
导语 | 本文对完美Hash的概念进行了梳理,通过Hash构建步骤来了解它是如何解决Hash冲突的,并比较了Hash表和完美Hash表。下面介绍常见的Hash与Perfect Hash函数及它们在不同场景的应用。
引言
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。
Hash函数是一种将集合S转换成具有固定长度的、不可逆的的集合U的单射,它的值一般为数字合字母的组合,Hash函数拥有无限的输入空间,却只有有限的输出空间,这意味着 Hash函数一定会产生碰撞,一个好的Hash函数可以显著的降低碰撞概率。Hash函数一般有一下特征:
-
一致性。Hash函数可以接受任意大小的数据,并输出固定长度的散列值,同时输出不同值的概率应该尽可能一致。如CityHash128,不管原始数据有多大,计算得到的hash值总是128 bit。
-
雪崩效应。原始数据哪怕只有一个字节的修改,得到的hash值都会发生巨大的变化。
-
单向。只能从原始数据计算得到hash值,不能从hash值计算得到原始数据。所以散列算法不是加密解密算法,加密解密是可逆的,散列算法是不可逆的。
-
避免冲突。几乎不可能找到一个数据和当前计算的这个数据计算出一样的hash值,因此散列函数能够确保数据的唯一性。在Hash函数保证不同值出现的概率一致的情况下,CityHash128出现碰撞的概率只有2^-128。因为不同Key的碰撞概率很小,所以在某些情况下我们可以直接使用较短的Hash值代替较长原始数据存储。


一、Hash函数
常见的Hash函数有:
-
CRC32:CRC32能够快速的生成32位Hash值,一般在数据库系统或数据传输中出现,用于快速校验数据是否完整。
-
SipHash:SipHash并不是为了速度设计的,与其他Hash函数相比速度上不占优势,而提供了HashDoS保护,是Rust中的Hash函数的默认实现,最新Redis中也在使用SipHash。
-
MurMurHash:经典快速的Hash函数,目前最新的版本是 MurMurHash3,可以生成32位或者128位Hash值。
-
CityHash:来自于Google实现,受到MurmurHash启发,但是比 MurmurHash更快,可以输出64位、128位或者256位Hash值。ClickHouse内置。
-
xxHash:针对小数据集速度非常快,支持输出32位、64位、128位Hash 值,Github开源,SSE支持。ClickHouse内置。
xxHash的benchmark,统计了常用Hash函数的性能:

常见用法:
Hash表:通过Hash算法将Key均匀映射到不同的位置上,访问单个key时可以达到O(1)的平均时间复杂度,加快访问速度。
二、安全Hash函数
安全Hash函数(或者叫加密Hash函数)是一种优秀的Hash函数,无法(或者很难)通过Hash值猜测出Key,更精确的说,安全Hash必须满足抗碰撞和不可逆两个条件:无法通过Hash值的统计学方法逆向,以及无法通过算法层逆向。常见的安全Hash算法包括:
-
SHA2,SHA3系列
-
BLAKE系列
SHA0、SHA1、MD5算法已经被认为是不安全的,存在已知的漏洞,不要使用这些不安全的Hash函数来签名。
常见用法:
安全Hash函数广泛应用于数字签名技术中:对原文进行Hash后,将Hash结果通过私钥签名,避免原文被泄露或者被修改。
工作量证明:如加密货币中挖矿就是通过给定值,计算符合条件的Hash输入。
文件ID:在网站下载地址旁往往提供了文件的MD5或者SHA-1,确保下载的文件完整且没有被调包。
三、HashDoS与全域Hash
(universal hash)
全域Hash解决的是确定性Hash算法无法应对特殊输入的问题。在链式HashMap里,假设m=bucket size,考虑我们有输入集合S和Hash函数 H,其中H=H’% m,攻击者在知道Hash函数的情况下,容易构造集合S使得集合中每一个元素的Hash值相同,那HashMap会退化成链表。最坏情况下,HashMap查找的时间复杂度变成了O(n),插入n个元素时需要 O(n2) 的时间复杂度,所以也叫HashDoS攻击。
全域Hash解决的问题是:对于精心构造的输入,冲突率仍然在1/m。一个简单的想法是随机选一个Hash函数,不是在每一次操作时选一个,而是在输入前选一个Hash函数,之后所有的操作都基于该Hash函数。当然H也不是随便定义的,具体来说是在|H|个Hash函数H中随机的选择一个Hash函数作为所有key的Hash函数,H中所有的Hash函数H’对于不相等的关键词x和y,使得H’(x)和H’(y)值相等的函数H’的数量个数等于|H|/m,此时冲突概率为 1/m。
四、完美函数
传统的Hashmap总会有分支预测开销与内存对比,最差时间复杂度是O(n),有那么一种Hash函数:完美Hash函数(Perfect Hash Function,PHF),它可以在最坏情况下取得O(1)的时间复杂度。当然鱼和熊掌不可兼得,完美Hash要求有一个静态的输入集合,查找的Key必须存在于静态输入集合中,导致使用场景受限。它有几个特点:
-
完美Hash大部分都要求输入Key的集合是已知的,用于提前构建数据结构。
-
构造算法复杂,大部分情况下需要比较大的内存,特别是时间复杂度高,需要很长的时间建立索引,构建海量key的完美Hash可能会失败。
-
完美Hash在实现上并不是只有一个Hash函数,而是多个普通Hash函数与数据结构算法上的组合,这意味着需要额外空间存储Hash冲突信息。
-
尽管它有一些缺点,但是在一些场景如汉字拼音映射,词典,以及程序中预定义的映射关系都有它的应用。
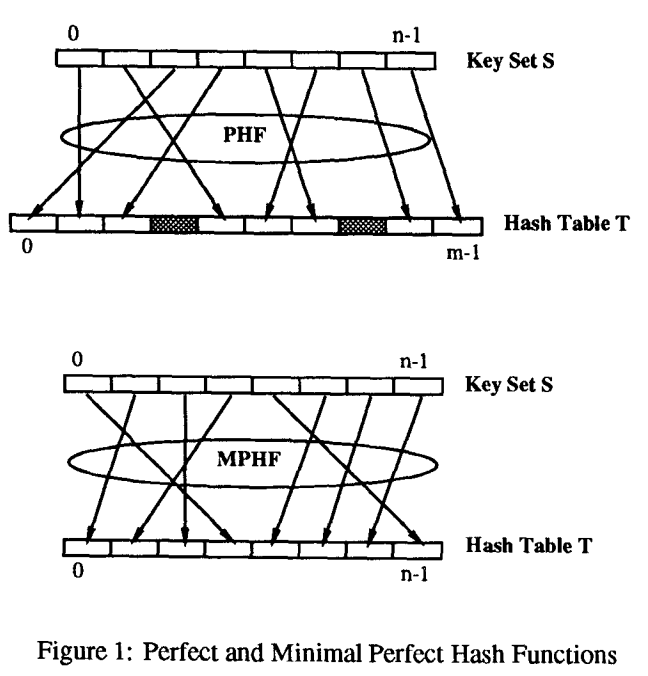
Perfect Hash Function对于给定的集合S,可以将S中所有的Key映射到整数[0, m)中,其中m>=|S|。当m=|S|时,称为最小完美Hash函数(Minimal Perfect Hash Function, MPHF)。即作为一个特例,如果完美Hash可以将N个key映射到0到N-1的整数,那它可以被称为最小完美 Hash函数。
更进一步,如果Hash后给出key的顺序没有发生变化,称为完美Hash函数是保序的。
如果一个Hash函数在给定区域不超过t次冲突,那这个Hash函数称为t-完美 Hash函数。
目前开源的Perfect Hash库有:
-
cmph:C/C++,集合了大部分知名完美Hash算法的库,针对不同的数据集合有推荐不同的算法,参数可调,文档不多,LGPL协议。
-
gperf:C/C++,专门针对于小数据集完美Hash的生成库,GPL协议。
-
rust-phf:使用CHD算法生成完美Hash,使用简单,10w个key只需0.4s就能生成。
下文会讨论FCH,CHD,PTHASH是如何巧妙解决了Hash冲突并实现了最差O(1)时间复杂度的。
完美Hash首先需要离线构造得到Hash冲突的信息离线保存下来,需要查询时,利用先前生成的信息计算得到唯一的整数Hash value。
在描述算法之前,先假设:对于已知大小n=|S|的输入集合S,已知的负载因子alpha和参数c,table的数量table_size=n*alpha,桶的数量m=cn/(log2 n+1)。一般来说,c在2-8左右,确保每个桶有合适数量的 key,同时不会空出太多的桶。最终所有的key会映射到 [0, table_size) 中的整数。当alpha=1,table_size=n,为MPHF。
(一)FCH
A Faster Algorithm for Constructing Minimal Perfect Hash Functions由Fox,Chen,Heath发明的一种生成完美Hash的算法,FCH 是一个相当经典的Perfect Hash的实现,后续多种算法均受到FCH算法的启发。
FCH是一种基于二级Hash表的完美Hash函数:将数据通过一级Hash映射到T空间中,然后冲突的数据随机选取新的哈希函数映射到S空间中,且S空间的大小m是冲突数据的平方(例如T2中有三个数字产生冲突,则映射到m为9的S2空间中,m即为避免桶内Hash冲突的参数),此时可以容易找到避免碰撞的哈希函数(这个避免冲突的过程称为position或者displace)。最差情况下所需存储空间为O(n2),但只要适当选择哈希函数减少一级哈希时的碰撞,则可以使预期存储空间为O(n)。
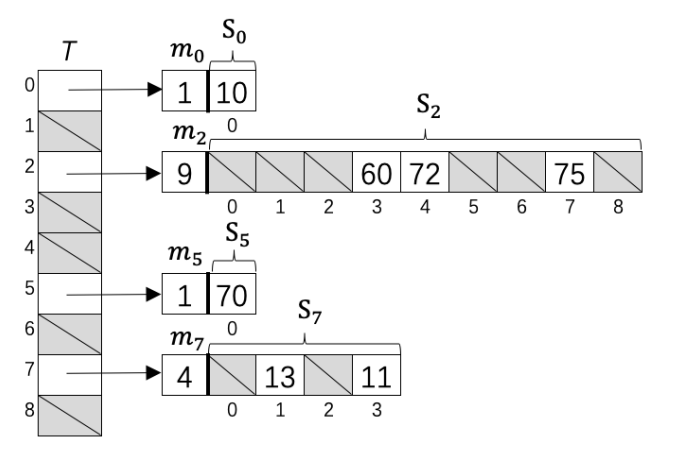
构造FCH需要分为三个步骤:
-
Mapping
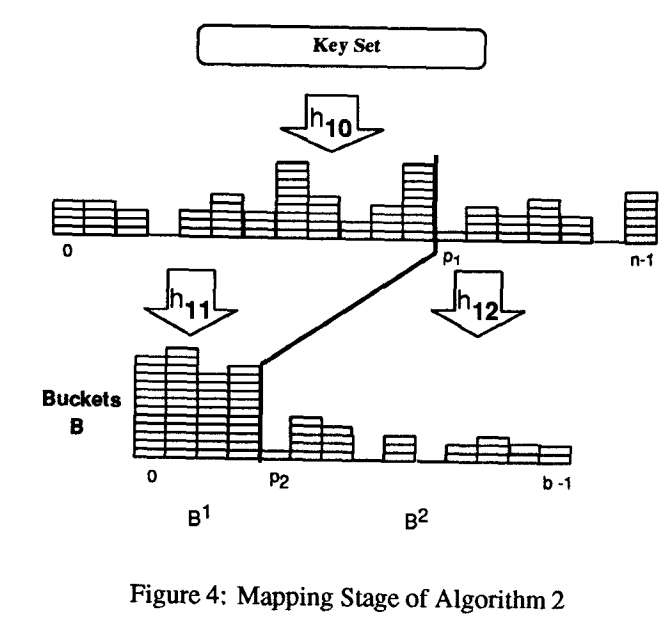
Mapping阶段为了将60%的key分布到30%的桶里,将n个key分为S1和S2两个集合,其中S1称为dense set,key的数量大概保持在0.6*n,S2为 sparse set,key的数量大概在0.4*n左右。同时,把所有桶分为两个部分B1和B2,B1数量p2=0.3*m,称为dense buckets,B2数量0.7*m,称为sparse bucket。使用普通的Hash函数如Cityhash/MurmurHash,将S1通过H1映射到B1中,同样道理将S2通过H2映射到B2中。
用数学语言描述:
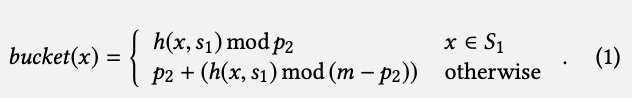
-
Ordering
Ordering阶段将所有的桶按照桶内冲突的数量排序,冲突数量最多的桶放在最前面。
-
Searching
Searching阶段会依次处理每个桶里的冲突,尝试将不重复的Hash值分配给每一个key。经过了上一个阶段排序,该阶段会优先处理冲突最多的桶。对于每一个桶,尝试参数di, bi,给桶内每一个key分配Hash值position(x, di, bi)=(h(x,s2+b1)+di) mod table_size,这个值在 [0,table_size) 之间,其中s2是全局随机种子,bi是单个bit,di是一个从0开始的递增的整数,如果Hash值在桶内和之前计算过的Hash值冲突,则改变bi或者di直到 Hash值不发生冲突(为了加速di的寻找,原始论文中提出了辅助数据结构和压缩方法,感兴趣可以参考论文)。

处理完冲突后,最终可以得到m个参数bi,di存入P数组中,只占用大概m*((log2 n)+1) =cn bit (这只是理论上的结果,如何存储bi和di不在我们讨论范围内),即每一个key只占用了c个bit。
查询时:对于给定的key,计算一级Hash,得到桶编号,通过该桶的bi,di 和全局s2参数来计算二级哈希,即完成了一次查找,可以发现,任何key的查询步骤都时相同的,没有循环,即所有步骤都是确定的O(1)。注意到这里无法判断key是否存在。
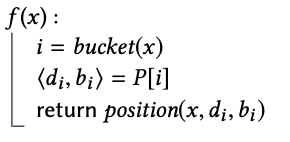
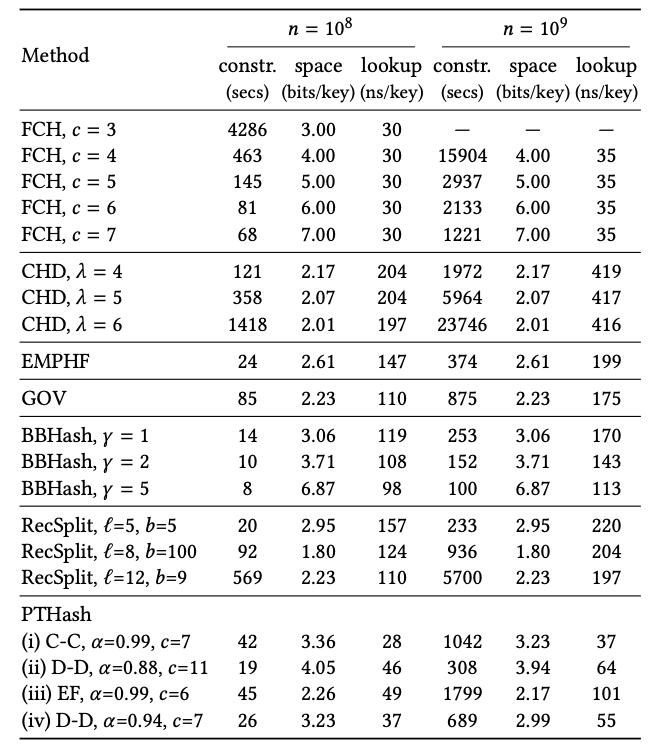
在FCH中,c越大,构造越快,但是空间利用率越低,特别是FCH寻找 MPHF需要耗费巨量的时间:c=3时,1亿uint64的数据需要花费1小时以上生成,所以它并不是一个实用的算法。
(二)CHD
为了解决FCH构建过慢的问题,出现了基于FCH思想的CHD,一种实现简单的Perfect Hash算法,支持MPHF,空间利用率更高,但lookup更慢。
主要不同地方:使用通用Hash函数计算出为每一个key计算出三个Hash 值:h,h0,h1,h用来表示桶号,h0、h1用来计算最终的position,position定义为position= (h0+ (h1*d1)+d0) mod table_size。
与FCH相同,CHD一共分为三个阶段:
-
Mapping
Mapping阶段不需要像FCH拆分两个集合,而是直接映射到一个集合中。
使用c++来描述:
buckets.resize(m);for (auto key : keys) {auto [h, h0, h1] = hash(key);buckets[h].hash = h;buckets[h].keys.push_back(make_tuple(h0, h1));}
-
Ordering
与FCH相同
sort(buckets.begin(), buckets.end(), [](auto &lhs, auto &rhs){return lhs.keys.size() > rhs.keys.size();});
-
Searching(也叫displace)
Searching阶段同样是处理每个桶里的冲突,不同的是position函数发生了变化:为每一个桶初始化一个pilot,其中pilot=d0*table_size+d1,使用position公式计算key的Hash值,发生冲突时,pilot加上一(相当与d1加上1,此时position的结果会发生较大的变化)重新计算position直到桶里所有key都不发生冲突。
bool_vector position_used, position_used_in_bucket;vectorp; // 结果数组 position_used.resize(table_size);position_used_in_bucket.resize(buckets[0].keys.size());p.resize(m);for (auto &bucket : buckets) {if (bucket.keys.size() == 0) continue;// 单个桶 pilot = d0 * table_size + d1int d0 = 0;int d1 = 0;while(true) {bool ok = true;position_used_in_bucket.clear();for (auto [h0, h1] : bucket.keys) {uint64 position = (h0 + (h1 * d1) + d0) % table_size;if (position_used[position]) {// hash 结果冲突,换一个 pilotok = false;break;}if (position_used_in_bucket[position]) {// 桶内 hash 结果冲突,换一个 pilotok = false;break;}position_used_in_bucket[position] = true;}if (ok) {// 单个桶处理完毕position_used.union(position_used_in_bucket);// pilot 存到 p 数组中p[bucket.h] = d0 * table_size + d1;break;}d1++;if (d1 >= table_size) {d1 = 0;d0++;if (d0 > table_size) {// 构建失败,找不到一个可用的 pilotthrow ...}}}}
最终得到的m个pilot存入P数组中。
查询时:对于给定的key,使用固定出的Hash函数计算出h,h0,h1,根据P[h]得到pilot与d0,d1,使用poisition易求得Hash值,即完成了一次查找(至少4次除法or求余操作,h
auto [h, h0, h1] = hash(key);auto pilot = p[h];auto d0 = pilot / table_size;auto d1 = pilot % table_size;return (h0 + (h1 * d1) + d0) % table_size;
结果集P中,pilot往往很小,有压缩空间,在作者的论文中,为了压缩P数组的大小,采用FN Encoding,可以压缩到2.08 bit/key的开销,自己的实现可以直接用bit vector(aka compact) 压缩,实现起来更简单。
compact压缩:给定一系列整数S,已知S中最大的整数x需要使用y个bit表示,我们可以将所有的整数都通过固定y bit来表示而不牺牲精度和访问时间。
CHD算法比较简单,Github上也有不同语言的实现,rust语言的实现。Go 语言实现。
(三)PTHash
虽然CHD实现简单,但其中包含了大量除法求余计算,Encoding后效率并不高,lookup耗时过久。最近有一篇文章提出了PTHash方法,在FCH上改进了构建时间,并提高了空间利用率,作者还提供了源代码供参考。
设计思路和FCH相似,只不过position定义变成了position(x,pilot)= (h(x,s) xor h(pilot,s)) mod table_size,其中h是普通Hash函数,x是key,s是全局种子。与FCH相比可以提前计算所有key的Hash h(x,s),节约构造时间。使用compact压缩方式效果很好,lookup耗时也能达到FCH水平。
-
Mapping
与FCH相同
-
Ordering
与FCH相同
-
Searching
使用新的公式计算position,得到n个pilot,由position公式定义,可以发现大部分pilot都是比较小的值,作者还介绍了一种Front-Back Encoding,将结果集前30%拆分成front集,后 (1-30%) 拆分为back集,代价是运行时多一次分支判断。
由于front集合里的桶是最先处理冲突的,冲突发生次数低,大部分pilot都比back集合内的要小,压缩率更高。将Front和Back集合里的pilot通过 Compact编码后,称为Compact-Compact Encoding。
查询时,按照bucket id确定去front还是back集合查询pilot,不考虑解压过程,只需要两次除法or求余操作。
当然这里也可以牺牲部分空间,不做Front-Back Encoding以取得更快的查询速度,根据不同的Encoding方式,可以在时间&空间上取得平衡:

benchmark:
五、HashMap
HashMap本质上是根据给定的key获得value的地址。设计核心主要在于:
-
HashMap的空间开销:key和value如何组织?单个key需要多少额外空间存储元信息?
-
HashMap的查询与插入:如何通过key计算出value的地址?冲突如何处理?
不同的HashMap不同点在于冲突如何处理,除了常规可读可写的 HashMap,存在只读HashMap,存储更小,性能更优。
(一)常规HashMap
在各个语言都有内置的HashMap实现,除了使用不同的Hash函数,不同实现对Hash冲突的解决方案也不同:
-
拉链法:每一个桶都存着链表的head节点,冲突key将会被插入链表。
-
升级红黑树:Java8在链表长度超过8时转换成红黑树。
-
线性探测法:发现冲突时向后找到第一个没有占用的桶存储,缓存命中率高,负载因子越高,插入效率越低。
-
多级Hash法:单次Hash结果冲突时,换一个Hash函数直到Hash值无冲突。
(二)F14&B16系列HashMap
F14 & B16是一种利用SIMD技术进行查找的链式HashMap,它为每一个 Key计算两个Hash值:H1和H2,H1决定Key放在哪一个桶里,H2用来处理桶内冲突,一般要求负载因子比较高,以获得较高的空间利用率。同时对桶内的H2通过SIMD指令对比,一次对比14个key或者16个key,相比 PerfectHashMap,它可以支持动态插入,但是查找性能不如 PerfectHashMap。
(三)PerfectHashMap
有没有办法把Prefect Hash利用起来做HashMap?由于Perfect Hash已经映射到 [0,table_size) 内的整数,完全不需要考虑key的冲突处理,所以想用起来比较简单:
-
当hashmap的value定长时,我们可以直接通过Hash值(Index)计算出value的offset,无需使用任何额外空间。
-
当hashmap的value不定长时,引入一层relocation,存储每一个Hash值对应value的offset,由于Hash值是从0递增的,因此offset也是递增的,可以通过一定方法去压缩value offset。

完美Hash要求查询的key需要存在于输入集内,其他HashMap没有这么苛刻的要求,如果使用一个不在输入集中的key会怎么样呢?从CHD算法的 lookup 过程来分析,输入未知key时可以认为返回一个随机的Index,如果我们需要确认key是否存在HashMap里,需要将原始key存下来放在Index对应的Value中,查询到Index后再对比一次才能确认key是否存在。
PerfectHashMap一般用法是先离线生成map信息,再读到buffer里,或者像rust-phf一样编译时内置到二进制,直接读P数组,如果HashMap特别大,还可以通过mmap只读方式载入到内存中。
(四)Benchmark
测试设备:MacBookPro m1 Pro 32G,MacOS 12.4,clang 13.1.6。
比较对象:
-
unordered_map:标准库自带的HashMap,链式实现。
-
Folly F14:Facebook HashMap实现,使用SIMD优化查询过程。
-
abseil swiss table:Google HashMap实现,为速度优化,包括使用额外指针的node_hash_map,与原地存储适合小value的flat_hash_map。
-
PTHashMap:PTHash+Value offset映射,(内部使用 CityHash128),c=7, alpha=0.98,Compact-Compact Encoding,Value offset使用MILC压缩。不存储key。
-
PTHashMap3:与PTHashMap参数不同:c=3,alpha=0.99。
-
PTHashMap10:与PTHashMap参数不同:c=10,alpha=0.94。
-
string
测试场景:输入100w随机不重复不定长字符串(平均长度8bytes)作为 key,value与key相同。全部随机lookup一遍:

meta data排除了key和Value之后统计占用内存大小,folly使用 computeStats()统计内存数据。
total memory值插入所有key后使用gpertools统计占用内存大小,包含key和value部分。
注意:PTHashMap meta data统计单位是bit。
-
uint64
测试场景:输入100w随机不重复uint64数字作为key,value与key相同。全部随机lookup一遍。
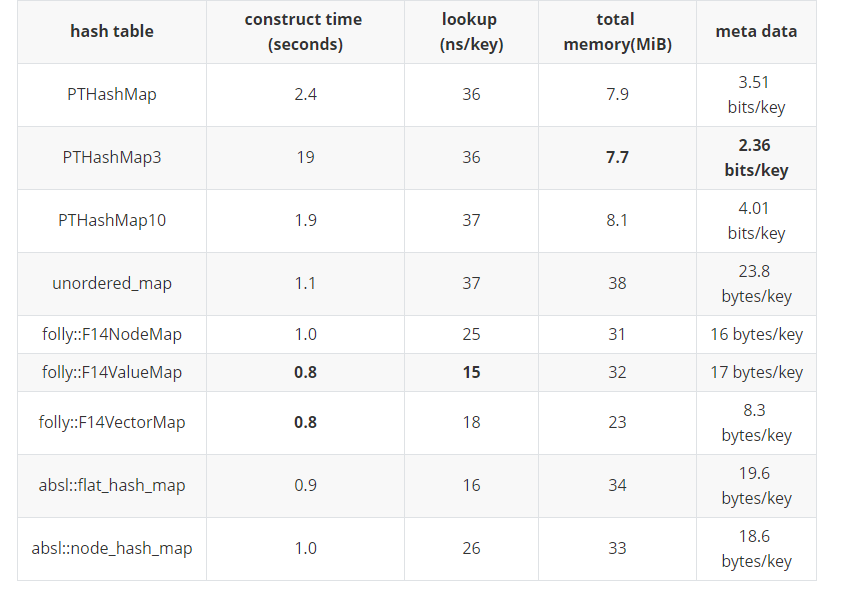
由于该场景数据是长度固定,PTHashMap去掉了Value offset映射表。
结论
完美Hash的概念扩展了Hash的使用场景,最近出现的新型完美Hash算法在运行速度&构建速度上取得了较大的进步,针对海量只读场景使用完美HashMap不仅可以提升速度,同时能够节省大量内存占用。
参考资料:
1.什么是哈希算法?
2.安全Hash
3. MurmurHash wiki
4.哈希表和完美哈希
5. 全域哈希是什么意思
6. 完美Hash技术调研
7. 倒排索引压缩技术在58搜索的实践
作者简介

肖亦帆
腾讯后台开发工程师
腾讯后台开发工程师,目前负责微信读书的后端开发工作,兴趣广泛,热爱挑战。
推荐阅读
第六届 Techo TVP 开发者峰会暨腾讯云大数据峰会来啦!
8 月 20 日,「低代码究竟是“银弹”还是“泡沫”」TVP 低代码技术分享会,即将重磅来袭!
扫码立即参会赢好礼?


本文转载自腾讯程序员 腾讯云开发者,原文链接:https://mp.weixin.qq.com/s/k9SyQKFT1WPCA6ukgcKSnQ。