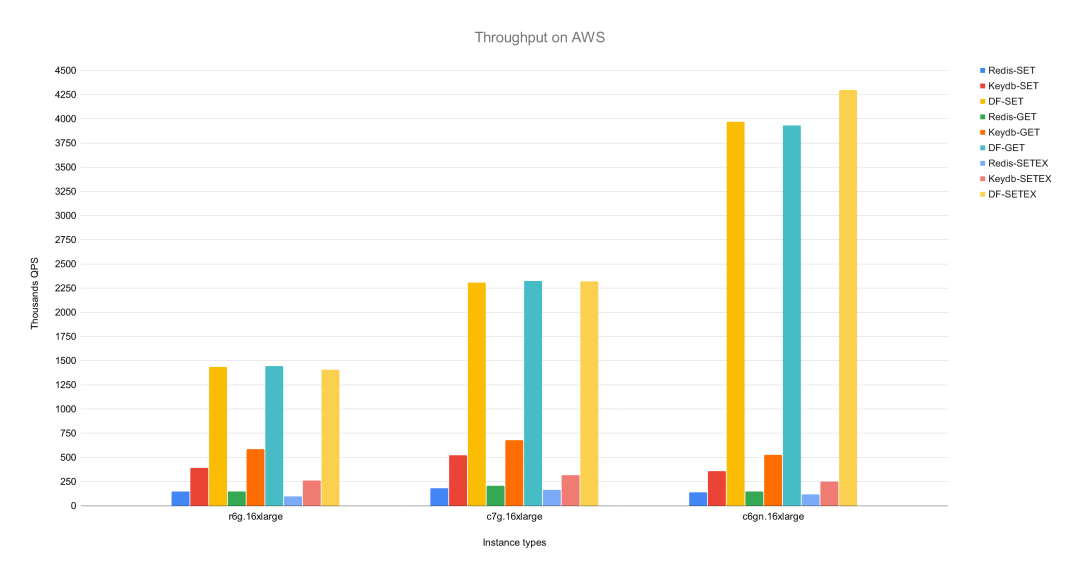
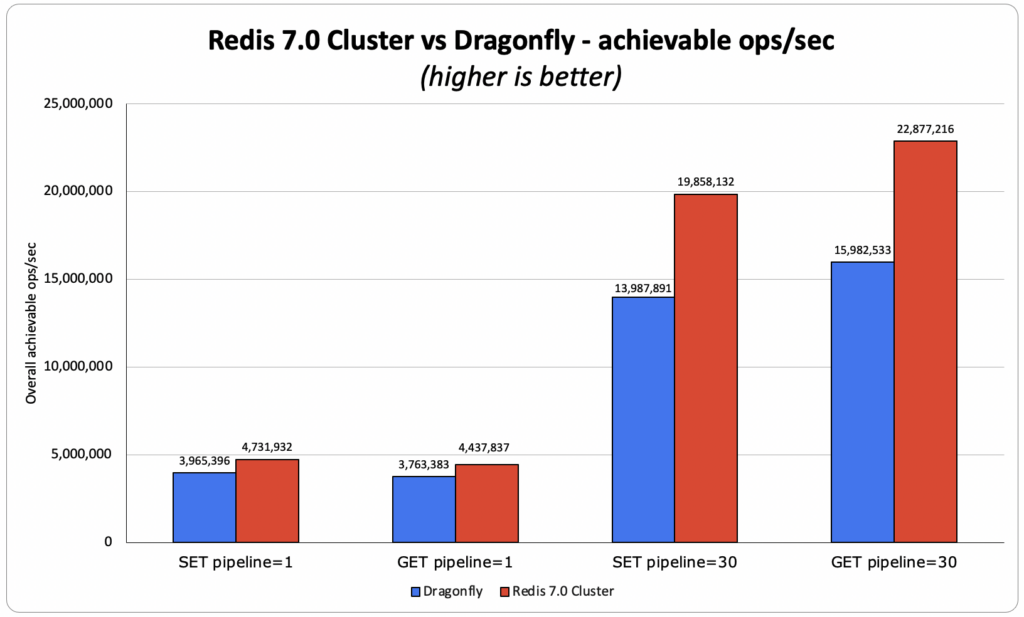
PubSub(发布订阅)在上文中有详细的介绍,解释了在 Tair 中如何利用多线程的方式做加速来优化单节点的 PubSub 机制的,这里不再赘述。同样的,在集群模式下的广播式 PubSub 也做了相应的优化策略。这个策略的专利还在流程中,这里不便多说。
说了这么多,看起来 Tair 都是在用多线程的手段来解决这些问题的。那么在 Tair 看来多线程才是正确的设计吗?是,也不是。我们认为这个争论其实没有意义。工程里充满着妥协与折衷,没有银弹。外部的讨论一般都是集中于单一的场景(比如普通的读/写请求跑分),只从纯粹的技术角度来看待架构的发展和技术的权衡。而 Tair 作为一个贴身业务,诞生于双十一的实际需求、和业务互相扶持着一路走来的存储产品,希望从业务视角给这场“模型之争”带来更多的思考。毕竟技术最终还是要落地业务的,不能片面的追求架构美而忽视真实的世界。我们需要根据用户实际的存储需求不断的打破自己的边界去拓展更多的使用场景。再者,单线程节点通过集群扩展和单节点通过线程扩展不是一个完全对立的问题。Tair 的单节点形态既可以是单线程(命令执行单线程,后台线程和功能性线程保留),也可以是多线程模式(我们全都要)。不同的模型可以适应不同的场景,现实世界不是非黑即白的,往往比有技术洁癖的码农心里所想象的世界要复杂很多。我们依旧要面临业务架构积重难返的客户,面临对 Redis 不甚熟悉但是要完成业务需求的客户,关键时候我们都得能拿出方案帮助客户去过渡或者应对突发情况。Tair 永远会朝着用户需要的方向比社区多走一步,我们认为这是作为云服务和用户自建相比的核心价值之一。
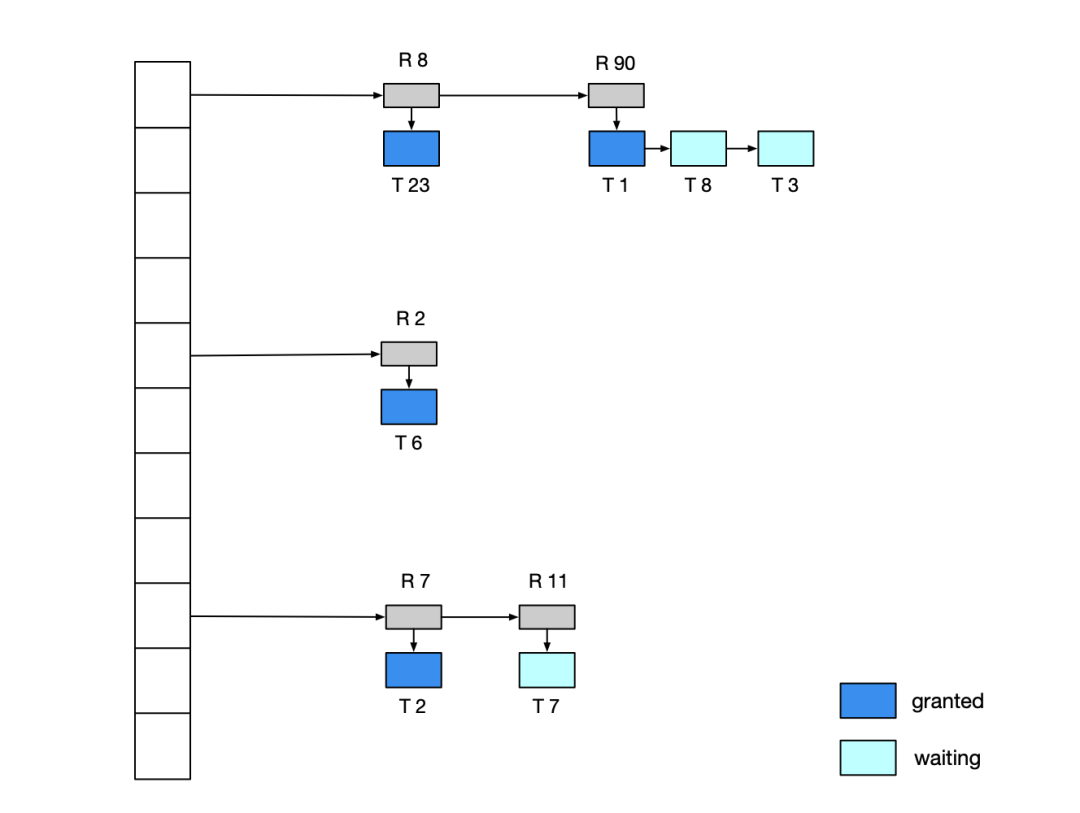
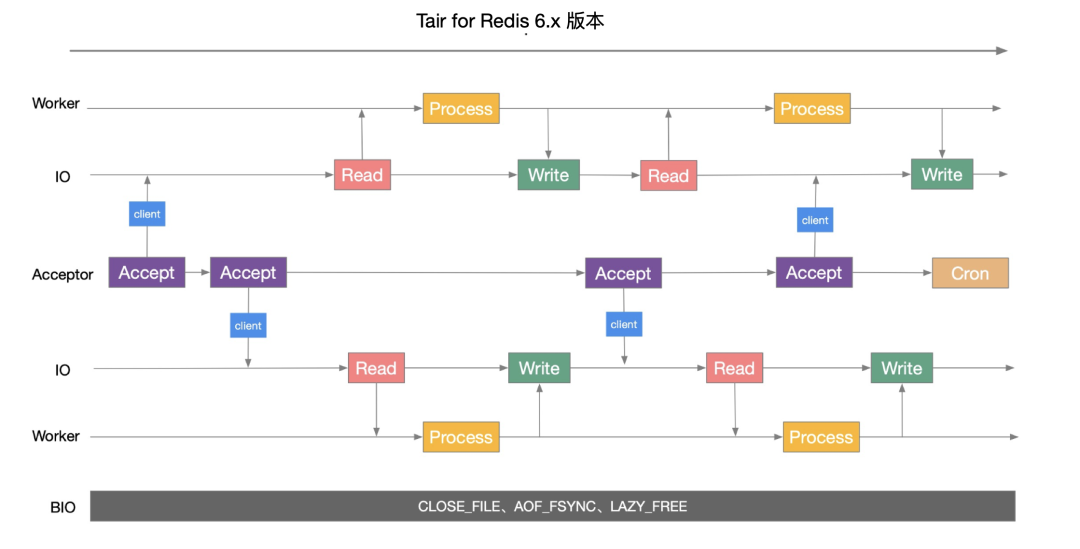
单纯在内存中实现一个线程安全的 HashMap 不算什么困难的事情。不过根据 Redis 的接口语义,这个 HashMap 还得实现两个特性:「渐进式 rehash」以及「并发修改过程中的无状态扫描」。前者是因为单个 Hash 存储的数据会到千万甚至亿条,触发引擎 rehash 的时候不能一蹴而就,必须是随着其他的数据操作渐进式进行的。后者是因为 Redis 支持使用 scan 接口来遍历数据,并发修改中这个遍历过程可以重复但是不能遗漏。Dragonfly 在官方文档里也坦言是参考了《Dash: Scalable Hashing on Persistent Memory》[6]这篇论文的思路。当然这个核心的存储不见得一定是 Hash 结构,社区也提过 RadixTree 的想法。这个领域的讨论也很多,比如 B+ Tree 的一些变体CSB+ Tree、PB+ Tree、Bw Tree 以及吸收了 B+ Tree 和 Radix Tree 优点的 MassTree 等等。Tair 的存储引擎是在不断变化和调整的,以后可以在另一篇文章中更系统的聊聊这个话题。并发引擎的设计难点不仅仅是数据结构层面,除了高性能的实现之外,服务的抖动控制、可观测性以及数据流和控制流的隔离与联动也是至关重要的。有了支持并发的存储引擎,上层还需要对处理事务的并发控制。这里并发控制机制所带来的开销与用户的请求没有直接关系,是用于保证事务一致性和隔离性的额外开销。之前有提到过 Redis 的事务隔离级别是 Serializable(序列化),那么想做到完全的兼容就必须保持一致。内存数据库和传统基于磁盘的数据库在体系结构上有很大的区别。内存事务不会涉及到 IO 操作,性能瓶颈就从磁盘转移到了 CPU 上。比较成熟的并发协议有:轻量锁、时间戳、多版本、串行等方式。大多数的 Redis 兼容服务还是采用了轻量锁的方案,这样比较容易做到兼容,Dragonfly 的实现是参考了《VLL: a lock manager redesign for main memory database systems》[7]里的 VLL 方案。不过从支持的接口[8]列表看,Dragonfly 尚未完全兼容 Redis 的接口。完全的 Redis 接口兼容性对 Tair 来说是至关重要的,这里简单介绍下 Tair 采用的轻量锁方案。一般情况下,处理 KV 引擎的事务并发只要保证在 key 级别上串行即可,轻量锁方案都是实现一个 Hash Lock Table,然后对一个事务中所有涉及到 key 进行加锁即可。这个 Hash Lock Table 类似这样:Hash Lock Table 的实现本质上是个悲观锁机制,事务涉及的 key 操作都必须在执行前去检查 Hash Lock Table 来判断是锁授权还是锁等待。如果事务涉及到多个 key 的话加锁的顺序也很重要,否则会出现 AB 和 BA 的死锁问题。工程上常规的做法是要么对 key 本身进行排序,要么是对最终加锁的内存地址进行排序,以保证相同的加锁顺序。
Tair 慢查询隔离
在 Tair 完成了 Redis 兼容引擎的事务并发支持后,针对慢查询请求的隔离需求便提上了议程。首先是识别,数学上的时间复杂度无法衡量真实的执行代码,还需要每个数据操作指令自定义复杂度公式,结合引擎查询计算复杂度。假设我们定义 C 表示参数的数量(argc)或范围(range),K 表示单个 DB 下的 KeyCount,M 表示该种数据结构的内部成员数量(比如 list 的 node 数量,hash 的 field 数量等等),一些命令的代价计算公式如下 :
keys -> O(K)
sort -> O(M+M*log(M)) | M*log(M)
lrange -> O(M) | O(C)
sinterstore -> O(C*M)
hgetall -> O(M)
zinterstore -> O(M*C)+O(M*log(M))
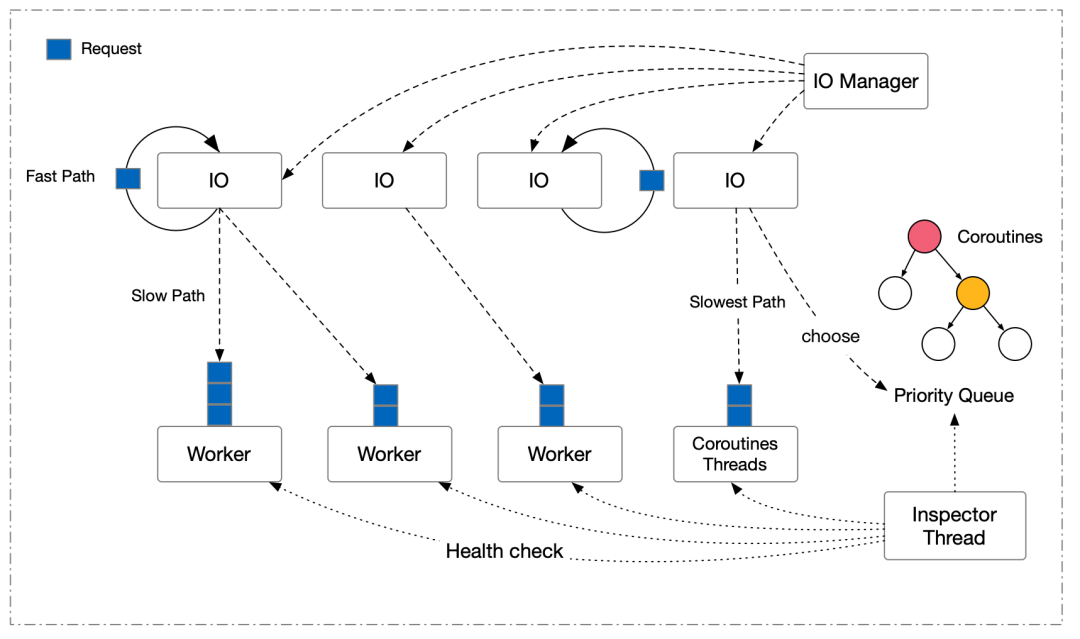
当引擎能估算识别请求的执行代价后,那么将这些必然会触发慢查询的请求隔离出去就可以了。Tair 在原本的 IO/Worker 线程之外,抽象了一组慢查询协程来处理这类慢查询的请求,整体的模型如下:请求被分为 Fast Path,Slow Path 以及可能造成严重阻塞的 Slowest Path 三类。Fast Path 直接在 IO 线程上执行并返回,Slow Path 在单独的 Worker 线程上计算(最后回到 IO 线程上回包),Slowest Path 是引擎的代码估算系统得出的慢速请求,会被投递给专门的 Coroutines Threads 处理。这里重点介绍下 Coroutines Threads,本质上这是一组协程和线程以 M:N 模型进行协作的抽象,每个慢速请求会创建一个新的协程加入到优先队列里被调度执行。使用协程切换的目的是希望慢查询本身也是有优先级的,次慢的查询理应比更慢的查询尽早返回,而不是简单的 FCFS(First Come First Serve)策略。协程的选择有无栈协程(Stackless)和有栈协程(Stackful)两种,有栈和无栈最大的区别就在于编程模型和资源占用上。使用有栈协程可以在任意的函数位置进行协程切换,用户态一次纯寄存器的上下文切换仅在 10 ns 上下,远低于操作系统上下文切换的开销(几 us 到上百 us )。为了不对原始代码进行过多的修改,Tair 选择了有栈协程进行任务的封装与切换,同时为了降低极端场景下的内存开销,也提供了共享栈协程(Copying the stack)的选项以支持时间换空间。Tair 是一个多引擎的服务,有内存和磁盘等不同的介质,所以这三类线程是根据实际的需求创建的。比如内存模式就只分配了 IO 和 Coroutines 线程,涉及到磁盘形态的存储才会使用 Worker 线程池。因为内存形态下请求处理的很快,此时 IO 线程直接处理快速的查询要比和 Worker 线程池的任务交互带来的 2 次上下文切换开销更划算。