
前言
数据被列为了与物质、土地、人力资源同样重要的基础生产要素,一个以数据驱动经济社会发展的时代悄然来临[1]。数据的价值在于流动与融合,然而近年来由于数据滥用和泄露造成的数据安全问题比比皆是,这进一步威胁到了个人权益、企业利益及国家安全。基于此背景,国家在2021年陆续颁布了《中华人民共和国数据安全法》和《中华人民共和国个人信息保护法》[2],力求最大限度保证数据的规范使用和数据价值的安全释放。伴随着政策法规的颁布,数据安全与隐私保护的相关技术逐渐走进人们的视野。其中,数据脱敏就是一项重要的数据安全防护手段,它可以有效地减少敏感数据在采集、传输、使用等环节中的暴露,进而降低敏感数据泄露的风险。但是目前常见的数据脱敏技术存在着一定的局限性。一方面,现有的脱敏技术对敏感数据的保护性不足,恶意攻击者可以结合相关背景信息,推导出敏感数据,引发隐私泄露的风险;另一方面,现有脱敏技术通常会改变原始数据的数据结构,在一定程度上影响了数据的可用性,折损了脱敏后数据的使用价值。
在近年数据隐私保护的大趋势下,隐私计算技术热度逐渐攀升,它可以在原始数据不可见的前提下,依然能完成其数据价值的释放,实现数据的“可用不可见”。这个特质也与数据脱敏的目的高度一致,即在保护敏感数据安全的前提下,实现数据价值合法合规的流通。因此,基于当前数据脱敏技术存在的局限性,本文提出了应用隐私计算的底层密码学算法、协议来进行数据脱敏的一些思考和应用方案,以期满足当下对数据安全越来越高的合规要求和对数据资产价值全面释放的迫切需要。
脱敏技术现状综述
2.1常见的数据脱敏技术
数据脱敏是指从原始环境向目标环境进行敏感数据交换时,通过一定的方法消除原始环境中数据的敏感性,并保留目标环境业务所需的数据特性或内容的数据处理过程[3]。数据脱敏要确保脱敏过程的代价可控,在合规的前提下,得到满足业务需要的数据结果。在实施数据脱敏时,往往需要平衡脱敏后数据或数据集的安全性和可用性。常见的数据脱敏方法,集中在泛化、抑制、扰乱和有损四方面[4]。泛化和抑制都是通过对数据实施取整、归类、截断、掩码屏蔽等方式降低数据的精度实现的脱敏,脱敏后数据在一定程度上保留了原始数据所携带的非敏感信息。扰乱是指通过对数据中的敏感信息使用重排、加密、散列等方式,破坏其结构,脱敏后数据的敏感信息被完全隐藏,因此极难推断出原始数据所携带的敏感信息。有损是指限制对数据集的敏感行数和列数向目标环境的交换来保护敏感数据不外泄。
2.2 数据脱敏技术现存问题
1. 对于敏感数据的保护不足
现有的数据脱敏技术往往是对样本标识实施脱敏,从而保证样本不被识别,达到保护个体隐私的目的。但是攻击者可以通过结合相关背景知识与脱敏的数据样本融合推导,得出数据样本的原始标识,导致样本隐私的泄露。例如,在常用的脱敏操作中,我们对用户的标识(如姓名、身份证号、电话号码等)进行脱敏,其属性类数据(如收入、贷款额度等)保留原始数据形态以参与统计分析。而具有恶意的数据使用者往往可以借助不同的数据表之间的关联关系,窥探或者反推出某个个体的标识,从而获取个体隐私。随着信息技术和互联网的进步,每个人获取数据的渠道五花八门,能够更容易地洞悉出数据与数据之间的联系,这也进一步降低了背景知识攻击的门槛。因此,如何更好地防范脱敏后的数据标识被反推造成的隐私泄露,是当前数据脱敏技术需要关注的重点。
2. 对数据的使用价值造成损失
在数据挖掘算法、模型的加持下,数据资产的价值在业务场景赋能的建设过程中越发显现。数据价值的充分挖掘需要将样本多样化的数据特征作为原料,投入到计算平台进行融合计算或联合分析。然而根据合规要求,样本数据往往需要经过脱敏后参与计算。根据脱敏的方式不同,脱敏后的数据通常会损失精度,或者根本无法参与计算,那么数据资产的价值也会随之折损。例如在统计贷款额度时,如果对相关数值使用了泛化的脱敏方式,其统计结果将会严重损失精度,降低业务分析的价值;再比如,对某些数值型变量经过扰乱脱敏后完全无法参与计算。因此现有的数据脱敏技术对数据要素的价值有所“浪费”,在当下鼓励数据融合、促进数据交易、释放数据价值的大背景下,这种“浪费”显然是需要改进的。
隐私计算技术概述
根据大数据联合国全球工作组(Bigdata UN Global Working Group)的定义,隐私计算是在处理和分析计算数据的过程中能保持数据不透明、不泄露、无法被计算方以及其他非授权方获取的一类技术的范畴和集合[5]。目前隐私计算技术的实现主要依赖于差分隐私、同态加密、不经意传输协议等密码算法和协议。本文认为,这些密码技术或安全协议被应用于数据脱敏时,既可以提升数据脱敏的安全性,增强对敏感数据的保护,又能够保证数据价值的无损应用,从而兼顾数据的安全性和可用性,推动数据要素的价值最大化合规释放。
下面本文将针对差分隐私、同态加密和不经意传输协议三种技术和其在数据脱敏方向应用的相关思考进行介绍。
3.1差分隐私
差分隐私是2006年由DWORK提出的一种新型的隐私保护机制[6]。通俗来讲,差分隐私机制保证了一个数据集的每个个体都不被泄露,但数据集整体的统计学信息却可以被了解(可能存在一定误差)。其中心思想是依据数据集的某种统计特征,针对性地引入可控的噪声,对原始数据进行混淆,可以在保留原始数据集统计特征的基础上实现对个人敏感信息的脱敏。差分隐私可分为中心化差分隐私和本地化差分隐私两种类型。在数据集或查询结果对外进行发布时,可以使用中心化差分隐私机制对发布结果加入噪声,从而保护敏感信息不被泄露;当服务端从用户端采集信息时使,可以使用本地化差分隐私机制对数据加入噪声,使服务器仅能获得加入噪音的信息。
3.2同态加密
同态加密算法允许用户直接对密文进行特定的代数运算,根据运算的规则定义不同,又分为半同态和全同态加密算法。具体来说,使用同一个同态加密算法得到的两个密文,可以在不解密的情况下,进行加法或乘法的操作,其结果与直接在明文状态下进行加法或乘法之后再进行加密的结果是相同的。同态加密的优势在于用户在数据加密的情形下仍能对特定的加密数据进行分析、检索、运算,并且正确的加密数据仍然能得到正确的解密结果,这大大提高了数据处理的效率,拓展了数据使用场景,保证了数据安全传输。
3.3不经意传输协议
不经意传输协议(OT协议)是发送和接受消息的双方以一种选择模糊化的方式传送消息的协议,发送者无法得知接收者收到了那条消息,接收者也无法知道其他不相关的消息。此协议可以应用在匿踪查询等场景中。例如,甲想购买商品A,希望在购物网站上查询商品A的价格。但是甲非常在意自己的隐私,不希望向购物网站泄露自己想要购买商品A的意愿。然而购物网站想要实现将商品A的查询结果返回给甲,就必然会了解到“甲正在考虑购买商品A”这一信息。不经意传输协议可以很好的规避这类问题。通过不经意传输协议,购物网站把他拥有的N个商品价格使用某种双方协商同意的加密算法和参数进行加密,然后发送给甲,甲只能从密文中解密出A的资料,而无法解密出其他N-1份资料。根据不经意传输协议的定义,其实现数据脱敏的方式,主要是使得数据在从原始环境向目标环境进行数据交换时,其中具有敏感性的数据不被目标环境所获取,进而达到保护个人隐私泄露的目的。
隐私计算技术在数据脱敏中的应用
4.1 加强敏感数据保护
4.1.1 基于本地差分隐私的数据收集脱敏
《中华人民共和国个人信息保护法》中规定,收集个人数据需要获得个体授权,并且应当限于处理目的的最小范围。然而现实情况下,即便是满足了上述两个条件,由于传统脱敏技术对于敏感数据被反推的情况保护不充分,收集个人数据的服务器依然存在推导出用户敏感信息的可能性。针对此情况,可以基于本地化差分隐私进行数据脱敏,再进行收集。目前已有多个研究机构及企业提出了不同的利用本地化差分隐私技术的实现数据收集阶段的脱敏方案,如苹果、谷歌、三星等,其中以苹果的方案较为有代表性。苹果在其iPhone、Mac等设备上进行系统和应用信息采集的时候,均应用了本地化差分隐私技术来对用户敏感信息进行脱敏[7]。其中一个典型应用场景,是对用户手机键盘上输入的单词及emoji表情,进行统计分析以得到流行的emoji表情、单词或新的网络用语,用于改善产品体验。


基于本地差分隐私技术脱敏方案,可以设计成上图所示机制,用户数据在被传输到收集方服务器之前,在本地终端根据收集方预设的差分隐私机制进行预处理,再将处理后的脱敏数据传输至数据方服务器,降低服务器对用户敏感数据的恶意窥探,减少隐私泄露的可能性。
4.1.2 基于不经意传输协议的查询意愿脱敏
用户在使用数据查询服务时,因为查询条件可以反映出用户的隐私信息,所以往往不希望透露自己的查询条件给被查询方。例如,用户在应用软件上查询某支股票的相关信息时,可能会泄露自己对于该支股票或该股票所处行业的兴趣,从而透露出自己的投资偏好。用户的投资偏好数据很可能被被查询方所采集,脱敏后做行业或市场分析之用。传统脱敏技术仅能够在采集用户的请求信息后,对其所采集的意愿数据予以脱敏处理,而基于不经意传输协议的机制进行,则使得查询方从一开始就避免了自己的查询条件暴露,免去了后续因脱敏不完全而可能带来的隐私泄露的安全隐患。借助不经意传输协议,用户无需担心自己的查询意愿被泄露,也能够从被查询方获得查询结果。
4.2 提高敏感数据价值
4.2.1 基于同态加密的云计算数据脱敏
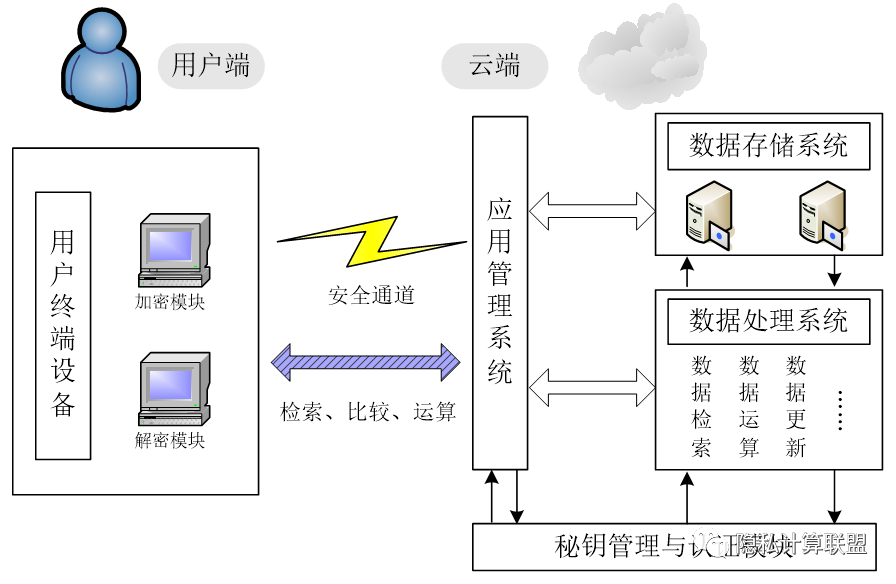
为了更好借助云端强大的算力资源进行计算,用户可以将数据在合规脱敏后上传到云端完成计算,直接获取云端返回的计算结果。同态加密算法的引入,使数据在其价值无损的前提下完成了脱敏,再将密文在云端完成计算,并返回结果。过程中云端仅拥有数据的同态加密后的密文,因此其安全性和计算结果的精确性有所保证。在云计算中利用同态加密的脱敏方案可如下图所示,用户和云端通过安全通道进行交互,完成用户的检索、比较、运算等任务。用户将加密后的密文数据传输至云端后,云端进行数据存储和数据处理,再将运算结果传输给用户,用户使用密钥解密即可。密钥全程由用户保存,云端不存储用户密钥。基于此方案,用户依然可以获得想要的计算结果而不用担心传输至云端的数据被泄露。
4.2.2 基于同态加密的数据恢复脱敏
同态加密的特性,决定了其加密后的密文数据可以进行计算而不影响其准确性,因此在一些数据分析、开发、测试的场景中,可以用同态加密来进行从生产环境向非生产环境进行数据恢复脱敏时的脱敏,防止内部人员使用背景知识攻击等手段获取用户的敏感数据。具体方案如下,在数据从生产环境恢复之前,先对其可参与计算的数值类数据进行同态加密,秘钥存放于生产环境中并将秘钥权限赋予生产环境的业务人员手中,而对个人标识类的数据则采用传统的数据脱敏;然后将已脱敏数据恢复至指定非生产环境,内部开发人员根据需求对数据进行加工、计算等操作;接着由开发人员将计算密文计算结果传输至生产环境,由业务人员解密结果后进行核对。这种方案将原始明文数据的访问权限进行了严格管控,在保证其不被攻击泄露的同时,依然可以通过分析、计算、加工释放其数据价值。
趋势和展望
随着《数据安全法》《个人信息保护法》等法律的颁布,国家对于个人信息的隐私保护要求逐渐严格,数据脱敏技术作为数据保护的一道关键防线,其相关研究必定会成为未来数据隐私保护方向的热点之一。而隐私计算作为一项可以调和个人隐私泄露的高风险与数据价值的充分挖掘之间的矛盾的技术,更是有充足的空间大展拳脚。然而,隐私计算技术在数据脱敏方面想要真正落地应用,带来效果的提升,还需要很多问题需要考虑。
一方面,隐私计算技术的复杂度远高于传统脱敏技术,因此使用隐私计算进行数据脱敏的方案设计难度较高。同时,隐私计算技术的实施方案与具体场景高度耦合,需要针对不同的场景做个性化配置,无法以一种通用的形态适配丰富多样的场景,因此较难集成在现有的数据脱敏技术平台提供服务。如何将隐私计算在数据脱敏中的应用形成易于实施、通用性高的用户友好型方案在未来将会是一个有待研究的课题。
另一方面,使用隐私计算进行数据脱敏相关的研究课题、落地场景十分匮乏,如何使用隐私计算来对数据脱敏的相关标准建设也尚不完善,行业内对于如何使用隐私计算技术进行数据脱敏、如何评价隐私计算技术应用在数据脱敏中的效果等方面没有形成共识。隐私计算这一新技术的在数据脱敏中的应用落地缺乏配套的实施指引和测评体系,难以进行验证和推广。
综上所述,行业内还需要加强数据脱敏平台或工具的研发,以及其配套的应用场景的适配性研究,加速工具的落地应用。对于隐私计算技术性能效率的提高以及通用性方案设计的研究可以由相关企业牵头提供场景,联合高校和科研机构进行进一步的探索,通过“产学研”的形式优化隐私计算的性能、表现、可行性。同时,管理层或监管部门也需要加速相关流程和管理制度的研究和落地,以推动数据脱敏在数据安全和个人隐私保护中的应用,保证数据要素安全、高效流转。
参考文献
[1] 于施洋,王建冬,郭巧敏.我国构建数据新型要素市场体系面临的挑战与对策[J].电子政务,2020(03):2-12.DOI:10.16582/j.cnki.dzzw.2020.03.001.
[2] 魏博言,强锋,安文森.隐私计算技术在开放银行数据合规中的应用与面临的挑战[J].现代金融导刊,2021(12):15-20.
[3] DB 52/T 1126—201, 政府数据 数据脱敏工作指南 [S].
[4] 中国信通院. 联邦学习应用场景研究报告[EB/OL],2022.http://www.caict.ac.cn/kxyj/qwfb/ztbg/202202/P020220222528294962585.pdf
[5] Big Data UN Global Working Group.Un Handbook on Privacy-Preserving Computation Techniques[J], 2019.
[6] C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating Noise to Sensitivity in Private Data Analysis. TCC, 2006.
[7] Differential Privacy Team. Learning with Privacy at Scale. Apple, 2017
*声明:本文仅代表作者观点,不代表隐私计算联盟的观点。
作者简介:
魏博言:中国工商银行大数据与人工智能实验室经理,英国谢菲尔德大学数据分析硕士,主要研究方向为机器学习学习建模和联邦学习。
强锋:中国工商银行大数据与人工智能实验室资深经理,英国爱丁堡大学运筹运化数学博士,主要研究方向为隐私计算技术在金融场景中的应用。
本文转载自魏博言 强锋@隐私计算联盟,原文链接:https://mp.weixin.qq.com/s/JNmPZrSjIIFRl1SqaOItRw。