
分享嘉宾:李阳 京东 架构师
编辑整理:史士博 百度
出品平台:DataFunTalk
导读:本文分享关于 Doris 的实际使用情况,主要是物化视图、索引的典型应用案例,以及在使用 Doris 过程中的一些心得。
本节主要介绍物化视图相关的概念和实际使用案例。
1. 物化视图基本概念


先介绍物化视图的基本概念,物化视图是指在 Doris 中将一些预计算好的数据存储在 Doris 中的一个特殊表(Doris 0.12版本之前是有 rollup 的概念,0.12 版本之后已经统一使用物化视图),这里涉及到两个知识点:
-
预计算:这里会用一些聚合函数相关的功能把数据先计算好
-
特殊表:所谓的特殊表是指物化视图在 Doris 中它是一张实际存在的物理表,它要占用实际的物理存储空间
物化视图的使用场景:
① 当我们既需要明细查询,又需要固定维度查询的场景时。比如用户订单底表我们有明细数据查询的需求,同时还需要对品类、商铺两个固定维度进行聚合查询。
② 仅涉及表中很小一部分列或者行的查询场景。
-
一部分行:有时数据是面向商家或者某部分品类的运营人员,他只需要查属于自己品类的数据
-
一部分列:对于有些大宽表,如订单表,单张表涉及上百列,但是有的分析可能只跟部分维度属性和下单金额有关系,对于更多的维度属性并不会用到,这时基本只会用到其中很小的一部分列
③ 我们在做查询时,经常用到聚合,比如求和、去重,这些比较耗时的聚合查询也可以用到物化视图。
④ 需要匹配不同的前缀索引,后面会具体介绍物化视图结合前缀索引在查询速度上做优化。
物化视图的优势是什么?
① 给我们带来查询速度上显著提升,因为现在绝大部分的场景都是即席查询,需要很快返回结果。
② 数据一致性的保障,就是底表和物化视图的数据保持一致。在京东 OLAP 建设中使用了很多个引擎,有的引擎它的物化视图是异步写入,这样经常给用户带来疑问,数据导入操作已经完成,而且查询命中了物化视图,但是查出的数据不是最新的状态,就是因为这个 OLAP 引擎的视图是一个异步操作。但是在 Doris 里,物化视图和底表数据是一致的,就是对于物化视图和底表,数据在写入时是一个事务,是同步操作,可以保证一致性。
图中右侧部分也列了物化视图支持的聚合函数。有常用的 Sum/Min/Max/Count,还有针对大数据量 PV/UV 分析场景或者精确去重场景使用的 bitmap_union,另外还支持 HLL_UNION。
2. 物化视图使用介绍

可能有的同学用过物化视图,比如说 Oracle 也有类似功能,这里我们介绍下 Doris 的物化视图的使用场景,其实跟大家在其他引擎上使用物化视图的用法基本上是差不多的。如图中上侧示例是创建一个物化视图我们需要做的事情:首先以关键词 CREATE 开始,后面是我们给这个视图的命名( MV name),然后是查询语句块 query(Doris 会根据查询语句将返回的结果放到物化视图里),最后还可以设置一些属性 properties 。其中 Query 语句示例如图中所示左中部分 Select 语句,它跟我们常见的查询语句是一样的语法 ,查询语句可以是一个分组聚合的查询(Group by);还可以指定排序列排序方式(ORDER BY),这样的话查询结果就会按照我们指定的顺序物化到特殊表(物化视图)里。
下面介绍下物化视图的一些使用场景。现在有这么一个表(如图中左下部分所示),表名是 duplicate_table ,它有四列 K1,K2,K3,K4 且 Column 类型都是 Key ,对于这个表不同的场景使用的物化视图的方式分别为:
场景一:部分列分组聚合。如下语句就是创建一个以 K1,K2 分组, K3 列为 SUM 聚合的物化视图,这就是典型的前面介绍的物化视图使用场景中的“仅涉及表中很小一部分列或者行的查询场景”。
CREATE MATERIALIZED VIEW k1_k2_sumk3 as select k1, k2, sum(k3) from duplicate_table group by k1, k2;场景二:数据去重。我们在某些场景中经常用到去重的功能,比如说数据导入过程发生了异常从而重复导入的场景,具体如从 Kafka 之类组件往 Doirs 导数据过程中可能会发生一些异常,有时候用户没有记录偏移量,只能大概知道时间点,然后他从这个时间点往前一段时间的偏移量重新导数,这个情况下就可能发生数据重复,此时创建一个类似于下面这样的去重物化视图就可以解决数据重复的问题,这个物化视图相当于直接使用 group by 语句将原来的数据做了一个去重,查询的时候命中的是去重后的物化视图。
CREATE MATERIALIZED VIEW deduplicate as select k1, k2, k3, k4 from duplicate_table group by k1, k2, k3, k4;接下来介绍 Doris 索引的基础原理和使用场景。
1. 原理介绍

我们知道 Doris 目前有三种数据模型 Aggregate、Uniq、Duplicate ,底层的引擎都是按照 Aggregate Key、Uniq Key、Duplicate Key 指定的列进行排序存储( Uniq 就是使用 Aggregate 实现的,它是 Aggregate 的一种特例)。实际上 Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中,该结构是一种有序的数据结构,以排序列作为条件进行查找,本身会非常的高效;然后 Doris 又结合有序这个特点来设计了内置的索引:前缀索引。所以 Doris 前缀索引主要就是在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。前缀索引的特点是:
-
一行数据的前 36 个字节作为这行数据的前缀索引。36 字节是根据实际的测试得到的结果,太大的话对性能影响比较明显, 36 字节是比较能覆盖绝大部分场景。
当遇到 VARCHAR 类型时,前缀索引会直接截断。
我们举例说明:如图右侧有两张表,第一张表它有五个字段 user_id、age、message、max_dwell_time、min_dwell_time 它的前缀索引按照36字节来算是 user_id(8Byte) + age(4Bytes) + message(prefix 24 Bytes) ,其中 message 本来有 100 字节会按照 24 字节来截断;第二张表的第一个字段是 user_name 类型是 varchar(20),因为是字符串类型, 即使没有达到 36 个字节,遇到 VARCHAR 也是直接截断,不再往后继续,所以它的前缀索引是 user_name(20 Bytes)
使用效果:
如下两条查询,使用 user_id 和 age 作为条件查询,因为命中我们上面表的前缀索引,它的查询效率会远高于只使用 age 作为查询条件的查询。
SELECT * FROM table WHERE user_id=1829239 and age=20;SELECT * FROM table WHERE age=20;
实际上在我们使用的时候经常会有因为没有命中前缀索引导致查询效率较低的情况,如优惠券或者订单明细数据的查询场景中,经常会碰到一些用户写的 Sql 没命中前缀索引,效率比较低,在量比较大的时候(比如说亿级数据的时候)可能会花好几秒的时间才能产生出结果。
接下来我们通过实际案例来看,如何结合上面介绍的物化视图和索引来优化我们的性能。
1. 场景一:订单分析
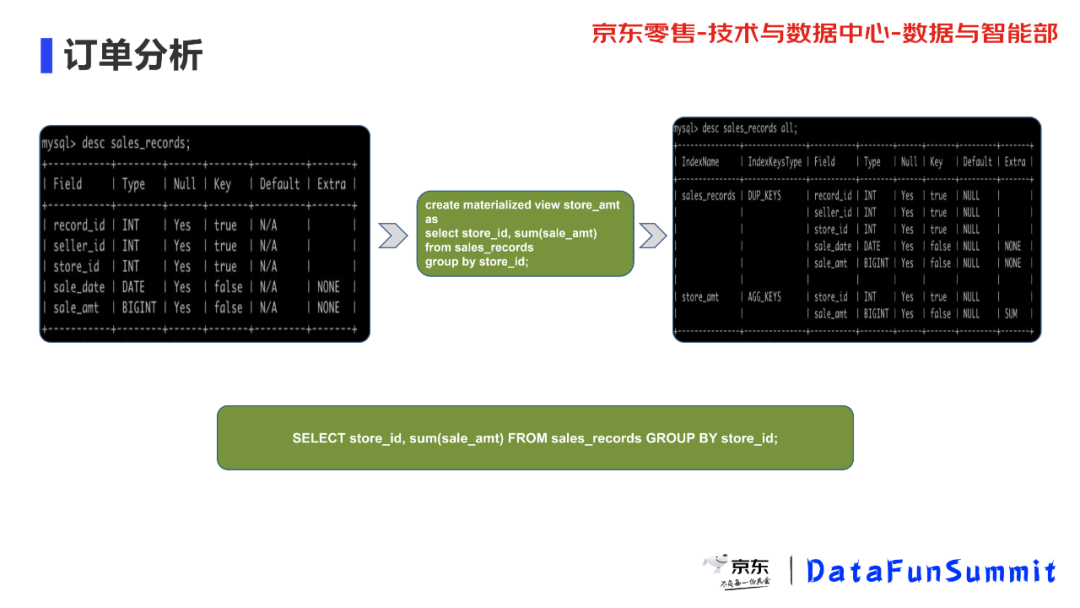
比如说我们做一个订单分析,假设我们左边那个表是一个订单表,有五个字段(订单ID、售卖员ID、仓储ID、售卖日期、售卖金额),然后我们创建一个对仓储ID分组、售卖金额求和的物化视图。物化视图创建完成后,我们可以通过 desc table_name all 的方式来查看,如图中所示我们可以看到已经新生成了有两列组成的 indexName :store_amt ,这就是我们刚刚创建的物化视图(通过这个命令查看把表和物化视图统一叫作 indexName)。
当我们查询每个仓储下的售卖金额时就会命中这个物化视图。一般情况下每天的订单量是远远高于公司的仓储量,比如公司每天的订单量可能有一亿个,但是仓储一般来说不会特别多,几千个仓储已经挺多的了,这样的话命中物化视图后扫描的数据量是有几个数量级的下降,基本上是毫秒级别,如果没有物化视图每次都是使用聚合的方式查询,可能就需要好几秒钟,这有一个很明显的一个性能提升。
2. 场景二:PV&UV
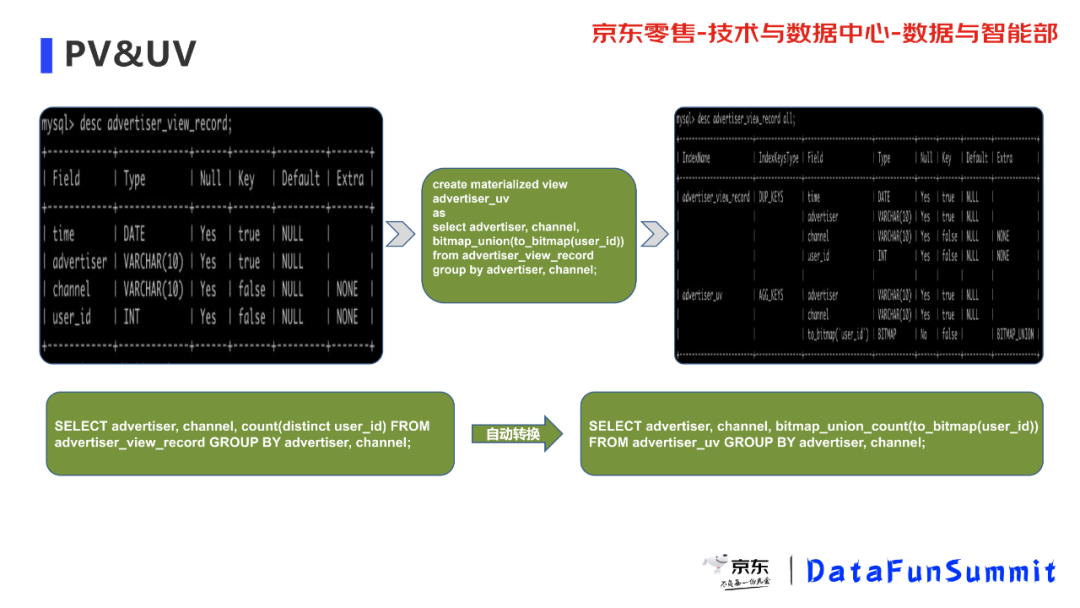
第二个场景就是典型的 PV/UV 场景,这在广告领域是很常见的。比如我们有一张广告记录表,有四个字段(时间,广告商,渠道,用户ID),然后我们创建一个可以创建一个根据广告和渠道分组,对 user_id 进行精确去重的物化视图,创建之后我们可以使用同样的方式查看。
当物化视图表创建完成后,查询广告 UV 时,Doris 就会自动从刚才创建好的物化视图 advertiser_uv 中查询数据。比如原始的查询语句如下:
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;在命中物化视图后,实际的查询会转化为:
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id)) FROM advertiser_uv GROUP BY advertiser, channel;这样就会命中我们刚刚创建的那个物化视图。按我们的实际场景来看的话,这样的查询时间也会有一个数量级的减少,是一个很大效率提升。
3. 场景三:明细查询
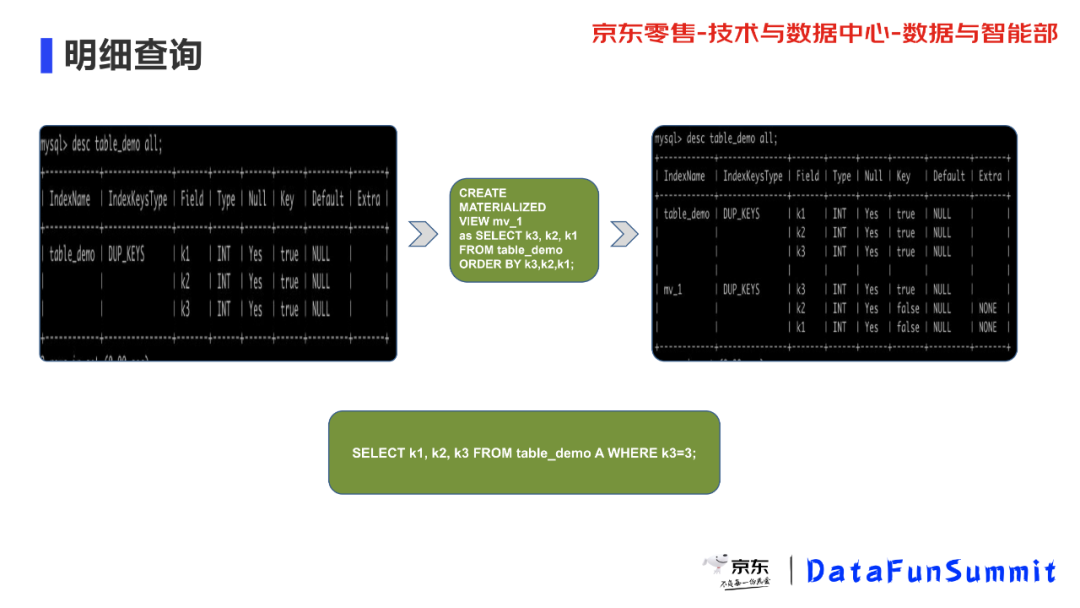
如说我们现在有三个列,用户的原始表有 (k1, k2, k3) 三列,按照我们刚才讲的前缀索引,它因三个都是 int 的,所以前缀索引列为 k1, k2, k3。在实际查询中,比如从一亿个订单的中查询数据,有时候是根据订单ID、商铺ID和用户ID(k1, k2, k3)来查可以命中前缀索引,但是有时候我只以用户ID(假设是k3)作为开头来查的话,就没办法命中前缀索引,查询语句如下。
select k1, k2, k3 from table A where k3=3;所以我们创建了一个视图,如图所示我们只调整了列的顺序,把 k3 调到了第一列,这样当我只以 k3 作为查询条件时就可以命中这个物化视图的前缀索引,通过创建这样的物化视图可以很大提升我们的查询效率,所以基本上就是几十毫秒或者十毫秒级别就能查出来的数据。
CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;当然物化视图也是有代价的,我们创建的物化视图或者索引会增加额外的存储成本。现在绝大部分场景下,我们的存储是够的,一般磁盘空间都比较大,但是需要的是查询要快,CPU 的算力不是很多,而且 CPU 相比磁盘更贵,综合考虑增加这些存储成本能获得更高的收益。
最后分享我们在实际使用场景中的一些心得:
1. 数据更新场景
控制写入任务频率:在订单系统中,用户完成一个订单,订单的状态基本上会发生大约二十次的变迁,在这种高频率数据更新情况下(同一个Key 的数据会不停的写入),这个时候我们需要控制任务的一个写入频率,因为 OLAP 和 OLTP 还是不一样的,如果写入频率过高的话,后台会不停的做 compaction,如果 compaction 数量过多,一是影响 IO,另外 compaction 过程中需要做计算和合并数据,对查询性能也有一定的影响。
调整 compaction 参数:比如在特别巨大的流量场景下,我们会放大阈值,避免频繁 compaction ,从而减少合并数据操作,否则会导致 IO 、CPU 使用率都会比较高。
2. 高吞吐的场景
控制物化视图数量:像我们碰到的,比如说搜索或者推荐这种场景每秒钟就能写几百万条数据进来,这个情况下我们要控制物化视图数量。虽然物化视图能带来一些好处,但是因为物化视图是占用实际的物理存储空间而且和表是同步更新的,因此会影响我们的写入效率,一个表有两个物化视图还是三个物化视图,写入表的吞吐速度是不一样的。在特别高吞吐场景下,这会影响写入速度,而且物化视图特别多的话会严重影响 IO。
调整 tablet 写入速度:主要是说我们现在大部分用到了 MME 相关的一些磁盘,原来我们设置的十兆或者二十兆的速度是没法满足高吞吐这个场景的,我们可以适当调整一下调整到到三十兆或者四兆,这样能提高它的一个吞吐。
磁盘选择:尽量还是要选择性能比较好的磁盘,我们使用的是 EXT 文件系统,文件系统本身有一个写屏障的保障,在使用 SCD 的时候对写入量有很大的影响,然后在SSD上面是没有这个问题的。
3. 是高时效性场景
任务写入并发、任务写入间隔:我们有一个业务场景是实时查看客服的接单量和投诉走势,比如说我们在大促的时候,我们要实时监控是不是有群诉的现象,要及时进行解决。以前这块儿业务都是 T+1 或者小时级别,是比较慢的,后来使用 Doris 改为实时提高了时效性。使用过程中也发现一些问题,就是我们的数据更新频率和时效性比较慢,后面排查中发现是因为我们设置的写入并发比较低,这种时候我们是适当的调小写入间隔以及调大写入并发来解决,但是这个也会带来一些其他的问题,比如频繁的写入会产生过多小文件,但是客服这个场景的数据量不会特别大,所以我们要结合实际场景来做一些权衡。
4. 高 QPS 场景
使用 rollup(物化视图):我们风控场景对查询 QPS 要求非常高,且查询场景包括明细查询和聚合查询,然后就会利用到我们刚才说的物化视图(rollup 是 Doris 早期的叫法)来提升查询速度。就刚才说的物化视图在数据量上是有几个量级减少的。
增加 observer:第二是我们可以适当的增加一些 observer 节点,observer 仅从 leader 节点进行元数据同步,不参与选举。可以横向扩展以提供元数据的读服务。
Q:建设物化视图过程中换个维度查询就要新建一个物化视图,会导致物化视图的膨胀或者爆炸吗?
A:前面有介绍到我们是需要控制一下物化视图的数量的,如果说每一个查询都创建物化视图的话肯定会发生膨胀甚至爆炸,所以我们尽量是让一个物化视图能覆盖到多个场景。比如前面的例子中某个物化视图 k1,k2 是前缀索引,使用 k1 作为查询条件和使用 k1,k2 两列作为查询条件都能命中的。
Q:Doris 是否批流一体场景,是否可以同时用于实时数仓和离线数仓?
Doris 准确来说微批的概念,如果微批特别小的话就接近于流,对于 Doris 来说每次的写数据都是一个事务,如果每一条数据进来都实时的往里面写,Doris 是不能够承受的。所以我们是在实际使用中是做一些权衡的,没法做到真正流式的那种用法,要求写了一条数据马上就能查到,这是不行的。在我们的使用场景中设置十秒钟或者五秒钟一次导入,更小的时间对系统来说是会有抖动的。
Q:Doris 的性能表现是怎么样 ?
A:大概介绍一下,我们内部使用了多个引擎,包括 Kylin、Druid、ClickHouse、Doris这些,大概说下 Doris 的性能表现:查询方面,整体来说性能上满足中小型场景,特别的场景就要做一些优化:
-
单表查询:在使用上述的优化情况下比 CK 差一些,但是差异不大。
-
多表表 JOIN :Doris 比 CK 有优势。
写入方面:吞吐量要注意控制一下频率和批次,我们集群几百台机器,一天好几千亿的数据是没有问题的。
Q:Doris 本地 Join(Colocation Join)在使用上有什么注意的吗?
A:一是建模型的时候,要根据业务情况把数据打散,尽量让它分布比较均匀,这样才能达到比较好的 join 效果;第二要注意的就是在集群做扩缩容的时候会影响 Colocation Join 性能,执行较慢。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/4988/