
实时数据分析正在成为企业数字化经营的核心,如何有效构建实时数据分析系统是每个企业都在面临的挑战。
当前在构建实时数仓时,由于数据源的多样性,需要使用不同的采集工具,如 Flume、Canal、Logstash。对于不同的业务,我们通常会采用不同的分析引擎。
比如,对于固定报表业务,根据已知的查询语句可以预先将事实表与维度表打平成宽表,充分利用 ClickHouse 强大的单表查询能力;对于高并发的查询请求,可以使用 Apache Druid 承受大量用户高峰时期集中使用带来的并发压力。通过技术栈堆叠的方式确实可以满足业务要求,但也会让分析层变得臃肿,增加开发与运维的成本。
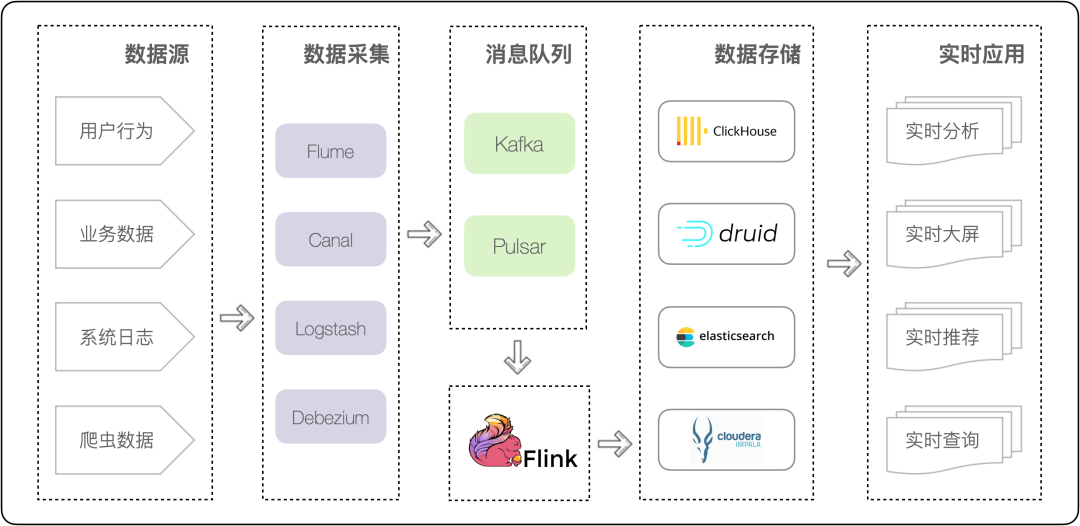

在这样一套架构中,数据从数据源到 OLAP 分析系统途径采集工具层、消息队列层、实时计算层。冗长的链路给开发和运维带来了极大风险,任何一个模块的阻塞都会对实时性产生影响。同时,在数据存储层上,我们也会选择不同的存储引擎适配不同的业务。
对于上面的数据链路,我们也面临着诸多的挑战,需要从时效性、功能性及可维护性上做更多的探索,由此可以总结出多个方面尚待优化:
-
CDC 链路复杂,维护成本高:组件不统一,链路过长,任何组件出现瓶颈都会对时效性产生影响;组件过多,需要多部门协作维护,维护成本成倍增长。
-
OLAP 存储和查询系统分散复杂,维护成本高,无法有效对复杂业务需求提供支持:分析层使用多种数据存储产品适应不同的业务类型,维护和使用成本巨大。另外,大宽表无法有效支持复杂查询需求,实时链路无法简单高效地实现不丢不重(去重),无法对业务数据变更提供很好的支持。
Flink CDC,一站式打通端到端链路
—
Flink CDC 是由 Apache Flink (以下简称“Flink”)社区开发的集数据采集、数据转换、数据装载一体的组件,可以直接从 MySQL、PostgreSQL、Oracle 等数据源直接读取全量或增量数据并写入下游的 OLAP 数据存储系统。使用 Flink CDC 后,可以简单高效地抓取上游的数据变更,同步到下游的 OLAP 数据仓库中。
构建一站式数据传输链路
在传统的实时数仓建设中,数据采集工具是不可或缺的。由于上游的数据源不一致,通常来说我们可能会在数据采集层接入不同的同步与采集工具,比如采集 Oracle 中的数据时,我们通常选择 GoldenGate,而对于 MySQL,我们可能会选择 Canal 或 Debezium。有些采集工具支持全量数据同步,有些支持增量数据同步。数据经过采集层后,会传输到消息队列中如 Apache Kafka(下文简称“Kafka”),然后通过 Flink 消费 Kafka 中的增量数据再写入下游的 OLAP 数据仓库或者数据湖中。
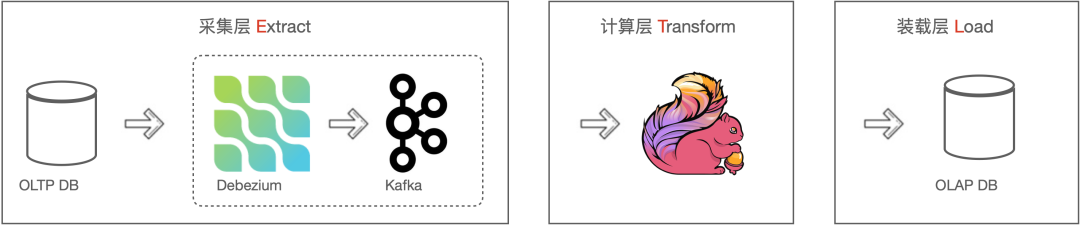
在业务开发中,上游的数据源、消息中间件、Flink 以及下游的分析性数据仓库通常在不同的部门进行维护。遇到业务变更或者故障调试时,可能需要多个部门协作处理,增加了业务开发与测试的难度。通过使用 Flink CDC 替换上图中的数据采集组件与消息队列,将虚线框中的采集组件与消息队列合并到计算层 Flink 中,从而简化数据链路,降低维护成本。同时更少的组件也意味着更少的故障与传输瓶颈,数据实效性会进一步提高。

在使用 Flink CDC 之后,数据链路中的组件变得更少,架构变得清晰简单,维护变得更方便。如在上面的例子中,我们使用 Flink CDC 拉取 MySQL 中的增量数据,通过 Flink SQL 创建事实与维度的 MySQL CDC 表,并在 Flink 中进行打宽操作,将结果写入到下游的 StarRocks 中。通过一个 Flink CDC 作业就可以完成抓取、转换、装载的全过程。
全量 + 增量数据同步
在传统的数据同步框架中,我们通常会分为两个阶段:
-
全量数据同步阶段:通过全量同步工具,如 DataX 或 Sqoop 等,进行快照级别的表同步。
-
增量数据同步阶段:通过增量同步工具,如 Canal 或 GoldenGate 等,实时拉取快照之后的增量数据进行同步。
在全量数据同步时,为了加快导入的速度,我们可以选择多线程的导入模式。在多线程模型下进行全量数据同步时,在对数据进行切分后,通过启动多个并发任务完成数据的同步。为了保证数据的一致性,有两种方案:
-
停止数据的写入操作,通过锁表等方式保证快照数据的静态性。但这将影响在线的业务。
-
采用单线程同步的方式,不再对数据进行切片。但导入性能无法保证。
通过 Flink CDC,可以统一全量 + 增量的数据同步工作。Flink CDC 1.x 版本中,采用 Debezium 作为底层的采集工具,在全量的数据读取过程中,为了保证数据的一致性,也需要对库或表进行加锁操作。
为了解决这个问题,Flink 2.0 中引入了 Chunk 切分算法保证数据的无锁读取。Chunk 的切分算法类似分库分表原理,通过表的主键对数据进行分片操作。
在经过 Chunk 数据分片后,每个 Chunk 只负责自己主键范围内的数据,只要保证每个 Chunk 的读取一致性,这也是无锁算法的基本原理。
StarRocks,让实时数据更新成为可能
—
StarRocks 在 1.19 版本推出了主键模型(Primary Key model)。主键模型可以更好地支持实时更新等场景。主键模型要求表有唯一的主键(传统 OLTP 数据库中的 Primary Key),支持对表中的行按主键进行更新和删除操作。
实时数据更新面临的挑战
在 OLAP 数据仓库中,可变数据通常是不受欢迎的。在传统数仓中,一般我们会使用批量更新的方式处理大量数据变更的场景。对于数据的变更我们有两种方法处理:
-
在新的分区中插入修改后的数据,通过分区交换完成数据变更。
-
部分 OLAP 数据仓库产品提供了基于 Merge on Read 模型的更新功能,完成数据变更。
分区交换数据更新模式
对于大部分的 OLAP 数据仓库产品,我们可以通过操作分区的方式,将原有的分区删除掉,然后用新的分区代替,从而实现对大量数据的变更操作。通过交换分区来实现大规模数据变更是一个相对较重的操作,适用于低频的批量数据更新。由于涉及到了表定义的变更,一般来说开发人员无法通过该方案独立完成数据变更。
Merge on Read 数据更新模式
Merge on Read 模式在写入时简单高效,但读取时会消耗大量的资源在版本合并上,同时由于 Merge 算子的存在,使得谓词无法下推、索引无法使用,严重影响了查询的性能。部分的 OLAP 数据仓库提供了基于 Merge on Read 的数据变更模型,如 ClickHouse 提供了 MergeTree 引擎, 可以完成异步更新,但无法做到数据实时同步。在指定 FINAL 关键字后,ClickHouse 会在返回结果之前完成合并,从而实现准实时的数据更新同步操作。但由于 FINAL 操作高昂的代价,会导致查询性能下降非常大,不足以支撑实时数仓带来的维度实时更新需求。
StarRocks 也提供了与 ClickHouse Merge Tree 类似的更新模型:Unique Key model。通过使用 Unique Key model,我们以 Merge on Read 的模式完成数据变更。在 StarRocks 存储内部会给每一个批次导入的数据分配一个版本号,同一主键的数据可能有多个版本,在执行查询时实时进行版本合并。Merge on Read 的更新模式牺牲了一部分的查询性能,由此 StarRocks 推出了更适合高频数据变更的 Primary Key model,以 Delete and Insert 的模型完成数据的实时变更。
主键模型高效的更新和查询能力

StarRocks 提供了基于 Delete and Insert 模式的主键模型,避免了因为版本合并导致的算子无法下推的问题。主键模型适合需要对数据进行实时更新的场景,可以更好地解决行级别的更新操作,支撑百万级别的 TPS,特别适合 MySQL 或其他业务库同步到 StarRocks 的场景。
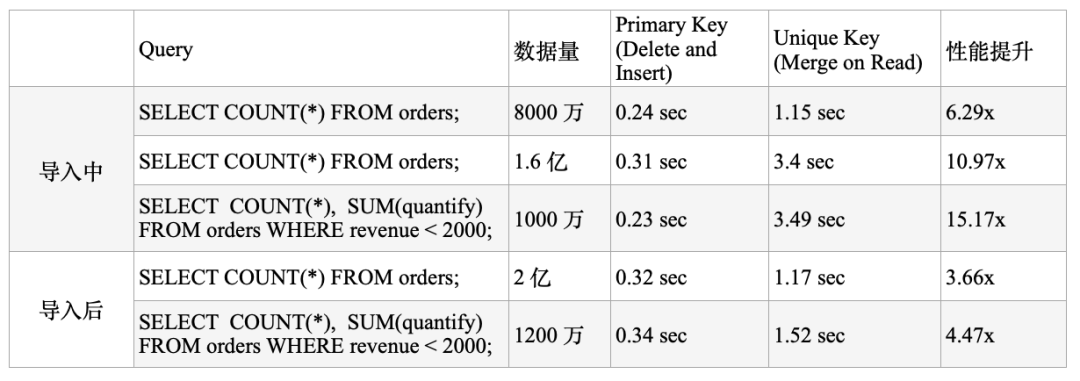
在 TPCH 标准测试集中,我们选取了部分的查询进行对比,基于 Delete and Insert 模式的主键模型相较于基于 Merge on Read 的 Unique Key 模型,性能有 3-5 倍以上的提高:
主键模型对去重操作的支持
消除重复数据是实际业务中经常遇到的难题。在数据仓库中,重复数据的删除有助于减少存储所消耗的容量。在一些特定的场景中,重复数据也是不可接受的,比如在客群圈选与精准营销业务场景中,为了避免重复推送营销信息,一般会根据用户 ID 进行去重操作。
在传统的离线计算中,可以通过 Distinct 函数完成去重操作。在实时计算业务中,去重是一个增量和长期的过程,我们可以在 Flink 中通过添加 MapState 逻辑进行去重操作。但通过 MapState,多数情况下只能保证一定的时间窗口内数据去重,很难实现增量数据与 OLAP 库中的存量数据进行去重。随着时间窗口的增加,Flink 中的去重操作会占用大量的内存资源,同时也会使计算层变得臃肿复杂。
StarRocks 的主键模型可以通过主键自动进行去重操作,这样可以无需在整个实时 Pipeline 中保证不丢不重,由 StarRocks 在 Pipeline 的末端进行去重即可,这样大大简化了“不丢不重”的实现复杂度。相比于在 Flink 中实现去重,StarRocks 主键模型可以节省大量的硬件资源,操作更为简单,并且可以实现增量数据加存量数据的去重操作。
维度数据实时变更
StarRocks × Flink,打造极速统一的实时数仓平台
—
大宽表实时数仓架构

在 ETL 不复杂的场景,我们可以将大部分 ETL 的操作放在 Flink 中实现。在某些场景下,业务模型相对简单,事实数据与维度数据利用 Flink 多流 Join 的能力打平成宽表,在 Flink 中完成了 DWD、DWS 与 ADS 层模型划分。同时对于非结构化的数据,也可以增量写入到 Apache Iceberg(以下简称“Iceberg”)、Apache Hudi(以下简称“Hudi”) 或 Apache Hive(以下简称“Hive”) 中,利用 StarRocks 的外表功能完成湖仓一体的架构。
当 ETL 的过程中引入较为复杂的业务逻辑是,可能会在 Flink 计算层占用大量的内存资源。同时,宽表的模式无法应对查询不固定的多维度分析场景。我们可以选择使用星型模型来替换宽表模型。
星型模型数仓架构
在某些复杂的业务,如自助 BI 报表、运营分析等场景中,分析师往往会从不同的维度进行数据探查,大宽表模型无法支持大量的维度,以及维度数据变更需要重刷大宽表代价巨大。星型模型可以很好支持查询的灵活性要求,以满足使用者“随意”在页面上拉去指标和维度、下钻、上卷和关联查询,也可以很好支持对维度数据进行变更。
StarRocks 提供了不同的 Join 方式,如 Boardcast Join、Shuffle Join、Bucket Join、Replica Shuffle Join、Colocation Join。CBO 会根据表的统计信息选择 Join Reorder 与 Join 的类型。同时也提供了多种优化手段,如谓词下推、Limit 下推、延迟物化等功能,进行多表关联的查询加速。同时通过 Primary Key 模型对于数据变更的支持,可以在 StarRocks 中创建缓慢变化维实现维度数据变更。
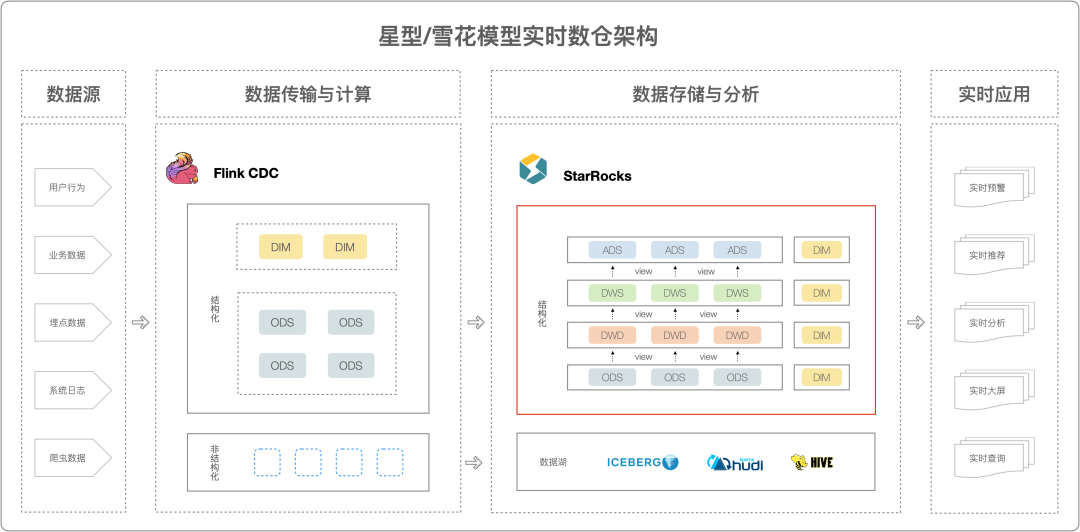
通过星型/雪花模型构建的开源实时数仓,在 Flink 中,只需要做 ODS 层数据的清洗工作,维度表与事实表会通过 Flink CDC 同步写入到 StarRocks 中。StarRocks 中会在 ODS 层进行事实数据与维度数据的落地,通过聚合模型或物化视图完成与聚合操作。利用 StarRocks 的极速多表关联查询能力,能够快速计算查询结果,保证业务在不同模型层的数据高度同源一致。
在真实业务中,维度的属性并非静止,会随着时间的流逝发生变化。星型模型可以将事实表与维度表独立存储,将维度数据从宽表中解藕,从而利用 StarRocks 的主键模型处理维度表变更的问题。
StarRocks × Flink 用户案例
—
在某知名电商平台业务中,通过使用 StarRocks 与 Flink CDC 极大程度地简化了数据链路的复杂度。用户通过 StarRocks 构建实时数据看板平台,实现了多维度数据筛选、灵活漏斗分析、不同维度上卷下钻的灵活分析。
困难与挑战
-
根据用户下单的操作,部分订单的状态会发生变化,但一般来说,超过两周的订单状态基本不会发生变化;
-
部分变化的数据不适合通过宽表的形式存储,部分的业务需求迭代较为频繁,宽表 + 星型模型的建模方式可以更好的服务于业务变更;
-
ClickHouse 扩缩容操作复杂,无法自动对表进行 Rebalance 操作,需要较长的业务维护窗口。
为了解决以上的问题,该电商平台重新做了技术选型。经过不断的对比与压测,最终选择使用 StarRocks 作为分析层的数据存储引擎。
系统架构升级
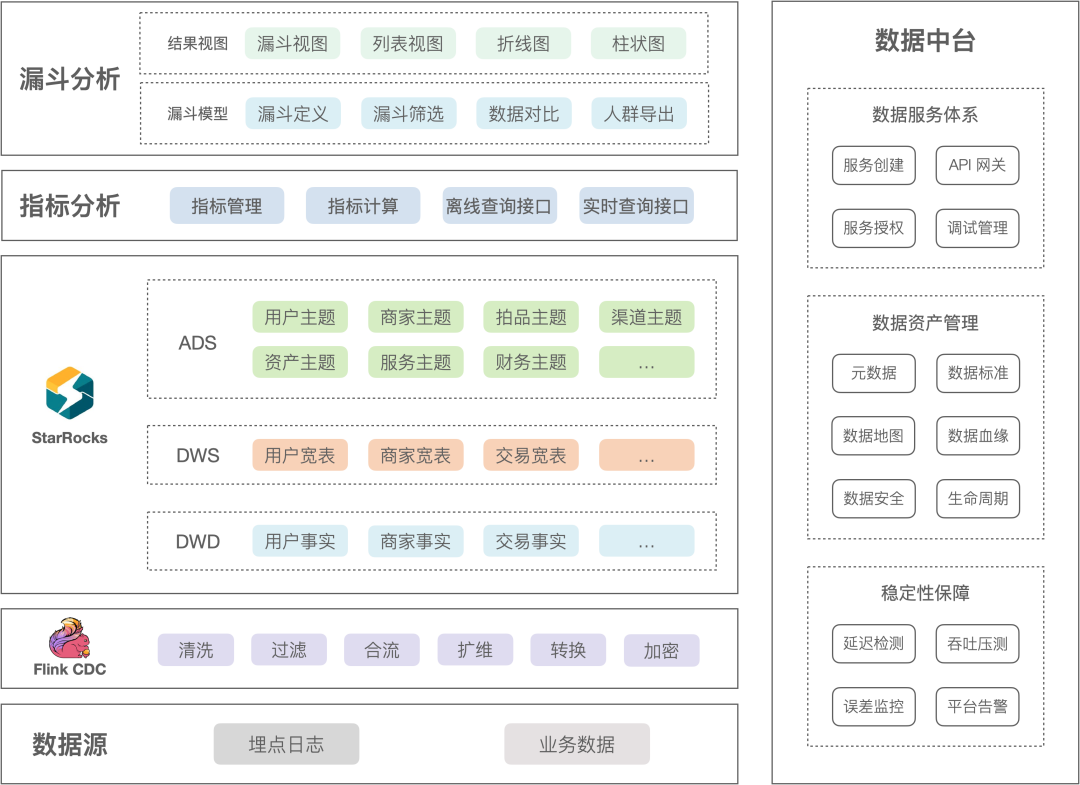
在实时看板业务中,主要可以划分成五个部分:
数据源层:数据源主要有两种,来自 Web 端与客户端的埋点日志,以及业务库中的订单数据;
Flink CDC:Flink CDC 抓取上游的埋点日志与业务数据,在 Flink CDC 中进行数据的清洗与转换,写入到 StarRocks 中;
数据存储层:根据业务的需求,将 DWD 层中的事实数据联合维度数据构建 View,以 View 作为 DWS 逻辑宽表,并在 ADS 层划分出不同的主题域;
数据服务层:包含了数据指标平台和漏斗分析平台两部分,根据内部的指标、漏斗定义进行逻辑计算,最终生成报表供分析师查看;
数据中台:围绕大数据分析平台,提供稳定性保障、数据资产管理、数据服务体系等基础服务。
新架构的收益
数据传输层:通过 Flink CDC 可以直接拉取上游的埋点数据与 MySQL 订单库中的增量数据。相比于 MySQL -> Canal -> Kakfa -> Flink 的链路,架构更加清晰简单。特别是对于上游的 MySQL 分库分表订单交易库,可以在 Flink CDC 中通过 Mapping 的方式,将不同的库中的表和合并,经过清洗后统一写入到下游的 StarRocks 中。省略了 Canal 与 Kafka 组件,减少了硬件资源成本与人力维护成本。
数据存储层:通过 StarRocks 替换 ClickHouse,可以在业务建模时,不必限制于宽表的业务模型,通过更为灵活的星型模型拓展复杂的业务。主键模型可以适配 MySQL 业务库中的订单数据变更,根据订单 ID 实时修改 StarRocks 中的存量数据。同时,在节点扩容时,StarRocks 更为简单,对业务没有侵入性,可以完成自动的数据重分布。
性能方面:单表 400 亿与四张百万维度表关联,平均查询时间 400ms,TP99 在 800ms 左右,相较于原有架构有大幅的性能提升。替换 StarRocks 后,业务高峰期 CPU 使用从 70% 下降到 40%。节省了硬件成本。
在“极速统一”上更进一步
—
一款优秀的产品,只提供极致的性能是不够的,还需要丰富的功能适配用户多样的需求。未来我们也会对产品的功能进行进一步的拓展,同时也会在稳定性与易用性上做进一步的提升。
日前,阿里云 E-MapReduce 与 StarRocks 社区合作,推出了首款 StarRocks 云上产品“阿里云EMR StarRocks”,大家可以在 EMR 上选择相应规格的 Flink 与 StarRocks。为了提供更好的使用体验,阿里云 E-MapReduce 团队与 StarRocks 也在不断的对产品进行优化,在未来几个月会提供以下的功能:
-
多表物化视图:StarRocks 将推出多表关联物化视图功能,进一步加强 StarRocks 的实时建模能力;
-
表结构变更同步:在实时同步数据的同时,还支持将源表的表结构变更(增加列信息等)实时同步到目标表中;
-
分库分表合并同步:支持使用正则表达式定义库名和表名,匹配数据源的多张分库分表,合并后同步到下游的一张表中;
-
湖仓一体架构:StarRocks 进一步增强 Iceberg 与 Hudi 外表功能,打造 StarRocks 湖仓一体架构。
一款优秀的产品也离不开社区的生态,欢迎大家参与 StarRocks 与 Flink 社区的共建,也欢迎大家测试 StarRocks X Flink CDC 的端到端开源实时数仓链路方案。
关于 StarRocks
StarRocks成立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 110 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
本文转载自王天宜 StarRocks,原文链接:https://mp.weixin.qq.com/s/TEqNtAbDLsebviYg97ZI9Q。