尘锋信息基于 Apache Paimon 构建流批一体湖仓,主要分享:
-
-
基于 Flink + Paimon 的数仓 批 ETL 建设
-
基于 Flink + Paimon 的数仓 流 ETL 建设
-
尘锋信息 (www.dustess.com) 是基于企业微信生态的一站式私域运营管理解决方案供应商,致力于成为全行业首席私域运营与管理专家,帮助企业构建数字时代私域运营管理新模式,助力企业实现高质量发展。
尘锋有着强大的研发技术团队,企业内部有着浓厚的学习氛围,尤其是研发团队的技术学习氛围。早期为产研团队开设独有的【尘锋公开课与微课堂】学习体系,主要以技术分享,最佳实践研讨为主。后期更是成立了尘锋学院覆盖全公司的员工,包括但不限于通用技术、管理技能、产研技术、解决方案、行业案例、市场拓展等方面的知识分享与内容沉淀,为公司全员提供跨区域、跨岗位、跨专业的学习平台。
经过两年多的快速发展,尘锋已经成长为拥有近千名员工的高新技术企业。
目前已在全国拥有13个城市中心,覆盖华北、华中、华东、华南、西南五大区域,形成了贯穿南北,辐射全国的城市服务网络,累计服务30+行业的10000+企业。
如上图尘锋信息在Paimon之前有以下两套数据仓库。
TiDB + HDFS + Yarn + Apache Hive + Apache Spark + Apache Doris
离线数仓用于覆盖批处理场景 ,覆盖业务场景主要是 T+1 和 小时级 延迟的报表需求
1、 离线数仓延迟过高,且批量从业务库拉取数据同步容易影响业务
2、基于 Hive 的离线数仓对于 CDC采集 和 更新场景 治理建模有较大的侵入性,开发成本较高
3、HDFS 相比于云厂商提供的对象存储,成本依旧很高
4、私有化困难,需要部署 Hadoop 整套生态,对于私有化数据量较小的单租户,硬件及维护成本过高
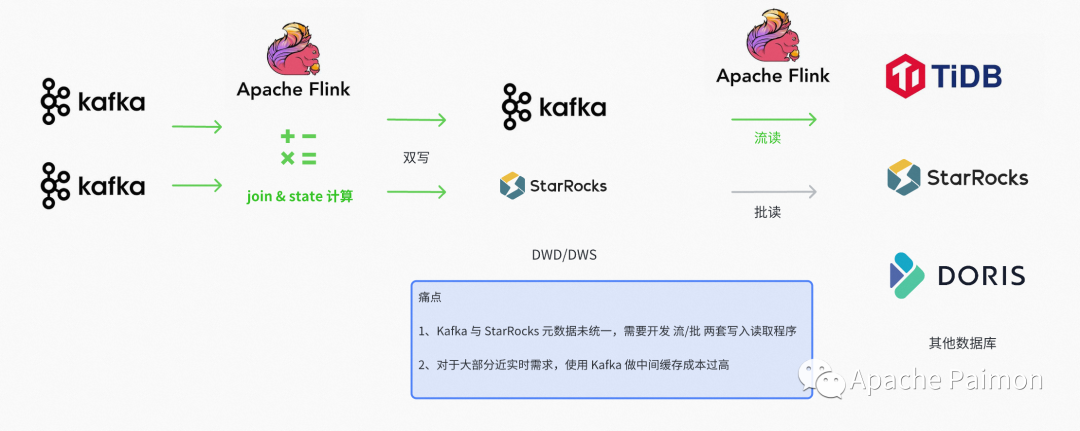
Apache Kafka + Apache Flink + StarRocks + K8S
实时数仓用于覆盖流(Flink) 和 微批(StarRocks),覆盖业务场景是 秒级 (流) 和 分钟(微批)低延迟的高价值报表需求
1、实时链路 SR 虽然有较好的流写能力,但不支持流读,不便于数仓依赖复用,每层之间使用Apache Kakfa对接,又造成较大的 开发维护成本
2、实时链路使用SR微批调度处理 会导致非常高的资源占用导致 OLAP 慢查 甚至稳定性问题
3、SR 不支持Overwrite 等批处理能力
4、与离线数仓割裂,造成数据孤岛
新架构需求
结合以上的痛点,我们决定Q1进行数仓架构调整,我们的业务需求主要有以下几点:
2、准实时需求 ,延迟可以在分钟级 (要求入湖端到端延迟控制在 1分钟左右)
5、兼容私有化 (整个环境不依赖 Hadoop 、Hive 等比较重的组件,降低部署运维成本)
为什么选择Paimon
对Paimon进行了深入的调研和验证,发现Paimon 非常满足我们的需求:
1、基于LSM ,具有很高的更新能力,默认的 Changelog 模型可以处理 CDC 采集的变更数据(实测入湖端到端延迟能控制在 1分钟左右)。另外Paimon 支持 Append Only 模型,可以覆盖没有更新的日志场景,该模型在写入和读取时不用耗费资源处理更新,可以带来更高的读写性能和更低的资源消耗。
2、支持 批写 、批读 ,并且支持 (Flink、Spark、Hive 等多种批处理引擎)
3、支持 流写、流读 (结合Flink 的批处理,我们希望后期能够建设流批一体的数据仓库)
4、Paimon 支持将一张表同时写入 Log System(如 kafka) 和 Lake Store (如 OSS 对象存储),结合 Log System 可以覆盖秒级延迟的业务场景,并且解决了 Kafka 不可查询分析的问题
5、支持 OSS 、S3、COS 等文件系统 ,且支持 FileSystem catalog ,可以完全与 Hadoop 、Hive 解耦
6、支持 Trino OLAP 引擎,实测 分组分析 5亿 200GB 数据,30 个Bucket,能够在10秒内出结果 (和社区沟通,还有优化空间),但满足目前需求。另外,Apache Doris 已经开始对接 Paimon格式,相信不久之后Paimon的OLAP生态会更加丰富。
7、社区活跃,从2022年初开源 至 2022下半年,短短几个月,就已经发布几个大版本。0.3 的功能已经非常足够落地去解决一些生产问题,0.4 近期也快发布,0.4(Master) 目前我们已经用于生产,非常稳定。
虽然起步晚,但是后发优势非常明显,且没有历史包袱,抽象解耦非常合理。相比 Hudi等设计之初就捆绑 Spark 的背景,Paimon 一开始就定位支持多引擎,所以未来的潜力和扩展空间是巨大的。
另外 ,社区活跃度上 PPMC 在社区群里直面用户,热心解答疑问,任何问题都会得到及时的回复。目前加入社区群的同学越来越多,我们也希望能够积极参与社区,帮助PPMC们减少负担。
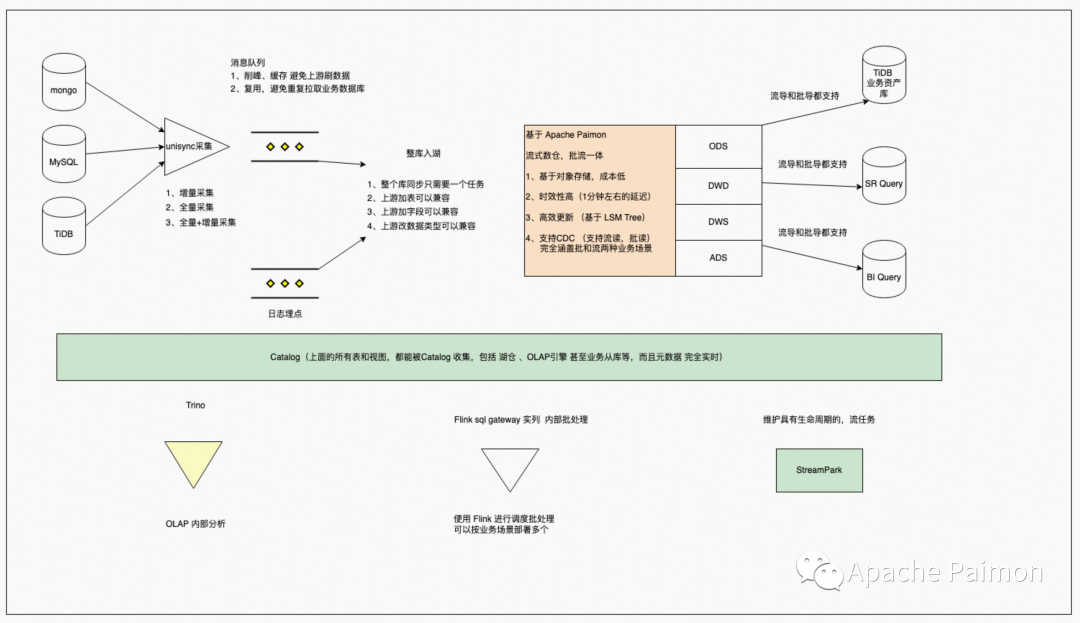
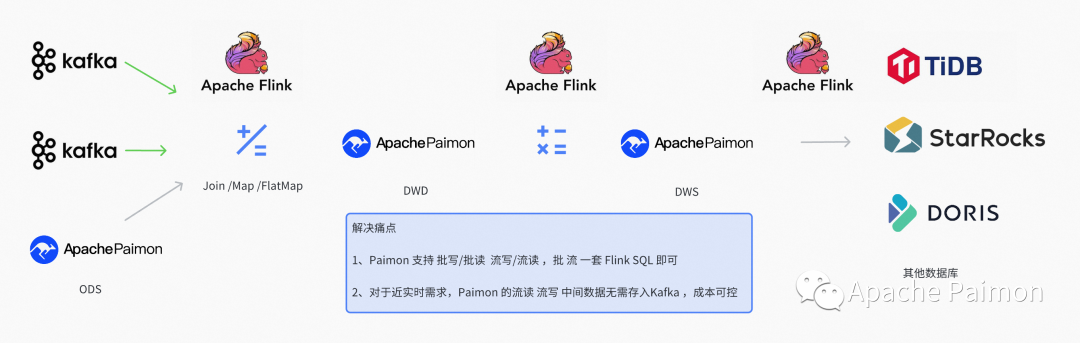
结合 Paimon ,我们Q1 落地的湖仓一体架构如下
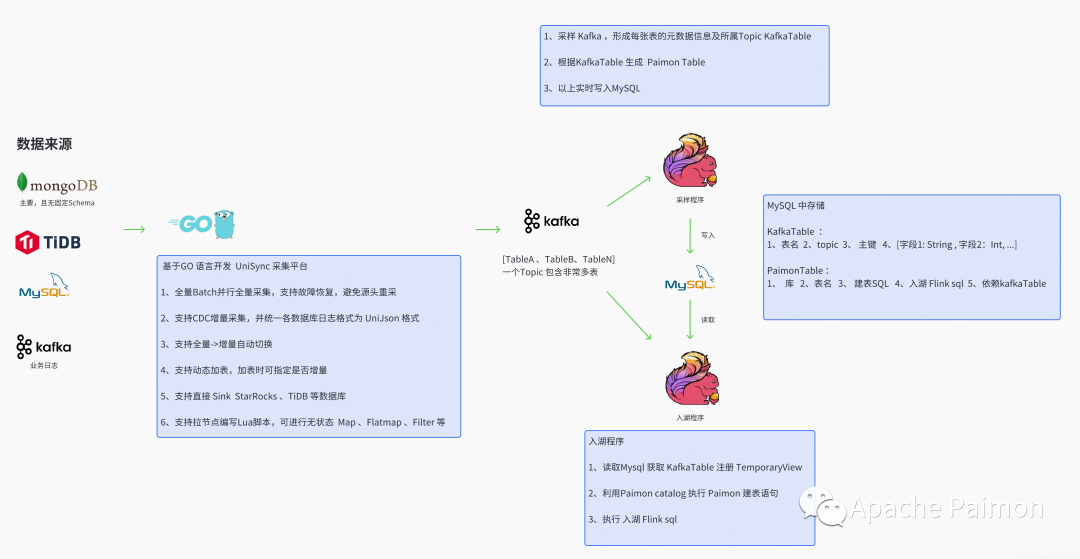
基于GO语言开发,自研Unisync 采集平台, 功能如下
1、支持 CDC 增量采集多业务数据库(MongoDB 、TiDB 、MySQL),将不同类型的数据库日志格式进行统一,便于下游使用
2、支持 Batch 并行全量读取,且支持故障恢复,避免过程中失败而重新拉取浪费时间
3、支持全量 和 增量采集自动切换 ,支持动态加表,加表时可指定是否增量
4、支持直接 Sink StarRocks 、Doris 、TiDB 等数据库
5、支持嵌入Lua脚本,可以进行无状态的 Map 、FlatMap 、Filter 等
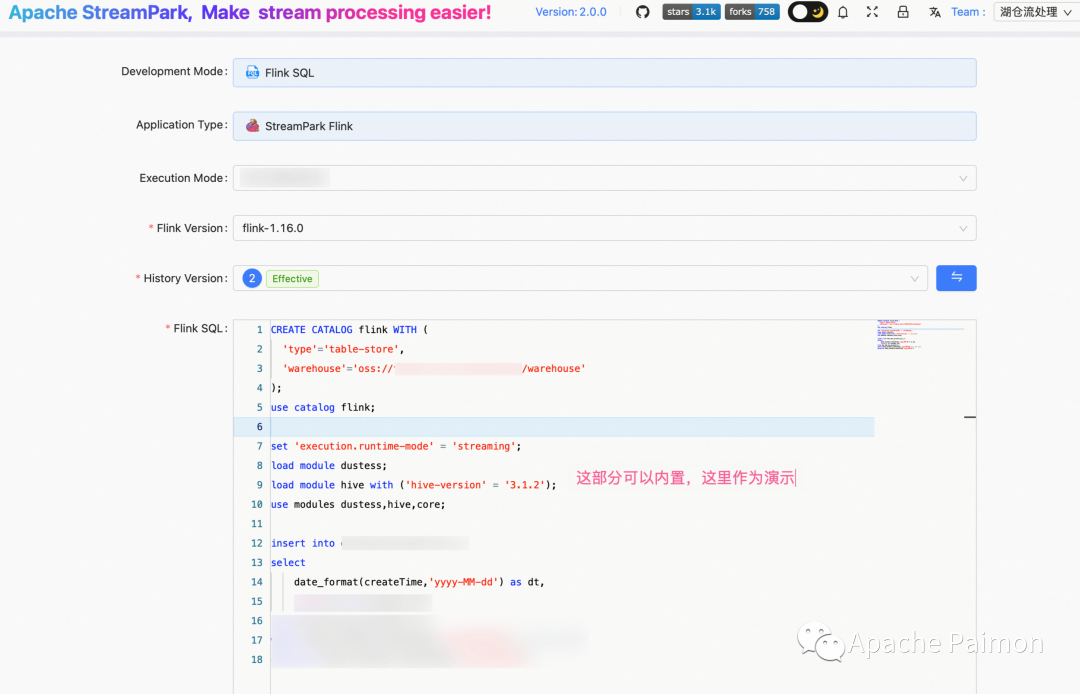
基于 Flink DatasSream API 开发 ,并通过 StreamPark 部署,功能如下
1、消费Kafka ,将Kafka 中的半结构化数据(MongoDB) ,进行解析,并将字段 – 类型保存至 State
2、有新增的字段自动加入State中,并将该条消息补齐字段和类型,发送至下游算子
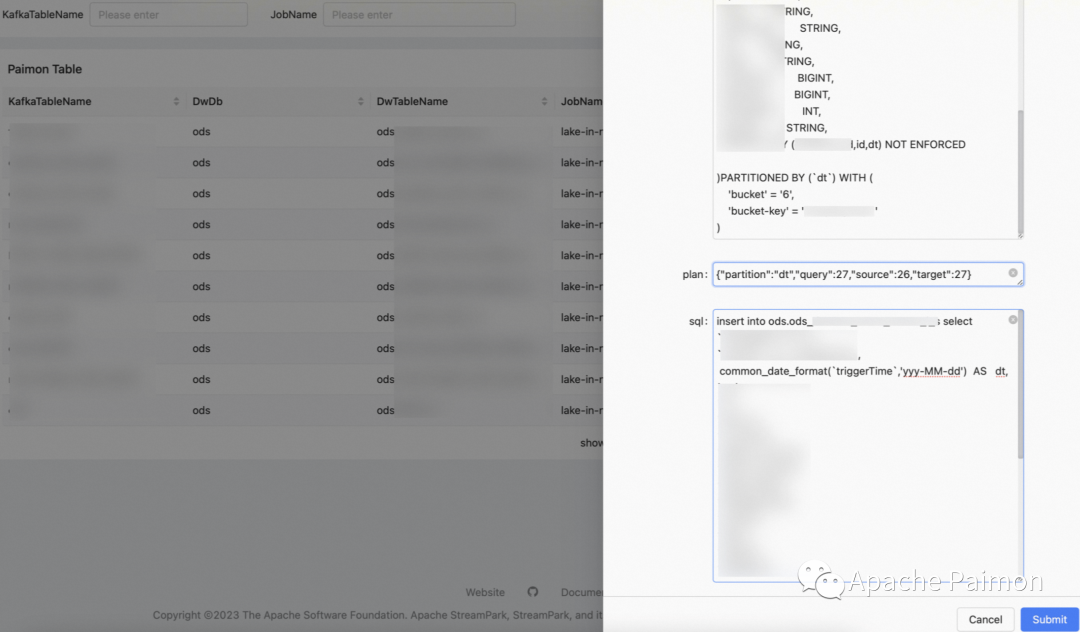
3、自动生成 逻辑 Kafka Table (见上图详解)
4、自动生成 Paimon Table 及 入湖 Flink SQL (依赖 Kafka Table 元数据信息,见上图详解)
5、入湖 Flink SQL 会将 Kafka Table 中的所有字段列出形成别名,自动使用UDF处理 dt 分区字段等等 。
6、另外有业务非常复杂的场景,可以在管理页面中,编辑生成的 Flink SQL,增强功能等等
基于 Flink DataStream API + Paimon 0.3 开发,并通过 StreamPark 部署,功能如下
1、每个Flink Job 可以配置读取多个 Kafka Topic ,并设置起始时间 或者 Offset
2、程序内部根据 Kafka Topic 查询 MySQL ,获取 Kafka Table 元数据信息
3、通过 DataStream API 读取 Kafka 得到 DataStream 类型,
通过表名,分流形成每个表单独的 DataStream
通过 fromChangelogStream 将 DataStream 转换为 Flink Table 并注册 TemporaryView
通过 Flink sql 不仅可以在入湖时做 Map Flatmap 甚至可以多流 Join 、State计算等
4、启动时 使用 Paimon 的 Flink Catalog API 根据MySQL 中的Paimon建表语句创建表
5、TabEnv 提交采样程序生成的入湖 Flink SQL
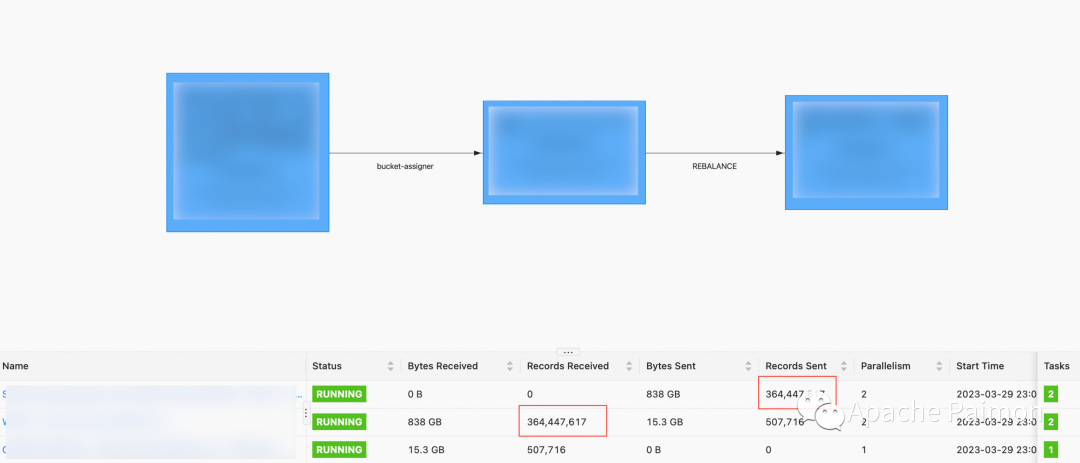
由于当初开发这套入湖程序时Paimon 0.3 还不支持 JAVA API ,所以任务节点会比较多,不过实测增量入湖50张表,2TB 左右数据,分配内存6GB ,并发 2 可以稳定运行 (2分钟左右checkpoint间隔)
Paimon 0.4 已经支持 JAVA API ,入湖的灵活性和功能性都会更加强大,我司也正在跟进优化。
Paimon 基于 LSM tree ,对于流写的场景,Writer 算子实时接收CDC 流,达到一定阈值之后才Sink 写入磁盘,当执行checkpoint 时,Writer 算子和 commit 会处理合并,如果 bucket设置不合理,则可能导致checkpoint 超时 (建议一个 bucket 存 1GB 左右数据量)
1、全量整库入湖 80+ 表,近 2TB ,全量写入阶段不处理更新,可以将checkpoint 设置4分钟左右
2、对于全量重刷一张大表的情况,需要更新非常多的 分区 和 bucket ,建议将表Drop后再全量写入
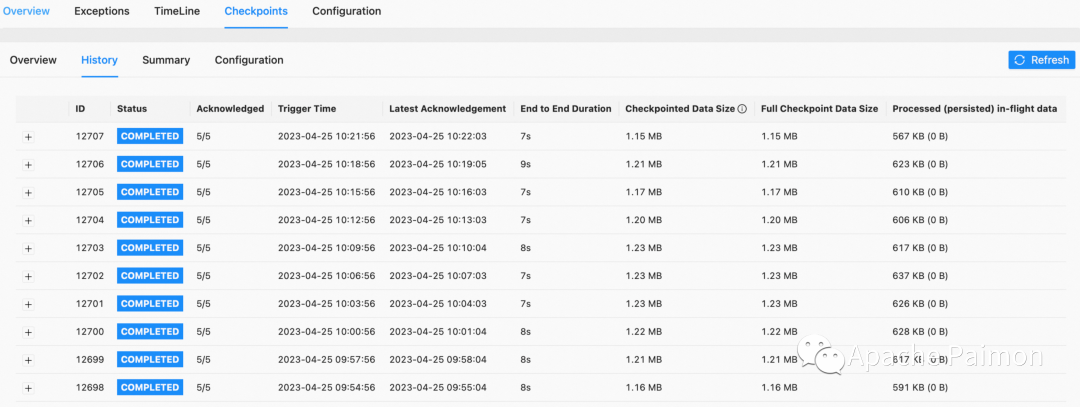
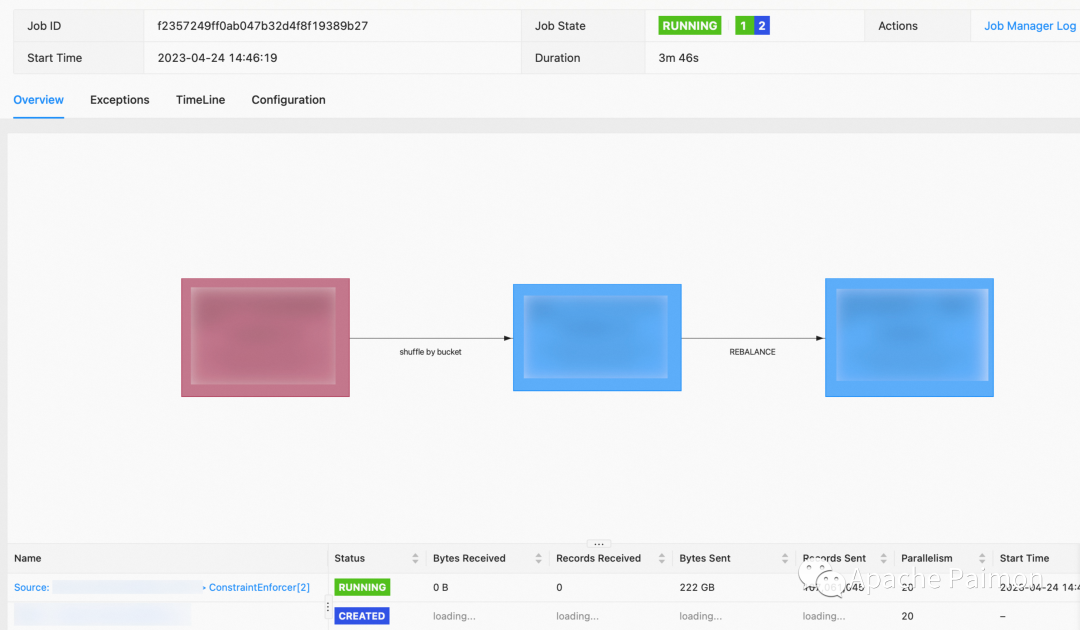
3、(下图)增量更新 150 + 字段 ,1.3 亿条(300GB存量)数据的大维度表 ,分40个 bucket 。如图,已经更新近 4亿次,增量800GB,目前 checkpoint 保持在10秒内。
资源:( 2并发 、TaskManger 4GB 内存 2 slot ,JobManager 1GB 内存 ) Paimon 基于 LSM tree 自动合并文件,基于上表已经更新近 4亿次 800GB 的情况下,大部分bucket 内的文件数能够控制在 80个内,不用担心小文件过多问题。
分别对一张 Append Only 日志表 和 Change Log 维度表进行增量稳定性测试 (数据量适中)
资源配比都是是 1个 TM 4GB 内存 2 slot
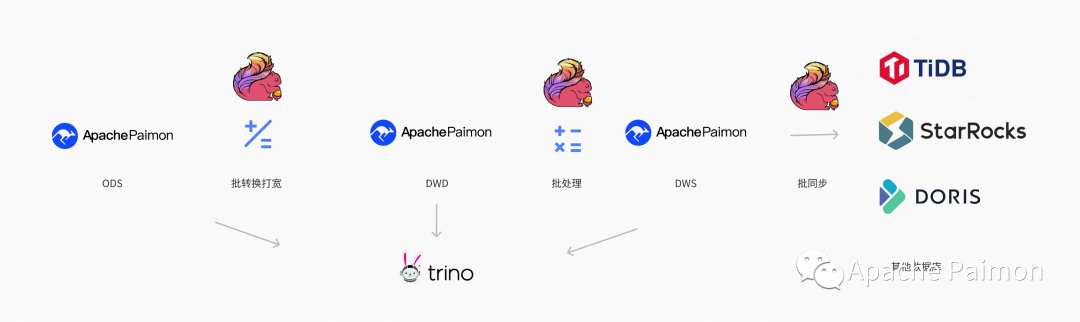
1、满足 T+1 / 小时级 的离线数据批处理需求
4、以上三种情况,业务SQL 不应该做过多侵入,而只需要修改参数和资源占用,就可以进行升降级
5、湖仓中治理后的部分高价值数据,需要支持 批 和 流两种 模式写入 StarRocks / Doris /TiDB 等数据库
尘锋批处理主要用于覆盖T+1 和 小时级的业务需求
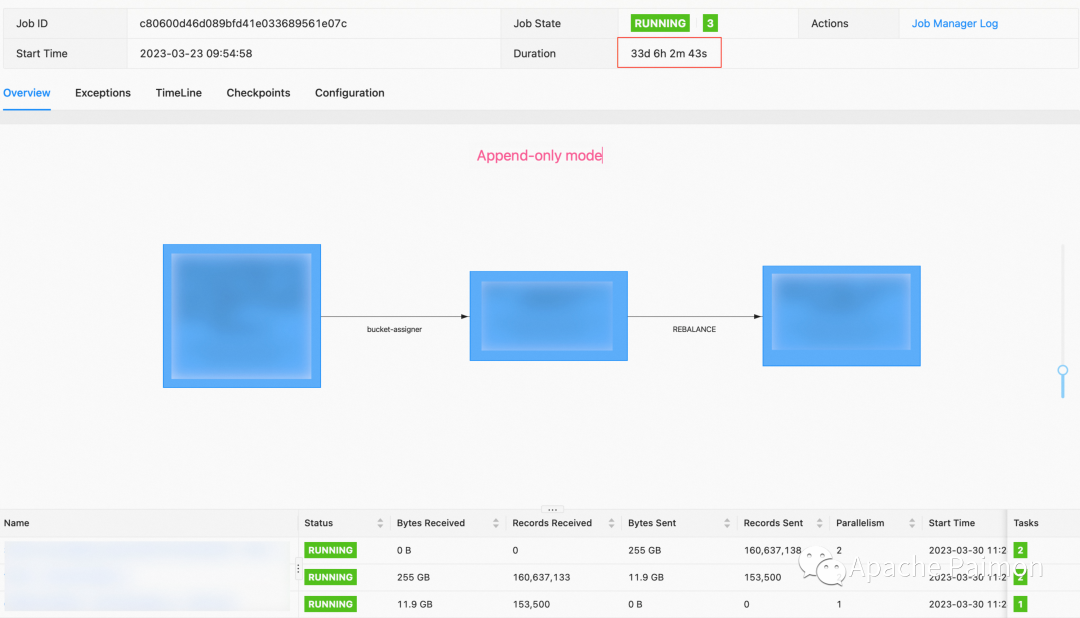
1、 存储侧选择 Paimon ,因为 Paimon 支持 Append-only 和 changelog 两种模式,支持 insert overwrite insert into 两种写入方式 。
2、计算引擎侧我们选择 Apache Flink ,并结合 flink sql gateway + flink sql + DBT 来进行批 ETL 的开发和提交部署。
Paimon 支持 Append only 模型 ,配合批覆盖写、批读 ,性能表现表现不亚于 Iceberg 。由于我们的更新场景较多,所以我们更加关注 Changelog 模型的读写
1、如上图,通过 Flink + Paimon 测试批读 Changelog模型(MOR) 220GB 、 一亿左右数据 、 20 并发 ,需要 3分钟左右,每个 TM 1 slot ,内存分配2GB 左右
(注意:由于我们使用测试的服务器是内存型 8C 64GB,所以该项测试数据并不是 Paimon 的最佳性能,理论 CPU 计算型服务器会更加出色,提供以上数据供大家参考)
2、ChangeLog 写入性能可以参考入湖侧。另外对于 Append only 不用处理更新,表现会更加出色,非常适合 insert overwrite 等批覆盖场景
3、Paimon 支持批模式 Partial Update ,可以覆盖批增量 Join 场景
为了满足流批一体的目标,我们的批处理引擎也选择主要使用 Apache Flink (以下简称 Flink )
Flink 1.16 的批处理能力得到非常大的改进 ,并且提供了 flink sql gateway 用于提交批作业(支持 rest endpoint 和 hiveserver2 endpoint )
Flink 1.17 近期已经发布,批处理能力 和 sql gateway 进一步得到了加强,我们已经在生产测试。
选择使用 flink sql gateway 进行批处理任务提交和管理的原因如下
1、sql gateway 具有交互式开发的能力,可以利用Flink 生态丰富的 connector,非常方便的读取 和 写入
Paimon 、SR、Doris、MySQL、TiDB 、Kafka 等, 甚至可以覆盖部分OLAP 场景。用于数据开发场景,可以极大的降低 Flink sql 的使用门槛 ,提升开发调试效率 和 降低维护成本
2、sql gateway 支持对接 remote 、yarn session、yarn per job(虽然已经过时,但可在支持 Application mode前暂时使用)等多种任务提交方式。并且 sql gateway 可以根据业务场景部署多个,分别对应不同的 session 或 standalone。对于在私有化部署等场景,湖仓方案可以根据私有化用户的需求进行灵活低成本的部署。
sql-gateway.sh start -Dexecution.target=yarn-per-job
当前我们生产使用基于Flink 1.16版本的 sql gateway还有一些不足,于是为了更好的和 dbt 数据构建工具整合,我们基于官方 hiveserver2 endpoint 实现 了 dustess_hiveserver2 endpoint ,增强功能如下
1、支持配置式内嵌多种 Catalog ,如 Paimon 、TiDB、SR、Doris、MySQL 等
2、支持配置式内嵌多种 Module ,主要是我们内部实现的 UDF 和 UDTF
3、修改默认语法为 Default (Flink)
4、扩展支持 Application mode (进行中)
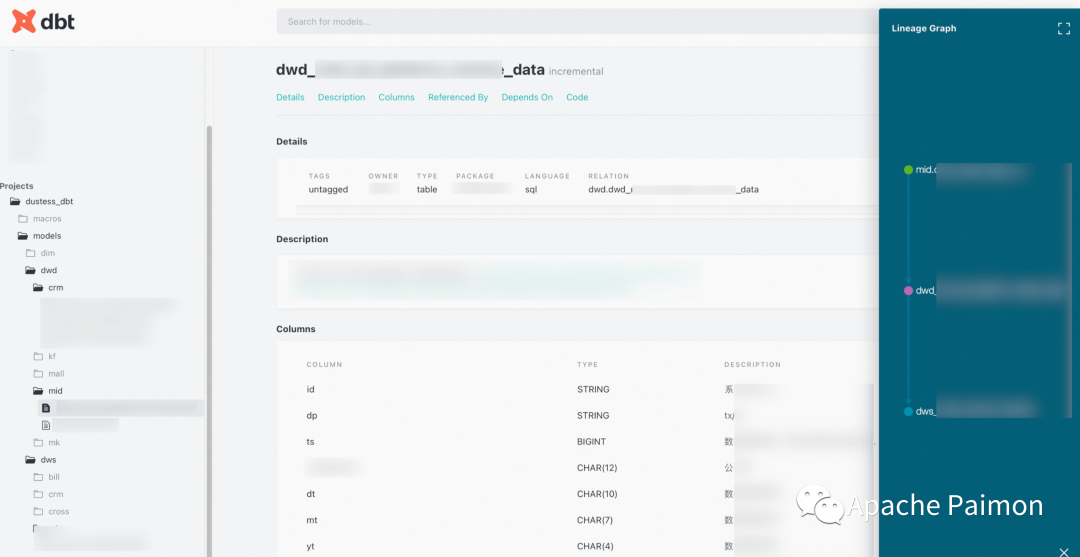
1、可以完全用编写工程代码 (如 Java 、Go等语言)的方式去构建数据仓库,所有的模型统一在 git 仓库,可以review 、PR 、发布等流程控制,极大的提高模型复用率和避免烟囱开发 。
2、数据开发只需要开发 select 语句,dbt 可以自动生成结果表结构,以及基于yml 的模型注释,极大的提高了开发效率 。并且dbt 支持非常多的 宏 语句,可以将非常多的重复工作复用,并且统一和收敛口径。
3、dbt 可以根据 source 和 ref 语法自动生成数据血缘,且也可以通过命令生成模型文档
Paimon 支持 流写 流读 (ODS 全部使用Flink 增量写入)
由于我们业务库以MongoDB 为主,有非常多的 JSON 嵌套字段,所以我们有较多的单表 Flatmap 需求,并且我们有非常多大量的不适合时间分区的大维度表,列多,更新频繁,于是非常适合用 流模式 来增量进行 Map 和 Flatmap
在Paimon之前,我们将打平好的表写入 dwd 提供服务之后,如果下游的 dws 需要使用 dwd 直接聚合分析,我们采用双写 Kafka + 结构化表的方式,这样带来的缺点是 ,开发复杂,维护困难,并且 Kafka 中的数据不可分析,下游的排查会比较麻烦。并且对于一些时效性要求不高的(比如分钟级延迟)场景,使用Kafka + 结构化表的成本实在太高,不是一个持久的方案
Paimon 支持流读,对于上述Flatmap后的dwd 表,下游直接使用流读即可获取 dwd 的changelog 流,时效性可以达到分钟级的延迟,这样 ODS->DWD-DWS 的变更数据就在每层之间流动起来,完全覆盖大部分准实时需求。
对于极少数的秒级需求,Paimon 支持 Log system (如Kafka ) + Lake Store 的混合存储方式,并且能够做到逻辑及使用层面的统一,HybridSource 和 HybirdSink 内部自动处理从 Kafka 或 Lake Store 读写 ,极大的减少了开发维护成本。
ODS的数据是使用Flink流式准实时写入,湖仓中DWD和DWS主要的治理需求为
1、Map、flatmap转换(对于此场景,流和批的SQL完全一致,只需要做提交sql的模式配置)
2、join 形成宽表 (join在流场景下复杂度要高于批,Paimon提供了带有相同key的部分列更新,lookup join等降低复杂度和成本,在sql层面和批是一致的)
3、分组聚合计算 (流利用 State 计算,但是sql 和 批也是一致,只需要做流的参数配置即可,如流的state ttl 配置等)
由于Paimon在存储侧实现批及流的统一,困扰Flink用户许久的流批分裂问题,已经得到了根本性的解决
Paimon 官方支持多种引擎 ,目前我们使用 Trino 部署在 K8S 中 OLAP 分析Paimon ,前端使用Superset 等BI 工具,可以满足绝大多数的内部分析需求。
通过Trino 读取 Iceberg VS Trino 读取Paimon(都是 Append Only模型) ,5亿 200GB 维度表分组聚合 ,Iceberg 是 7秒 ,Paimon 10秒,两者的差距主要在读取性能,Iceberg读取ORC 有优化,而目前我们的Paimon 基于ORC ,Paimon读取 Parquet有优化,最近会使用Parquet进行测试。
如果是千万 或者 百万级的小表或分区,两者几乎没有差距,并且社区正在积极的优化中。Paimon的优势是既能高效的更新数据,又能高效读取,非常全面。
前面有提到 Paimon 支持 FileSystem catalog ,我们在一个 Spring boot + Mybatis 的JAVA WEB 项目中,嵌入 Paimon Catalog API ,支持定时和手动同步元数据信息进MySQL 中,配合前端页面进行数据备注、检索、指标管理等
目前使用批处理任务使用 dbt 通过 flink sql gateway 提交作业
目前Flink sql gateway 支持 yarn session 和 yarn per job 两种部署模式,目前有以下问题
– yarn session 启动需要静态指定JobManger 和 TaskManger 的内存 ,不能根据提交的SQL 做针对性调优,存在稳定性不佳 或 资源利用率不高的问题
– yarn per job 可以在向 sql gateway 提交时通过 set 语法设置各项内存值,但是 per job 已经过时,且存在单点问题容易导致 sql gateway 不稳定。
如上:我们后期会逐步实现 sql gateway 的 Application mode,用于解决以上问题,目前正在进行中
目前我们的流任务,虽然可以通过 dbt 编写sql ,且通过 sql gateway 提交至集群运行 (通过 set ‘execution.runtime-mode’=’streaming’ )
但流任务不同于执行完成即退出的批模式,需要在调度层,兼容流的监控和管理 , 也需要 sql gateway 具有任务查看,任务管理,异常报警等流任务生命周期管理能力
Paimon 支持 Log system + Lake Store 混合存储,在元数据层面统一,可以覆盖数据新鲜度很高的业务场景。
目前我们有大量基于 Kafka + Flink + StarRocks 的实时任务及报表,也存在离线和实时的两条开发链路。未来我们准备利用 Log system 进一步生产解决离线和实时割裂的问题。
以上就是 Apache Paimon 在尘锋的批流一体湖仓实践分享的全部内容,感谢大家阅读到这里。
从今年初开始调研湖存储 (Paimon 、Hudi 、Iceberg ),到选择Paimon ,到如今我们已经生产入湖上百张表 ,覆盖了大量业务。非常感谢 Apache Paimon 社区给予的帮助,并由衷感谢 PPMC 之信老师耐心、快速、细心的解答和指导,帮助我们快速解决每次遇到的问题 。
0.4 版本也即将发布,在这里希望 Paimon 越来越好,也希望之后能够多为 Paimon 贡献自己的一份力量。
Apache Paimon官网:https://paimon.apache.org/
Apache Piamon Github:https://github.com/apache/incubator-paimon
Apache Paimon 钉钉交流群:10880001919
尘锋信息大数据研发工程师,专注于流/批计算 ,目前对大数据存储也充满兴趣和激情
本文转载自代欣雨 Apache Paimon,原文链接:https://mp.weixin.qq.com/s/lbZ3VS317vSXec-nuw85eA。