
1
架构
1.1 B站SQL On Hadoop 整体架构
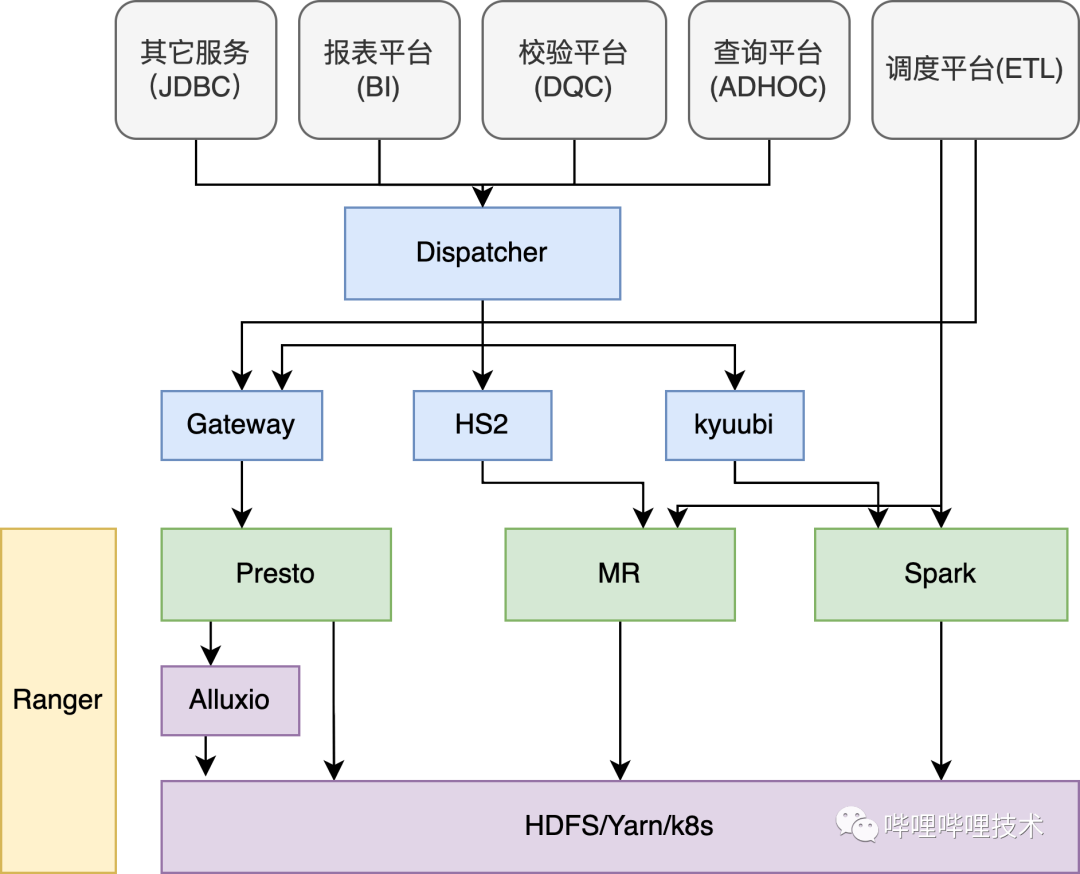
在介绍Presto在B站的实践之前,先从整体来看看SQL在B站的使用情况,在B站的离线平台,核心由三大计算引擎Presto、Spark、Hive以及分布式存储系统HDFS和调度系统Yarn组成。
如下架构图所示,我们的ADHOC、BI、DQC以及数据探查等服务都是通过自研的Dispatcher路由服务来进行统一SQL调度,Dispatcher会结合查询语句的语法特征,库表读HDFS的数据量以及引擎的负载情况等因素动态决定选择最合适的计算引擎执行,如果是Hive的语法需要用Presto执行的,目前利用Linkedin开源的coral对语句进行转化,如果执行的SQL失败了会做引擎自动降级,降低用户使用门槛;调度平台支持Spark、Hive、Presto cli的方式提交ETL作业到Yarn进行调度;Presto gateway服务负责对Presto进行多集群管理和路由;我们通过Kyuubi来提供多租户能力,对不同部门管理各自的Spark Engine,提供adhoc查询;目前各大引擎Hive、Spark、Presto以及HDFS都接入了Ranger来进行权限认证,HDFS通过路径来控制权限,计算引擎通过库/表来控制权限,并且我们通过一套Policy来实现表, column masking和row filter的权限控制;部分组件比如Presto、Alluxio、Kyuubi、Presto Gateway、Dispatcher, 包括混部Yarn集群都已经通过公司k8s平台统一部署调度。

1.2 Query查询情况
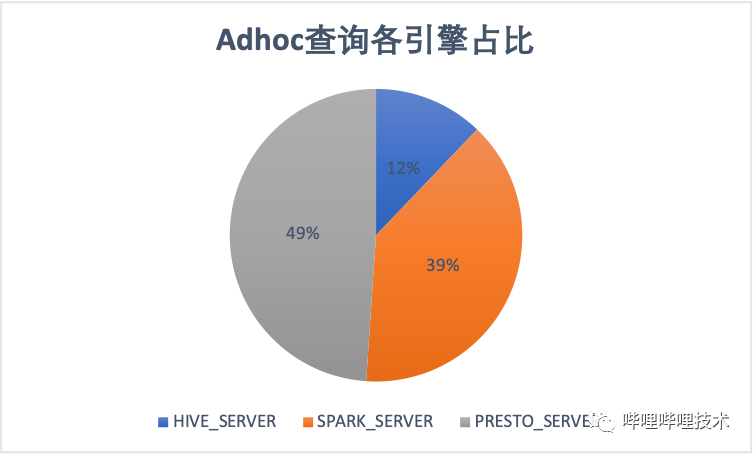
目前在Adhoc查询场景,Presto引擎占比接近一半。ETL常见主要还是Spark和Hive,随着我们不断的对Hive作业迁移到spark,ETL作业spark占比达到64%。
2
Presto应用
Presto是由facebook 开源的分布式的MPP(Massive Parallel Processing)架构的SQL查询引擎。基于全内存计算(部分算子数据也可通过session 配置spill到本地磁盘),并且采用流式pipeline的方式处理数据使其能够节省内存的同时,更快的响应查询。
相对Hive、Spark引擎,Presto存在不少优势:
1. shuffle数据不落地
2.流式任务执行而不是按stage级别执行
3.split为线程级别的调度
4.数据源插件化
这使Presto 特别适合交互式跨源数据查询,Presto也并不是完美的,比如因为其流式pipeline执行方式的设计,使其丧失了task级别的recovery机制,所以Presto目前不是特别适合用来做大规模的ETL查询,当然目前社区也在通过对presto进行各种优化来使其适应更大规模的查询,比如Presto Ulimited和Presto on Spark项目。
2.1 使用场景
在B站,Presto主要承担了ADHOC查询、BI查询、DQC(数据校验,包括跨数据源校验)、AI ETL作业、数据探查等场景.
2.2 集群规模
目前Presto总共7个集群,分布在2个机房,最大单集群节点400+,总节点数在1000+。
2.3 业务增长
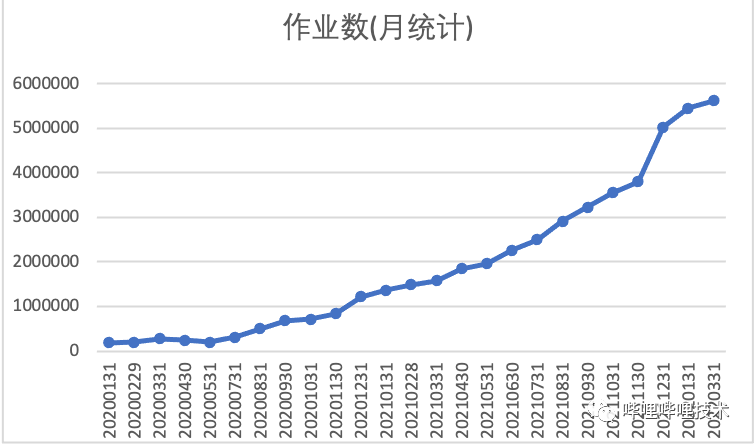
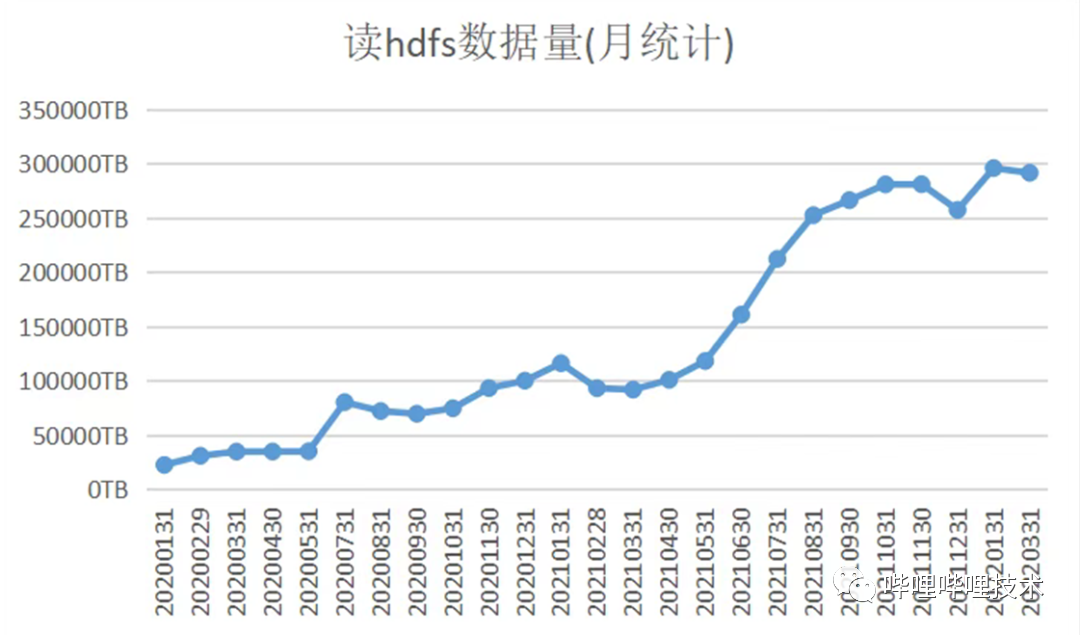
目前我们集群每日查询数16w左右,每日查询HDFS数据量10PB左右,目前相比2020年初日查询数增长10倍。
2.4 Presto架构
目前我们是基于PrestoSQL-330(现在改名叫Trino)版本进行二次开发和优化的,我们所有集群接入到公司Caster发布系统,由k8s进行调度管理,包括jmx的采集、监控dashboard、告警,极大的简化了我们运维的成本。整体架构如下图:
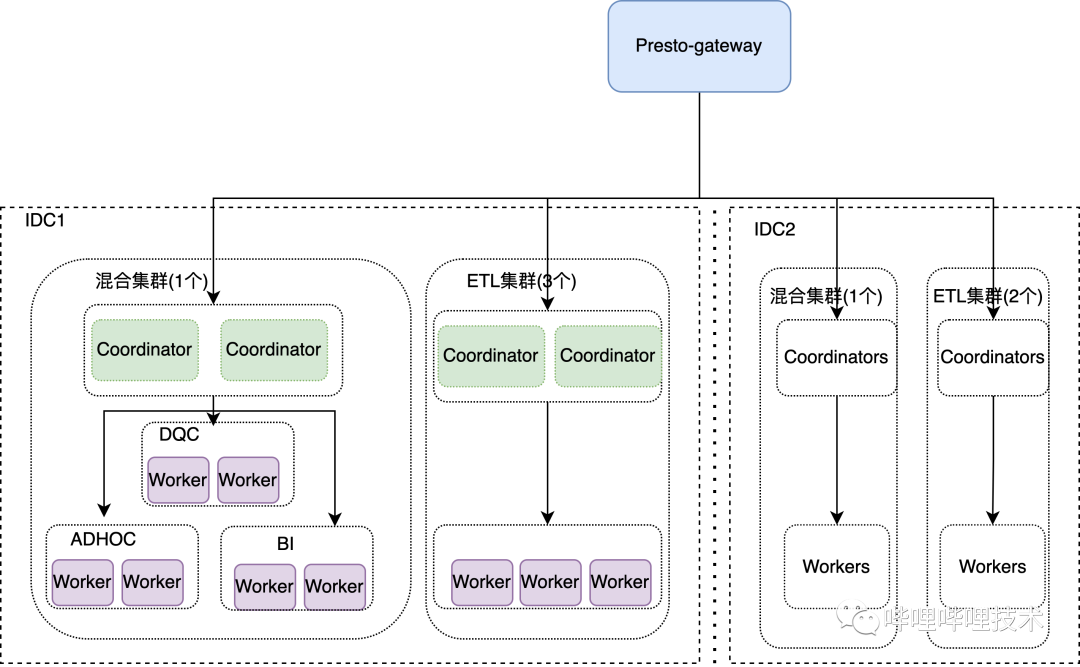
目前我们所有的presto查询,包括Cli、JDBC、PyHive都是直接提交到Presto-gateway,由gateway来负责路由。
gateway改造:
1. 支持多coordinator调度,相同query只能调度到一个集群的一个coordinator。
2. 探测coordinator的状态,如果不Active,则踢出调度列表,给无损发布提供可能。
3. 支持按用户/作业ID来选择机房调度,同时我们还会对Query通过Parser解析依赖的表和分区,根据哪个机房流量读取大,将Query调度到哪个集群。
4. 探测coordinator的负载,主要包括内存、作业是否堵住,支持跨集群负载均衡调度。
5. 提取了Query特征,相同特征Query提交我们会有一系列拦截措施。
presto改造:
1. coordinator支持多活,解决了coordinator的单点问题。
2. coordinator支持按业务来进行调度,不同业务调度到不同的Worker节点,同时为了增加集群利用率,我们支持按时间跨Label调度, 比如凌晨为adhoc和bi查询的低峰,但却为dqc的高峰,这个时候dqc能够跨Label使用其他Label的计算资源。
2.5 集群执行情况
目前adhoc集群执行百分位如下图所示:

3
稳定性改进
3.1 Coordinator多活改造
Presto 是典型的主从架构,Coordinator作为主节点,其存在单点问题,当主节点挂了之后,整个集群不能对外提供服务,为了增加集群的稳定性和可靠性,我们对Presto服务发现以及资源全局化做了改造,使coordinator可以支持横向扩展。架构图如下:
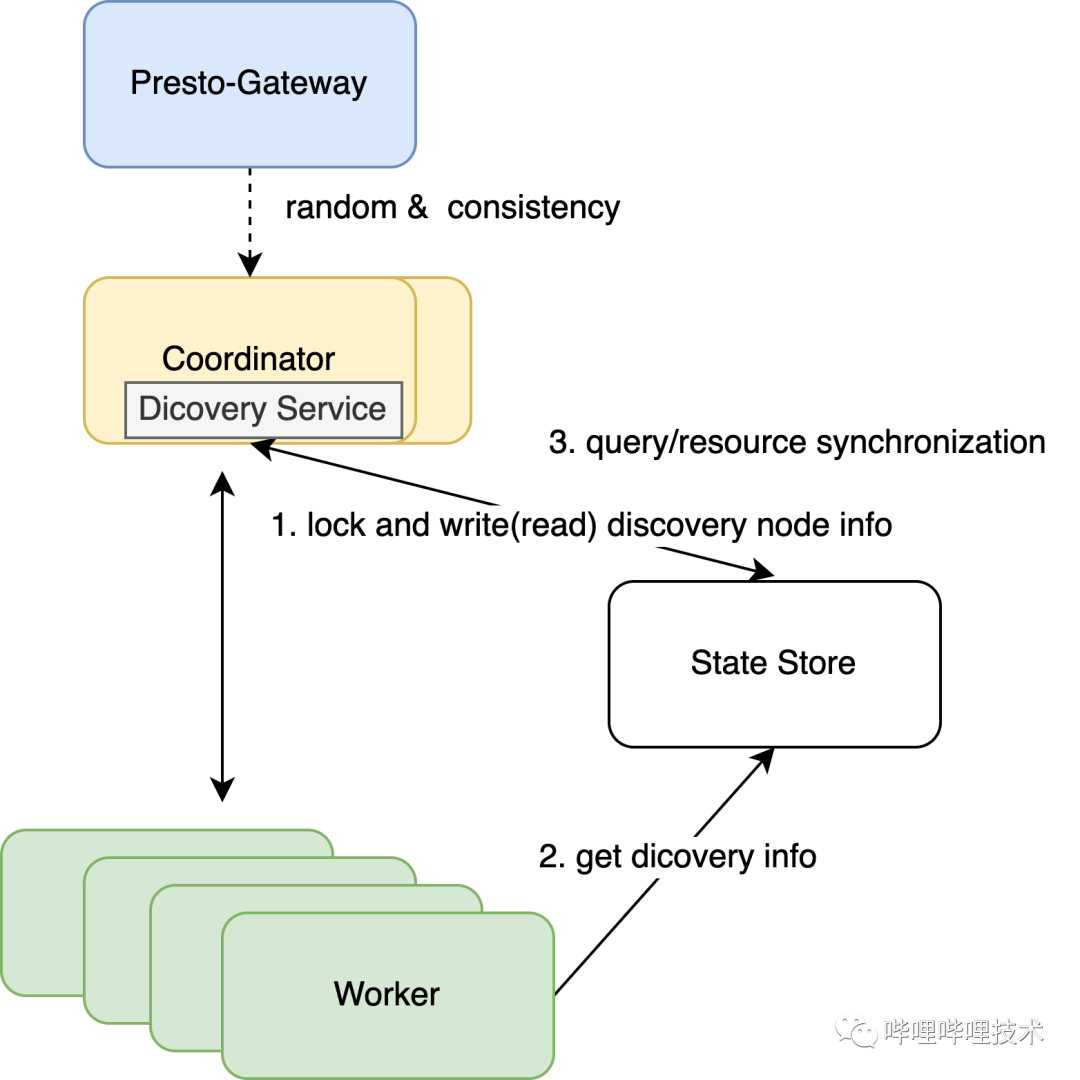
1. 因为Coordinator虽然能够支持横向扩展,但是它并不是无状态化的,所以我们对gateway进行了改造,一条query提交过来之后,针对这个集群,如果是多活,则随机选择一个coordinator,并且将该query和coordinator的mapping保持到redis,之后该query的所有请求都会保持一致。
2.coordinator启动的时候会通过加全局锁的方式,尝试将自己节点ip和端口写入State Store服务,然后启动DiscoveryServer服务。
3.各节点的ServiceInventory获取上述写入到State Store中的节点信息来作为Discovery Service,所有节点都会向该地址发送announce,DiscoveryServer会进行保存,然后DiscoveryNodeManager通过GET请求到‘/v1/service‘便能拿到所有节点信息。
4.为了保持多Coordinator具有整个集群的全局资源信息,每个Coordinator会将自己的query和resource group的信息写入State Store,同时会从State Store中不断的读取并更新自己节点上的资源信息,这能保证各个Coordinator都有全局的资源使用情况,避免了过度调度导致集群负载过高而不稳定。
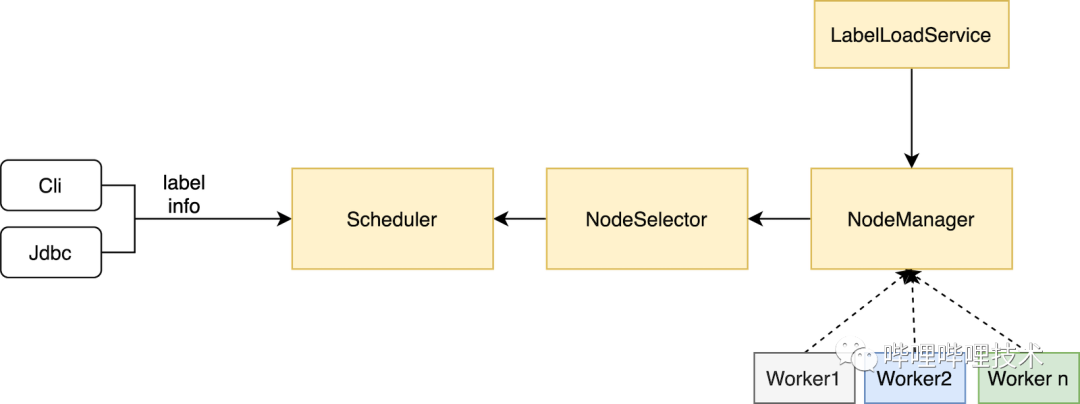
3.2 Label改造
大家都知道,Presto 在资源隔离方面做的并不好,coordinator的resource group 只能在用户提交查询的时候进行限制,比如超过query数,内存使用超过比例,cpu使用超过quota则新提交的查询会进到queued队列中,worker端虽然有MultilevelSplitQueue 来对运行时间长的task进行调度限制,但是并不能做到很好的资源隔离。
在经过多次因adhoc大查询影响报表查询之后,同时又不想拆分集群(运维成本增加),所以我们对presto进行了改造,改造思路比较简单:
1.开发一个服务,负责将已经划好label的配置文件load进内存,并实时检测文件是否更新,如有更新重新load。
2.DiscoveryNodeManager 通过服务发现拿到所有Node之后,将label信息写进InternalNode中。
3.NodeSelector 构建NodeMap的时候也就有了节点label信息了。
4.客户端根据不同业务将label信息传递到coordinator,调度的时候根据label去get到相应的节点即可。
3.3 实时惩罚
Label的改造能隔离业务之间互相影响,但是并不能解决相同业务Label下受大查询的影响,另外社区版本的cpu/内存限制只能限制新提交的语句,已经在执行的语句会不受cpu/内存限制,所以我们开发了一套实时惩罚的机制。
架构图如下,通过实时收集到各个query的cpu使用情况,基于resource group配置的cpu quota信息,对超过quota的resource group,直接向所有worker节点下发惩罚消息,worker收到消息后,会停止对该resource group的task进行调度,等到该resource group使用资源低于quota后,再通知worker重新对task进行调度执行。
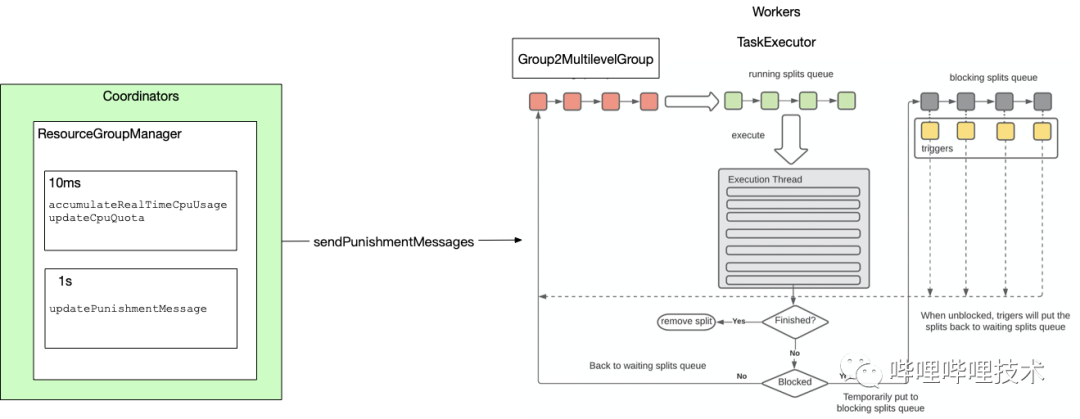
目前的使用场景是,ETL集群如果有大量大查询同时提交,就会出现集群不稳定,比如某个worker被打挂,针对大查询,presto gateway会在第二次提交到集群后,自动路由到slow resource group,针对该resource group我们开启了惩罚机制,避免过多大查询影响整个集群的稳定性。同时我们的惩罚机制是否开启,以及惩罚quota大小都支持动态更新,随时可以调整配置不需要重启集群。
惩罚算法伪代码如下:
成员变量:(以GroupA举例)
-
punishCpuLimit :GroupA所配置的cpu算力上限
-
usagePerSecond:GroupA实时统计到的每秒所使用的cpu消耗
-
cSum:GroupA累计消耗的cpu总和
long cSum = lastCSum + usagePerSecond;if (cSumcSum = 0;} else if (cSum >= 2 * punishCpuLimit) {// 这边记录当前resource group 需要惩罚cSum = cSum - punishCpuLimit;} else if (punishCpuLimit 2 * punishCpuLimit) {cSum = cSum - punishCpuLimit;}
代码做了如下改造:
1. ResourceGroup中除了通过running query收集原有cpu time信息,我们还收集了schedule time和running driver指标供惩罚选择。
2. 如下图所示,worker端我们实现Grouped2MultilevelSplitQueue对象,该对象维护了一个resource group和MultilevelQueue的mapping,并且会接受处理coordinator的惩罚信息。
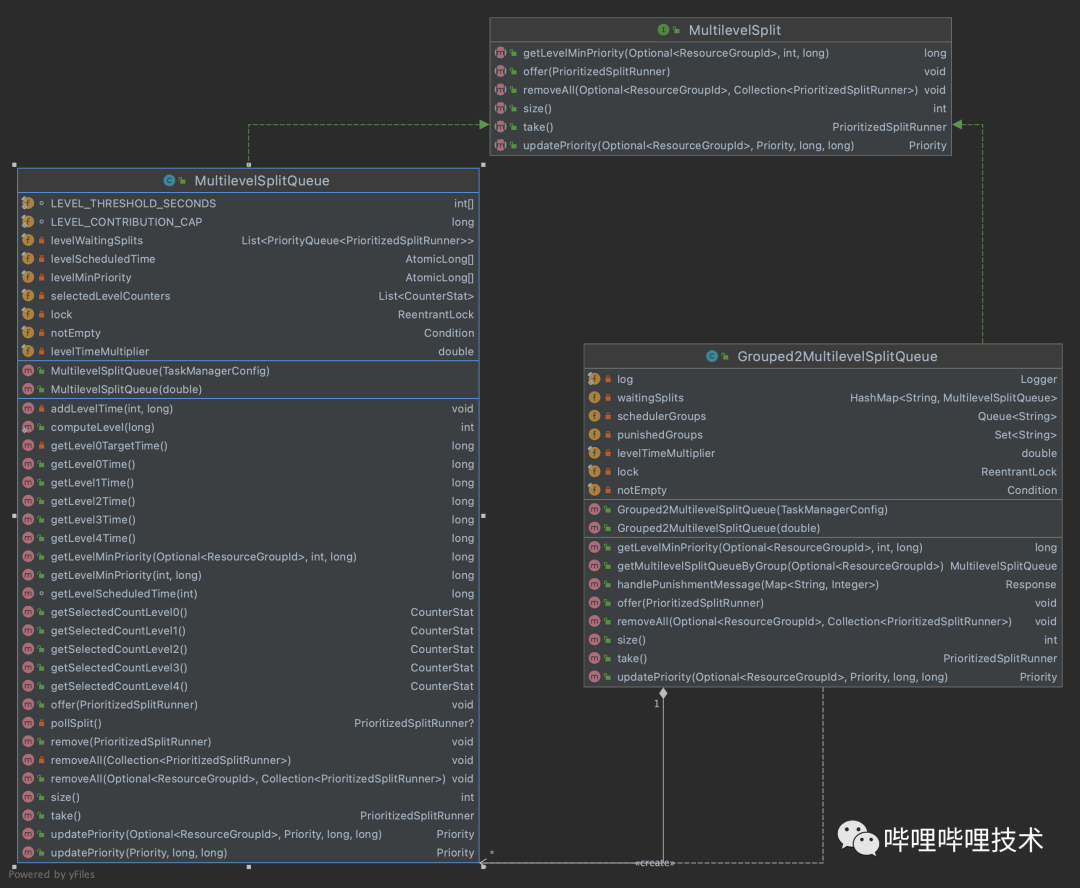
3. coordinator端实现了一个Punish Service,用来实时计算各resource group是否超过了quota设置,如果超过,则下发惩罚信息给所有worker节点
3.4 查询限制
我们在presto gateway中开发了一系列规则来对用户查询行为以及bad sql进行限制,策略包括:
1. 对查询语句进行了特征提取,包括去除注释,替换表达式的具体值为通配符,取md5为该查询的特征值,方便进行相同特征查询限制。
2. 针对INSUFFICIENT_RESOURCES类型超内存的查询,第二次查询直接拦截不让提交,因为再次提交依然会失败,浪费集群资源。
3. 读HDFS超过30TB的查询第一次会在运行时被kill掉,第二次提交会被gateway检测到后直接拦截。
4. 短时间大量提交的查询会进行拦截限流,比如1分钟提交超过30条相同特征的query。
5. 回刷数据任务统一调度到一个独立的resource group,避免影响正常ETL/ADHOC任务。
6. 针对worker oom killer的kill掉的查询,如果其占用内存超过一定阈值,那么之后该特征query都会调度到slow resource group进行限制。
3.5 其他改造
1. worker端开发了oom killer服务
不断的从MemoryMXBean拿内存使用情况,当worker堆使用超过一定百分比,并且持续超过一定时间,就开始选择占用最大内存的task kill掉。
2.监控告警
通过presto暴露的jmx,然后将信息采集吐到grafana,可以很方便的监控到集群的一些关键信息,并且基于这些信息做了一些告警。
4
可用性改进
4.1 支持隐式转换
Hive和Spark默认就支持隐式数据类型的转换,比如query select 1 = ‘1’ hive能正确返回true,而presto直接报语法错误,我们通过在ExpressionAnalyzer中对逻辑表达式和算术表达式进行了判断,如果左右表达式不一致,同时能够兼容的话,直接通过加cast进行类型强转。
hive> select 1 = '1';trueTime taken: 3.1 seconds, Fetched: 1 row(s)presto> select 1 = '1';Query 20220301_114217_08911_b5gjq failed: line 1:10: '=' cannot be applied to integer, varchar(1)select 1 = '1'presto> set session implicit_conversion=true;SET SESSIONpresto> select 1 = '1';_col0-------true(1 row)
4.2 兼容HIVE UDF
我们兼容了Hive自带的UDF和GenericUDF, 并且如果在Presto自带以及hive-apache中没有的UDF,会尝试从hive metastore去获取一下是否存在该Function,如果存在,则将UDF所在的jar包download到本地,然后通过classloader进行load。
1. UDF入参和出参转换,Hive GenericUDF入参为DeferredObject,需要根据Presto参数类型进行相应的转换,比如Presto的VARCHAR则需要通过Slice的toString转换成String类型,返回结果为ObjectInspector,不同的返回类型需要转换成Presto相应的数据类型,比如是StringObjectInspector则需要封装到Slice中。
2. 通过codegen方式将HiveUDF调用方法生成到MethodHandle中。
3. 因Hive UDF未考虑并发问题,所以存在线程安全问题,构建的GenericUDF需要通过ThreadLocal来隔离。
4.为了防止各个UDF依赖不同版本的jar导致冲突,通过对每个UDF的jar new一个新classLoader进行隔离,该classLoader的parent为Hive plugin ClassLoader(已经加载了Hive-exec相关类)。
presto> select b_security_mask_email('123@bilibili.com',0);_col0------------------1*3@bilibili.com(1 row)
4.3 支持insert overwrite table/ directory语法
Presto原生要支持Overwrite语义需要在insert into语句中设置’insert_existing_partitions_behavior’ session参数来控制,为了保持和hive语法的一致性,我们通过修改Presto的语法文件, 使其先支持接受Insert overwrite table语法,然后在遍历AST树时,遇到InsertOverwrite节点则生成Insert节点,同时将overwrite含义一路透传到worker,修改其Insert语义为overwrite, 同时也支持hive的动态和静态分区写法。
因为adhoc系统针对大查询的结果下载功能,通过将用户sql修改为insert overwrite directory ‘location’ select语法,将结果保存到hdfs,然后通过下载中心提供给用户导出,hive和spark是支持的,我们也对presto进行了改造支持。
presto> insert overwrite table tmp_db.tmp_table select '1' as a, '2' as b;INSERT OVERWRITE: 1 rowpresto> insert overwrite directory "/tmp/xxx/insert1" select value.features from ai.xxxTable limit 10;rows------10(1 row)
4.4 兼容Hive Ranger Plugin
Ranger在2.0版本开始支持Presto plugin,我们基于Ranger1.2版本做了不少优化,升级的需求不大,所以我们在1.2版本的Ranger中加入了Presto的plugin,同时2.0版本的Ranger是基于3段式来进行赋权,而我们大部分的权限需求还都在hive,所以我们对plugin进行了一些改造,使其兼容了Ranger Hive赋权policy,也就是说通过对Hive plugin赋权一次,presto和hive、spark引擎共用policy,目前库,表,row-level filtering和column masking都支持。
4.5 支持Hint语法
我们在语法定义层面做了hint的实现,支持常见session参数通过写在sql hint上进行配置,比如join类型的选择,query执行时间,是否关闭cache读,是否开启spill to disk等。
/*+ query_max_execution_time= '1h', scale_writers=true*/SELECT clo_1, col_2 FROM xxxx WHERE log_data='20211019'
4.6 支持having alias、group by alias语法
针对如下查询,因为percent是一个alias字段,presto查询会报错,而hive和spark是支持该语法的,我们通过拿到node的SelectItems进行对比,并替换alias字段信息。
presto> select log_date, sum(job_percent) as percent from test.test_report group by log_date having percent > 0;log_date | percent----------+-----------------------20211231 | 0.03625346663870051
4.7 其他改造
-
基于Linkedin开源的Coral支持读Hive视图。
-
支持动态加载和更新Resource group。
-
支持多数据源联合查询,数据源包括Kafka, JDBC, Tidb,Clickhouse,Iceberg,Hudi, ES,其中JDBC connector支持按splitField自动切分成多个Split并行读表。
-
基于HDFS的共享JAR包和配置,做到动态添加Catalog,无需重启集群。
-
在Web ui中展示了Query queued具体原因。
-
语句结束后将QueryInfo序列化写入HDFS,实现了Job History服务,更长时间保留语句信息,方便对出问题语句进行问题定位。
-
集群实现无损发布,Presto worker进程通过监听发布系统kill -15信号,然后将自身状态置为非ACTIVE,不接受新任务,等所有任务结束再退出进程。
-
实现了和Hive一样的点边式的字段级血缘和算子影响关系,细化了血缘模型。
5
性能提升
5.1 Presto on alluxio
通过收集presto的血缘信息,我们发现少数表会被反复读取,根据表最近7天访问的平均值作为热度,从下图可以发现,很多表一天被访问好几百次。

基于这样一个事实,因为本身Presto和HDFS是存算分离的架构,加上HDFS经常会存在slow rpc,或者热点Datanode情况。所以我们决定使用Alluxio来缓存这部分热数据,使Presto提升查询效率的同时,也减少了HDFS的压力,减少了受HDFS的影响。
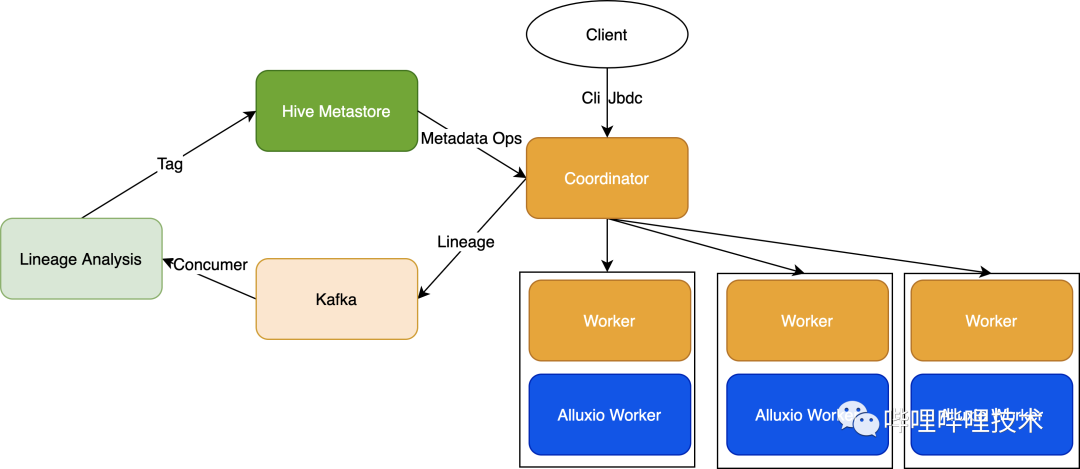
架构图如上,通过将Presto的血缘吐出到kafka,然后对血缘进行分析,比如如下血缘信息,只需要对json进行解析就能拿到查询的表,以及读了哪些分区。

我们也做了以下事情来确保热表数据被Presto识别,并且自动转换到Alluxio中读取:
1. 消费血缘数据,按集群解析到分区级别访问信息并落地到Tidb。
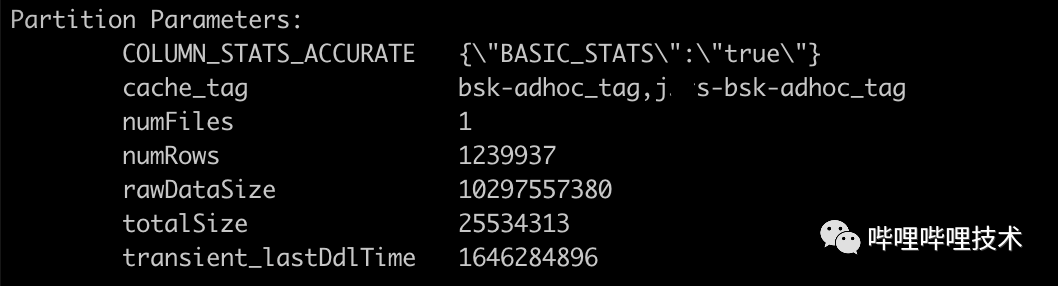
2. 开发cache tag管理服务,主要用来对分区进行打tag(tag存储在hms中的Partition Parameters),并且通过分区访问情况,计算其TTL,对于超过TTL的分区会进行untag,并且从alluxio中删除路径。
如下图所示,如果这个分区对哪个集群是热表,那么只需通过cache_tag来控制哪个集群应该从Alluxio读数据。
3. 开发cache invalidate服务主要为了保证hdfs和alluxio的数据一致性,该服务会监听Hive meta event,分区更新则删除alluxio中的分区路径,同时对于已经打tag的表,该服务还监听add partition事件,然后给新增分区打tag,并且通过alluxio的distributed load 向Alluxio JobMaster发送请求,load文件到alluxio worker。
alluxio自身可以通过下面参数来控制是否每次和底层HDFS元数据是否一致,但是为了不受偶尔NN慢rpc影响,我们通过上述服务来保证数据的一致性,目前Presto adhoc集群已经接入了HDFS的Observer NN,在RPC读请求延迟方面得到了很大的改善,可以考虑直接通过alluxio来保证数据的一致性。
alluxio.user.file.metadata.sync.interval=0alluxio.user.file.metadata.load.type=ALWAYS
4. Presto这边做的改造就比较简单,在load split的地方拿到分区的Parameters,如果含有cache_tag的信息,并且如果和当前集群是吻合的,那么将HDFS的路径改成Alluxio的地址,真正建立连接时候还会检测一次Alluxio是否连通,如果有问题,会继续降级读HDFS。
效果如下:
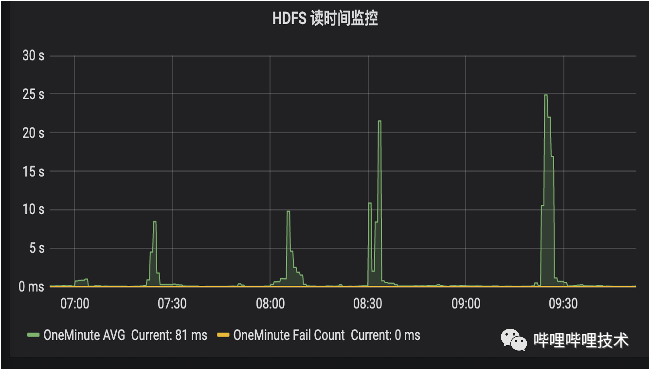
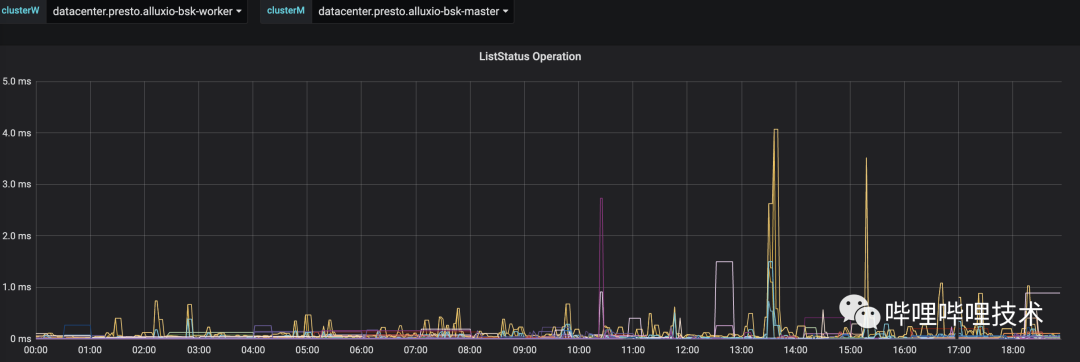
通过Presto的TPC-DS benchmark,基本上平均能够达到20-30%左右的性能提升,同时被打了tag的分区查询更加稳定,如下图所示,HDFS经常会有几十秒的读RPC延迟,从Alluxio的liststatus rpc时间来看(耗时低于10ms),访问到热分区的rpc请求更稳定,也更快。目前我们BI报表有30%的分区已经被打上了tag,未来计划打上更多的热分区tag。
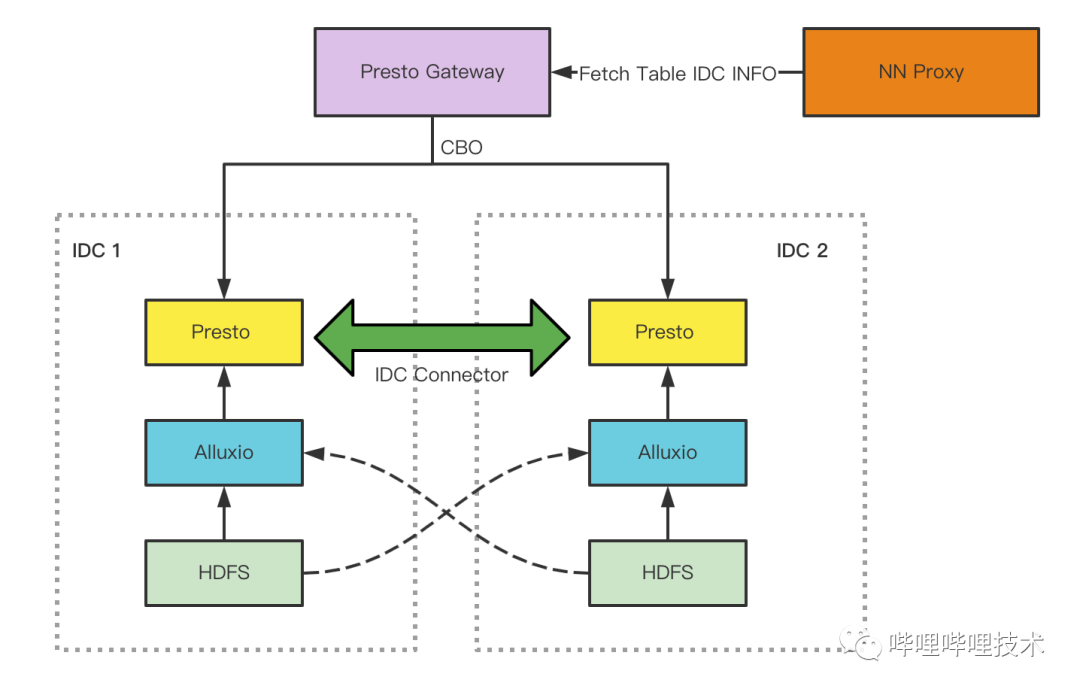
5.2 多机房架构
随着B站业务高速发展,数据量和作业数增长也变得越来越快,机房机位快速消耗,容量达到上限后会阻塞业务的发展。一个机房资源既然有限,那我们扩展为多个机房,引入异地第二机房部署Hadoop和Presto集群, 但多机房面临的问题一个是跨机房数据交互带宽资源有限,存在瓶颈,一个是网络抖动造成的服务SLA会有影响。在此背景下我们设计了Presto的多机房架构,对原有的架构进行改造,保证从用户视角仍然是一个机房。用户侧统一接入Presto gateway,每个机房我们都独立部署一套Presto集群,这样Presto内部shuffle数据就不会跨机房产生流量。对于Hive外部数据源读取,分两种场景,ETL场景下由于我们做了基于单元化思路的数据和业务迁移,将高内聚的业务和数据迁移到第二机房,所以作业通过Presto gateway时会自动按照用户或者作业ID的mapping关系路由到对应机房的集群。adhoc场景下,临时产生的需求,一般无法预测流量,我们做法是在Presto gateway中解析出语句需要访问的表和分区路径,并从Namenode proxy中获取到路径所在的机房位置和数据大小信息进行计算,预估出作业放到各机房后所产生的跨机房流量,以节省跨机房带宽为目标,再综合每个集群的实际负载情况来决定将作业调度到哪个机房。比如:
-
访问单张表:调度到数据所在机房
-
访问多张表:
a. 多表在同一机房,作业路由到数据所在机房
b. 多表在不同机房,路由到数据量较大的表所在机房,较小的表限流读
此外我们也做了两个优化,一个是计算下推优化,利用Presto的Connector多源查询能力,实现了跨IDC connector,将第二机房集群视为一个connector,在访问多表不同机房的场景下将SQL做改写,子查询计算逻辑尽可能下推到第二机房集群进行部分计算处理,再和主机房计算结果进行合并,以减少跨机房流量带宽。另一个我们也通过血缘分析出跨机房读热分区,提前加载到本地alluxio进行缓存,尽量避免下次跨机房访问。
5.3 Query result cache
我们之前根据query的md5统计了一下,每天有超过万条查询是重复的查询,如果这部分查询的结果能够缓存起来,那么直接将结果返回给客户端,不仅可以减少集群压力也可以提升查询速度。
对Query的结果做缓存,最大的挑战就是保证用户查询的是最新的数据,否则就出现数据质量问题了。
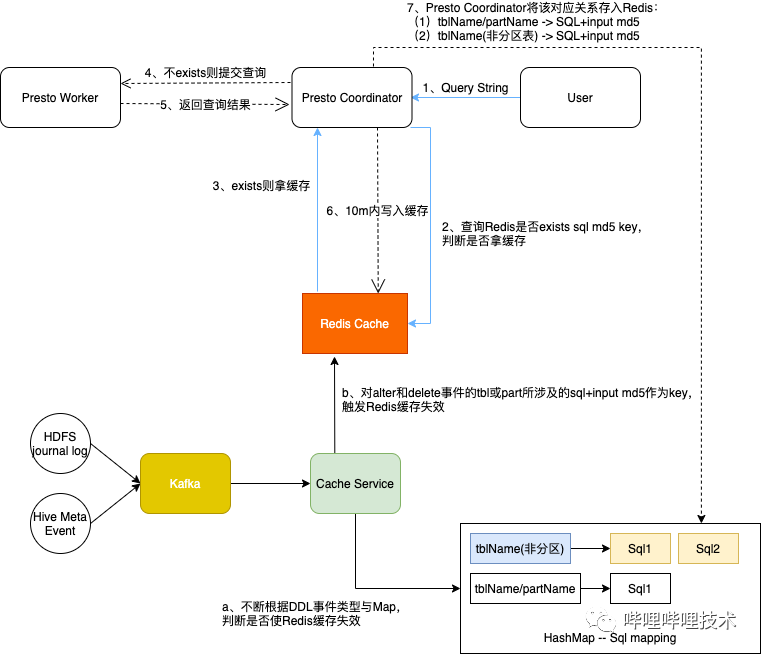
架构如上图:
1.为了能够获取query查询的表以及分区信息(这部分信息将用来作为缓存的key),我们将逻辑写在Coordinator,在Coordinator 做完LogicalPlan之后,拿到查询的表信息(包括分区信息),然后再加上query本身计算md5作为key,然后从根据key值从redis中查询看看是否存在缓存,如果存在,则将QueryStateMachine置为Cached状态。这里再解释一下为什么需要获取查询的表和分区信息,比如这条sql:select * from db.table where log_date > ‘20220101’, 那么这条query今天和明天分别执行,读到的分区数是不一样的。当然我们最近也在准备将这部分逻辑前置到gateway,在gateway中对query进行部分元数据分析,拿到分区级别信息。
2.在获取结果的逻辑中,加入了缓存结果保存和读取的逻辑,在保存缓存结果的同时,也会将上述分析拿到的分区、列类型信息和query的mapping关系也保存起来。
3.同时还开发了缓存失效服务,监听查询依赖的表分区是否有更新,如果有则直接删除缓存。
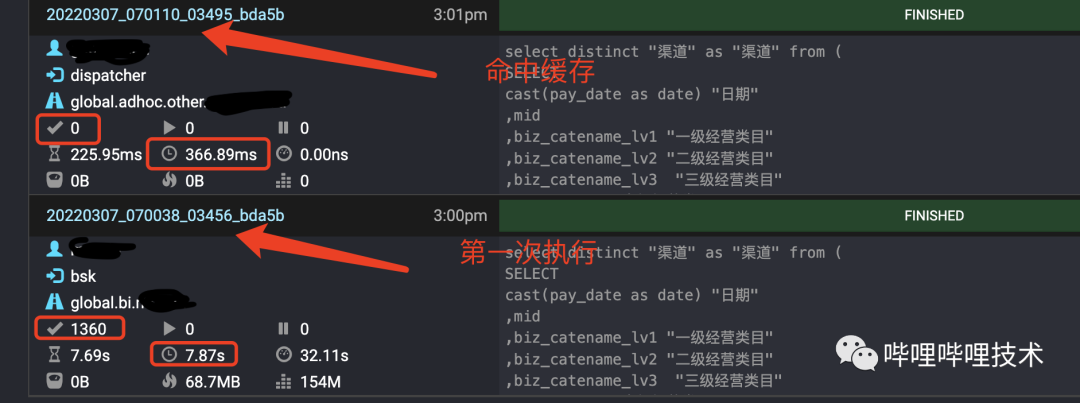
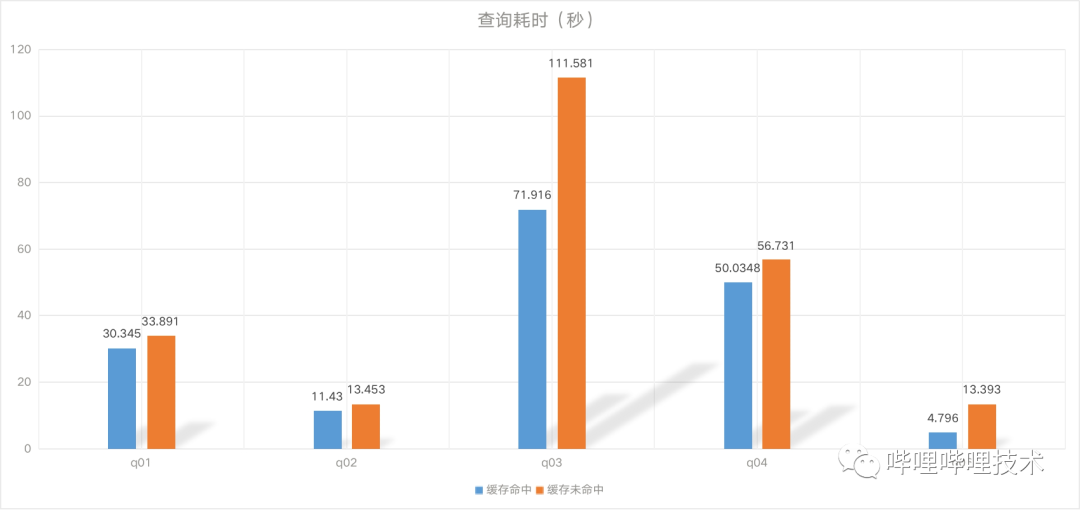
如下图所示,两条一样的query,第一次执行需要7s,第二次执行只需要300ms,并且从split来看没有触发调度。目前每天有5k条Query能够得到缓存加速。
5.4 Raptorx
Raptorx是Prestodb通过数据缓存进行查询加速的项目(https://github.com/prestodb/presto/issues/13205),得益于软亲和性的调度策略,一个Split或者文件会通过一致性Hash算法调度到相同的Worker节点,第一次访问的时候按照文件需要读的offset和length,以细粒度Page(通常1MB)为单位从HDFS缓存在本地磁盘,第二次访问的时候,直接从本地节点的缓存访问,而不需要再远程读取数据,因为采用了一致性Hash算法所以尽可能降低了节点扩缩容时候对现有节点缓存命中率的影响,如果分片Hash完选择的第一台节点由于负载过高不宜分配,会自动顺延降级到后一台节点调度,如果后一台节点负载也很高,则继续降级调度策略进行随机调度,同时关闭本次查询从缓存读的开关,这样文件最多物理缓存在两台节点。同时得益于Split或者文件能调度到相同机器,那么针对ORC或者Parquet的一些文件meta信息,比如orc文件的file footer,stripe statistics, row group index信息等都可以缓存到worker进程JVM内存中,无需再从HDFS读取,也有不错的缓存命中率。
上面也提到,我们其实上线了Alluxio集群来缓存数据,那为什么还需要引入raptorx呢,raptorx相对于Alluxio集群模式有几大好处:
-
Raptorx基于Alluxio local cache,是Page级别(默认1MB)的缓存,而集群模式必须缓存整个文件,通常用户经常访问的数据集中在某张表的几个列,而列存格式中同一列数据是紧凑存放一起的,细粒度缓存只需要缓存某些常用列的数据,不需要整个文件缓存,减少缓存管理开销。
-
上面提到,可以针对orc和parquet缓存文件和stripe、row group等的meta信息,近一步提升查询性能。
-
本地数据管理以Library方式嵌入到Presto worker进程中,不受Alluxio集群稳定性影响。
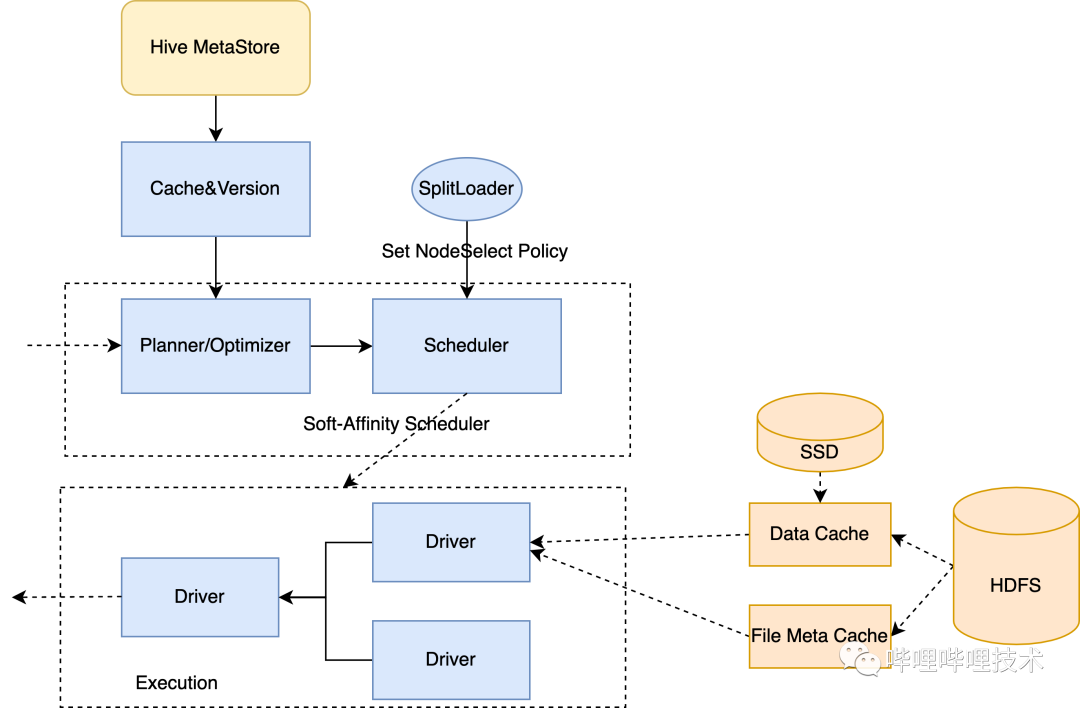
我们backport了Prestodb Raptorx相关的patch,并且做了一些其他改造:
1. 社区通过session来控制一个query级别的local cache,如果该query 开启local cache,那么query依赖的所有表的所有分区数据都会进SSD,粒度不够精细,我们是根据分区是否被标记成热分区,然后只会将热分区进行软亲和性调度。
2. Raptorx中的hive metastore versioned cache是基于FB的内部版本,要使用这块功能需要对hive metastore改造thrift api暴露出分区和表的版本信息,我们利用Table和Partition的lastDDLTime来作为version,解决meta版本不一致问题,及时失效meta缓存并重新加载。
3. 对orc和parquet都支持了文件元数据的缓存,并根据hive文件的lastModifiedTime及时失效过期缓存。
4. 基于alluxio local cache进行了改造,支持基于文件的lastModifiedTime来判断数据是否失效,并及时清理过期page。
5. 因为alluxio local cache目前只支持挂载一块磁盘,实现了基于剩余空间的VolumeChoosingPolicy来对多块磁盘进行存储管理。
6. 每次Presto worker启动后必须恢复完所有page后才开始对外提供服务,这样尽可能保证Page的缓存命中率。
我们拿了一些query进行测试,如下图所示,部分query能够得到数倍性能提升。
PS:如果有用到viewfs来做hdfs的federation,那么应该会遇到一些问题,大家可以参考:
https://github.com/prestodb/presto/pull/17390
https://github.com/prestodb/presto/pull/17365
https://github.com/prestodb/presto/pull/17367
5.5 支持struct 字段类型下推
trino在高版本(334,https://github.com/trinodb/trino/pull/2672) 支持struct字段类型的下推优化,包括project和filter的下推,我们AI团队经常会用到嵌套数据类型,这个优化能够给查询带来不小的提升,我们将整个功能backport到我们自己的版本,如下图所示,有和没有deference下推,执行计划的project和filter有巨大的差别,实际测试下来有的sql shuffle数据量能够达到几十上百倍的减少,查询性能也能够提升数倍。
测试语句:
SELECTA.ip,B.info.midFROMtmp_bdp.tmp_struct_test AJOIN tmp_bdp.tmp_struct_test B on A.ip = B.ip
其中info是struct类型,包含9个String类型字段,执行效果见下图,Scan input size和shuffle size大幅度减少

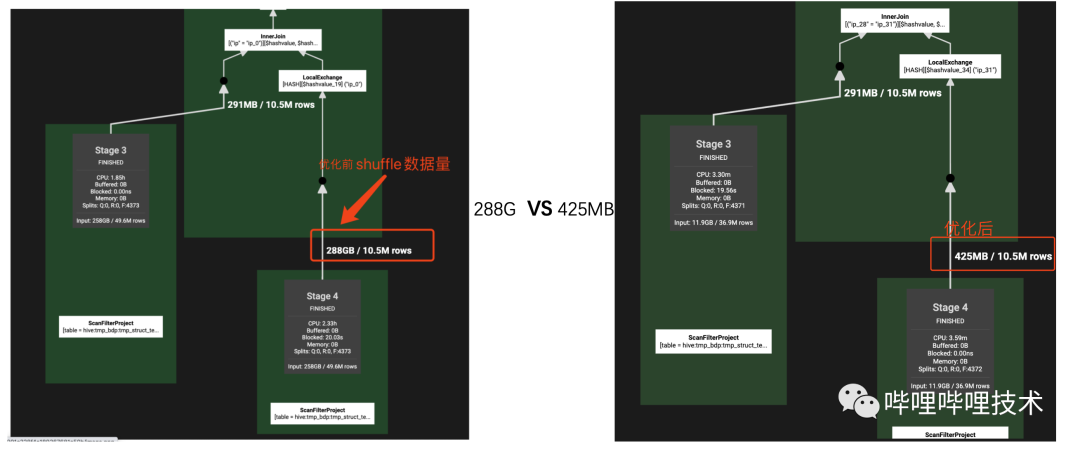
目前我们只支持struct字段类型下推,还无法做到map和array类型的下推,而我们线上存在不少array中嵌套struct的数据类型,大部分sql通过unnest来对array进行展开,之后目标是继续深入研究针对array和map的下推支持。
5.6 JDK版本从8升级到zulu JDK 11
我们一开始想在升级JDK同时将垃圾收集器切换到ZGC来降低单次 GC的时间,提升集群整体性能。benchmark测下来也确实ZGC效果最好,但是因为JDK11的zgc没有class unloading功能,导致presto codegen出来的大量class无法回收导致metaspace泄漏,所以升级了JDK11依然使用G1收集器。
升级后,JDK11 g1收集器gc吞吐量是98%,相比JDK8有2个点的提升。同时JDK11提供了一些新的监控和诊断工具,比如JFR能帮助我们后续进一步分析JVM运行性能和定位问题。
JDK11 ZGC收集器性能指标:
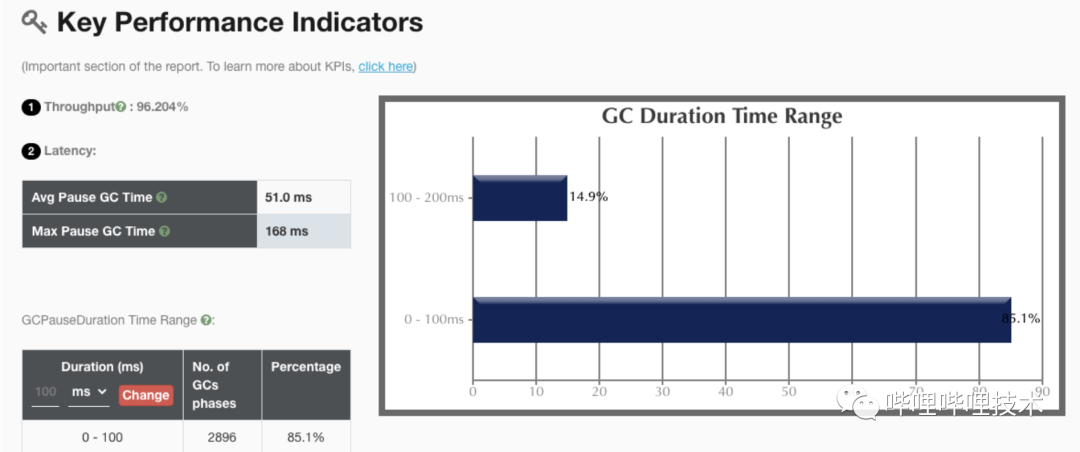
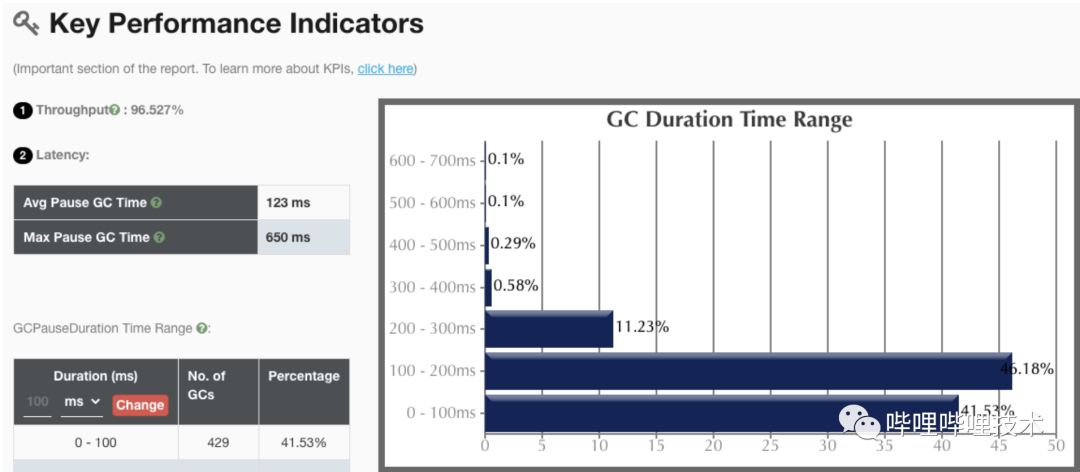
JDK8 G1收集器关键性能指标:
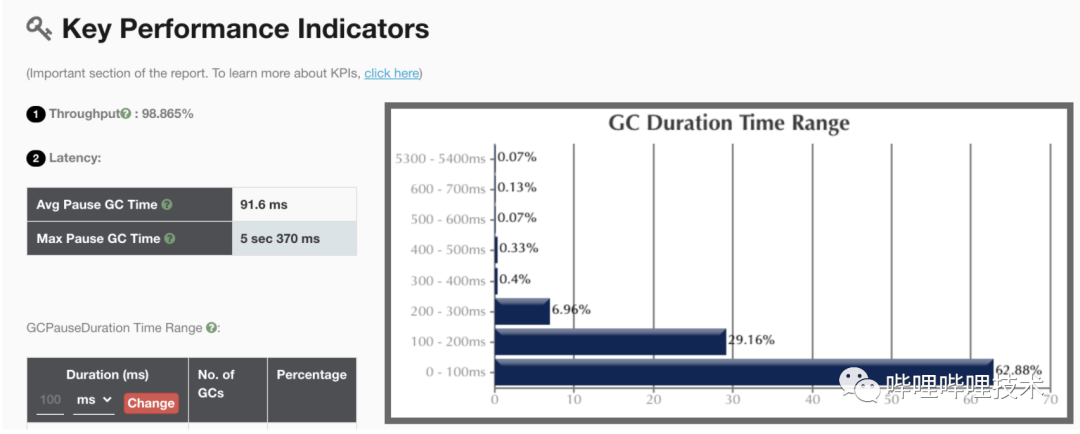
JDK11 G1收集器关键性能指标:
5.7 支持动态过滤
动态过滤是指作业在运行时动态生成过滤器的功能(简称Dynamic Filter),适用于高选择性Join场景,以此减少IO以及后续的计算量。目前,trino高版本已支持动态过滤,我们借鉴了trino高版本的动态过滤,实现了BroadcastJoin,Dynamic Partition Pruning以及Partitioned Join。
整体架构:
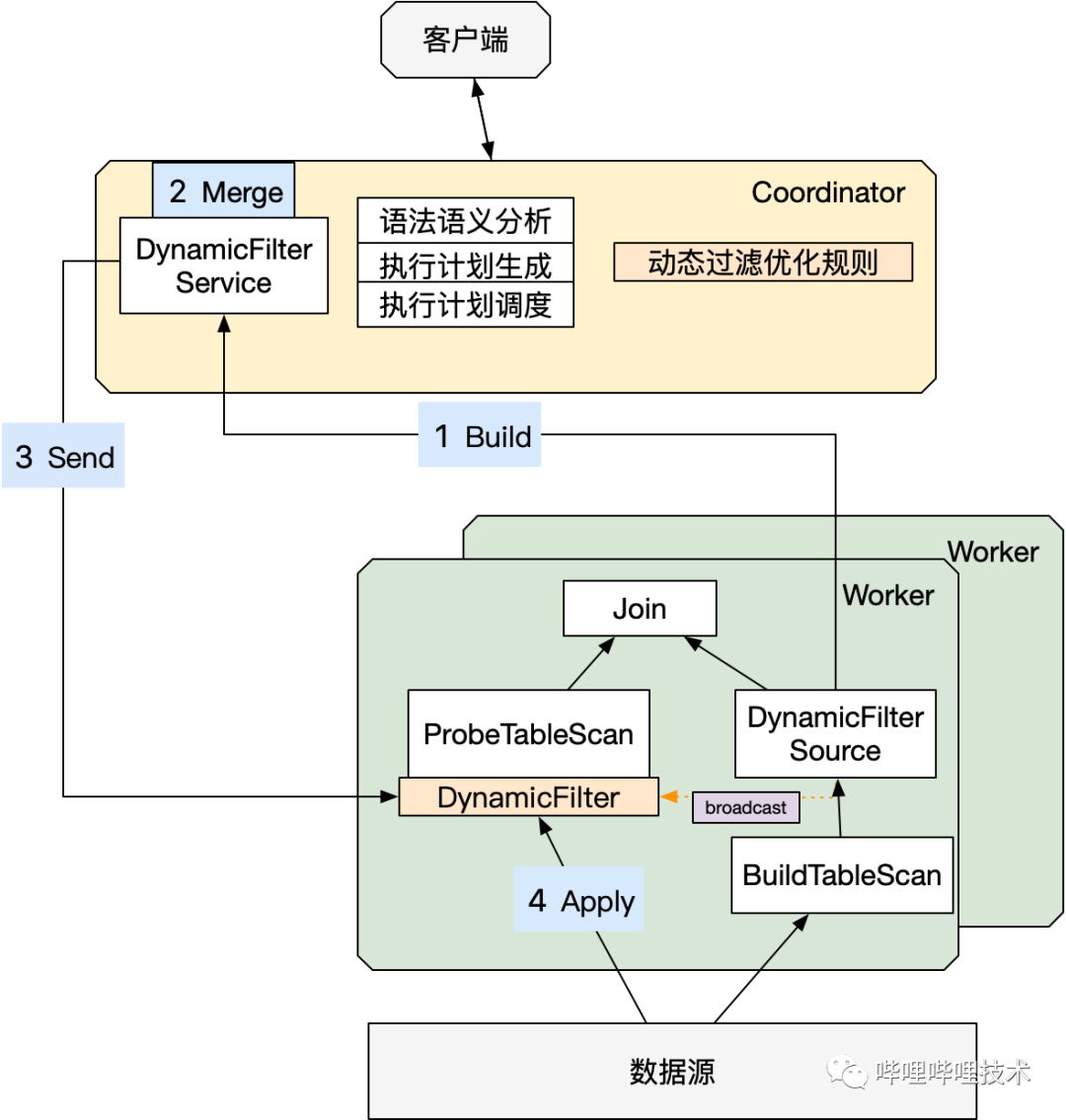
具体改造如下:
-
Coordinator端新增PredicatePushDown优化器下推DynamicFilter信息。
-
Worker新增“Collect”算子,通过PageSourceProvider下推DynamicFilter到源文件读取。
-
Worker新增上报DynamicFilter信息。
-
Coordinator新增DynamicFilterService,对Worker汇报上来的DynamicFilter信息做整合,再将整合后的DF信息下发到各个worker做过滤。
改造效果:
-
对特定Dynamic Partition Pruning的SQL,效果明显:

左表读数据量从6.36T减少到358GB
2. benchmark效果:
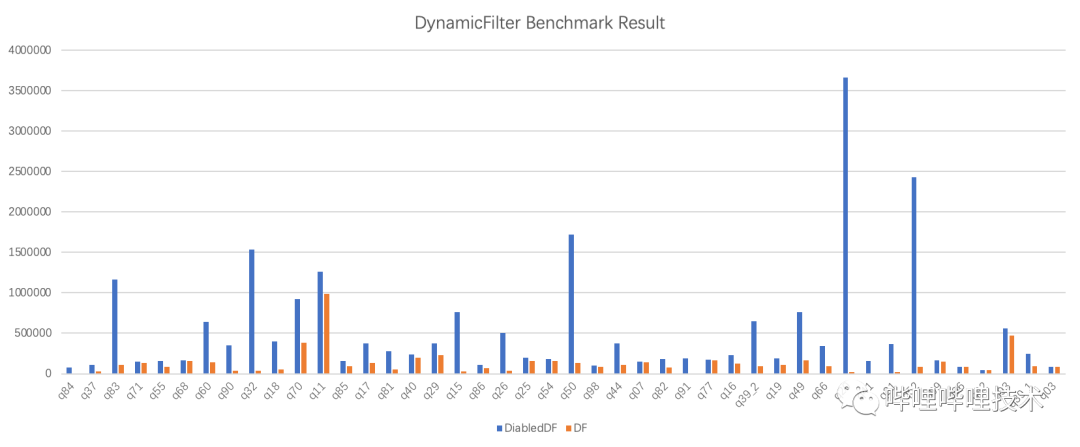
其中,benchmark中效果好的Query主要由以下两个因素决定:
-
Query类型为高选择性join场景。
-
底层文件的过滤性能,例如orc文件写入的时候如果有sort by字段,stripe过滤时会更高效;或者底层orc文件如果开启了bloomFilter,也会提高过滤效果。
总结:
-
动态过滤适用于Hive Connector,支持OrcFile/Parquet,下推到数据源。
-
支持分区表的分区裁剪,非分区表的行过滤。
-
支持Join策略包括Broadcast Join/Dynamic Partition Pruning/Partitioned Join。
-
支持Join语法包括InnerJoin/SemiJoin。
5.8 其他改进
-
针对小文件产生split数过多的问题,将它们合并成一个大split进行调度,减少split数和调度压力。
-
HDFS读请求接入Observer Namenode,减少因Active Namenode slow rpc造成的影响。
-
开启FileStatus cache, 减少对NN的RPC访问压力。
-
针对大查询,开启spill功能,将page写入本地磁盘,缓解内存压力。
-
Coordinator侧查询执行计划缓存,减少生成和优化plan的时间。
-
多个stage的语句自动转换成phased调度执行方式,降低集群压力。
-
当Hive分区或者表的Stats信息不准的情况下,比如row_count为0,但size不为0,Presto在做Join选择的时候会优先选择Broadcast join,如果是一张大表,那么整个查询效率非常低,我们在CBO计算模块中,如果row_count为0,那么我们通过拿分区的datasize信息乘以一个默认的膨胀比来作为该表或分区的scan数据量,然后通过该值来进行CBO的计算,确保更准确的选择更合适的Join类型。
6
未来规划
-
Presto集群支持HPA, 低峰时自动对Presto Worker节点进行优雅缩容给到Yarn混部集群,从而提升机器利用率,达到降本增效目的。
-
启发式索引,在读数据前提前过滤Split,orc的文件和stripe,减少读数据量。
-
支持自动物化视图,根据用户常见的语句,自动创建和刷新物化视图,无需用户操作和管理开销,查询时改写语句复用先前物化的数据。
-
复杂数据类型Array/Map读优化。
-
基于HBO,ETL大查询自动路由到Presto on spark,缓解Presto集群压力,提升作业成功率。
我们会和业界同行和开源社区保持密切技术交流,在服务好内部用户作业的同时,也会积极反馈社区,共建社区生态。
本文转载自离线团队 哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/9_lSIFSw5o8sFC8foEtA7w。