
点击蓝字 关注我们


导读
-
有赞:全面从 Airflow 迁移到 DolphinScheduler,日均调度 6w+ 任务实例; -
360数科:全面从 Azkaban 迁移到 DolphinScheduler,日均调度 1w+ 任务实例; -
Fordeal:全面从 Azkaban 迁移到 DolphinScheduler,日均调度 3500+ 工作流实例、1.5w+ 任务实例; -
新网银行:借助 DolphinScheduler 调度实时跑批、准实时跑批和指标管理系统的离线跑批,日均 9000+ 任务实例; -
中国联通:借助 DolphinScheduler 调度处理 Spark/Flink/SeaTunnel 等作业,业务涵盖稽核、收入分摊、计费业务,日均调度 300+ 工作流实例、5000+ 任务实例,业务覆盖 3 地 4 集群; -
T3出行:结合 DolphinScheduler + Kyuubi on Spark,日均处理 3w+ 离线调度任务、300+ Spark Streaming 任务、100+ Flink 任务、500+ Kylin、ClickHouse 和 Shell 任务; -
联通数科:借助 DolphinScheduler 调度大数据调度任务和数仓计算任务(如 Spark/Flink 等),日均调度 1w+ 工作流实例、7w+ 个任务实例、集群规模 80+ 个节点; -
联通医疗:基于 DolphinScheduler 构建了涵盖数据采集、同步、处理和治理为一体的大数据平台,日均调度 6000+ 任务实例; -
伊利集团:借助 DolphinScheduler 构建了一个统一的数据集成、开发、调度和运维的多云大数据平台,日均调度任务数达到 1.3 万个,每日搬迁 8000+ 张表,集群规模 15 个节点,涉及 4 朵云(阿里云+腾讯云+京东云+自建云),80 多个业务系统。
业界主流产品对比
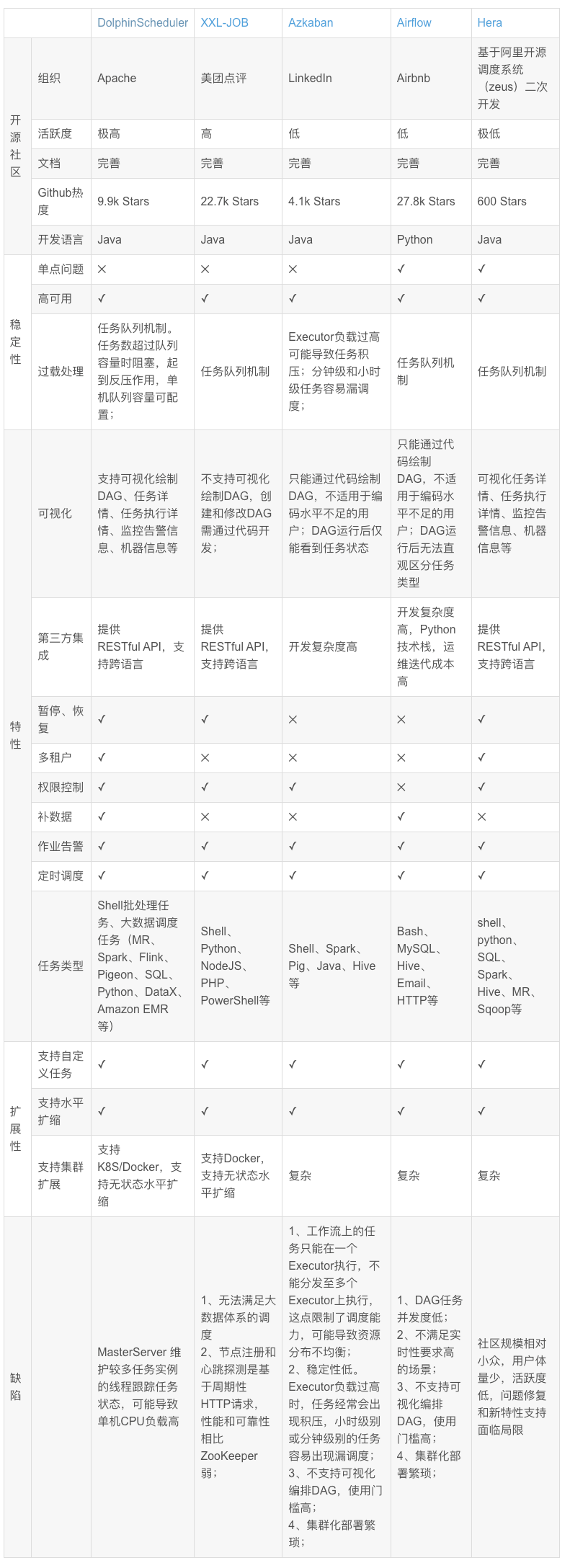
架构设计
-
ApiServer:对外统一提供 RESTful API,涵盖工作流的增删改查、上下线、启动、暂停、恢复、从指定节点开始执行、任务执行状态的查看等; -
AlertServer:一方面负责对外提供告警接口,另一方面负责定时发送集群级别和用户业务级别的告警信息; -
MasterServer:采用分布式去中心化设计,内部集成Quartz服务,主要负责工作流DAG的任务切分、监听任务提交情况、监听其它MasterServer/WorkerServer的健康状态;启动时主动向ZooKeeper注册临时节点,并通过监听ZooKeeper进行容错; -
WorkerServer:采用分布式去中心化设计,主要负责DAG任务的执行和提供日志查询服务;启动时主动向ZooKeeper注册临时节点,并周期性上报心跳信息。
MasterServer 设计要点
4.1
核心服务
-
Scheduler:分布式调度组件,主要负责Quartz定时任务的启动,当Quartz调度任务后,MasterServer内部任务线程池负责处理任务的后续操作; -
MasterRegistryClient:ZooKeeper客户端,封装了MasterServer与ZooKeeper相关的操作,例如注册、监听、删除、注销等; -
MasterConnectionStateListener:监听MasterServer和ZooKeeper连接状态,一旦断连则触发MasterServer的自杀逻辑; -
MasterRegistryDataListener:监听ZooKeeper的MasterServer临时节点事件,一旦发生节点移除事件,则先移除ZooKeeper上的临时节点,再触发MasterServer的故障转移(过程和FailoverExecuteThread一致); -
MasterSchedulerBootstrap:调度线程,每隔一段时间扫描DB,按照分片策略批量取出Command,封装成工作流任务执行线程(WorkflowExecuteThread),投放至缓冲队列中,等待下一个线程消费; -
FailoverExecuteThread:故障转移线程,每隔一段时间扫描DB,筛选出分配到故障节点的工作流实例,向WorkerServer发送TaskKillRequestCommand请求杀死运行中的任务;向Command表写入RECOVER_TOLERANCE_FAULT_PROCESS记录,等待MasterServer消费; -
EventExecuteService:工作流的执行线程,包含两部分: -
ProcessInstanceExecCacheManager:工作流实例的缓冲队列。MasterSchedulerBootstrap按照分片策略取出Command,封装成工作流实例执行线程(WorkflowExecuteThread)后投放; -
WorkflowExecuteThreadPool:从缓冲队列中取出WorkflowExecuteThread,并监听线程的执行情况(执行前先检查是否已经被其它线程启动); -
TaskPriorityQueueConsumer:任务队列消费线程,根据负载均衡算法将任务分发至Worker; -
TaskPluginManager:任务插件管理器,启动时会将TaskChannelFactory的所有实现类持久化到t_ds_plugin表中;因此,如果开发者需要自定义任务插件,只需集成实现TaskChannelFactory即可; -
MasterRPCServer:MasterServer RPC服务端,封装了Netty服务端创建等通用逻辑,并注册了各种消息处理器: -
CacheProcessor:接收来自ApiServer的CacheExpireCommand请求,强制刷新缓存; -
LoggerRequestProcessor:接收来自ApiServer的GetLogBytesRequestCommand、ViewLogRequestCommand、RollViewLogRequestCommand、RemoveTaskLogRequestCommand请求,操作日志; -
StateEventProcessor:接收StateEventChangeCommand请求,处理工作流实例/任务实例的状态变更,包括工作流实例/任务实例的提交成功、运行中、成功、失败、超时、杀死、准备暂停、暂停、准备停止、停止、准备阻塞、阻塞、故障转移等; -
TaskEventProcessor:接收TaskEventChangeCommand请求,处理任务实例的状态变更,包括:强制启动、唤醒; -
TaskKillResponseProcessor:接收来自WorkerServer的TaskKillResponseCommand请求,请求内容是杀死任务实例请求的响应结果; -
TaskExecuteRunningProcessor:接收来自WorkerServer的TaskExecuteRunningCommand请求,请求内容是任务实例的运行信息(工作流实例ID、任务实例ID、运行状态、执行机器信息、开始时间、程序运行目录、日志目录等) -
TaskExecuteResponseProcessor:接收来自WorkerServer的TaskExecuteResultCommand请求,请求内容是任务实例的运行结果信息(工作流实例ID、任务实例ID、开始时间、结束时间、运行状态、执行机器信息、程序运行目录、日志目录等); -
WorkflowExecutingDataRequestProcessor:接收来自ApiServer的WorkflowExecutingDataRequestCommand请求,向指定的WorkerServer查询执行中的工作流实例信息。
4.2
自治去中心化
-
单点故障:如果Master节点宕机则集群就会崩溃,为了解决这问题,大多数中心化系统都采用Master主备切换的设计方案,可以是热备或者冷备,也可以是自动切换或者手动切换,越来越多的中心化系统都具备自动选举切换Master的能力,以提升系统的高可用性; -
Master过载:如果系统设计和实现不完善,例如Master节点上的任务并发量过大、业务逻辑过于复杂,可能会导致Master节点负载过高,那么系统性能瓶颈就卡在Master节点上。
4.3
缓存策略
-
缓存管理:采用 caffeine,可调整缓存相关配置,例如缓存大小、过期时间等; -
缓存读取:采用 spring-cache 机制,可直接在Spring配置文件中决定是否开启(默认关闭),配置在相关的 Java Mapper 层; -
缓存刷新:通过 AOP 切面 @CacheEvict 监听 ApiServer 接口的业务数据更新,当有数据更新时会通过 Netty 发送 CacheExpireCommand 请求通知 MasterServer 进行缓存驱逐。
4.4
任务分发
-
Id:Command表中的记录ID; -
MasterCount:分片总数,成功注册在ZooKeeper的MasterServer总数; -
MasterSlotId:分片序号,当前MasterServer在ZooKeeper的位置索引。
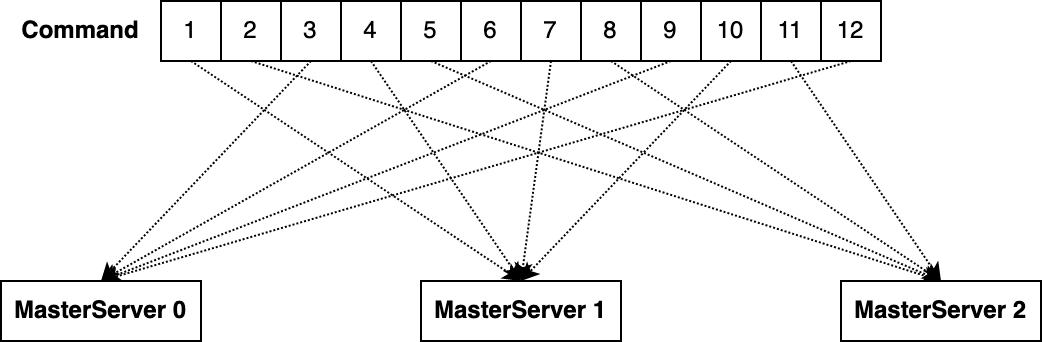
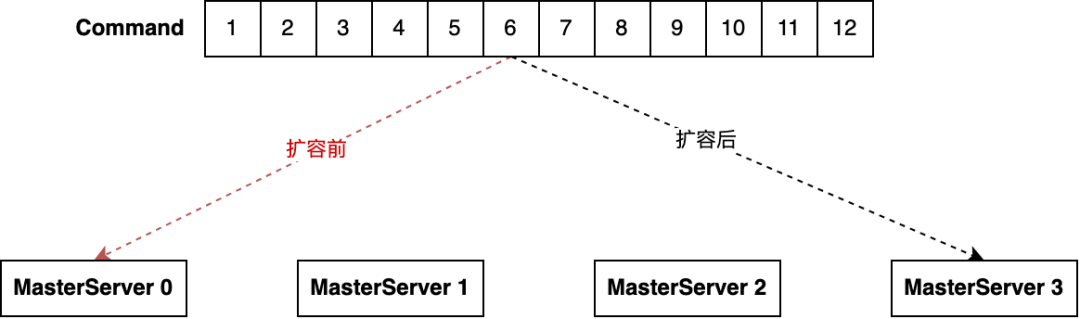
-
加权随机(Random):随机选择一个节点;算法缺点是所有节点被访问到的概率是相同的,具有不可预测性,在一次完整的轮询中,有可能负载低的完全没被选中,而负载高的频繁被选中; -
加权轮询(LowerWeight):默认策略。WorkerServer节点每隔一段时间向ZooKeeper上报心跳信息(包含cpuload、可用物理内存、启动时间、线程数量等信息),MasterServer分发任务时根据WorkerServer节点的CPU Load平均值、可用物理内存、系统平均负载、服务启动耗时计算节点权重值,值越大意味着节点负载越低,选中的优先级越高;算法缺点是在某些特殊的权重下,会生成不均匀的序列,这种不平滑的负载可能会导致节点出现瞬间高负载的现象,导致节点存在宕机风险; -
平滑加权轮询(RoundRobin):节点宕机时降低有效权重值,节点正常时提高有效权重值;降权起到缓慢剔除宕机节点的效果,提权起到缓冲恢复宕机节点的效果。
private double calculateWeight(double cpu, double memory, double loadAverage, long startTime) {double calculatedWeight = cpu * CPU_FACTOR + memory * MEMORY_FACTOR + loadAverage * LOAD_AVERAGE_FACTOR;long uptime = System.currentTimeMillis() - startTime;if (uptime > 0 && uptime// If the warm-up is not over, add the weightreturn calculatedWeight * Constants.WARM_UP_TIME / uptime;}return calculatedWeight;}
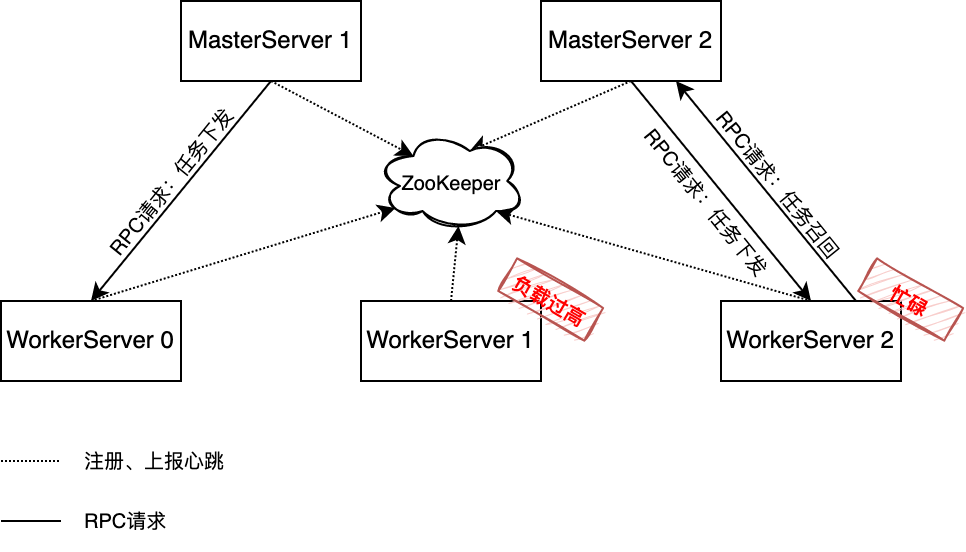
-
WorkerServer 的队列有: -
等待分配队列:org.apache.dolphinscheduler.server.worker.runner.WorkerManagerThread#waitSubmitQueue,无边界的阻塞队列,负责接收来自MasterServer的DAG任务,此队列会延迟执行队列; -
执行队列:org.apache.dolphinscheduler.server.worker.runner.WorkerExecService,线程池(大小默认100),可通过worker.exec-threads参数调整; -
等待执行队列:同执行队列,其中未分配到空闲线程而阻塞的任务数,即为等待执行的任务数; -
WorkerServer 会周期性更新 ZooKeeper 中的心跳信息,其中包括等待执行队列的大小,假如在一次心跳周期内启动了大量的任务(本次心跳周期内等待队列还未更新),WorkerServer 获取到任务时先放到等待分配队列,等待分配队列会将任务给执行队列,执行队列满时,会放到等待执行队列,当执行队列、等待执行队列都满时,等待分配队列则无法分配任务,就会触发 MasterServer 召回策略,WorkerServer 把任务返回给 MasterServer,MasterServer 会重新分配。
4.5
容错机制
public class MasterConnectionStateListener implements ConnectionListener {...public void onUpdate(ConnectionState state) {switch (state) {...case DISCONNECTED:logger.warn("registry connection state is {}, ready to stop myself", state);registryClient.getStoppable().stop("registry connection state is DISCONNECTED, stop myself");break;default:}}}
-
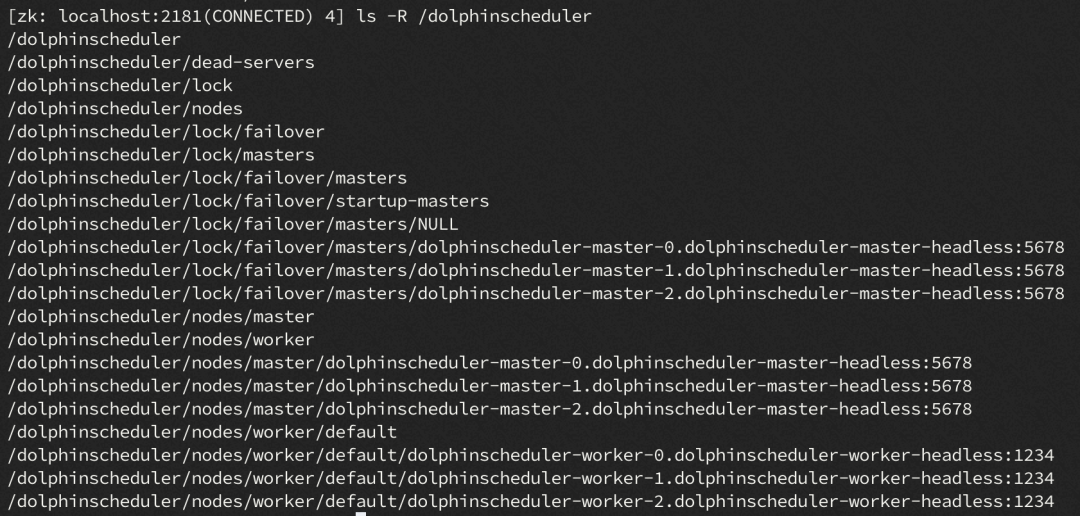
MasterDataListener:监听ZK路径 /dolphinscheduler/nodes/master,若发生临时节点移除事件,则发送告警; -
WorkerDataListener:监听ZK路径 /dolphinscheduler/nodes/worker/${WorkerGroup},若发生临时节点移除事件,则发送告警。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

本文转载自Apache DolphinScheduler,原文链接:https://blog.csdn.net/yeweiouyang/article/details/127212062。