
作者:vivo 互联网服务器团队- Hao Chan
随着互联网业务的快速发展,基础设施的可用性也越来越受到业界的关注。内存发生故障的故障率高、频次多、影响大,这些对于上层业务而言都是不能接受的。
本文主要介绍EDAC(Error Detection And Correction)框架在内存预测方面的应用。首先介绍了EDAC应用的背景,接着是EDAC的原理介绍,然后通过EDAC安装——配置——测试过程详细地介绍了EDAC在vivo服务器上的应用,最后提出了内存预测使用EDAC的方案总结以及服务器RAS(Reliability, Availability and Serviceability)应用减小硬件故障对系统的影响的展望。
一、背景介绍
随着互联网业务的快速发展,基础设施的可用性也越来越受到业界的关注。然而硬件故障一直以来都是一种普遍存在的现象,由于硬件故障而造成的损失往往是巨大的。在服务器各个部件中,除硬盘故障以外,内存故障是第二大常见的硬件故障类型。并且服务器内存的数量众多,vivo的内存数量达到40w+条,内存故障造成的最严重的后果是会直接导致系统崩溃,服务器宕机,这些对于上层业务而言都是不能接受的。
内存故障可分为UCE(Uncorrectable Error)和CE(Correctable Error)。当硬件侦测到一个错误,它会通过两种方式报告给CPU的。其中一种方式是中断,这种情况如果是UCE也就是不可纠正错误,则可能会导致服务器立马宕机。如果是CE,即可纠正错误,硬件会利用一部分资源对该错误进行修复,而当内存CE累计过多,无法进行自我修复时,则会产生UCE,造成系统宕机重启。因此,我们需要尽早地发现CE过多的内存条,及时进行更换,避免造成重大的损失。
以往内存故障大多是通过MCE(Machine Check Exception)log 和BMC记录的SEL (System Error Log)日志结合去发现定位故障的,而这些最大的问题是不能够提前发现内存问题,往往是服务器宕机重启后才被动发现的。除此之外还存在以下几个方面的问题:
-
MCE日志很难直接定位到故障内存槽位。
-
没有直观的CE/UCE错误计数。
-
无法根据内存条上CE/UCE的数量判断内存的健康状况。
针对以上问题,我们需要寻找别的解决方案。这时EDAC便出现在我们的视野,它能够完美地解决上面所说的所有问题,并且能够实现内存CE故障的主动发现,提前发现内存问题。
本文将主要介绍EDAC的原理以及如何通过它实现的故障预测。
二、EDAC 原理介绍
EDAC(Error Detection And Correction)是Linux系统的错误检测和纠正的框架,它的目的是在linux系统运行过程中,当错误发生时能够发现并且报告出硬件错误。EDAC由一个核心(edac_core.ko)和多个内存控制器驱动模块组成,它的子系统有edac_mc、edac_device、PCI bus scanning,分别是负责收集内存控制器,其他控制器(比如L3 Cache控制器)以及PCI设备所报告的错误。
这里主要讲述EDAC子系统edac_mc是如何收集内存控制器的错误。内存CE以及UCE是edac_mc class获取的主要错误类型,它主要涉及了以下几个函数:
-
【edac_mc_alloc()】:使用结构体mem_ctl_info来描述内存控制器,只有EDAC的核心才能接触到它,通过edac_mc_alloc()这个函数去分配填充结构体的内容。
-
【edac_device_handle_ce()】:标记CE错误。
-
【edac_device_handle_ue()】:标志UCE错误。
-
【edac_mc_handle_error()】:向用户空间报告内存事件,它的参数包括故障点的层次结构以及故障类型,累计的相关UCE/CE错误计数统计。
-
【edac_raw_mc_handle_error()】:向用户空间报告内存事件,但是不做任何事情来发现它的位置,只有当硬件错误来自BIOS时,才会被edac_mc_handle_error()直接调用。
那么EDAC是如何控制和报告设备故障的呢?它又是如何将故障定位以及记录到对应的内存条上的呢?
Linux 是通过sysfs文件系统来展示内核设备的层次关系,EDAC则通过它来控制和报告设备故障。EDAC是通过抽象出来的内存控制器模型,将故障定位到对应的内存条上,这主要也是与内存在系统中的排列结构相关。CPU对应的每个MC(memory controller)设备控制着一组DIMM内存模块,这些模块通以片选行(Chip-Select Row,csrowX)和通道(Channel,chX)的方式排布,在系统中可以有多个csrow和多个通道。
通过下列路径可以查看相关文件:
# ls /sys/devices/system/edac/mc/mc0/csrow0/ce_count ch0_ce_count ch0_dimm_label ch1_ce_count ch1_dimm_label dev_type edac_mode mem_type power size_mb subsystem ue_count uevent
部分文件的用途如下表所示:
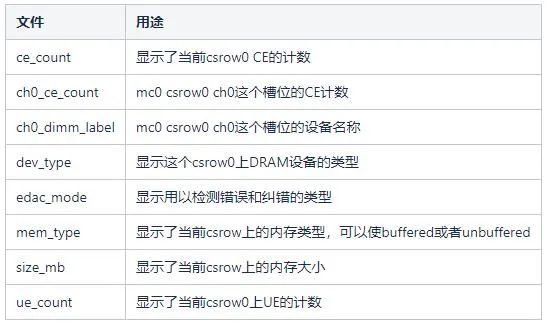

EDAC如果发现硬件设备控制器报告的是UE事件,并且控制器要求UE即停机,则会重启系统。控制器检查到CE事件后,可以看作对未来UCE事件的预测。我们可以通过一些屏蔽手段或者更换内存条减少UE事件以及系统宕机的可能性。
三、EDAC 的应用
EDAC在vivo 现网中的应用过程主要分为以下几步:
(1)EDAC在Linux系统中的支持
EDAC在Linux 2.6.16以上的内核中以及系统发行版都已经得到了支持,但是内核中edac的驱动模块却有很多,不同的系统版本支持的驱动模块却不尽相同,可以通过以下方式查看系统支持哪些驱动模块。
# ls /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/amd64_edac_mod.ko.xz edac_core.ko.xz i3000_edac.ko.xz i5000_edac.ko.xz i5400_edac.ko.xz i7core_edac.ko.xz ie31200_edac.ko.xz skx_edac.ko.xze752x_edac.ko.xz edac_mce_amd.ko.xz i3200_edac.ko.xz i5100_edac.ko.xz i7300_edac.ko.xz i82975x_edac.ko.xz sb_edac.ko.xz x38_edac.ko.xz
那么这些驱动模块之间有什么区别?我们又应该怎样选择呢?拿sb_edac与skx_edac进行说明,我们先来看一下它们描述。
# modinfo sb_edacfilename: /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/sb_edac.ko.xzdescription: MC Driver for Intel Sandy Bridge and Ivy Bridge memory controllers - Ver: 1.1.1...# modinfo skx_edacfilename: /lib/modules/3.10.0-693.el7.x86_64/kernel/drivers/edac/skx_edac.ko.xzdescription: MC Driver for Intel Skylake server processors...
通过查看描述我们发现,原来驱动模块是和CPU的产品架构有关,安装不匹配的模块会出现 edac-util: Error: No memory controller data found 这样的报错。经过我们测试发现,一般而言,如果CPU的产品架构支持的驱动模块存在的话,系统会默认安装支持的驱动。
(2)配置内存槽位与物理槽位对应关系
通过sysfs文件系统我们可以看到哪个CPU的哪个内存控制下的哪个通道的哪条内存的CE计数,但是它对应的系统下的哪一个内存呢,毕竟我们服务器日常的运维,经常看到的是系统槽位名称,那么它们的关系是怎样的呢?
经过查看edac-util的源代码结构发现,它提供了labels.db这个配置文件,去存储服务器内存的系统槽位与物理槽位对应关系。
编写这个文件的时候,我们需要知道内存是如何在服务器上是怎么插,并且知道它对应的是系统中的槽位名称,不同服务器型号系统槽位的名称不同。一般能使内存性能发挥最大的插法,总结起来就是对称插法,并且先插离CPU远的通道,每个通道里面先插离CPU远的槽位。
配置完成后,如何去检查是否配置正确呢,主要分为两步:
① 使用edac-ctl查看SYSFS CONTETS条数是否正确
② 用dmidecode -t memory查看内存的名称是否一致
这里我们还遇到一个rpm包的问题:对于厂商的主板的model name前后有多个空格的情况,edac-ctl无法识别到主板的model name,lables.db无法注册成功。最后我们修改了edac-utils包的源代码,重新进行了打包。
vim edac-utils-0.9/src/util/edac-ctl# 新增了两行代码,将verdor以及model两边多余的空格去掉$vendor =~ s/^s+|s+$//g;$model =~ s/^s+|s+$//g;
(3)测试与验证
安装配置完成后,就到了测试验证环节了,要怎样去验证EDAC的正确性,保证CE错误记录到了对应的内存条上呢?我们可以使用APEI Error inject做一些错误注入的测试。
APEI Error inject 它的原理是依赖APEI(ACPI Platform Error Interface),它的结构中有四张表:
-
BERT(Boot Error Record Table):主要用来记录在启动过程中出现的错误
-
ERST(Error Record Serialization Table) :用来永久存储错误的抽象接口,存储各种硬件或平台的相关错误,错误类型包括 Corrected Error(CE),Uncorrected Recoverable Error(UCR),以及 Uncorrected Non-Recoverable Error,或者说Fatal Error。
-
EINJ(Error Injection Table):主要作用是用来注入错误并触发错误,是一个用来测试的表
-
HEST(Hardware Error Source Table):定义了很多错误源和错误类型。定义这些硬件错误源的目的在于标准化软硬件错误接口的实现。
这里是通过debugfs向内核APEI结构中的EINJ表注入内存错误来进行测试,debugfs是一种用于内核调试的虚拟文件系统,简单来说就是可以通过debugfs映射内核数据到用户空间,使用户能够修改一些数据进行调试。
方法步骤如下:
# 查看是否存在EINJ表# ls /sys/firmware/acpi/tables/EINJ# grep /boot/config-3.10.0-693.el7.x86_64CONFIG_DEBUG_FS=yCONFIG_ACPI_APEI=yCONFIG_ACPI_APEI_EINJ=m# 安装einj# modprobe einj# 查看内存地址范围,这一步是因为/proc/iomem这个文件记录的是物理地址的分配情况,有些内存地址是系统预留存放以及其他设备所占用的,无法进行错误注入。# cat /proc/iomem | grep "System RAM"00001000-000997ff00100000-69f79fff6c867000-6c9e6fff6f345000-6f7fffff100000000-407fffffff# 查看内存页大小# getconf PAGESIZE4096 即4KB# 进入edac错误注入目录# cat /proc/mounts | grep debugfsdebugfs /sys/kernel/debug debugfs rw,relatime 0 0# cd /sys/kernel/debug/apei/einj/# 查看支持注入的错误类型# cat available_error_type0x00000008 Memory Correctable0x00000010 Memory Uncorrectable non-fatal0x00000020 Memory Uncorrectable fatal# 写入要注入的错误的类型echo 0x8 > error_type# 写入内存地址掩码echo 0xfffffffffffff000 > param2# 写入内存地址echo 0x32dec000 > param1# 写入0x0,若为1,则会跳过触发环节echo 0x0 > notrigger# 写入任何整数触发错误注入,这是错误注入的最后一步echo 1 > error_inject# 查看日志# tail /var/log/messagexxxxxx xxxxxxxx kernel: [2258720.203422] EDAC MC0: 1 CE memory read error on CPU_SrcID#0_MC#0_Chan#0_DIMM#1 (channel:0 slot:1 page:0x32dec offset:0x0 grain:32 syndrome:0x0 - err_code:0101:0090 socket:0 imc:0 rank:0 bg:0 ba:3 row:327 col:300)# 使用edac-util -v查看,可以看到对应的内存条上新增了CE计数
四、 总结与展望
-
EDAC可以明确的获取到服务器的每条内存上的CE计数,我们可以通过CE计数去设定阈值,分析CE计数曲线等,结合其他MCE log 、SEL等对内存进行健康状况评估,进行内存预测。EDAC在vivo服务器全量上线过程以来,累计提前发现450+ case的内存CE问题,服务器的宕机数量明显减少。对满足报修标准服务器业务进行迁移,并更换相应的内存条,避免因服务器突然宕机导致业务的不稳定,甚至因此造成的损失。
-
EDAC是服务器RAS(Reliability, Availability and Serviceability)在内存方面应用的一小部分。RAS是指通过一些技术手段,软硬件结合去保证服务器的这三个能力。RAS在内存方面的优化还有很多,例如MCA(Machine Check Architecture)recovery等等。未来我们也将引入RAS去缓解硬件故障对系统的影响。
参考资料:
本文转载自 Hao Chan vivo互联网技术,原文链接:https://mp.weixin.qq.com/s/UP5Fph3DrjlHuBdjT9Crrg。