
文章摘要
本文整理自 Pulsar Summit Asia 2022 腾讯云高级研发工程师冉小龙的演讲《Deep Dive into Apache Pulsar Lifecycle》。Apache Pulsar 中抽象了 Topic 来承载用户发送的消息,一条消息发送到 Topic 中之后会经过 Broker 的计算存储到 Bookie 中。本文将详细阐述消息是如何发送到 Broker 并经过 Broker 的计算以及元数据处理最终存储到 Bookie 中,然后会进一步阐述 Bookie 如何利用垃圾回收机制回收 Topic 中的数据,以及 Broker 中的 TTL 和 Retention 策略如何作用到 Bookie Client 来触发垃圾回收的机制。
作者简介
冉小龙,腾讯云高级研发工程师,Apache Pulsar Committer,RoP maintainer,Apache Pulsar Go Client、Pulsarctl 与 Go Functions 作者与主要维护者。
导读
本文分为以下几个部分:
- 1. 从用户的视角看消息收发流程
-
2. TTL 与 Retention 策略(与消息生命周期息息相关)
-
3. 从 Topic 的角度看消息存储模型
-
4. Bookie GC 回收机制
-
5. 脏数据如孤儿 Ledger 的产生
-
6. 如何清理脏数据
-
1、2、3 主要在 Broker 层面分析原理,5 和 6 根据生产环境中遇到的问题来分析脏数据的产生与清理。
用户视角下的消息收发流程
在用户视角下,MQ 可以理解为 Pub-Sub 模型,在 Broker 抽象一个 Topic,消息经由生产者发送到 Topic 中然后进入消费者进行消费。
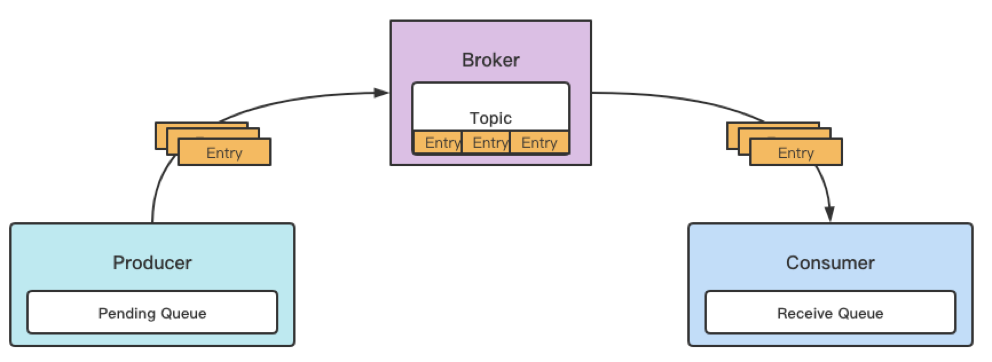

首先需要了解两个概念,Pending Queue 和 Receive Queue。
-
• Pending Queue:发送过程中的概念。消息发送时并不是每次直接投递给 Broker,而是在本地抽象 Pending Queue,所有数据先进入 Pending Queue 再被发送到 Broker。
-
• Receive Queue:接收过程中的概念。同 Pending Queue 原理相同,消息接收时并不是每次直接从 Broker 要数据,而是在本地抽象 Receive Queue,数据按批次进入 Receive Queue,再结合 Pulsar 消息推拉机制不断地填充 Receive Queue 来调动整体流程。
在 Pulsar 中,Broker 不解析批消息,因此 Broker 无法知道消息是否是批消息,这里抽象了一个 Entry 的概念,Entry 内可能包含批消息或者非批消息。
下图是用户视角下更深入的架构图。生产者和消费者可以理解为 Client 模型,Client 把消息发送给 Broker。Broker 可以理解为 BookKeeper Client,BookKeeper Client 通过增删改查的操作将数据传递给 Bookie。BookKeeper 和 Broker 都有元数据管理中心,目前使用较多的是 ZooKeeper,其内包含所有节点信息,如节点调度信息。
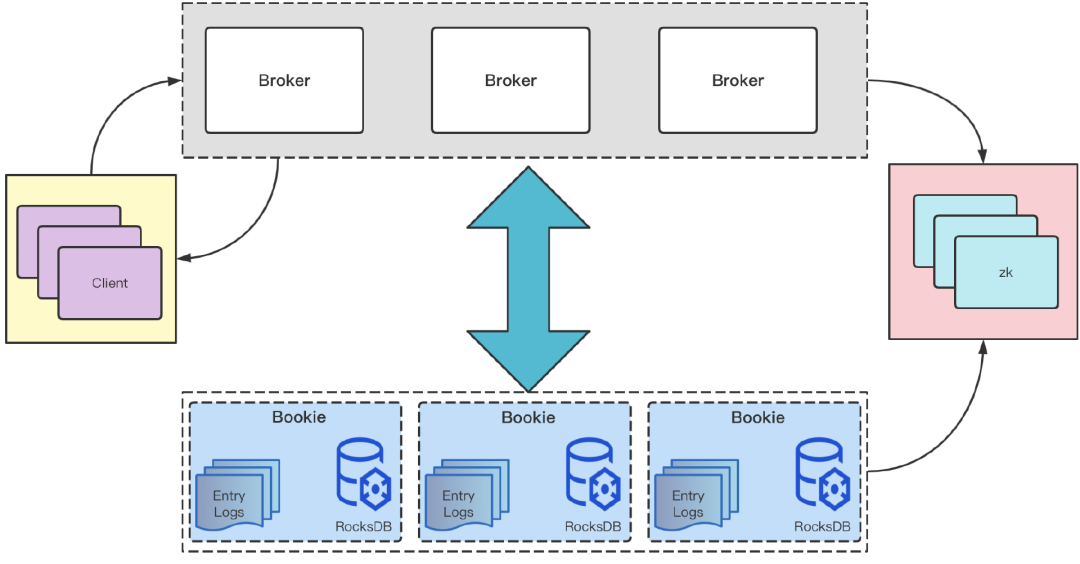
下面解析一下数据从 Client 到 Broker 再到 BookKeeper 是怎样的整体流程。首先,BookKeeper 存储层功能比较单一且纯粹。作为一个分布式日志文件系统,它暴露给上层系统的、能够供上层系统调用的仅仅是增删改查的操作,伴随这些操作可以观察从 Client 到 BookKeeper 的操作链路:
-
• Send -> Broker -> add Entry -> Bookie:发送
Send命令到 Broker,Broker 向 BookKeeperaddEntry -
• Receive -> Broker -> read Entry -> Bookie:发送
Receive命令到 Broker,Broker 调用 BookKeeperreadEntry接口从 Bookie 中读取消息 -
• Ack -> Broker (TTL) -> move cursor (markDeletePosition) -> Bookie:发送
Ack命令到 Broker,Broker 会执行 move cursor 操作。Broker 抽象的 Topic 里面有一条条的消息,Ack 相当于操作 cursor 的行为,指针随着 Ack 行为移动,此处抽象了 markDeletePosition 的指针。在 markDeletePosition 之前,所有的消息都已被正确消费。 -
• Retention -> delete Entry -> Bookie:接收到 Retention 策略后,Broker 触发 Retention 阈值后会调用 Bookie delete Entry 接口,来删除 BookKeeper 中数据。delete Entry 是本文重点讨论的话题,后文将具体介绍触发 Retention 策略后,Entry 如何被从 BookKeeper 中删除。
TTL 与 Retention 策略
首先需要明确 TTL 策略和 Retention 策略的概念。
TTL 策略
TTL 策略指消息在指定时间内没有被用户 Ack 时会在 Broker 主动 Ack 掉。
Client 在消费者侧暴露两个接口 Receive 和 Ack。当用户消费者接收到消息时,Broker 并不知道此时用户已经正确接收到消息,需要用户手动调用 Ack 告诉 Broker 自己成功接收到了当前消息,所以 Client 要发起 Oneway 的 Ack 请求通知 Broker 进行下一步处理。不论消息是否被推送到 Broker,生产者发送到 Topic 的消息都会产生 TTL(生命周期)。所有消息都在 TTL 内受管控,超出这个时间后 Broker 会代替用户把消息 Ack 掉。
此处需注意,在上述过程中没有任何与删除相关的操作,因为 TTL 不涉及与删除相关的操作。TTL 的作用仅仅是用于 Ack 掉在 TTL 范围内应被 Ack 的消息,真正删除的操作与 Pulsar 中抽象出来的 Retention 策略相关。
Retention 策略
Retention 策略指消息被 Ack 之后(消费者 Ack 或者 TTL Ack)继续在 Bookie 侧保留的时间,以 Ledger 为最小操作单元。
消息被 Ack 之后(消费者 Ack 或者 TTL Ack)就归属于 Retention 策略,即在 BookKeeper 保留一定时间,比如在离线消息场景下会将数据保留一段时间来进行回查等操作。Retention 以 Ledger 为最小操作单元,删除即是删除整个 Ledger。
下面是在 TTL 内 Ack 消息的示意图。在 T1 时间段有 10 条消息,m1 – m5 是被 Ack 的消息,m6 – m10 是未被 Ack 的消息。在 T2 时间段,假设到达 TTL 的 3 分钟阈值后消息还没有被 Ack,m6 – m8 就会被 TTL 策略检查到,Broker 主动将其 Ack。在 T3 时间段,m6 – m8 已被 Broker Ack。这就是 TTL 策略操作行为与作用范围。
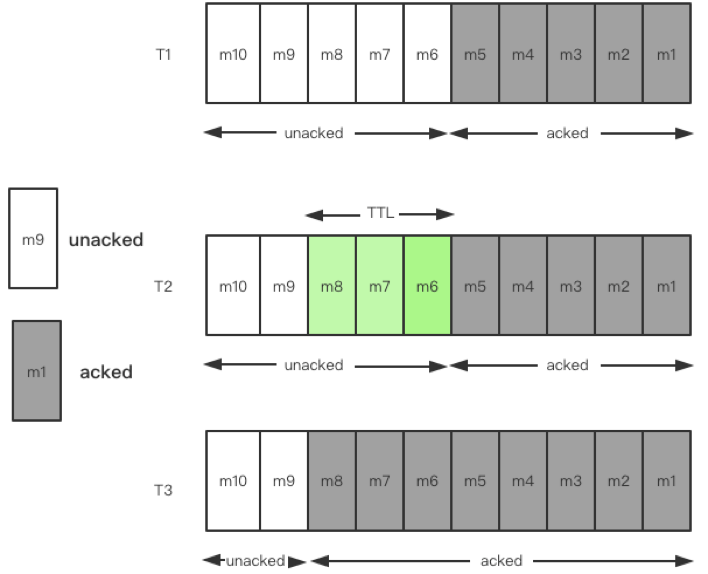
Pulsar 内的所有策略都在 Broker 抽象了线程池,周期性地执行线程,比如 TTL 策略或者 Retention 策略默认 5 分钟检查一轮。TTL 策略就是根据设置的时间,定期检查,不断更新 Cursor 的位置(等价于 Consumer 侧暴露的 Ack 接口),将消息过期掉;Retention 策略是检查 Ledger 的创建时间以及 Entry 的大小来决定是否要删除某一个 Ledger。
TTL 策略和 Retention 策略的生命周期在时限上有如下规则:
-
• TTL 时间
-
• TTL 时间 ≥ Retention 时间,消息的生命周期等于 TTL 时间。在 TTL 检查时,有一个判断标准是 Ledger 是否进行切换,如发生切换且达到 TTL 时间,Ledger 会进入 Retention 策略删除动作。所以如果 TTL 时间 ≥ Retention 时间,消息生命周期就是 TTL 时间。
从 Topic 的角度看消息存储模型
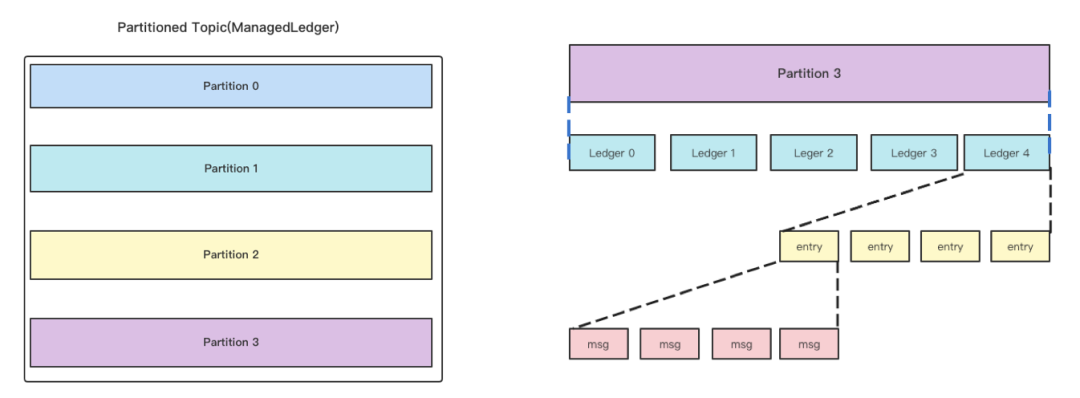
讲到消息存储模型,首先接触到的是 Topic,生产者向这个 Topic 发送消息、消费者从 Topic 消费消息。Topic 内部抽象了 Partition 的概念,一个 Topic 内可以创建多个 Partition,作用是增加并发处理的能力,即一个 Topic 中的消息可以分发到多个 Partition,由多个 Partition 承载 Topic 的服务。
在 Bookie 存储层,一个 Partition 由多个 Ledger 构成。如图,Partition 3 下面有 5 个 Ledger。Ledger 里面存储的是多条 Entry。如前文所说的 Entry 概念,根据消息是否是批消息,Entry 就可以分为批和非批两种。如果消息是批消息,那么 Entry 里面有多条 Message;如果消息是非批的,那么一条 Entry 等于一条 Message。这就是 Topic 视角下的存储模型。
Bookie GC 回收机制
前面三个部分都围绕 Broker 层,Broker 作为计算层,本质是 Bookie Client,调用 Bookie 侧暴露的增删查的接口来进行相关的操作,操作逻辑简单。下面将重点介绍 BookKeeper 层如何将数据进行压缩和回收。
Bookie 压缩类型
压缩类型分为两种:
-
• 自动压缩:Bookie 有周期性执行的 GC Compaction 线程,GC 分为 Minor GC 和 Major GC,后文会详细介绍两种 GC 的区别。
-
• 手动压缩:通过 BookKeeper 暴露的 Http 调用 Admin Rest API 接口来触发 GC 请求。这个操作在日常急救运维中很常见,比如 Bookie 磁盘内存突然大幅度上涨,用户想要紧急回收数据,那么就可以跳过 Minor GC 和 Major GC 检查周期,手动触发 GC 来释放磁盘空间。
Bookie 压缩方式
Bookie 的压缩方式分为两种:
-
• 按照 Entry 大小
-
• compactionRateByEntries
-
• isThrottleByBytes
-
• 按照 Entry 数量(默认)
-
• compactionRateByEntries
Minor GC 和 Major GC
从代码实现逻辑上来看,Minor GC 和 Major GC 完全相同,二者区别在于触发时机和触发阈值。
| Minor GC | Major GC | |
| 压缩时间 | 1h | 24h |
| 压缩阈值比例 | 20% (minorCompactionThreshold) |
80% (majorCompactionThreshold) |
| GC 执行最大耗时 | minorCompactionMaxTimeMillis | majorCompactionMaxTimeMillis |
-
• Minor GC 压缩时间是 1h,Major GC 压缩时间是 24h。
-
• 压缩阈值比例的含义是 Bookie 里面有用数据的占比。在 Minor GC 内,Bookie 有用数据占比为 20%;在 Major GC 内,Bookie 有用数据占比为 80%。当有用数据占比超过 20% 和 80% 时,不对数据进行回收。Entrylog 里文件大小固定为 1.1 GB,假设 Major GC 有用数据超过 80%,那么可以理解为大部分数据都是有用的且不可被删除,Entrylog 全部保留。剩下的 20% 数据没必要耗费磁盘 IO 进行回收,通过多占用一定空间的方式降低磁盘 IO 的损耗。
-
• 为了避免一次 GC 执行时间过长,因此设定了 GC 执行最大耗时。超过规定的耗时就会强行中止 GC。
-
注意:
-
• 压缩阈值比例不可以超过 100%。
-
• Minor GC 的阈值必须小于 Major GC。
-
• 压缩时,必须要保证磁盘还有一定的可用空间。
Bookie 压缩
Bookie 压缩时,首先需要了解以下几个概念。(生产环境中配置 DBLedgerStorage,社区目前使用居多。后文所有 GC 回收流程和 BookKeeper 相关内容都在默认此配置的前提下展开。)
-
• Metadata Store:元数据存储中心默认使用 ZooKeeper。我使用的是社区提供的工具 ZK-Web,可以看到 Ledger 路径下存储了很多 Ledger。
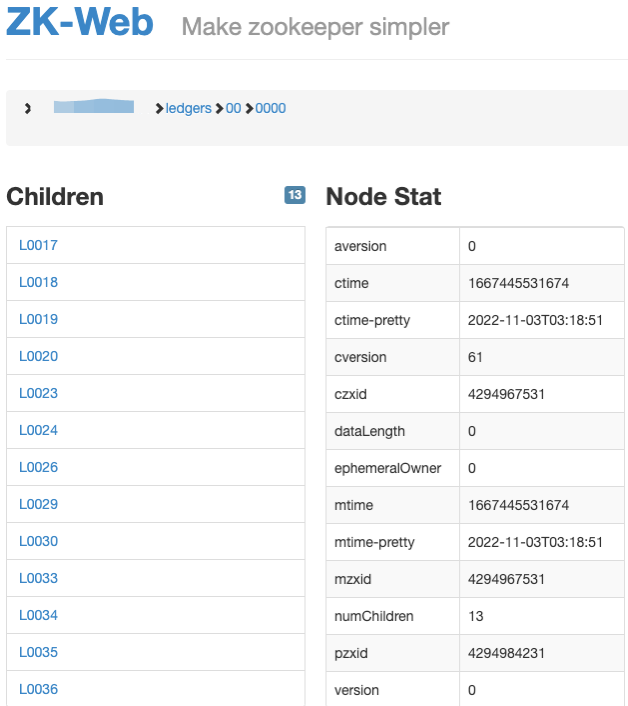
-
• LedgerIndex:RocksDB 中存储的 Ledger 集合。使用 DBLedgerStorage 即相当于用 RocksDB 做 Entrylog 的索引存储,读取数据时先读取 RocksDB 来找到索引数据,然后去 Entrylog 读 Value。这是一个拿 Key 取 “V” 的操作。
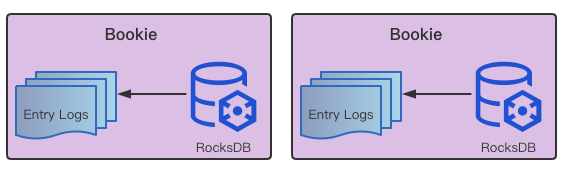
-
• LedgersMap:当前的单个 EntryLog 中存储的 Ledger 集合。
-
• EntryLogMetaMap:当前 Bookie 下所有 EntryLog,Key 是 Entrylog ID,Value 是 Entrylog Metadata。EntryLogMetaMap 是 EntryLogMeta 的集合,EntryLogMetaMap 中包含 LedgersMap 集合。
-
有了上面的抽象后,我们就可以进行判断。EntryLogMetaMap 的 Key 是 Entrylog ID,映射到 LedgersMap 集合。
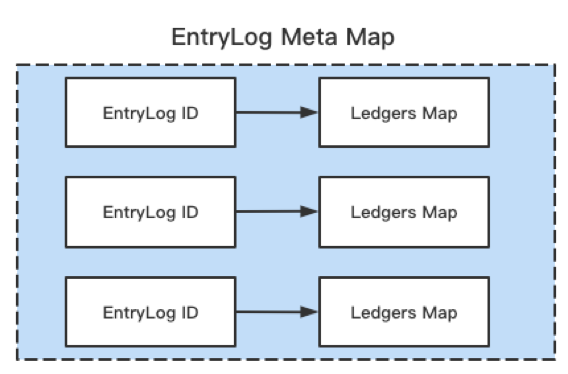
在整个压缩过程中,有三个核心的处理逻辑与函数:
-
1. doGcLedgers():处理 LedgerIndex 的集合(RocksDB),通过集合判断数据是否可以删除。
-
2. doGcEntryLogs():处理 LedgersMap 和 EntryLogMetaMap 的集合,以 doGcLedgers() 得出的集合为基准来判断当前 LedgersMap 中哪些 Ledger 可以删除,以及当前 EntryLogMetaMap 中哪些 Entrylog 可以删除。
-
3. doCompactionEntryLogs():在进行完上面两个步骤后就可以进行具体的删除操作。doCompactionEntryLogs() 处理 EntryLog 文件本身是否可以被删除,对于一个 Key Value 库来说如何进行删除也是一门学问。删除操作不能直接从 Key Value 集合删除,这样会造成很多消息空洞(消息不连续)。BookKeeper 中删除操作是从旧的 EntryLog 文件读取不可删除的数据写入到新的 EntryLog 文件中,相当于在新的 EntryLog 文件中进行备份,因此旧的 EntryLog 文件可以一次性删除。
前文多次提到了 EntryLog,下面将介绍 BookKeeper 中 EntryLog 如何存储、存储了什么。Entrylog 的构成从上至下核心数据分为三部分。下图可以帮助大家了解 Entrylog 的大致结构,如需精确了解,可以阅读相关源码。
-
• Header:包含指纹信息(BKLO,标识 Entrylog 文件,用于校验)、BookKeeper 版本、Ledgers Map Offset(Offset 偏移量、如何读取等)与 Ledgers Count(一个 Entrylog 内 Ledger 的数量)。
-
• LedgerEntry List:LedgerEntry 对象,包含 Entry Size、Ledger ID、Entry ID 和 Count。
-
• Ledgers Map:包含 Ledgers Map Size、Ledgers Count 和 Ledgers Map Entries。每一个 Ledgers Map Entries 是 Key Value 结构,由 Ledger 映射到 Size。
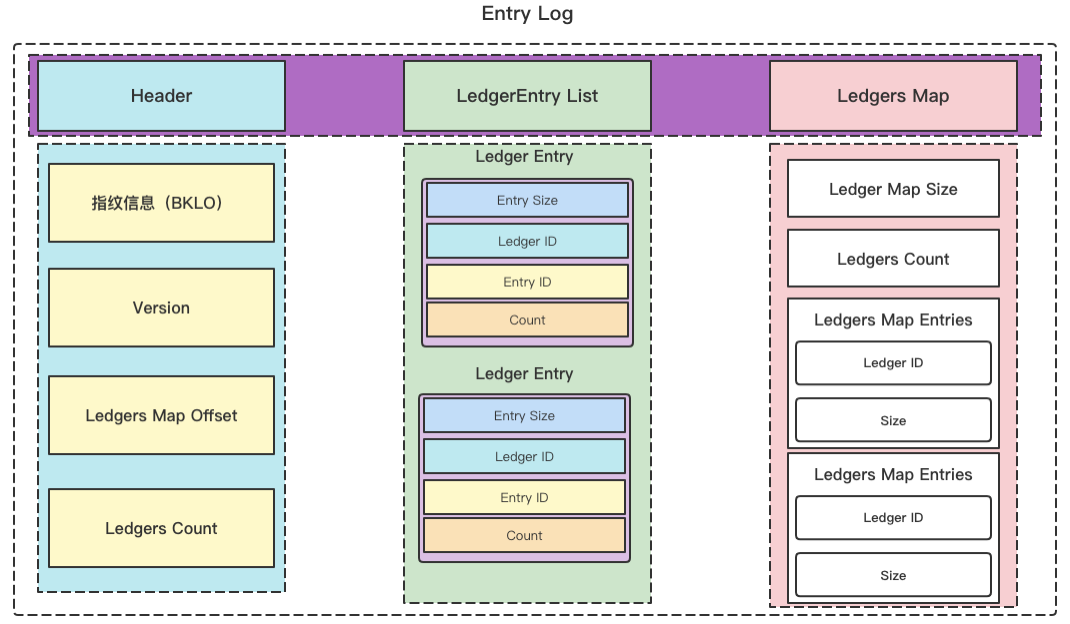
数据回收全流程
有了上面介绍的基础概念,我们就可以把数据从 Broker 到 BookKeeper 的回收流程串联起来。
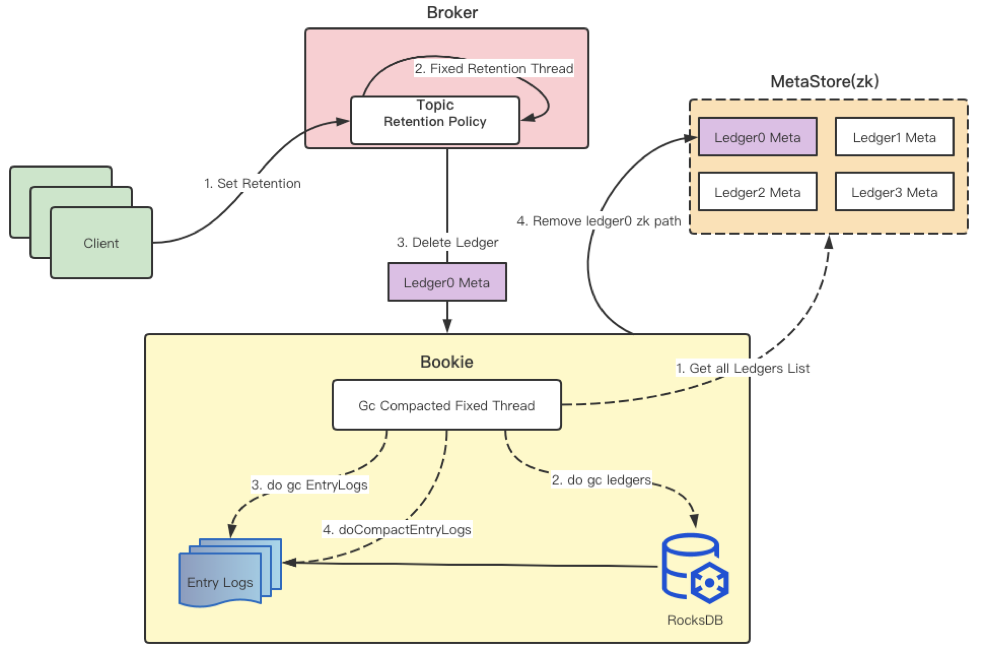
首先 Client 触发流程。创建 Topic 建议设置 Retention 策略,不设置的话默认策略是消费完成即删除该消息。设置 Retention 策略后,Broker 有定期检查的线程,周期性针对 Topic 执行 Retention 策略。到期可删除的 Ledger 调用暴露的 Delete Ledger 接口,如图 Ledger 0 可删除,即调用 Delete Ledger 删除 Ledger 0。删除 Ledger 0 后 ZooKeeper 中移除 Ledger 0 的 ZooKeeper 路径。这就是完整的删除流程,上图不包含返回逻辑。
Delete Ledger 从调用到返回成功的过程中没有使用 BookKeeper 磁盘上的数据。用户可能会困惑调用接口删除 Ledger 为何没有释放磁盘空间,原因在此,因为删除操作和 BookKeeper 回收磁盘的操作是完全异步化的。BookKeeper 回收磁盘的操作由 GC Compaction 线程固定进行处理。
那么,GC Compaction 周期性执行线程如何运行?GC Compaction 周期性执行线程就是 Minor GC 和 Major GC。在操作流程上,首先会获取 ZooKeeper 内所有 Ledger 列表。因为创建 Ledger 需要向 ZooKeeper 注册对应的 ZooKeeper 路径,删除 Ledger 也需要从 ZooKeeper 上删除路径。ZooKeeper 上的 Ledger 路径最全面也最准确,因此以 Metadata Store (zk) 为基准来获取所有 Ledger 列表的集合。然后进行 doGcLedgers() 操作,把 RocksDB 中所有 Ledger 列表集合与 ZooKeeper 上获取的 Ledger 列表集合做比较,找出可以删除的 Ledger。删除后进行 doGcEntryLogs() 操作,处理 LedgersMap 和 EntryLogMetaMap 的集合,判断 EntryLog 中哪些 Ledger 可以删除。进一步删除后进行 doCompactionEntryLogs() 操作,最理想的情况下,Entrylog 里面所有的 Ledger 都可以被删除,那么就可以直接清除这个 Entrylog。大部分情况是 Entrylog 里部分数据可删、另一部分不可删,那么如何判断是否保留 Entrylog 呢?由 Minor GC 和 Major GC 的压缩阈值比例决定。
我们结合下图了解如何通过 doGcEntryLogs() 来 doCompactionEntryLogs()。假设 doCompactionEntryLogs() 时通过 Major GC 的阈值判定一部分未达标的数据可以进行回收,那么 GC Compaction 线程首先从旧的 Entrylog 中检查 Ledger 是否可以删除。假定 Ledger 0 和 Ledger 2 可以删除,Ledger 1 和 Ledger 3 不可以删除,检查到可用性占比后根据阈值判断 Entrylog 可以删除,那么就把 Ledger 1 和 Ledger 3 的有用数据写入新的 Entrylog 文件,有用数据有备份后就可以删除旧的 Entrylog 文件。
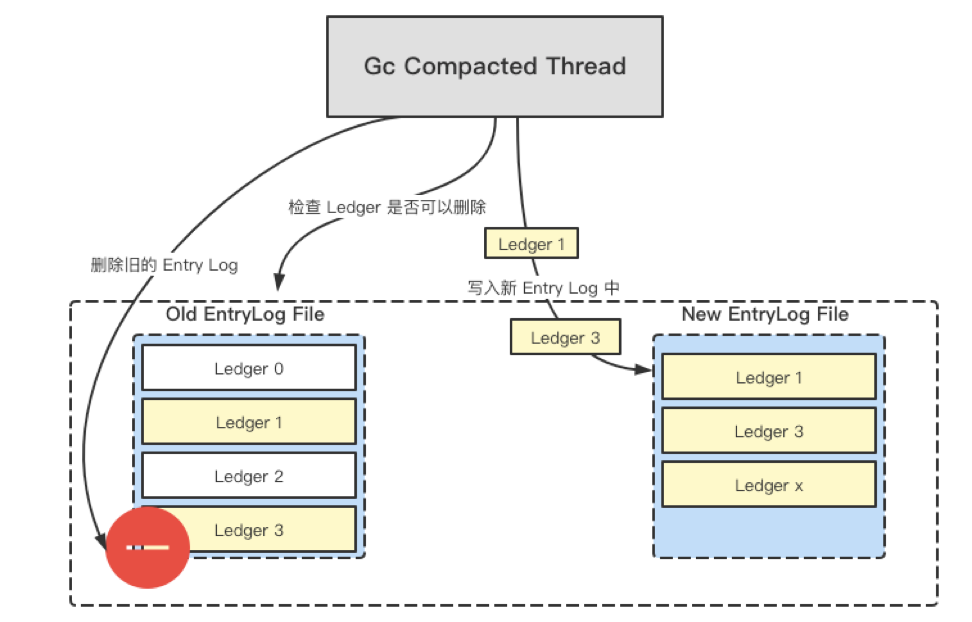
此处需要补充一点,创建新的 Entrylog 文件时还有一个动作叫做 Flush。旧的 Entrylog 文件在创建时会产生索引信息,Bookie 里 Entrylog 在读取 Entry 时,比如读取 Entry 0、Ledger 1 的数据,会根据索引信息来追溯对应的 Entrylog。在删除旧的 Entrylog 文件并创建新的 Entrylog 文件操作完成之后,新的 Entrylog 文件索引信息需要更新到 RocksDB,通知上层的读请求去寻找新的 Entrylog 文件中生成的十六进制的 ID 来读取 Entry 0、Ledger 1 的数据。
以上是消息完整的生命周期,包含从 TTL 与 Retention 策略到 Bookie GC 回收机制的全流程。
脏数据的产生
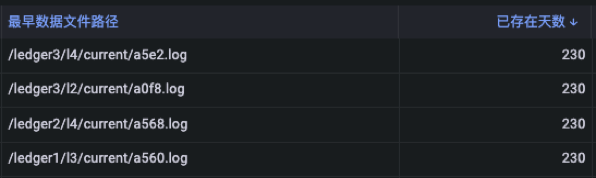
下面介绍在实际生产中遇到的问题。在下图中,我们监控了每个 Bookie 上的 Entrylog 文件发现,假设设置的 Retention 策略周期为 1 天或 5 天,但是这些 Entrylog 文件已经存在超出 200 天还没有被删除。这是异常情况,文件不删除会一直占用磁盘空间。经过分析,以下三个情况可能导致脏数据的产生:
-
• Ledger 删除逻辑出错,导致孤儿 Ledger 产生:回顾数据回收全流程,Ledger 删除操作分为两个部分:从 ZooKeeper 中清理路径和 GC Compaction 线程清理 Entrylog。社区发起了 PIP[1] 进行双阶段删除,来保证删除过程中不会产生孤儿 Ledger。
-
• Broker 不会加载不活跃的 Topic,导致 Retention 策略没有生效:目前社区正在改进该逻辑。BookKeeper 唯一暴露的 Delete Ledger 操作只有在设置 Retention 策略后才能掉入行为。因此如果 Retention 策略没有生效,Broker 不活跃 Topic 产生的 Ledger 就无法被删除。
-
• GC 回收阈值设置不合理,导致一部分数据无法从 EntryLog 移除:这是上图中产生存在 200 多天的 Entrylog 的主要原因。根据对用户数据的调配发现,系统没有按照 80% 的有用数据占比来设置回收阈值,而是调整为 50%,导致一半的数据一直存在于 Entrylog 中,无法删除 Entrylog。
-
• 存在不活跃的 Cursor(不活跃即是 Sub 下没有对应的消费者),这些 Cursor 对应的 Ledger 无法被删除:目前提出的方案是增加校验逻辑,如果 Cursor 一段时间内不更新则删除,此方案还有待商榷与验证。无论以上哪一种情况,都会导致 Ledger 脏数据无法删除。因此下面我们展开讲解如何删除脏数据。在了解删除脏数据前,需要了解一个概念叫 Custom Metadata。在 Broker 生成或者创建 Ledger 时,可以给 Ledger 设置一部分元数据,即自定义 Ledger 的元数据属性。下图是 Pulsar 默认提供的 Custom Metadata,通过 BookKeeper Admin ctl 获取到的 Pulsar Managed Ledger Base64 信息。这一串属性反写出来就是一个 Topic 的信息,只有拥有 Topic 信息才能进行后面的操作。
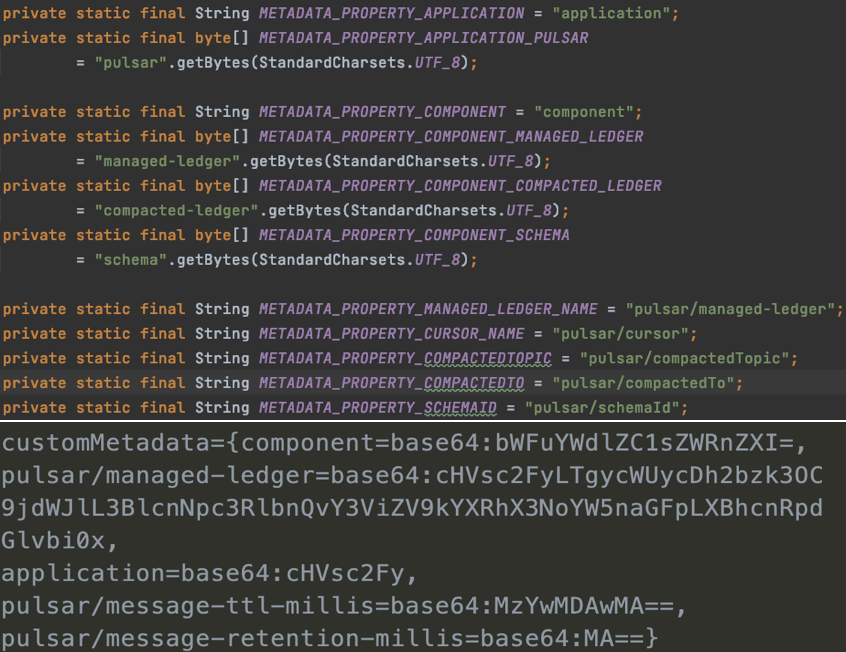
通过 Ledger Metadata 可以获取 Topic 信息,即 Ledger 的 Owner Topic。然后我们就可以开始清除这些脏数据。
清除孤儿 Ledger
清除孤儿 Ledger 使用 Clear Tool 清除工具。过程如下:
-
• 从 ZooKeeper Snapshot 中获取所有的 Ledger 列表(如果线上环境压力不大,也可以直接连接 ZooKeeper 读取,不需要使用 Snapshot。)从 ZooKeeper Snapshot 中获取所有的 Ledger 列表后,通过 BookKeeper Admin 工具获取 Ledger 的 Custom Metadata。
-
• 通过 Custom Metadata 找到该 Ledger 的 Owner Topic,并在 Broker 内查看是否存在该 Topic。
-
• 如果 Broker 内 Topic 不存在,Client 首先访问 Broker 就无法成功。BookKeeper 存储数据没有意义,可以直接删除。
-
• 如果 Broker 内 Topic 存在, 就会进一步检查 Ledger 是否存在,Topic Stats Internal 列表展示了 Topic 内所有 Ledger 的情况,用来确认该 Ledger 是否包含在该 Topic 中。注意,Topic Stats Internal 命令有时候可以可以获取到 Ledger 列表,有时无法获取,解决方法是重复获取,如果仍获取不到,那么将判定为列表不存在。
-

Topic 所有的属性以及 Topic Stats Internal 等指标信息都是 Broker 向 ZooKeeper 获取的。以上检查都过后就可以从 BookKeeper 中删除 Ledger。Ledger 删除逻辑和前文回收流程相同,首先删除 Ledger 的 ZooKeeper 路径,Ledger 占用的磁盘空间通过 GC Compaction 线程走异步流程进行删除。
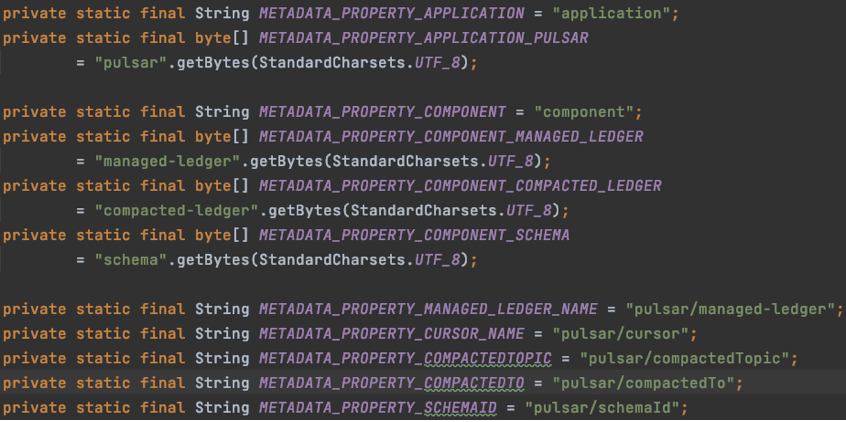
此外,Schema 和 Cursor 信息也会使用 Ledger 来存储。下图中有一个信息是 Pulsar Schema ID,如果用户指定了 Schema 是 String、Json,那么就会产生也对应 Ledger 的 Schema 属性,ZooKeeper 下面也会存储 Schema 信息。检查 Stats Internal 时可以获取到 Schema Ledger 和 Cursor Ledger,需要仔细查看。
注意:清理脏数据时一定要备份。ZooKeeper Snapshot 备份可以在错误删除后恢复数据。
总结
文章从用户视角出发,讲述了消息存储到 Bookie 中的流程,并阐述 Bookie 的垃圾回收机制,以及 TTL 和 Retention 策略如何作用到 Bookie Client 触发垃圾回收机制。希望可以为用户在生产环境中的操作提供参考。
引用链接
[1] PIP: [https://github.com/apache/pulsar/issues/16569](https://github.com/apache/pulsar/issues/16569)
本文转载自冉小龙 ApachePulsar,原文链接:https://mp.weixin.qq.com/s/q8qluRMLqWC1XApjirY9_w。