
作者:群核科技大数据团队
本文主要介绍群核科技大数据团队基于新一代极速全场景 MPP 数据库 StarRocks,在数据服务体系和数据应用场景中的实践和探索。
企业的原始数据通常来源于日志埋点系统、业务数据库、三方接口等。随着群核科技的业务规模越来越大,数据规模和体量也急剧膨胀,每天的增量数据接近 1TB。
企业通常基于 CDH/Apache Hadoop(以下简称 Hadoop)等大数据分布式计算框架和数据集成工具,构建离线的数据仓库,并对数据进行适当的分层、加工、建模和管理。
查询的时效性要求高,数据存储最终会通过数据同步工具回流到 MySQL、ElasticSearch、Presto、Apache HBase(以下简称 HBase) 等数据库或计算引擎中。
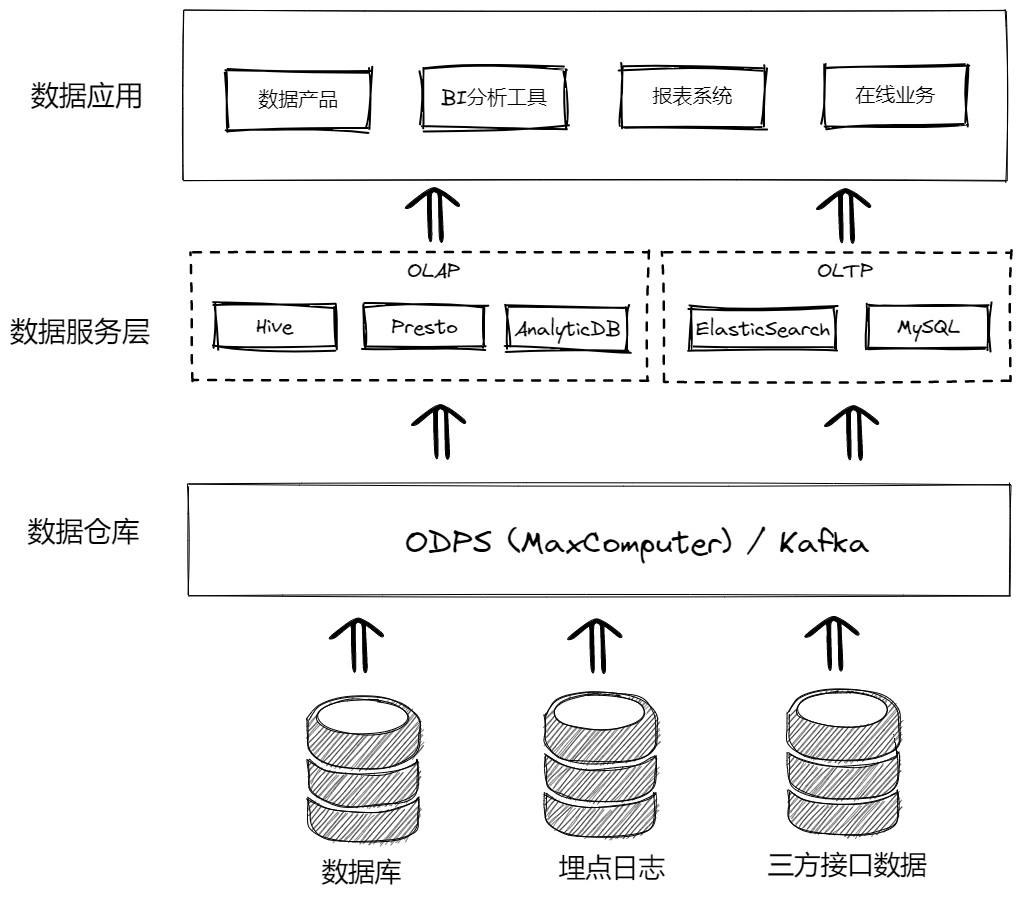

由于数据膨胀,尤其是酷家乐设计工具使用场景下产生的模型/方案/渲染使用明细数据,离线实时计算任务需要对 TB 级别的数据进行调度、聚合、计算,在数仓里沉淀出大量明细表、聚合表和最终的数据报表。
数据服务层的愿景是开放数仓能力,针对不同的应用场景(数据规模、QPS、UDF 支持、运维成本等),建立统一的数据服务出口,在底层计算引擎的选型上主要基于以下考量:
-
大数据量、低 QPS:使用 Apache Hive(以下简称 Hive) + Presto 等基于 Hadoop 生态的离线批任务计算框架和 MPP 数据库来解决。
-
小数据量、高 QPS:使用 MySQL、ElasticSearch、HBase、MongoDB 等关系型/非关系型数据库来解决。
在目前的数据架构下,我们遇到如下问题和挑战:
-
离线/实时 ETL 任务过多,处理逻辑大部分为简单聚合/去重,导致聚合表数量庞大,运营和运维上的成本增加;
-
针对中等数据量、中等 QPS 的查询场景,如何能兼顾数据规模的同时,有较友好的查询耗时响应、延迟小于 200ms;
-
大数据量下插入、更新的实时数据场景的支持,例如:用户画像、实时 DMP、用户路径、监控数据大盘等。
StarRocks 是基于 MPP 架构的新一代极速全场景 MPP 数据库,自带数据存储,整合了大数据框架的优势,支持主键更新、支持现代化物化视图、支持高并发和高吞吐的即席查询等诸多优点,能出色解决我们遇到的问题。

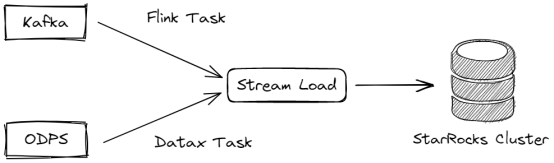
在生产环境中,StarRocks 主要被作为离线/实时数据的 OLAP 数据库使用。酷家乐的离线数据主要存储于 ODPS,通过 DataX 任务批量同步数据,实时数据主要存储于 Apache Kafka(以下简称 Kafka) 中,基于 Kafka 的流式处理任务写入。
DataX 任务使用的 StarRocksWriter 插件及 Flink 任务使用的 Fink-connector-starrocks 插件均通过 Stream Load 的导入方式写入 StarRocks 集群。
基于 StarRocks 的统一 OLAP
数仓内的数据业务存在如下痛点:
-
每日有上亿规模的超大增量明细表数据,需要统计按日、周、月、季、年等粒度等统计数据;
-
商家账号使用、模型使用、方案渲染在任意日期区间的聚合值、累计值、去重值。
这些前端查询需求,都需要保证低延迟。在没有引入 StarRocks 之前,我们底层采用 MySQL 或者 Presto on HDFS 方式存储存明细表/聚合表以支撑应用查询。
当 MySQL 处理上亿规模的数据,无论使用分库分表、分区表,还是集群化部署的 PolarDB 方案,都会存在慢查询、数据库扛不住、运维困难的窘境;
Presto on HDFS 的方案更偏向于分析型数据业务,虽然能存储海量数据,通过水平扩展来获得不错的计算能力,但无法满足在线业务的高 QPS 需求,这一点非常致命。
使用了 StarRocks 后的业务效果如下:
-
支撑了在线数据查询+数据分析业务,能服务于对内运营+对外商业化数据产品,在线业务查询 P95 耗时在毫秒级别,分析型业务查询 P95 耗时在秒级别;
-
支持 10 亿规模的明细表查询,月、季、年度统计数据能现场聚合、去重,查询效率基本能控制在500ms;
-
经过 Colocate Join 特性优化,千万级别的多表 Join 和 Union 查询的响应速度在秒级别。
StarRocks 支持下的实时链路探索
在探索实时数据链路方案中,StarRocks 显示出了如下优势:
-
实时数据写入:目前 StarRocks 支持通过 HTTP 使用 Stream Load 方式实现秒级到分钟级别微批写入和使用 Routine Load 方式实现 Kafka To StarRocks 的秒级延迟导入,此外还支持使用 Flink CDC 方式实时同步 TP 数据库到 StarRocks,多种实时数据同步方案带来了极大的操作灵活性,使延迟敏感度要求不高的业务和实时业务均能很好得到满足。
-
流批融合:实时数据和离线数据在 StarRocks 中能更好地进行融合,灵活支撑应用,通过 StarRocks 动态分区的功能很好满足了数据存储清理需求。
-
SQL Online Serving:高效的 SQL 即席查询能力,能够支持 SQL 标准,兼容业界流行的 MySQL 规范,支撑业务灵活复杂的访问,可以提高取数开发的效率。
总结和规划
群核科技大数据团队通过引入 StarRocks 生产集群,解决了数据服务层单表亿级别规模、高 QPS 数据场景下引擎的空白,直接开放明细表准实时查询的能力。
新的 OLAP 方案给上层数据业务和 BI 系统提供了更多的选择和自由度,同时大量减少数仓中 ETL 任务、聚合表、报表,降低了数仓 ETL 的运维压力和维护成本。
接下来,我们在 StarRocks 的应用和实践方面还有不少规划:
-
除了 Duplicate 数据模型,未来会将符合的数据场景迁移至 Aggregation 模型和物化视图,进一步降低数仓开发维护成本;
-
更多数据应用层的场景接入 StarRocks,例如人群更新、用户画像服务、用户行为路径分析等,进一步探索 StarRocks 的实时数据更新等特性;
-
考虑使用多云架构,自主可控的数仓架构可以灵活的在多云间切换迁移,降低单一来源依赖,控制成本提高可用性。
关于 StarRocks
StarRocks 成立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 110 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
本文转载自,原文链接:。