▼ 关注「Apache Flink」,获取更多技术干货 ▼摘要:本文整理自阿里巴巴高级技术专家林东、阿里巴巴技术专家高赟(云骞)在 Flink Forward Asia 2021 核心技术专场的演讲。主要内容包括:
面向实时机器学习的 API
流批一体的迭代引擎
Flink ML 生态建设
一、面向实时机器学习的 API
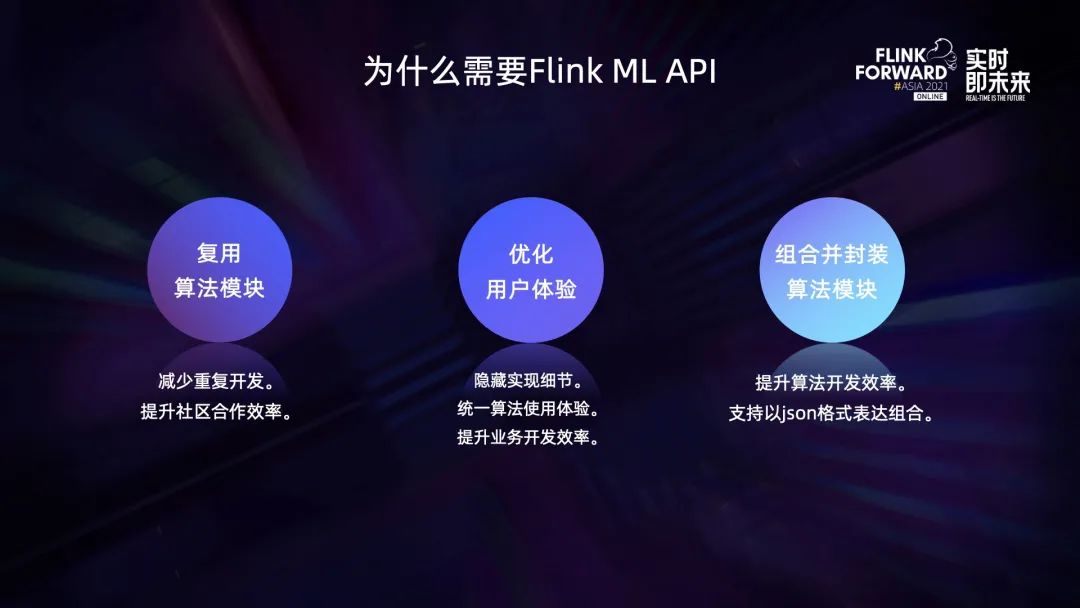
Flink ML API 指的是提供给用户使用算法的接口。通过把所有算法打包为统一的 API 提供给用户,让所有使用者的体验保持一致,也能降低学习和理解算法的成本,此外算法之间也可以更好地交互和兼容。
举个例子,在 Flink ML API 中提供一些基础的功能类,通过使用这些功能类可以把不同算子连接组合成一个高级的算子,可以大大提高了算法的开发效率。同时,通过使用统一的 Table API,让所有的数据都以 Table 格式进行传输,可以使得不同公司开发的算法能够互相兼容,降低不同公司重复开发的算子的成本,提升算法合作的效率。
之前版本的 Flink ML API 还是存在不少痛点。
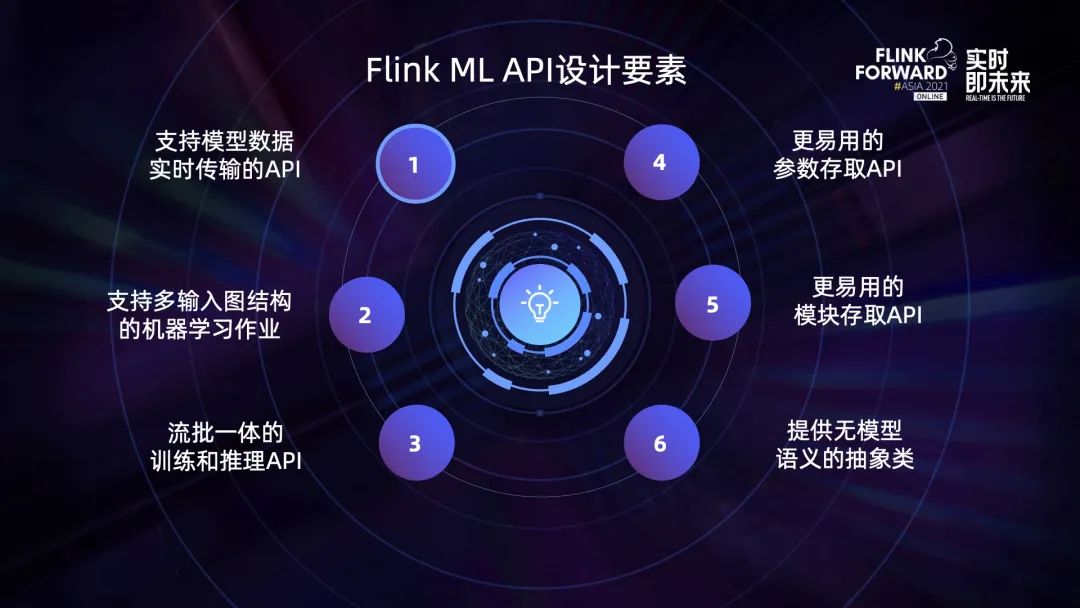
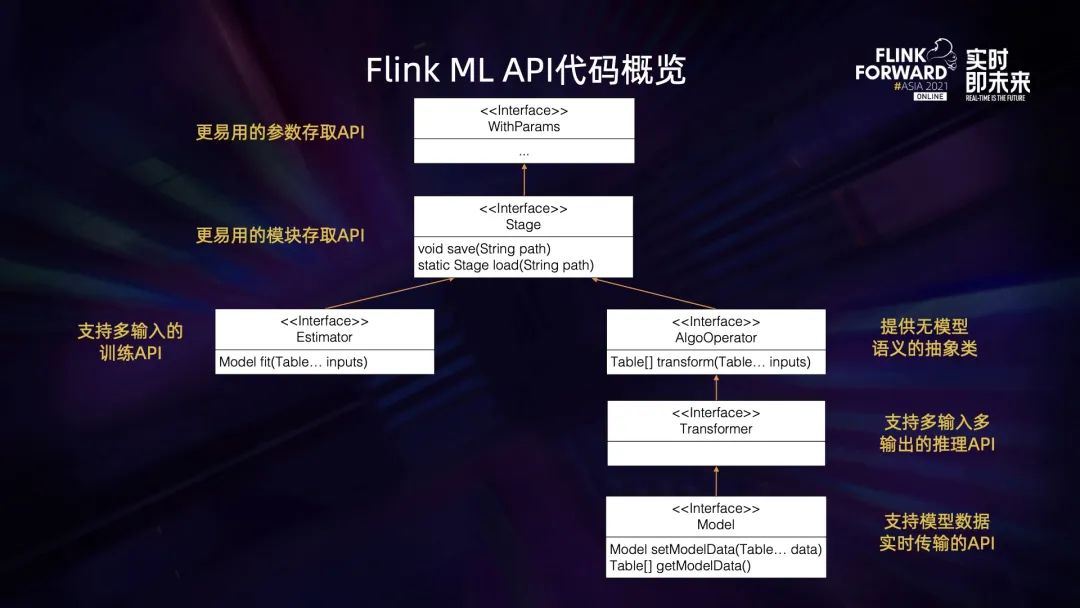
首先是表达能力方面。之前的 API 的输入只支持单个 Table 的形式,无法表达一些常见的算法逻辑。比如有些训练算法的输入表达是一张图,把数据通过不同的 Table 传进来,这种情况下单个 Table 输入的接口就不适用了。再比如有些数据预处理的逻辑需要将多个输入得到的数据进行融合,用单个 Table 输入的 API 也不适合。因此我们计划把算法接口扩展为支持多输入多输出。
其次是实时训练方面。之前的 API 无法原生支持实时机器学习场景。在实时机器学习中,我们希望训练算法可以实时产生模型数据,并将模型数据以流的方式实时传输到多个前端服务器中。但是现有的接口只有一次性的训练和一次性的推理 API,无法表达这种逻辑。
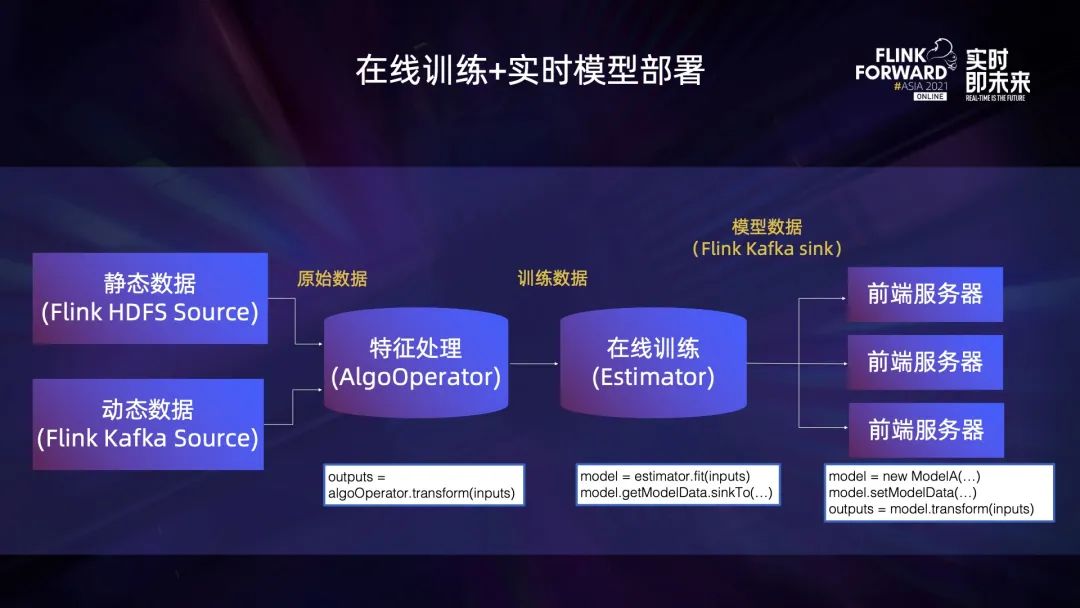
上图是一个比较简化但经典的实时机器学习场景。这里的数据来源主要有两个,静态数据来自于 HDFS,动态数据来自于 Kafka。由 AlgoOperator 读取来自以上两个数据源的数据,将它们拼接之后形成一个 Table 输入到 Estimator 逻辑。Estimator 读取刚才拼接得到的数据并产生一个 Model,然后可以通过 getModelData() 拿到代表模型数据的 Table。再通过 sink() API 将这些数据传输到 Kafka topic。最后在多个前端服务器上面运行程序,这些程序可以直接创建一个 Model 实例,从 Kafka 中读出模型数据形成一个 Table,再通过 setModelData() 把这些数据传递给 Model,使用得到的 Model 做在线推理。
在支持在线训练和在线推理之后,我们进一步提供了一些基础组件,方便用户通过简单的算子构建更复杂算子,这个组件便是 FLIP-175 提供的 GraphBuilder。假设用户的输入也是与上文一致的两个数据源,最终输出到一个数据源。用户的核心计算逻辑可以分为两块,第一块是数据预处理,比如特征拼接,把两个数据源的数据读进来之后做整合,以 Table 的形式输出到 Estimator,执行第二块的训练逻辑。我们希望先执行训练算子,得到一个 Model。然后将预处理算子和 Model 连接,表达在线推理逻辑。用户需要做的只是通过 GraphBuilder API 将上述步骤连接进行,不需要专门为在线推理逻辑再写一遍连接逻辑。GraphBuilder 会自动从前面一个图生成,并与后面图中的算子形成一一对应的关系。AlgoOperator 在训练图中的形式是直接转换为推理图中的算子,而 Estimator 在训练图中得到的 Model 会成为推理图中对应的节点,通过将这些节点相连,便得到了最后的 ModelA,最终用作在线推理。
二、流批一体的迭代引擎
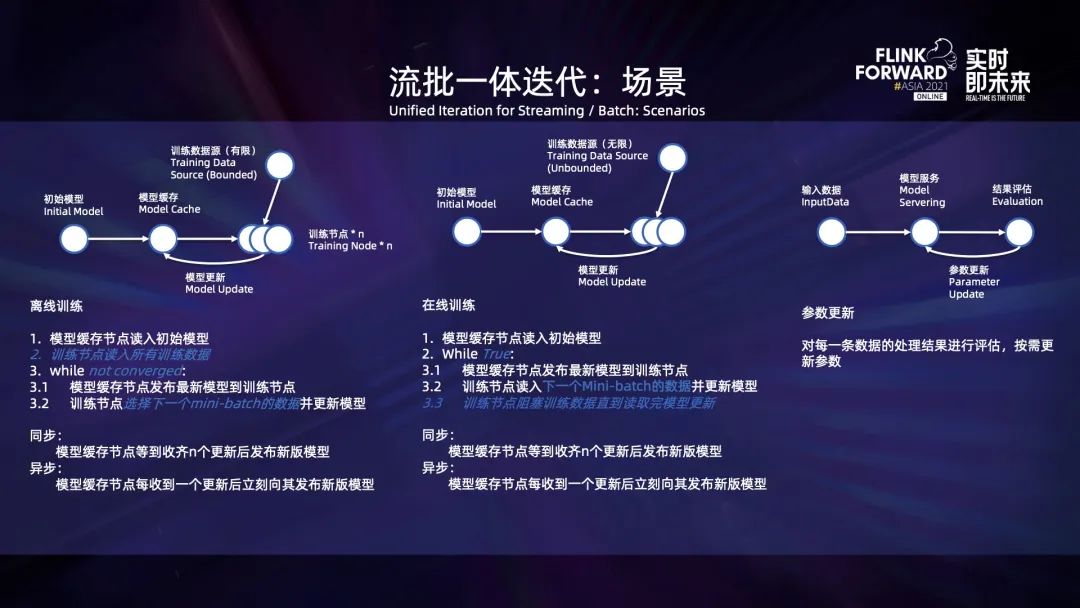
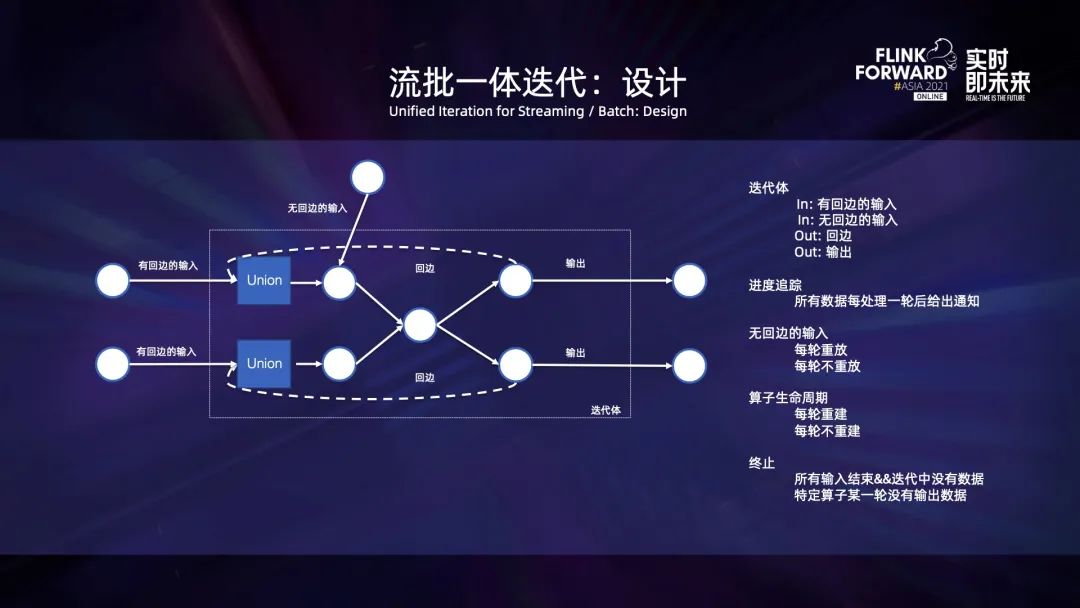
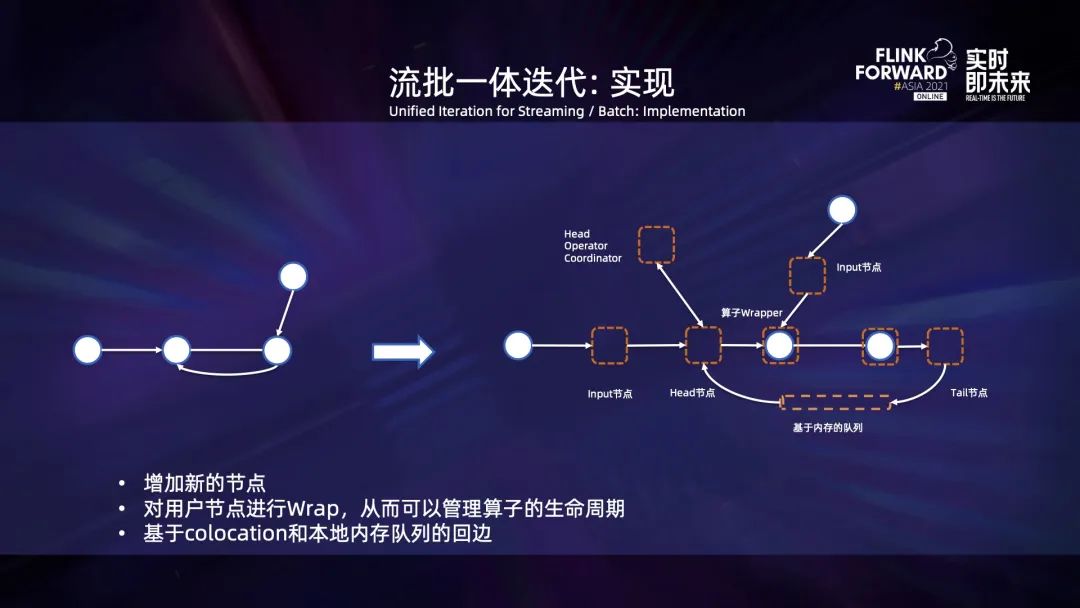
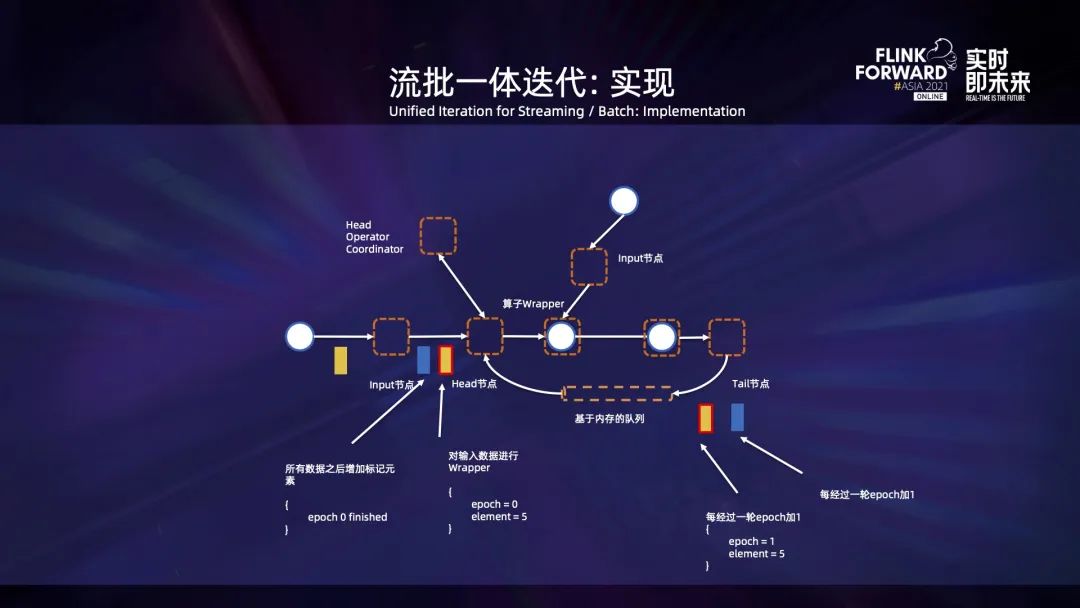
Flink 是一个基于 Dag 描述执行逻辑的流批一体的处理引擎,但是在许多场景下,尤其是机器学习图计算类型的应用中,用户还需要数据迭代处理的能力。例如,一些算法的离线训练、在线训练以及模型部署后根据结果动态调整模型参数的场景,都需要数据迭代处理。由于实际的场景同时会涵盖离线和在线处理的案例,因此需要在迭代这一层能够同时支持离线和在线处理。
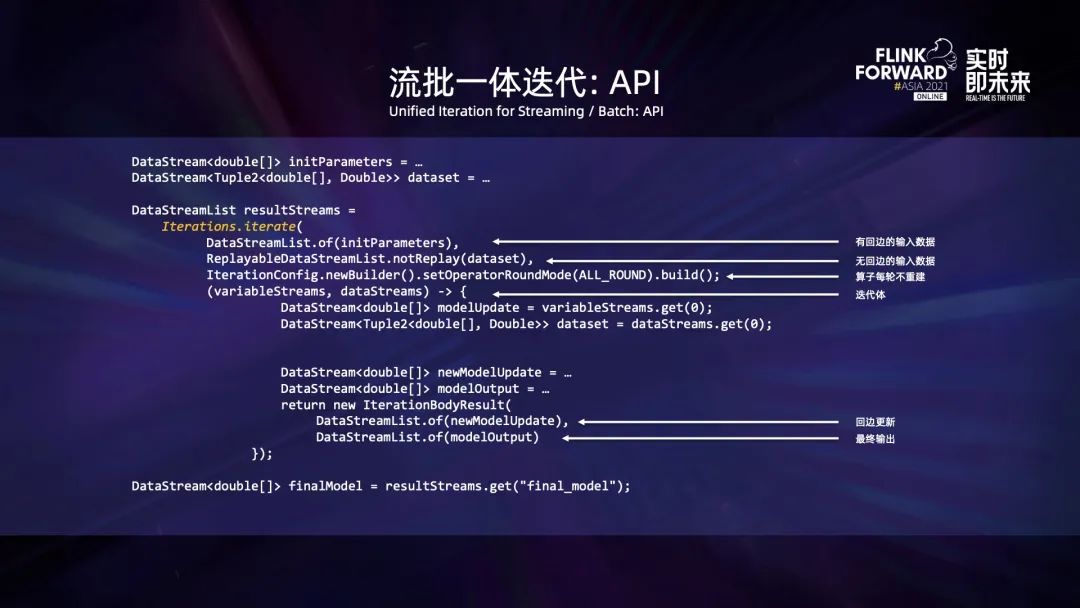
上图是使用迭代 API 来构建迭代的例子。用户需要指定有回边和无回边的输入列表、算子是否需要每轮重建以及迭代体的计算逻辑的等。对于迭代体,用户需要返回回边对应的数据集以及迭代的最终输出。
publicstaticclassModelCacheFunctionextendsProcessFunctionimplementsIterationListener {private final double[] parameters = newdouble[N_DIM];publicvoidprocessElement(double[] update, Context ctx, Collector output){// Suppose we have a util to add the second array to the first. ArrayUtils.addWith(parameters, update); }voidonEpochWatermarkIncremented(int epochWatermark, Context context, Collector collector){if (epochWatermark collector.collect(parameters); } }publicvoidonIterationEnd(int[] round, Context context){ context.output(FINAL_MODEL_OUTPUT_TAG, parameters); } }