
01 前言
沉寂已久的大数据技术圈,因为数据湖的概念变得热了起来,一时间,数据湖,湖仓一体,智能湖仓,众多概念如雨后春笋。数据湖用来存储和处理大量结构化、半结构化和非结构化数据。提供更灵活的数据组织,与传统数仓相比,数据湖的schema可以在分析数据时编写,而数仓是在数据写入之前编写。可以说数仓中的数据更多是提前设计好的固定格式,而数据湖的数据组织更灵活。
同时,随着机器学习技术的发展,实时训练,实时推荐不仅推进着机器学习架构的升级,同时对底层数据处理的架构也产生着巨大的影响,这也是近几年流批一体、湖仓一体、实时数仓技术发展的一个重要动力。
目前数据湖开源产品主要技术以Iceberg、Hudi、DeltaLake为代表,这三款产品各自提供了一种数据湖的Table Format,三者各有各的背景和特点,其中,Iceberg以更开放的接口设计逐渐显露出快速的发展势头。Iceberg对多种引擎的适配,对元数据以及partition的变更更强的兼容性,使得Iceberg在技术选型中占据有利的位置。同时,我们在实际应用对比中,发现Iceberg设计更合理,问题更少,所以,在数据湖仓的Table Format的选型上,我们选取了Iceberg作为依托。
02 数据湖
数据湖的概念和技术近些年日新月异,但什么样的数据湖是我们真正所需的,数据湖要服务哪些类型的用户,都是需要我们结合实际的业务需求进行取舍构建。
早期的数据湖更偏重于数据存储,比如Amazon的S3对象存储,将各种规格的数据统一存到对象存储系统。随着技术演进及需求发展,对数据湖的灵活性提出更高的要求,于是数据湖技术发展到了提供ACID、TimeTravel、Schema Evolution、Partition Evolution等更高级的feature。这一阶段,促进了数据湖进一步繁荣。不过,这些功能仍然集中在传统数仓的结构化数据上。数据湖的初衷是要支持结构化,非结构化数据共存共享,不仅要支持数据仓库,机器学习也是数据湖的一等公民。
那么,我们对数据湖的愿景是什么?在传统数仓的流批一体,机器学习实时训练等技术的推动之下,促使对数据湖的实时性,快速检索以及对机器学习非结构化数据管理等能力提出更高的要求。因此,我们理想中的智能湖仓基础架构应该能够提供以上能力,并且尽量做到用户无感,自动完成索引的构建,实时数据的合并等操作。
Iceberg作为一个TableFormat,距离提供一套完善的数据湖服务还是有一定的差距。把TableFormat比作一台车的发动机,想要让车子跑的快跑的稳,还需要变速箱,需要电控系统。同理,智能湖仓除了底层灵活的TableFormat支持,更需要将数据湖仓和机器学习等智能化技术结合,使大数据更方便的支持智能服务。
下面借助一些实际的业务场景来分析一下目前数据湖存在的痛点:
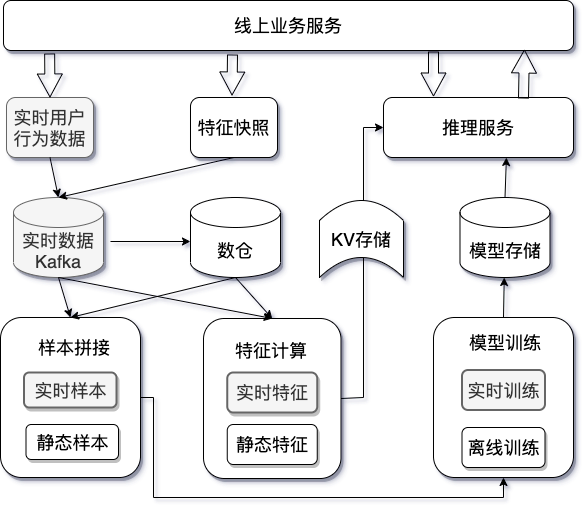

图 1:实时推荐整体架构
线上实时推荐的流程架构中,实时样本拼接和实时特征计算对时效性要求比较高。同时,该场景会经常变动表的schema,所以,传统的hive数仓已经不适合该场景,非常适合使用数据湖仓的TableFormat来支持。以Iceberg为例,我们分析一下以上典型的场景下,存在哪些问题:
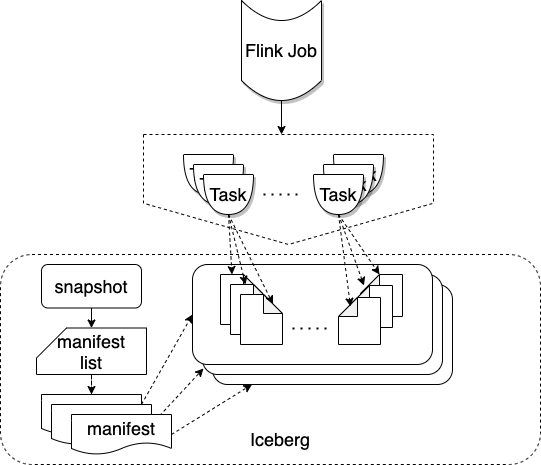
图 2:Flink任务commit 数据入 Iceberg
实时特征计算和用户实时行为数据落数仓的过程中,为了尽量保持数据的实时性,Flink任务每隔数秒或者数十秒commit一次数据到Iceberg,随时间推进,产生大量的小文件,一方面会对底层存储造成比较大的压力,另一方面也会降低查询数据的性能。同时,实时样本拼接对实时性和数据查询性能要求都比较高。开源Iceberg提供触发spark任务额外来合并小文件的功能,但是,无法满足实时推荐等对实时性和性能要求比较高的场景的需求。
机器学习场景下,训练样本会经常变化,以前面的实时推荐场景为例,样本准实时变化,在模型调整或者回退的时候,需要对样本数据提供方便的版本管理能力。
总结来说,智能湖仓为了更好的支持机器学习和大数据结合,需要提供以下能力:
-
数据实时插入,实时查询
-
索引查询加速
-
数据多版本管理
基于上面的分析,我们提出来OPPO的自研技术Glacier,作为智能湖仓的基石,Glacier提供一套完善的服务,重点解决了上面提到的实际业务痛点。
03 Glacier 架构设计
首先,看一下Glacier的整体架构,整体架构在设计之初,不但考虑基本的湖仓查询加速,并且为解决机器学习的实时性,训练的多次回滚对数据多版本管理的需求,倾注了更多的设计思考。Glacier整体架构如图3所示:

图3:Glacier 整体架构
Glacier整体架构设计有以下几个特点:
-
引擎透明,通过完全兼容Iceberg接口,Glacier不强绑定某个引擎,天然支持多种引擎
-
Glacier Service以常驻服务形式提供数据合并,索引构建等辅助能力
-
结合大内存发展趋势,使用分布式内存提供实时数据读写支撑
-
Glacier Version 提供数据版本管理功能,精准管理结构化,半结构化,非结构化数据
04 秒级实时
Append场景
前面提到,我们利用分布式内存支持实时数据读写,实现数据实写实查。
首先,需要一套完备的分布式内存文件系统。我们改进的分布式缓存系统Glacier cache,提供数据高可用,一致性的高性能缓存服务。Glacier cache数据传输基于Netty封装RPC协议,通过灵活使用底层API,利用零拷贝,预读,流控等机制,充分挖掘数据传输性能。同时,Glacier cache通过Raft协议保障数据块多副本一致性;
有了实现实时性的基础设施Glacier cache,计算引擎通过Iceberg读写接口,实时写入Glacier cache中,数据在Glacier cache中以Arrow格式进行组织,使用Arrow接口方便查询内存数据。
当实时数据累积达到阈值,会由Glacier Service合并转存到底层存储系统。为了能对实时数据和底层存储数据进行合并查询,保障数据完整性,需要元数据能够感知两种数据的存在形式。下面看一下Glacier元数在内存中如何组织:
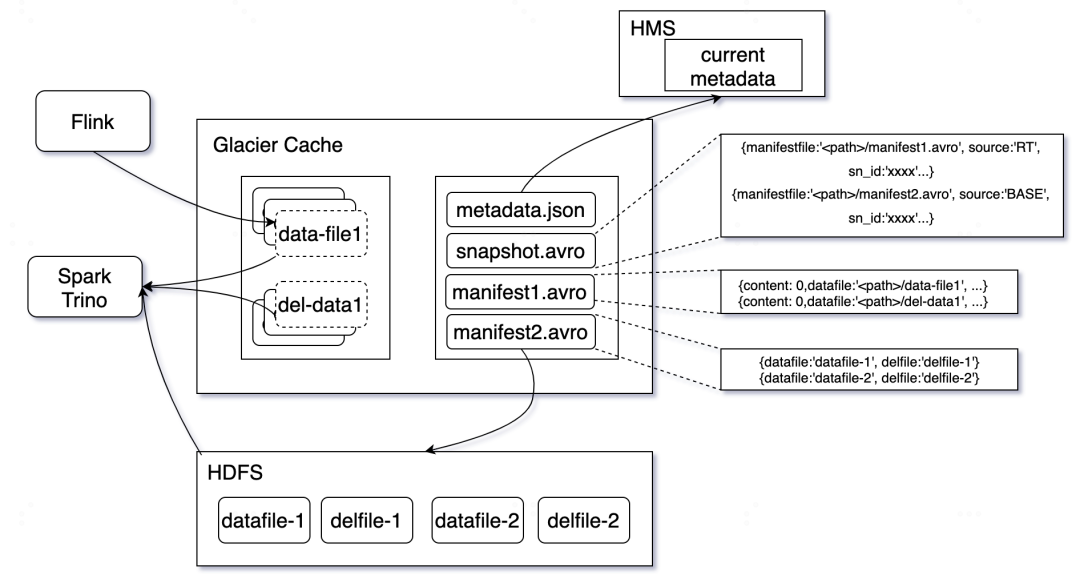
图4:Glacier 元数据组织形式
总体上,元数据组织形式保持对Iceberg一致,只不过将manifest等元数据从底层分布式存储系统转移到Glacier cache中,加速对元数据的访问速度。
元数据中,为内存数据单独新增一个manifest管理,如图4所示,在snapshot文件内容中,对内存和底层存储manifest区分管理,source属性为RT指的是内存数据源,BASE为底层分布式存储数据源。当内存数据被Glacier Service写入到底层存储,相应的元数据也会跟着改变。
CDC场景
CDC数据实时同步入湖场景中,CDC数据变化多样,不仅有插入操作,也有大量的删除更新操作。所以不仅对数据append的实时性提出了比较高的要求,同时在删除数据场景下,对数据的合并和查询的实时性也提出了挑战。下面结合Iceberg的处理删除数据的方式,介绍一下我们在删除数据的实时性方面做的工作。
Iceberg提供两种delete数据方式:Position delete 和 Equality delete。
Position delete记录要删除数据在文件中的位置,Merge On Read时,流式的读取源数据,跳过Position delete的中记录即可,非常高效,但这种删除数据方式需要感知删除数据在文件中的位置;
Equality delete 根据删除列值过滤,在读取效率上不及Position delete方式,但不需要获取要删除的数据在文件中的位置,根据列值删除数据的场景更常见。
Iceberg的Equality delete,待删除数据写入一个delete文件,读数据文件的时候,均需要与delete文件内容对比过滤。对于多个数据文件来说,待删除数据可能只对应部分数据文件,同时,每次查询也可能只需要查询部分文件的数据。鉴于此,我们做了删除的专项优化,大幅提高的Equality delete的效率,测试数据(见表3)显示,优化后的Equality delete性能达到Position delete相当。
删除优化的主要思路将唯一delete文件拆解,待删数据与数据文件对应,减少不必的待删数据过滤匹配操作。下面介绍具体优化方案:
-
待删数据插入到内存的del map中;
-
GlacierService在将内存数据转存到磁盘过程中,先对内存的DataBlock数据过滤;
-
DataBlock过滤后的数据写入磁盘的datafile;
-
Del map数据根据 BloomFilter 找到对应的datafile,并写入对应的del-file;
-
读取数据过程中,只过滤datafile对应的del-file的删除数据,缩小匹配规模,提高查询效率;
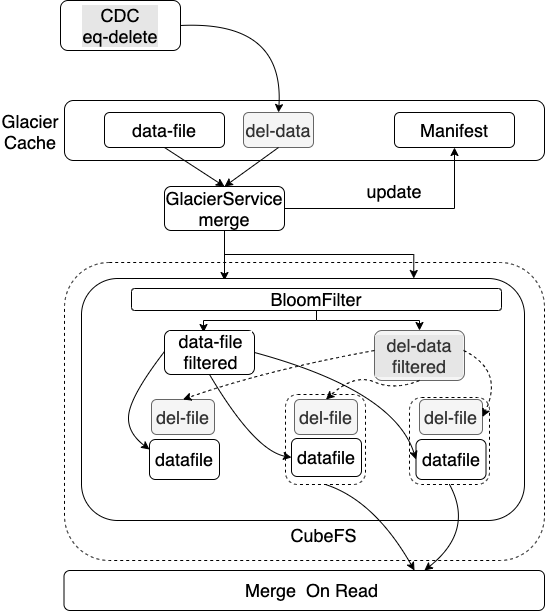
图5:delete性能优化示意图
Delete优化后查询性能对比:
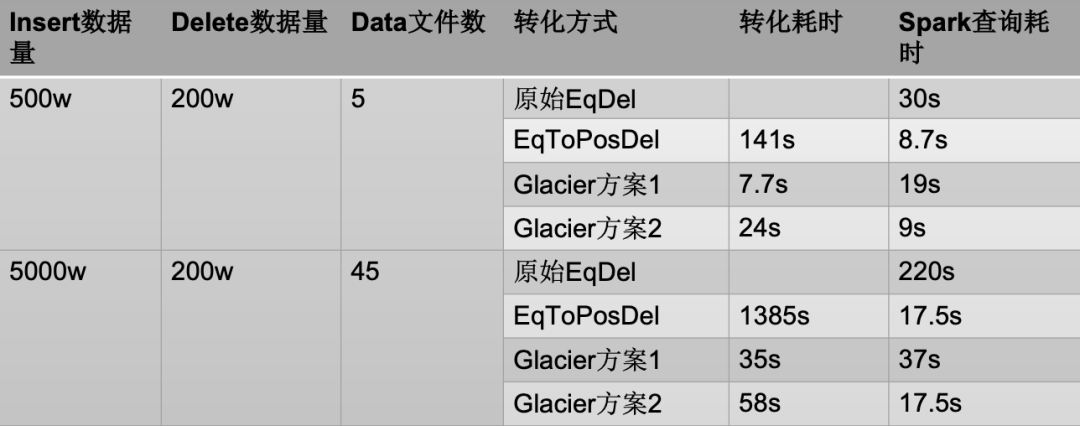
表3:delete优化性能对比
注:
-
原生EqDel:Iceberg原生Equal delete模式。
-
EqToPosDel:将Iceberg的Equal delete数据转换成Position delete,查询性能最快,但是前期转化需要消耗过长时间,同时这种方案不具备实时转换能力。
-
Glacier方案1:通过BloomFilter将delete数据分配到data file 对应的 del file中,删除模式仍然是Equal delete。
-
Glacier方案2:在Glacier方案1的基础之上,将对应的del file数据转换成Position delete,查询效率更高,但转换时间更长。
05 索引加速
Glacier service负责同步内存数据到磁盘存储,同时,对同步数据和历史数据构建索引。借助于常驻服务的优势,构建索引与数据同步过程统一,降低单独构建索引的数据IO成本。Glacier Indexer构建索引的流程示意图见图6所示。
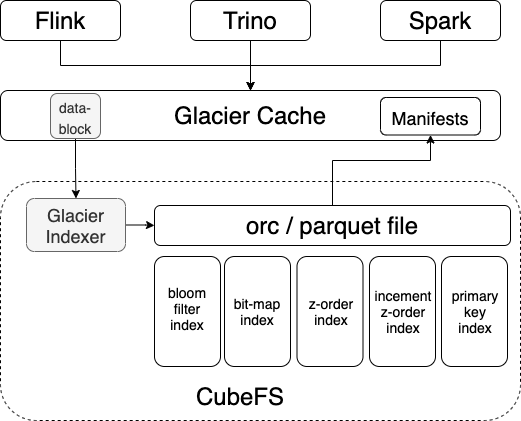
图6:Glacier Service 数据构建索引示意图
目前Glacier支持orc和parquet两种数据格式的布隆索引,位图索引,Z-Order索引,增量Z-Order索引,以及主键索引等主流索引功能;布隆索引和位图索引比较常见,重点介绍一下增量Z-Order和主键索引的应用效果。
增量Z-Order索引
Z-Order索引的构建需要对全量数据排序,消耗大量的算力,且计算时间较长,对于数据频繁变动的场景,如果频繁的构建zorder索引,构建索引消耗的算力的成本将变的不可接受。所以,我们提出来增量zorder模式,全量数据可以在算力充沛期定期排序,实时新增数据可以构建增量zorder,常驻的Glacier Service可以方便的构建增量zorder索引;增量zorder在TPCH测试集上的测试结果显示(图7所示),增量zorder在可接受的算力支出范围内,取得了明显的加速查询效果。

图7:增量zorder查询加速效果对比图
倒排索引
另外,我们新增了主键索引,并不是只针对表的主键才可以加,是针对单列数据加的倒排索引。这种索引对查询性能提升非常明显,针对于等值和范围查询,查询条件落到了索引列上,性能将会提升数十倍。不过,索引没有银弹,超高的性能提升带来的代价就是索引数据本身占空间较大,所以该索引还是需要挑场景使用。我们通过线上几个线上针对单列条件查询的SQL对比一下该索引的加速性能,如图8所示:
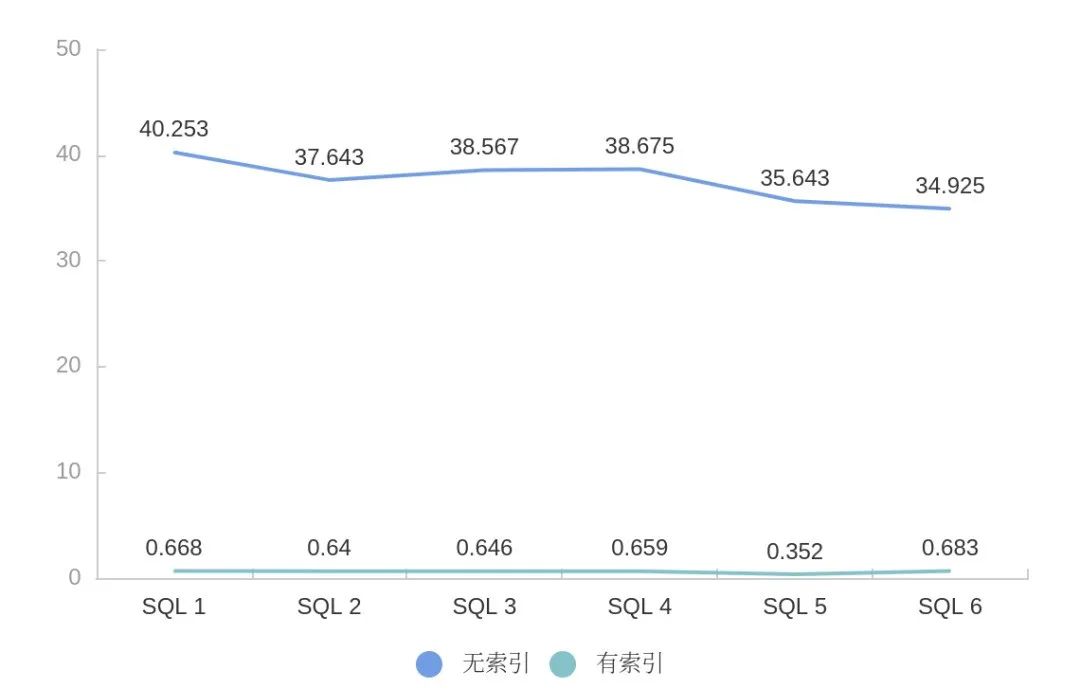
图8:主键倒排索引查询加速效果(时间单位: min)
主键索引主要采用倒排反向索引和FST作为数据字典来存储,FST优点在于内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快,相比于HashMap,性能相差不多,但是占用空间有10倍左右的减少,这对于大数据检索规模至关重要。
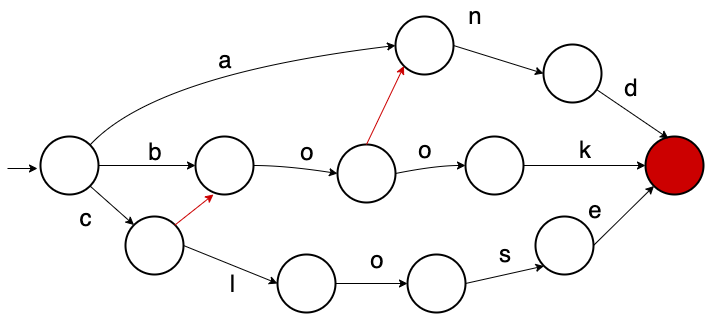
图9:FST示意图
为了进一步降低索引占用的空间,我们选用 FST 的 LZ4 high压缩模式,保障压缩比例最大化。同时,我们对索引内容做了进一步裁剪。
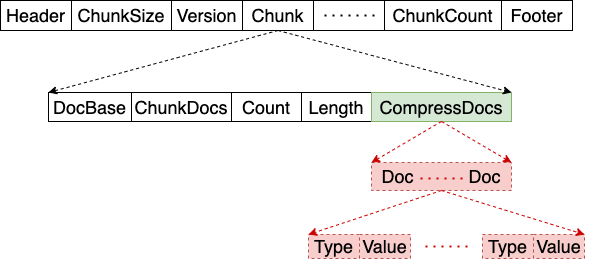
图10:主键索引数据裁剪示意图
主键索引的FST实现中主要包含了Chunk的一些信息,chunk块的大小,其他块位置的偏移量,以及被索引的原始数据,在内容文本索引场景中索引命中后可以直接返回原始数据提供查询,但是作为主键索引来说,该索引主要判断当前文本在不在某个列式文件中,以便数据湖ScanFile Task决定扫描该文件与否,所以去掉该部分可以降低索引占用空间,同时不影响索引效率。
06 数据多版本
数据多版本管理,在大数据计算领域和机器学习领域均有特殊的需求。比如:在大数据计算场景中,开发者要用测试验证数据应用程序,可以通过数据版本管理,克隆部分数据作为测试版本;另外,对于ABTest场景,对实验的多种对照组数据均可用版本管理工具进行管控;
当然,数据版本管理,在机器学习应用中使用的更普遍,不仅可以对训练样本的变更,回滚等进行版本管理,还可以对模型版本进行管理。总之,数据版本管理对数据湖来说,有着不可或缺的地位。下面介绍一下Glacier Version,我们的智能湖仓数据版本管控技术。
提到版本管理技术,不得不提代码管理工具git,但是在大数据场景下,git在技术设计本身存在天然的缺陷,下面通过表4介绍对比一下Git和Glacier Version的差异:
|
比较项 |
Git |
Glacier Version |
说明 |
|
Clones |
Y |
N |
数据集通常很大,不适合clone,通过branch提供类似功能 |
|
速度(rw/second) |
| 5000+ |
git 通过blob对象对文件进行管理,每次提交会对文件进行内容比较,速度慢,而且会生成大量版本数据 |
|
速度(seconds/commit) |
3-5s |
30ms |
|
|
管理对象 |
文件 |
表、文件 |
Glacier Version可以支持结构化非结构化数据的版本管理 |
表4:Glacier Version与Git对比
在大数据、大容量的场景下,Git的缺陷是不能容忍的,所以在设计Glacier Version时基于Merkle Tree加文件pointer的模式对文件进行管理。
Merkle Tree是一种基于哈希的树形数据结构,该树中的每一个叶子结点都是一个数据块,而每一个非叶子结点都是其子结点组合的哈希,Merkle Tree在分布式系统中被广泛使用于进行数据校验。在分布式系统中,可以保证数据可靠性及一致性,而不需要对文件逐一比较。
Merkle Tree的结构如图所示:
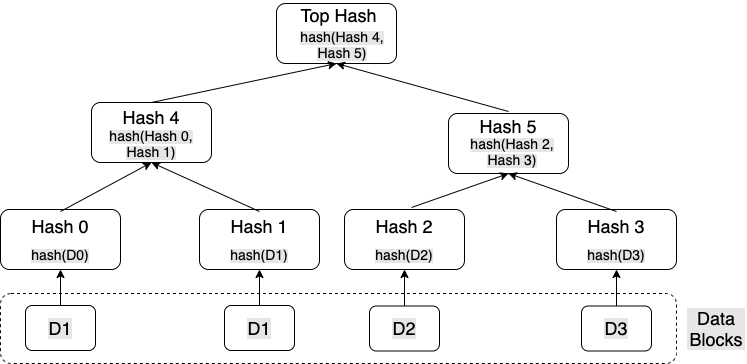
图11: Merkle Tree组织示意图
基于上述思想,智能湖仓的版本管理方案Glacier Version架构如下图12所示:
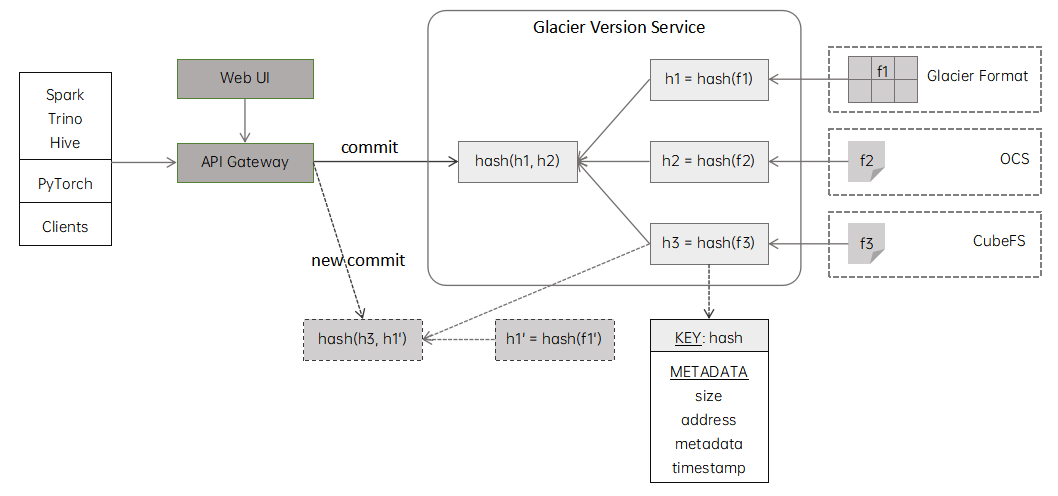
图12:Glacier Version架构图
Glacier Version主要的特性有以下几点:
-
支持Git常用命令:clone、commit、branch、merge等
-
支持多种引擎,并针对PyTorch等机器学习框架进行适配
-
对于版本提交使用Merkle Tree对文件进行管理
-
如果新提交基于之前的版本进行提交,其中未更改的文件可以复用
-
使用manifest方式进行管理,不再需要将blob对象下载到本地
-
支持外部源的文件管理(由于外部文件的删除不在系统内,可能存在clone异常的情况)
Glacier Version性能延迟以及吞吐指标:
-
平均操作延迟在30ms以内
-
创建分支及读写操作支持5000+ rps
-
每次提交支持数据量达到PB级别
Glacier Version设计之初,融合了Git的操作特性,契合用户使用习惯。同时支持多种大数据计算引擎和机器学习引擎,为大数据和机器学习提供统一便利。
07 非结构化数据管理
Glacier-Version支持快速将非结构化数据转成结构化数据并入湖管理,支持对其进行打标,并能够统一进行数据版本管理。
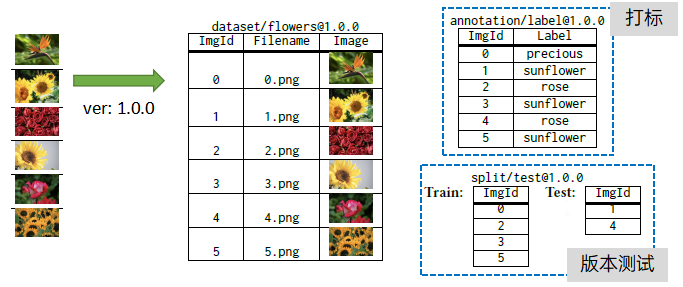
图13:Glacier-version 对非结构化数据管理
针对机器学习的场景,对非结构化数据进行文件格式设计,块化存储,并带有标签,方便查询过滤及流式传输。
针对机器学习场景存在的IO瓶颈问题计划从下面几个方面入手:
1、数据存储格式,基于列式存储,数据存储在特定大小数据块中,一个块中可以存多条数据,如果文件比较大,也可以分成多个块存储,这样做可以提升传输效率,同时可以支持流式传输
2、缓存提速:Glacier cache提供高速缓存数据读写支持,在机器学习场景下,可以利用该分布式缓存进行调度算法优化,基于调度系统提前进行缓存,并可以将容器调度到指定已有缓存的机器上,提升缓存命中率并降低网络IO,降低IO的等待瓶颈。
非结构化-Tensor存储:
HDF5(Hierarchical Data Format),用于存储和组织大量数据的文件格式。侧重图像、数组。
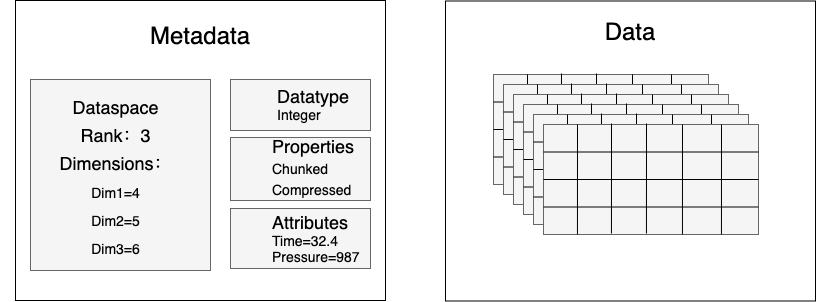
图14:HDF5存储格式示意图
如图15所示,数据存储为大小为4 x 5 x 6的三维数据集,数据类型为整数。属性为时间和压力,同时数据被分块和压缩 。
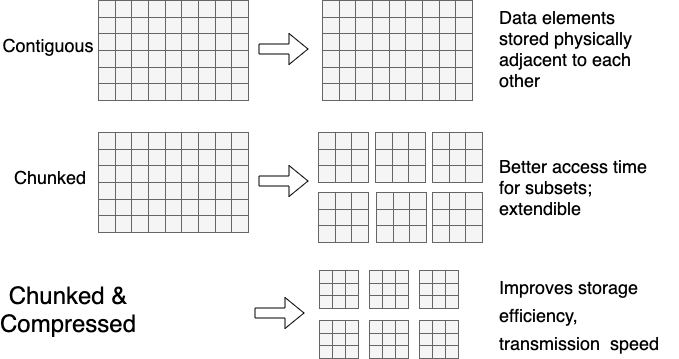
图15:HDF5分块压缩示意图
zarr , n5 继承并扩展了HDF5的规范定义,对机器学习框架的支持更加友好。
非结构化-Data Stream Loader:
通过将非结构化数据转换成结构化数据,原本松散的文件会以固定大小的块以列存的模式进行存储,同时可以通过index把标注、时间戳等信息进行关联。
图16:非结构化数据转结构化数据
以机器学习场景进行说明,非结构化的数据不可避免的需要通过网络将数据传输到本地再进行处理,而我们在转成结构化数据后,由于固定的块和列式的存储的模式,使得我们可以进行流式数据传输,这样无需等待所有数据都传输完成,在传输的同时将数据进行处理。
通过将非结构化数据转成结构化数据,可以得到:
-
传输效率:可以支持流式读取,降低反复网络建链,无需等待所有数据都传输完成,就可以对数据进行处理
-
内存效率:使用固定大小的块进行存储,可以提升内存的复用度,减少内存频繁的申请销毁带来的碎片化问题
-
执行效率:可以充分提升CPU和GPU的并发能力对数据进行处理

图17:流式读取

图18:基于Ring Queue的内存复用模型
08 总结与展望
作为智能湖仓的底座,Glacier提供一套完整的数据湖服务,不仅包括传统湖仓服务,更与机器学习紧密结合,为机器学习和大数据结合提供更便捷的平台。
数据湖仓应用,使用户只需要关注数据应用本身,不必过度的关注数据的排布,合并等问题。提供秒级入仓,实写实查高效的实时性增强。利用常驻服务,自动的创建相应的索引,创新的提供增量zorder索引,在计算成本和加速效果两者之间做到更平衡,更高效。同时,在删除数据的merge on read场景,对内存和磁盘数据两种模式分别做了优化,使 Equality delete与Position delete性能相当。
在机器学习方面,提供完备的代码、模型、数据版本管理服务,使Glacier融合到整个机器学习线上流程;同时,可以利用Glacier高性能基础设施,优化数据传输和读写性能。
未来的Glacier发展方向,将向着更加智能化,更完备的方向发展。对于湖仓领域的延伸,Glacier可以根据数据查询的特征,自动创建合适的索引;对于机器学习领域的支持延伸,Glacier将支持向量数据的查询加速,主要针对图形数据的应用场景。
OPPO的智能湖仓,是对数据基础架构的一次全面技术升级。除了Glacier这一服务底座,还包括 Shuttle:OPPO智能湖仓计算加速器, 提供对Shuffle, Sort, Broadcast等算子的优化增强服务。LakeLink:OPPO智能湖仓引擎适配器,提供自动化,智能化的大数据计算接入方式,降低用户使用数据平台的门槛,提升资源利用率。后续系列文章将陆续为大家揭秘,敬请期待。
本文转载自安第斯智能云,原文链接:https://mp.weixin.qq.com/s/lPi99OMGH9fzjodrkh2Jdg。