
Part1 介绍
现代GPU集群旨在支持多个租户(multi-tenancy) 的分布式深度学习任务,我们发现每个租户对资源的需求可能随着时间而动态改变。但是,现有的GPU调度器未能充分考虑租户和工作之间的公平性,从而导致租户之间的资源分配不平衡。为了解决这个问题,我们提出一种保障多租户公平性并提升深度学习任务性能的调度器。首先,我们引入了一种长期GPU时间公平性指标,它考虑资源分配的时间和空间因素,评估当前的资源分配是否保障了租户和任务的公平性。其次,我们设计了一个GPU调度器,ASTRAEA,保障了租户和工作之间资源需求的公平。
Part2 多租户的资源动态需求


一般情况下,GPU集群会分配划分虚拟集群(Virtual Cluster)给各个租户, 而不同租户对资源的需求会随着时间动态变化,而如今的资源划分往往是静态的,这样的静态划分效率低下,不能充分利用集群资源,而且也会导致不同租户之间的资源使用的不公平,如上图06月21日,租户B对资源的需求相对角度,而租户A的资源需求达到100%,更合适的资源分配方式是将租户B的部分资源分配给租户A从而达到资源利用效率最大化。
Part3 长期公平性度量
ASTRAEA 提出了长期公平性度量(Long-Term GPU-Time Fairness)衡量每个任务/租户的资源是否公平。最朴素的公平性定义是每个用户/租户均享整个集群的资源,但是由于GPU资源的不可分的性质,ASTRAEA考虑了时序上的资源使用,通过对每个任务/租户历史资源使用情况在时序上积分获得每个任务的GPU-Time使用情况,尽可能保障不同任务/租户的GPU-Time相等。
Part4 ASTRAEA系统框架

ASTRAEA采用两阶段调度策略决定每个任务的资源分配。(1) 不同租户提交相应的任务进入任务等待队列。(2) 调度器根据不同租户的长期公平性度量,选择获得资源最小的租户,旨在提高它的未来的GPU-Time。(3) 调度器选择该租户等待队列里的任务,仍然根据不同任务的长期公平性度量,选择获得资源最小的任务。(4)分配资源给相应的任务。(5)如果某些任务结束,释放资源,并提醒调度器进行资源调度。
Part5 实验结果
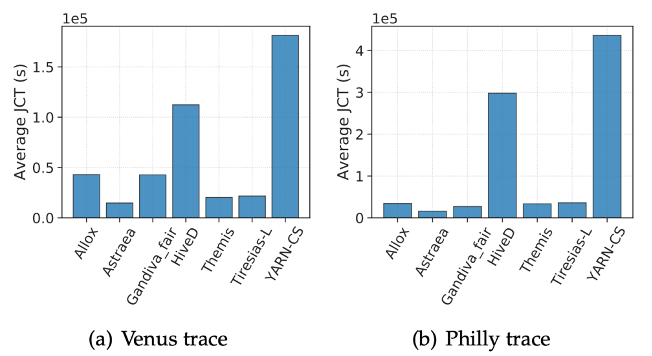
实验数据集:Venus: SenseTime GPU集群trace, Philly: Microsoft GPU集群trace
实验metric: Average JCT: 平均任务完成时间
Part6 总结
我们提出了一项关于GPU集群中深度学习任务的资源分配公平性的调度器。我们对某AI独角兽中的一个生产集群的任务进行了定量分析,揭示了保障深度学习任务调度的公平的重要性。我们提出了一个新的实用指标长期公平性指标,以衡量深度学习作业和不同租户的公平性,并采用了两阶段调度算法解决了现有集群资源使用不公平的问题。
本文转载自Gao Wei@南洋理工CAP组,原文链接:https://mp.weixin.qq.com/s/d8RPB7zMKqPE9EHKiDlkQw。