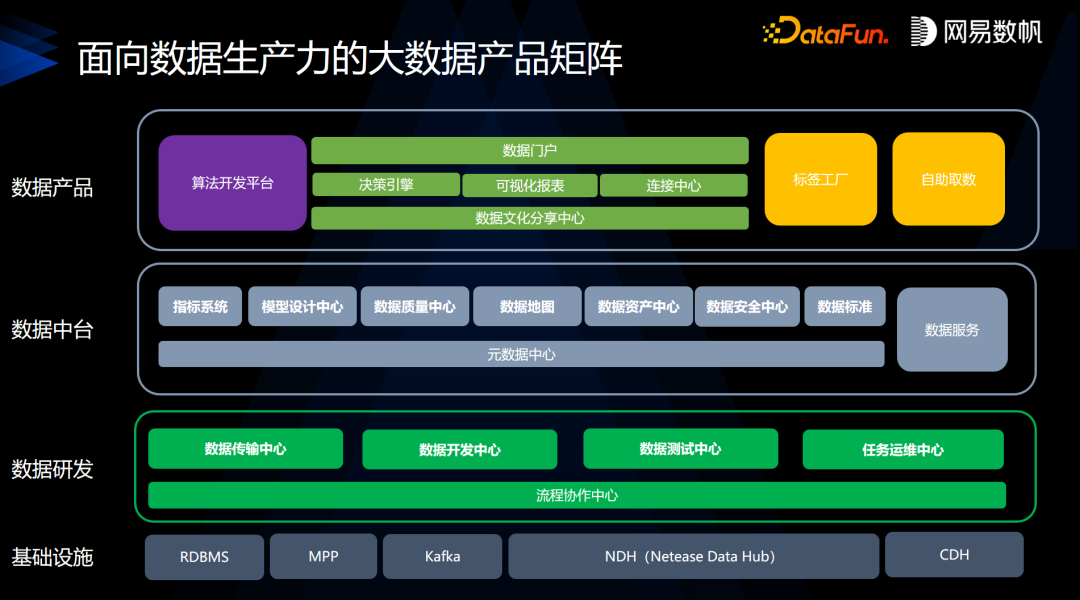
最下面是基础设施,这里有网易数帆自己的 NDH 发行版,也可以对接 CDH 或者 CDP,基础设施主要是提供存储计算能力,NDH 在回收站等方面也有加强,还做了一些存算分离、混合部署的工作。 -
在数据基础设施之上是数据研发,覆盖了从数据设计、开发、一直到测试、上线、运维的整个过程,希望能做成一个符合 DataOps 的数据研发产品。 -
在数据中台部分,我们提供了指标系统、模型设计、数据地图等产品,目的是帮助业务去建设数据中台。 -
在数据产品层,我们提供了很多工具,比如 BI 工具、数据门户,我们的理念是要利用低代码和无代码的方式,帮助用户、客户去打造面向场景化的数据产品,从而真正达成“人人用数据”的理念,实现数据生产力在企业落地。
02

-
第一个问题是指标口径不一致,很多指标同名不同义、同义又不同名,不同部门之间的沟通存在很大困难。 -
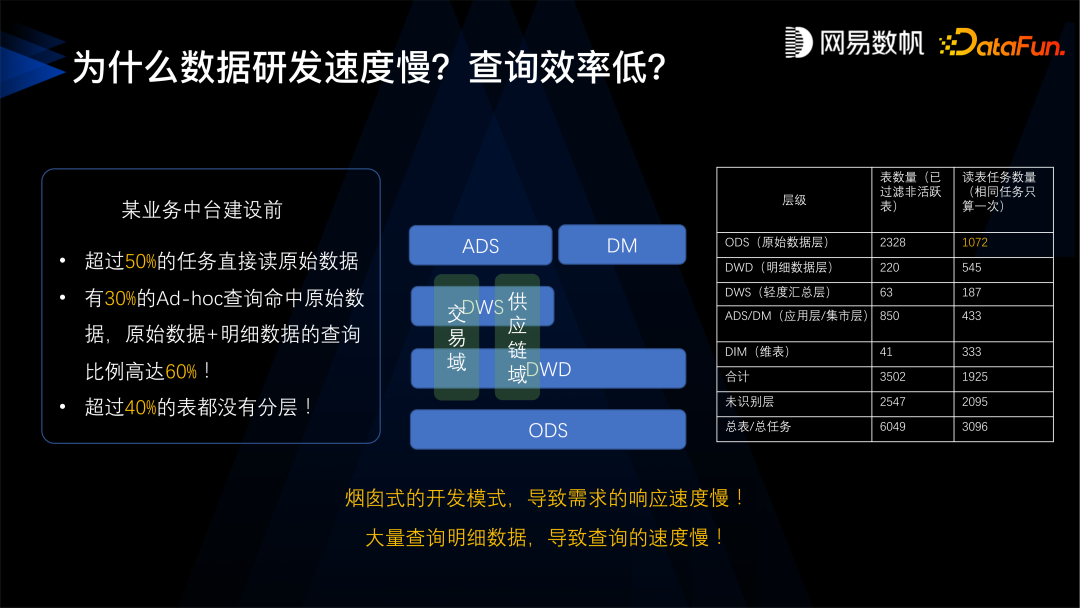
第二个问题是缺乏数据建模规范,当时我们的数据团队非常辛苦,但还是不能满足业务上的需求,交付的速度还是非常慢,平均需要一周的时间, 并且查询的效率又特别低,一个月范围内的查询要将近一分钟, 一年内的查询要 300 多秒,找数据也特别困难,业务产生了几万张表,不知道哪里有数据,不知道怎么去找、怎么去用。 -
第三个问题是数据重复建设,有超过一半的数据是冗余的,数据量超线性增长。
-
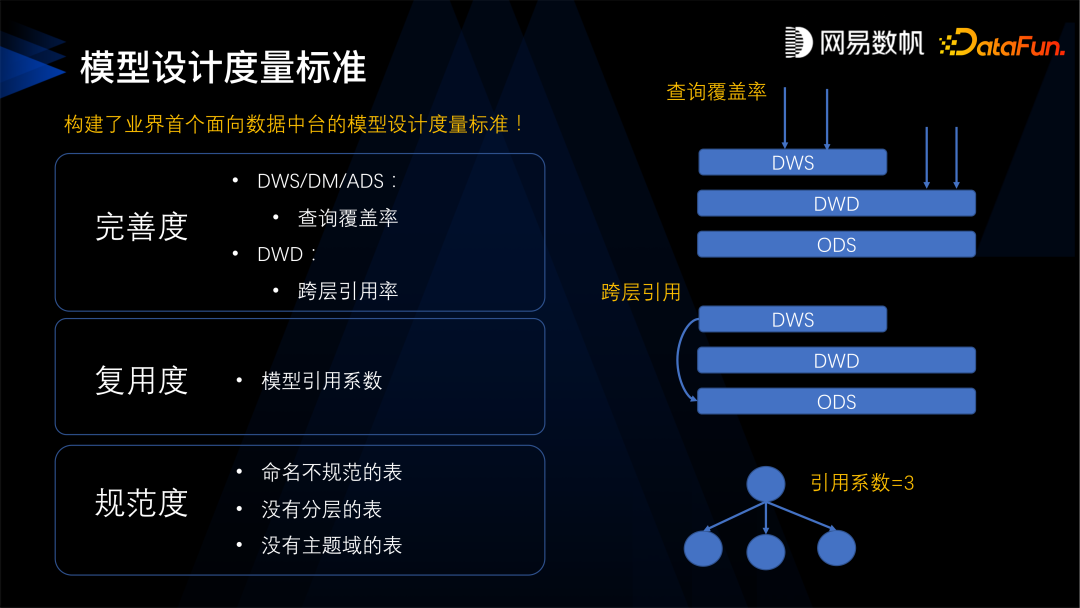
第一是完善度,可以分为两类,首先是查询的覆盖度,就是 ADS 层的表能满足多少比例的查询,这个比例越高说明建设得越完善,越能满足客户的需求;另外就是跨层的引用率,DWS 层直接引用 ODS 层,就叫跨层引用,跨层引用率越低越好,我们希望一层层往上叠加,不要产生跨层引用的情况。 -
第二是复用度,一个模型被下游模型引用的次数越多越好。 -
第三是规范度,是否存在不规范的表,没有分层的表,没有主题域的表等等。


-
投入产出低:每个业务部门都有很着急的需求,一方面是需求做不完,另一方面是做出来的很多数据没有人用,我们有时发现有超过一半的表都是 30 天内没有人访问过,不得不怀疑这样的需求是否正确; -
资源使用不合理:数据开发天天抱怨数据分析师的 SQL 写得太烂太占资源,分析师天天埋怨 SQL 跑得太慢,每周都有因为资源使用不当导致造成的事故; -
成本指数增长:不停地加机器,已经非线性增长,老板也要问,这些机器到底用在了哪些业务?产生了什么价值?哪些可以做哪些可以省略不做?

-
首先,核算每个查询任务和表存储资源,然后折算到钱。网易是做内部结算的,所以我们能够把所有的任务折算到钱,而且可以把这些钱分摊到每个数据表、报表, 分摊到每个数据的应用,这样就特别清楚了。 -
第二,采用“剥洋葱”式数据下线。从下游不再被使用的数据应用开始,逐层向上游任务和上游数据去下线。这里的下线不是马上下线,而是把它先暂存起来,让其不可访问,如果需要可以马上恢复。 -
第三,预估任务和查询成本,对高消耗的任务和查询进行审批和管控。


-
首先,建全链路的数据质量跟踪体系,从数据源到数据中台模型再到数据应用建立全链路监控。那半年里做了 1000 多个任务的监控,基本覆盖了所有重要数据源,特别是涉及资损的重要数据,保证数据正确性。 -
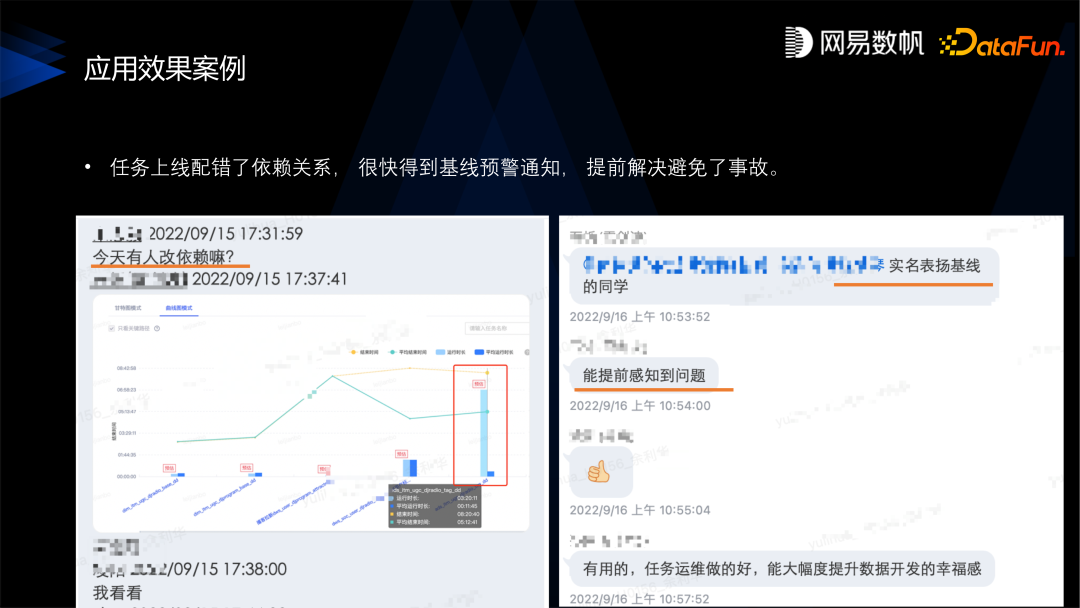
第二,构建智能基线运维体系,最早我们是基于单个任务去管,报警特别多特别繁琐难以管控,所以我们做了基于基线的运维体系,把任务划分了一些基线,把任务都挂到基线上去。为基线规定了产出时间,并且做了一个特别有用的功能——基线预警,可以提前预知到基线的问题,使得问题可以早发现早挽救,避免事故。
-
第三,任务影响分析,在真正出现了事故和延迟的时候,就需要做任务的影响分析,根据全面的血缘精准评估数据影响了哪些下游的 API、报表、应用,根据应用反推应该如何去修复高优先级的数据。



-
第一,先污染再治理,开发环节无法保证数据的出厂质量,出来的数据就不是很合格,过多依赖事后去治理数据,效率不高。 -
第二,运动式治理,缺少统一的数据治理的衡量标准,不确定效果,也缺乏持续优化的机制,这是存在于治理环节的问题。 -
第三,存在于数据消费的环节的问题是,消费者找不到、看不懂也信不过这些数据,导致数据很难被利用起来产生价值。 -
第四,只能治理大数据平台内的数据,无法管理其他系统的数据。通常互联网公司都把数据集中在大数据平台,但是我们在服务客户的过程中也发现了在很多行业不可能如此,因为他们有建设了不同系统来满足不同的场景需求, 所以我们的治理平台能不能治理大数据平台以外的数据也是一个问题。
-
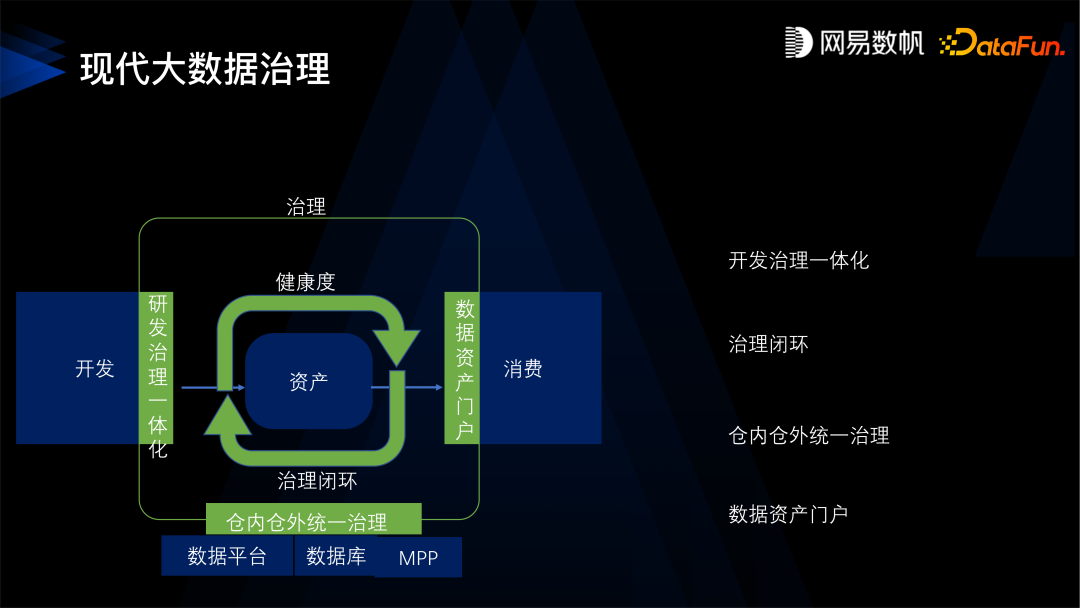
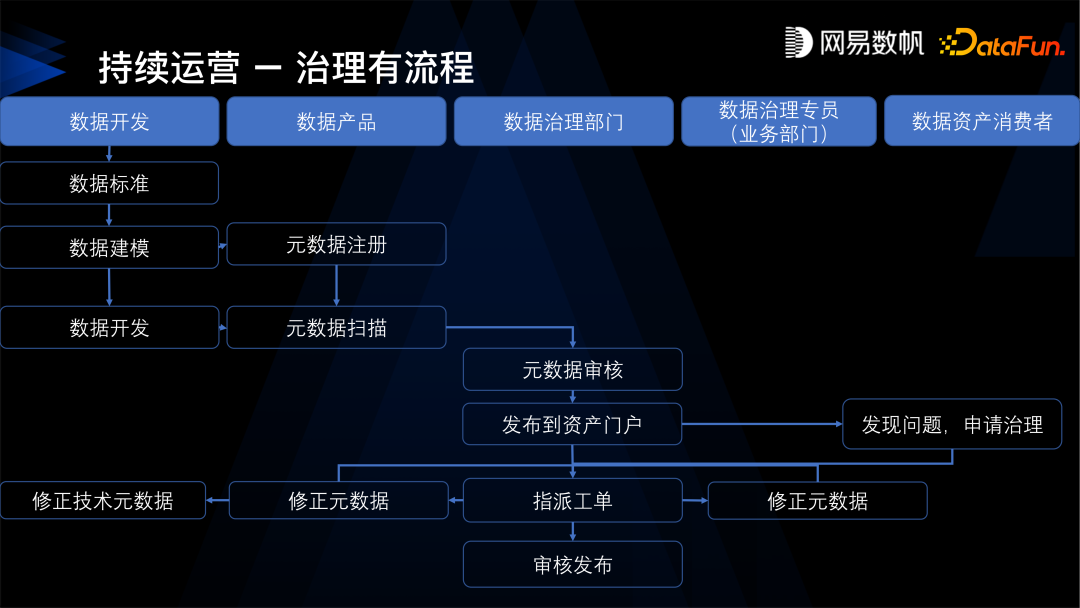
第一,开发治理一体化,从源头开始控制,实现新产出的数据都能得到治理,未来产生的数据也得到保障。 -
第二,形成治理的闭环,这点主要是针对存量的数据。 -
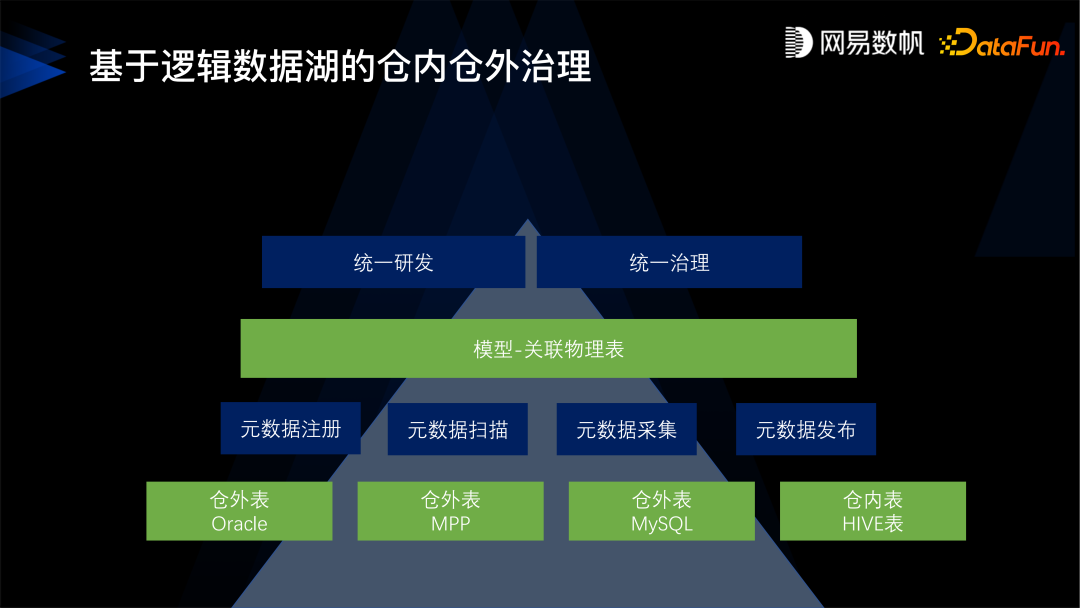
第三,仓内仓外统一治理,不仅仅是针对大数据平台内的数据,还可以治理数据库、MPP 等现存的一些非平台内的数据,非中台内的数据。 -
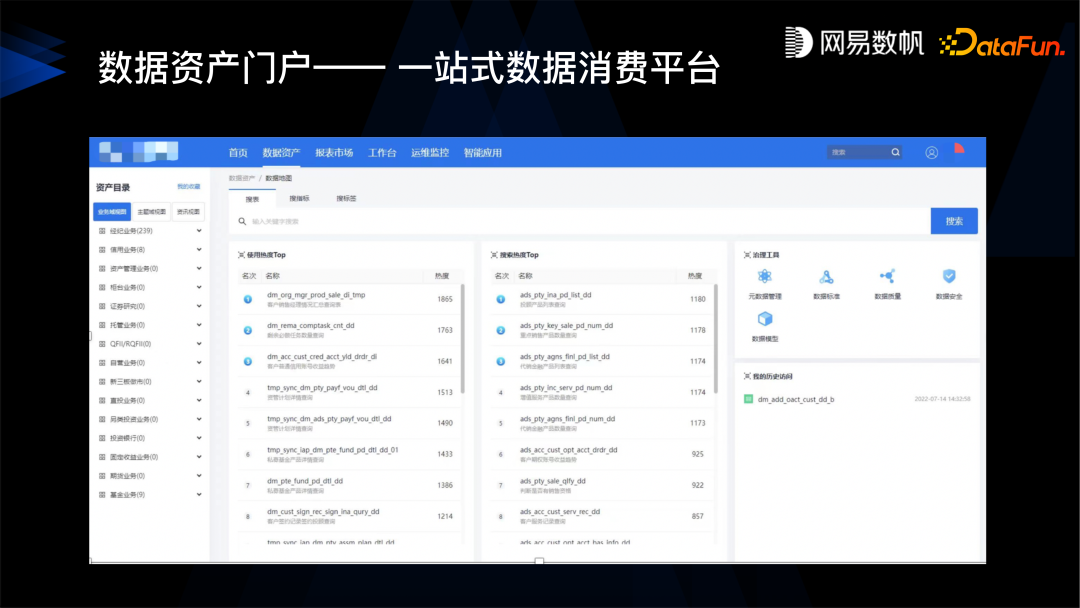
第四,建立数据资产门户,我们通过数据资产门户或者数据目录这样的方式,能够让数据更好地被消费。
-
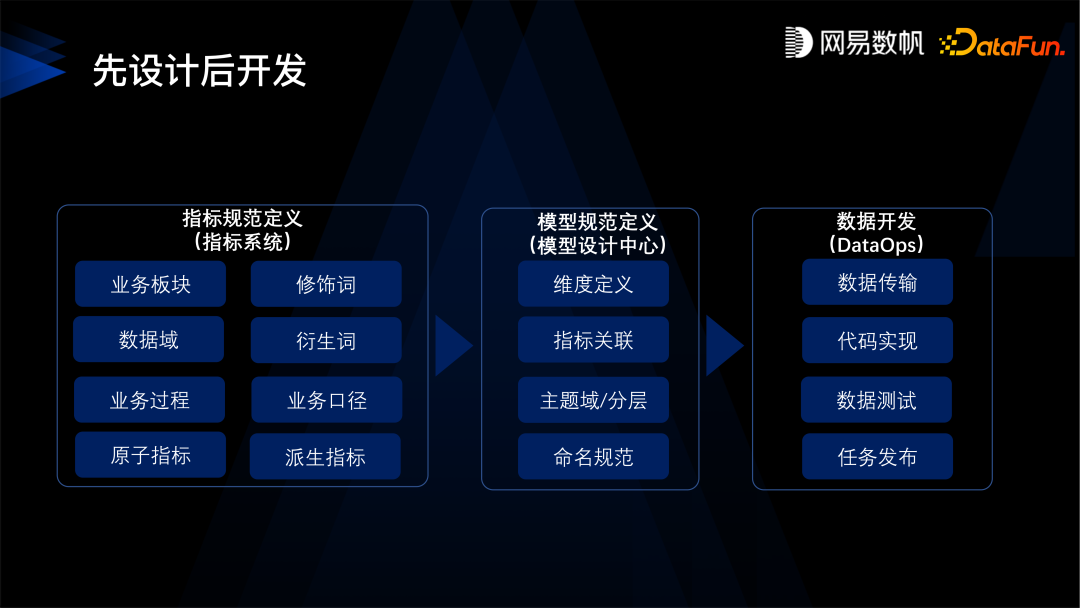
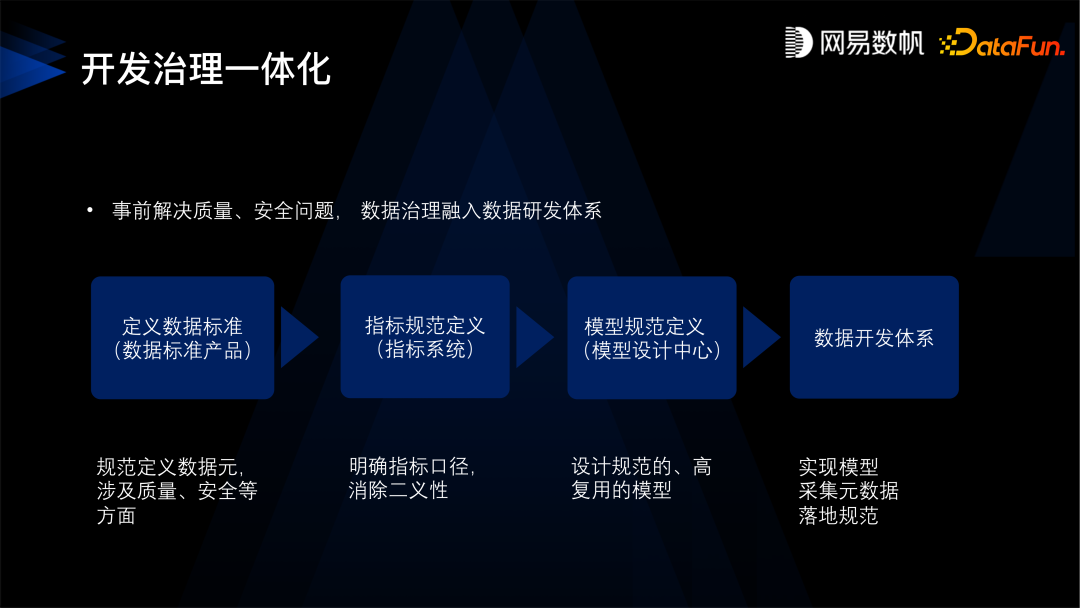
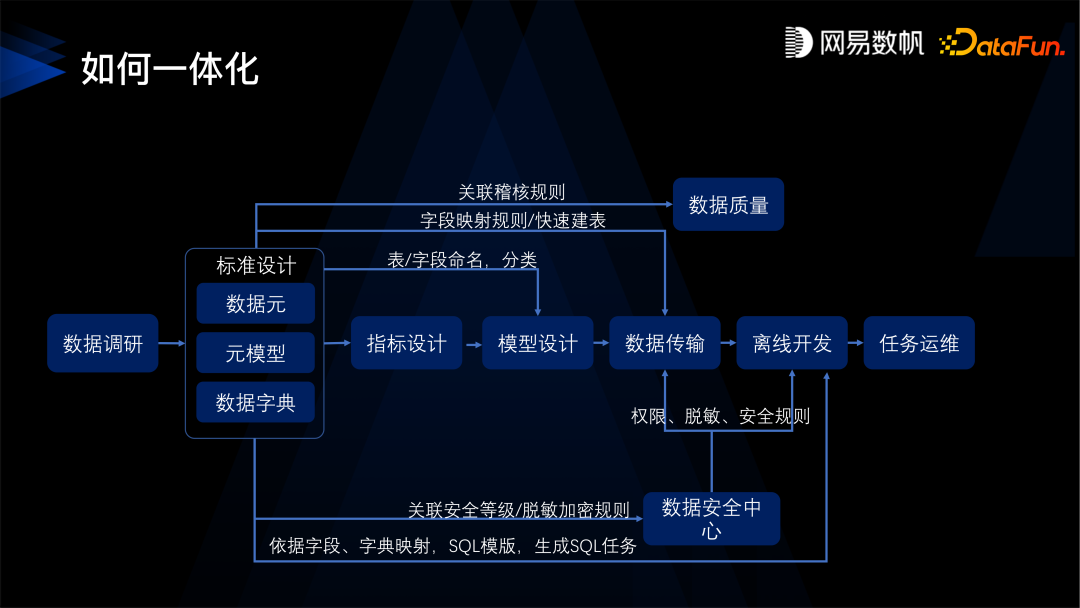
第一是要先定义数据标准,数据标准的核心是数据元,比如身份证就是一个数据元类型, 数据元就会规定它是一个字符串的类型,它的取值范围是什么样的,长度是多少,校验质量、校验规则是什么样的,还有设定身份证的隐私条件,比如是保密的,所有的质量安全规则都会绑定在身份证这个数据元上。 -
有了这样的数据元之后,第二步,是定义指标口径,明确指标的业务含义。 -
然后有了标准和指标规范之后,才是建设模型。指标规定了模型业务方面的需求,而标准规定了模型上的质量、安全规则,规定了类型和命名。 -
定义好模型之后,再进入到数据研发环节。




问答环节

|分享嘉宾|

余利华
网易数帆 大数据产品线总经理
专注数据方向十多年, 完整经历了网易大数据整个发展过程,目前负责网易有数业务。
本文转载自余利华 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/N-0Y-cmbmyNFTEkATiEejg。