
概述
随着存储表格式 Apache Hudi、Apache Iceberg 和 Delta Lake 的发展,越来越多的公司正在这些格式的基础上构建其 Lakehouse,以用于许多用例,例如增量摄取。但当数据量增加时,更新插入的速度有时仍然是一个问题。
在存储表中,使用Apache Parquet作为主要文件格式。在本文中我们将讨论如何构建行级二级索引以及在 Apache Parquet 中引入的创新,以加快 Parquet 文件内数据的更新插入速度。我们还将展示基准测试结果,显示速度比 Delta Lake 和 Hudi 中的传统的写入时复制快得多。
动机
高效的表 ACID 更新插入对于当今的 Lakehouse 至关重要。数据保留和变更数据捕获 (CDC) 等重要用例严重依赖它。虽然 Apache Hudi、Apache Iceberg 和 Delta Lake 在这些用例中被广泛采用,但当数据量扩大时,更新插入速度会变慢,特别是对于写入时复制模式。有时缓慢的更新插入会成为耗时和资源消耗的任务,甚至会阻碍按时完成任务。
为了提高 upsert 的速度,我们在具有行级索引的 Apache Parquet 文件中引入了部分写时复制,可以跳过不必要的数据页(Apache Parquet 中的最小存储单元),从而实现高效读写。这里的术语“部分”意味着仅对文件内的相关数据页执行更新插入,但跳过不相关的数据页。一般情况下只需要更新一小部分文件,大部分数据页可以跳过。与 Delta Lake 中的写入时复制相比,我们观察到速度有所提高。
LakeHouse 中的写时复制
在本文中我们使用 Apache Hudi 作为示例,但类似的想法也适用于 Delta Lake 和 Apache Iceberg。Apache Hudi 支持两种类型的 upsert:写时复制和读时合并。通过写时复制,在更新范围内具有记录的所有文件都将被重写为新文件,然后创建新的快照元数据以包含新文件。相比之下读时合并只是添加用于更新的增量文件,然后将其留给读取器进行合并。一些用例(例如“被遗忘权”)通常使用写时复制模式,因为它可以减轻读取压力。
下图显示了更新分区表的一个字段的示例。从逻辑视图来看,用户 ID1 的电子邮件字段被替换为新电子邮件,并且其他字段没有更新。从物理上讲,表数据作为单独的文件存储在磁盘上,并且在大多数情况下,这些文件根据时间或其他分区机制分组为分区。Apache Hudi 使用索引系统来定位每个分区中受影响的文件,然后完全读取它们,更新内存中的电子邮件字段,最后写入磁盘并形成新文件。图中的红色表示被重写的新文件。
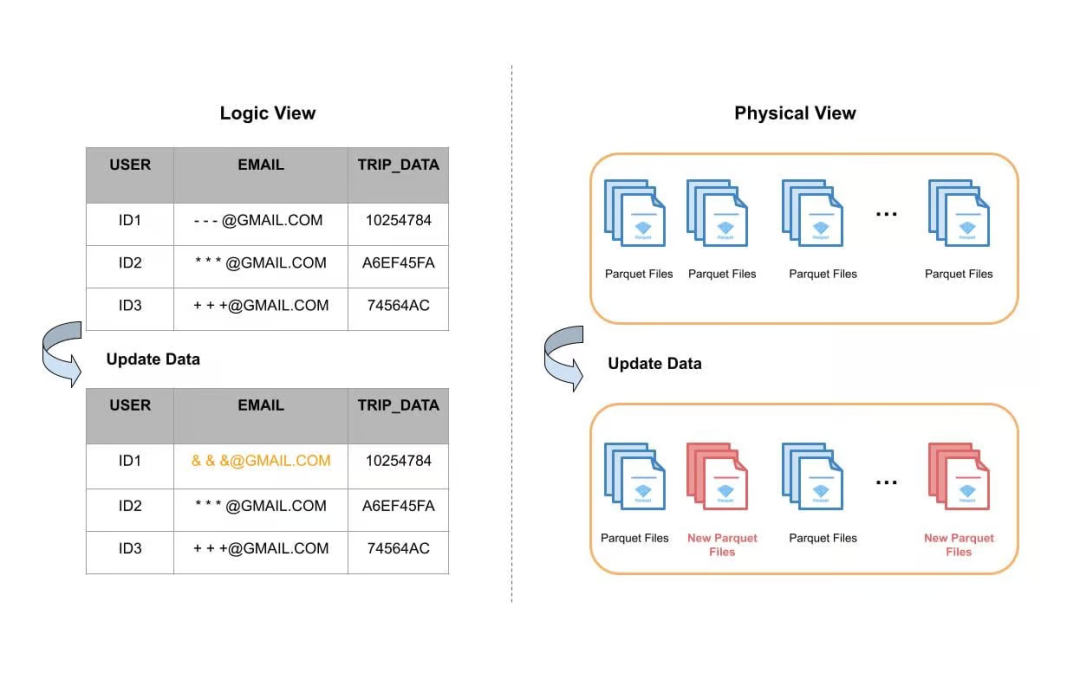

图 1:表更新插入的逻辑和物理文件视图
正如博客“使用 Apache Hudi 在 Uber 构建大规模事务数据湖”中提到的,我们的数据湖中一些表收到的更新分布在 90% 的文件中,导致任何给定的大型数据重写约 100 TB。因此写时复制的速度对于许多用例来说至关重要,缓慢的写时复制不仅会导致作业运行时间更长,还会消耗更多的计算资源。在某些用例中我们看到大量的 vCore 被使用,相当于花费了数百万美元。
引入行级二级索引
在讨论如何改进 Apache Parquet 中的写时复制之前,我们想先介绍一下 Parquet 行级二级索引,我们用它来定位 Parquet 中的数据页,以帮助加速写时复制。
Parquet行级二级索引是在第一次写入Parquet文件时或通过离线读取Parquet文件时构建的。它将记录映射到 [file, row-id] 而不仅仅是 [file]。例如,RECORD_ID可以用作索引键,FILE和Row_ID用于指向文件以及每个文件的偏移量。

图 2:Apache Parquet 的行级索引
在 Apache Parquet 内部,数据被划分为多个行组。每个行组由一个或多个列块组成,这些列块对应于数据集中的一列。然后每个列块的数据以页的形式写入。块由页组成,页是访问单个记录必须完全读取的最小单位。在页面内部,除了编码的词典页面之外,每个字段都附加有值、重复级别和定义级别。
如上图所示,每个索引都指向该记录所在页面内的行。通过行级索引,当收到更新时,我们不仅可以快速定位到哪个文件,还可以定位到哪些数据页需要更新。这将帮助我们跳过所有其他不需要更新的页面,并节省大量计算资源以加快写时复制过程。
Apache Parquet 中的写入时复制
我们引入了一种在 Apache Parquet 中执行写时复制的新方法,以实现 Lakehouse 的快速更新插入。我们仅对 Parquet 文件内的相关数据页执行写时复制更新,但通过直接复制为字节缓冲区而不进行任何更改来跳过不相关的数据页。这减少了更新插入操作期间需要更新的数据量并提高了性能。
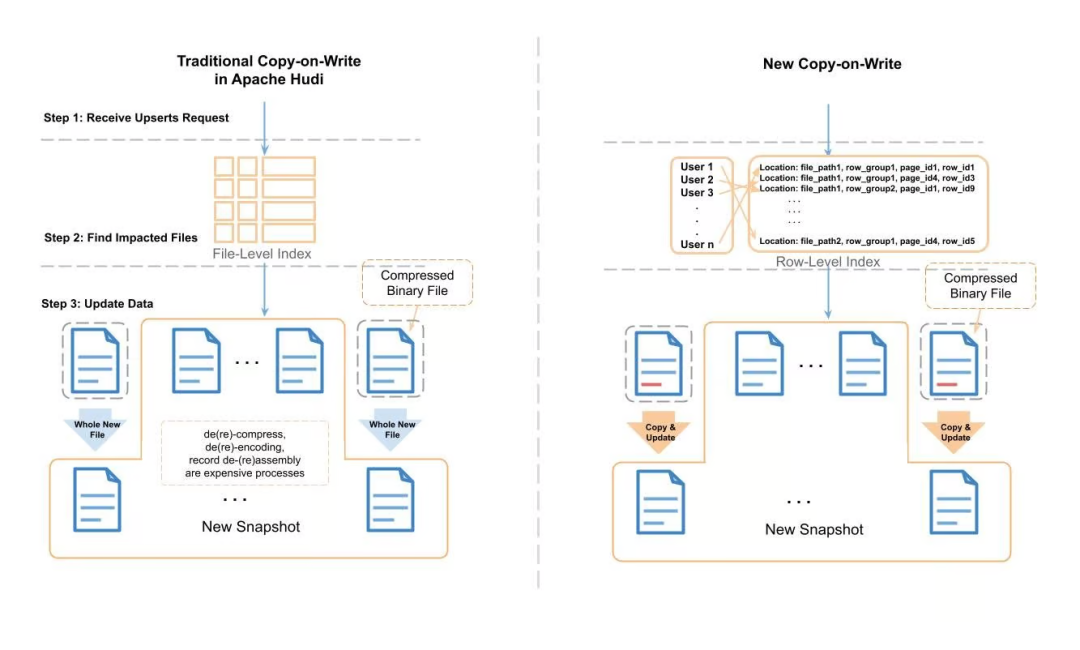
图 3:Apache Hudi 中传统写时复制与新写时复制的比较
我们演示了新的写时复制过程,并将其与传统过程进行比较。在传统的Apache Hudi upsert中,Hudi利用记录索引来定位需要更改的文件,然后将文件记录一条条读取到内存中,然后搜索要更改的记录。应用更改后,它将数据作为一个全新文件写入磁盘。在这个读取-更改-写入过程中,存在一些昂贵的任务(例如,解(重新)压缩、解(重新)编码、具有重复级别、定义级别的记录解(重新)组装等),这些任务会消耗 大量的 CPU 周期和内存。
为了改善这个耗时和资源消耗的过程,我们使用行级索引和 Parquet 元数据来定位需要更新的页。对于那些不在更新范围内的页,我们只是将数据作为字节缓冲区逐字复制到新文件,而无需解(重新)压缩、解(重新)编码或记录解(重新)组装。我们称之为“复制和更新”过程。下图对其进行了更详细的描述。
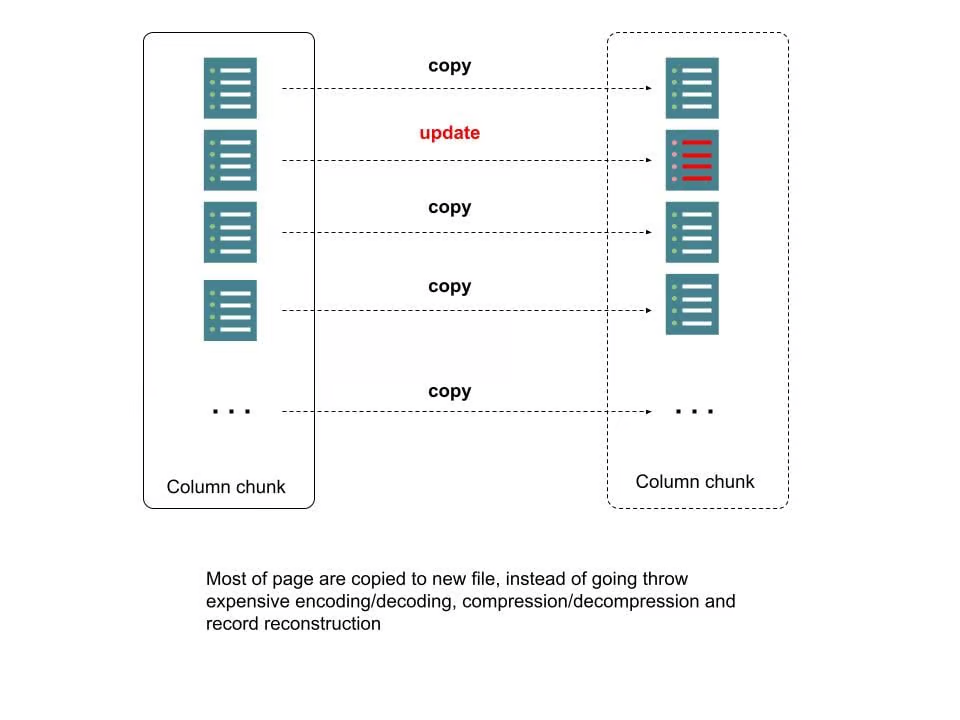
图 4:Parquet 文件中新的写时复制
基准测试结果
我们进行了基准测试,以使用TPC-DS数据比较我们的快速写时复制方法与传统方法(例如 Delta Lake)的性能。
我们使用具有相同 vCore 数量和 Spark 作业内存设置的 TPC-DS 销售数据,以开箱即用的配置进行测试。我们选择了 5% 到 50% 之间的一定比例的数据进行更新,然后比较 Delta Lake 和新的写时复制所消耗的时间。我们认为 50% 作为最大值足以满足实际用例。
测试结果表明新方法可以实现明显更快的速度。当更新数据的百分比时,获得的性能是一致的。
免责声明:DeltaLake 上的基准测试使用默认的开箱即用配置。

图 5:新写时复制与传统 Delta Lake 的基准测试结果
结论
总之高效的 ACID 更新插入对于当今的LakeHouse至关重要。虽然 Apache Hudi、Delta Lake 和 Apache Iceberg 被广泛采用,但更新插入的速度缓慢仍然是一个挑战,特别是当数据量扩大时。为了解决这一挑战,我们在具有行级索引的 Apache Parquet 文件中引入了部分写时复制,这可以有效地跳过不必要的数据页读写。我们已经证明这种方法可以显着提高更新插入的速度。我们的方法使公司能够高效地执行数据删除和 CDC,以及依赖 LakeHouse 中高效表更新插入的其他重要用例。
未来工作
我们计划将行级索引和快速写时复制功能集成到 Apache Hudi,Uber 的 LakeHouse 就是在 Apache Hudi 上构建。我们将看到这种集成将如何提高 Apache Hudi 的性能并帮助我们的客户解决增量摄取等问题。敬请关注!
本文转载自Uber ApacheHudi,原文链接:https://mp.weixin.qq.com/s/lCkGL6uCFF-3dPA7FPLS3Q。