
Apache Hudi 是一个流式数据湖平台,将核心仓库和数据库功能直接引入数据湖。Hudi 不满足于将自己称为 Delta 或 Apache Iceberg 之类的开放文件格式,它提供表、事务、更新/删除、高级索引、流式摄取服务、数据聚簇/压缩优化和并发性。Hudi 于 2016 年推出,牢牢扎根于 Hadoop 生态系统,解释了名称背后的含义:Hadoop Upserts Deletes and Incrementals。它是为管理 HDFS 上大型分析数据集的存储而开发的。Hudi 的主要目的是减少流数据摄取过程中的延迟。


随着时间的推移,Hudi 已经发展到使用云存储[1]和对象存储,包括 MinIO。Hudi 从 HDFS 的转变与世界的大趋势齐头并进,将传统的 HDFS 抛在脑后,以实现高性能、可扩展和云原生对象存储。Hudi 承诺提供优化,使 Apache Spark、Flink、Presto、Trino 和其他的分析工作负载更快,这与 MinIO 对大规模云原生应用程序性能的承诺非常吻合。在生产中使用 Hudi 的公司包括 Uber[2]、亚马逊[3]、字节跳动[4]和 Robinhood[5]。这些是世界上一些最大的流式数据湖[6]。Hudi 在这个用例中的关键在于它提供了一个增量数据处理栈,可以对列数据进行低延迟处理。通常系统使用 Apache Parquet 或 ORC 等开放文件格式将数据写入一次,并将其存储在高度可扩展的对象存储或分布式文件系统之上。Hudi 作为数据平面来摄取、转换和管理这些数据。Hudi 使用 Hadoop FileSystem API[7] 与存储交互,该 API 与从 HDFS 到对象存储到内存文件系统的各种实现兼容(但不一定最佳)。
Hudi 文件格式
Hudi 使用基本文件和增量日志文件来存储对给定基本文件的更新/更改。基本文件可以是 Parquet(列)或 HFile(索引),增量日志保存为 Avro(行),因为在发生更改时记录对基本文件的更改是有意义的。Hudi 将给定基本文件的所有更改编码为一系列块。块可以是数据块、删除块或回滚块。这些块被合并以便派生更新的基础文件。这种编码还创建了一个独立的日志。
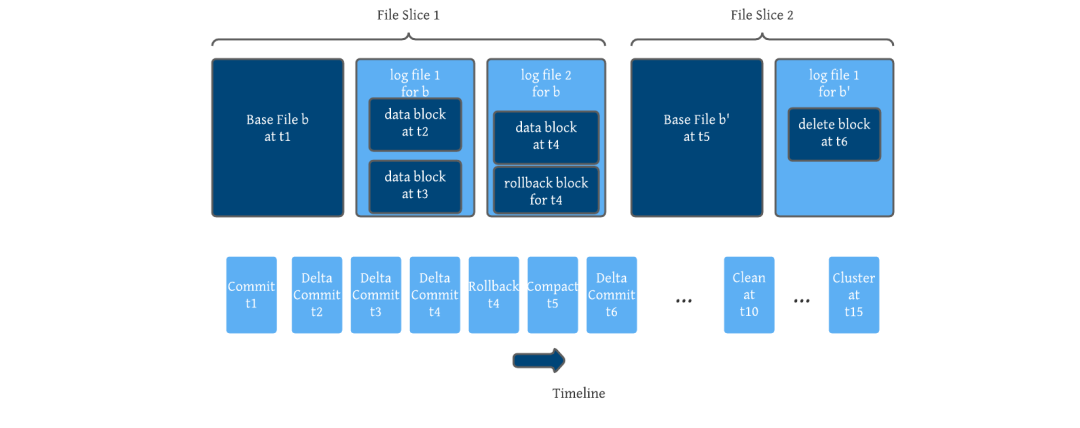
表格式由表的文件布局、表的模式(Schema)和跟踪表更改的元数据组成。Hudi 强制执行模式写入,与强调流处理一致,以确保管道不会因非向后兼容的更改而中断。Hudi 将给定表/分区的文件分组在一起,并在记录键和文件组之间进行映射。如上所述,所有更新都记录到特定文件组的增量日志文件中。这种设计比 Hive ACID 更高效,后者必须将所有数据记录与所有基本文件合并以处理查询。Hudi 的设计预计基于键的快速更新插入和删除,因为它使用文件组的增量日志,而不是整个数据集。
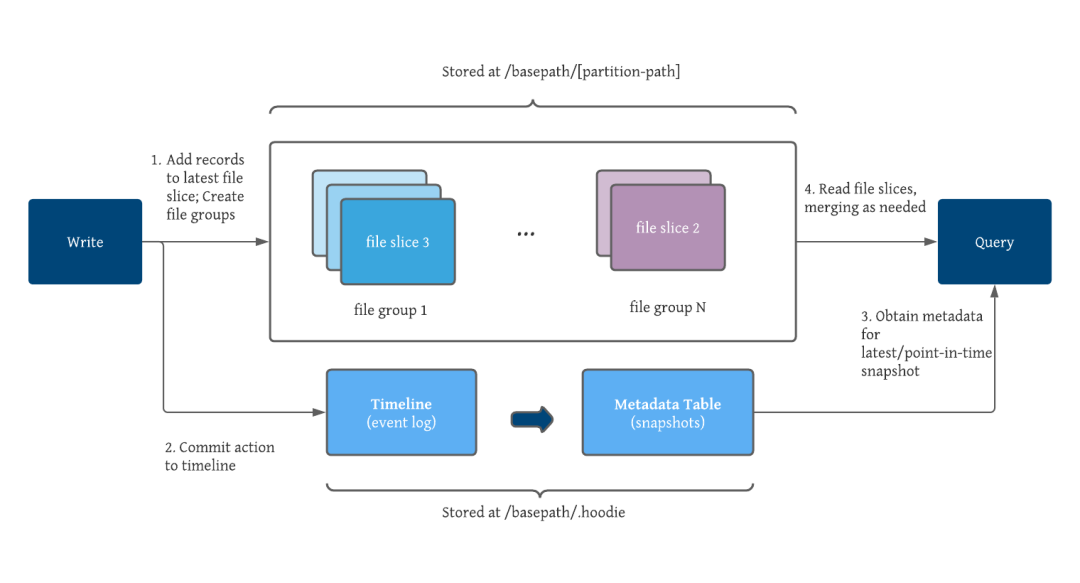
时间线对于理解Hudi至关重要,因为它是所有 Hudi 表元数据的真实事件日志的来源。时间线存储在 .hoodie 文件夹中,在我们的例子中是存储桶。事件将保留在时间线上直到它们被删除。整个表和文件组都存在时间线,通过将增量日志应用于原始基本文件,可以重建文件组。为了优化频繁的写入/提交,Hudi 的设计使元数据相对于整个表的大小保持较小。时间线上的新事件被保存到内部元数据表中,并作为一系列读取时合并的表实现,从而提供低写入放大。因此,Hudi 可以快速吸收元数据的快速变化。此外元数据表使用 HFile 基本文件格式,通过一组索引键查找进一步优化性能,避免读取整个元数据表。作为表一部分的所有物理文件路径都包含在元数据中,以避免昂贵且耗时的云文件列表。
Hudi写入
Hudi 写入架构具有 ACID 事务支持的高性能写入层,可实现非常快速的增量更改,例如更新和删除。典型的 Hudi 架构依赖 Spark 或 Flink 管道将数据传递到 Hudi 表。Hudi 写入路径经过优化,比简单地将 Parquet 或 Avro 文件写入磁盘更有效。Hudi 分析写入操作并将它们分类为增量操作(insert, upsert, delete)或批量操作(insert_overwrite, insert_overwrite_table, delete_partition, bulk_insert),然后应用必要的优化[8]。Hudi 写入器还负责维护元数据。对于每条记录,都会写入该记录唯一的提交时间和序列号(这类似于 Kafka 偏移量),从而可以派生记录级别的更改。用户还可以在传入数据流中指定事件时间字段,并使用元数据和 Hudi 时间线跟踪它们。这可以显着改进流处理,因为 Hudi 包含每个记录的到达时间和事件时间,从而可以为复杂的流处理管道构建强大的水印[9]。
Hudi读取
写入器和读取器之间的快照隔离允许从所有主要数据湖查询引擎(包括 Spark、Hive、Flink、Prest、Trino 和 Impala)中一致地查询表快照。与 Parquet 和 Avro 一样,Hudi 表可以被 Snowflake[10] 和 SQL Server[11] 等作为外部表读取。Hudi 读取器非常轻量,尽可能使用特定于引擎的向量化读取器和缓存,例如 Presto 和 Spark。当 Hudi 必须为查询合并基本文件和日志文件时,Hudi 使用可溢出映射和延迟读取等机制提高合并性能,同时还提供读取优化查询。Hudi 包含许多非常强大的增量查询功能,元数据是其中的核心,允许将大型提交作为较小的块使用,并完全解耦数据的写入和增量查询。通过有效使用元数据,时间旅行非常容易实现,其只是另一个具有定义起点和终点的增量查询。Hudi 在任何给定时间点以原子方式将键映射到单个文件组,支持 Hudi 表上的完整 CDC 功能。正如上面 Hudi 写入器部分所讨论的,每个表都由文件组组成,每个文件组都有自己的自包含元数据。
Hudi核心特性
Hudi 最大的优势在于它摄取流式和批处理数据的速度。通过提供 upsert 功能,Hudi 执行任务的速度比重写整个表或分区快几个数量级。为了利用 Hudi 的摄取速度,数据湖库需要一个具有高 IOPS 和吞吐量的存储层。MinIO 的可扩展性和高性能的结合正是 Hudi 所需要的。MinIO 能够满足为实时企业数据湖提供动力所需的性能——最近的一项基准测试[12]在 GET 上实现了 325 GiB/s (349 GB/s),在 PUT 上实现了 165 GiB/s (177 GB/s) 32 个现成的 NVMe SSD 节点。活跃的企业 Hudi 数据湖存储大量小型 Parquet 和 Avro 文件。MinIO 包括许多小文件优化[13],可实现更快的数据湖。小对象与元数据一起保存,减少了读取和写入小文件(如 Hudi 元数据和索引)所需的 IOPS。模式(Schema) 是每个 Hudi 表的关键组件。Hudi 可以强制执行模式,也可以允许模式演变,以便流数据管道可以适应而不会中断。此外Hudi 强制执行 Schema-on-Writer 以确保更改不会破坏管道。Hudi 依靠 Avro 来存储、管理和发展表的模式。Hudi 为数据湖提供 ACID 事务保证。Hudi 确保原子写入:以原子方式向时间线提交提交,并给出一个时间戳,该时间戳表示该操作被视为发生的时间。Hudi 隔离了写入器、表 和 读取器进程之间的快照,因此每个进程都对表的一致快照进行操作。Hudi 通过写入器之间的乐观并发控制 (OCC) 以及表服务和写入器之间以及多个表服务之间的基于 MVCC 的非阻塞并发控制来完善这一点。
Hudi 整合 MinIO 教程
本教程将引导您设置 Spark、Hudi 和 MinIO,并介绍一些基本的 Hudi 功能。本教程基于 Apache Hudi Spark 指南[14],适用于云原生 MinIO 对象存储。请注意,使用版本化存储桶会增加 Hudi 的一些维护开销。任何被删除的对象都会创建一个删除标记[15]。随着 Hudi 使用 Cleaner 实用程序[16]清理文件,删除标记的数量会随着时间的推移而增加。正确配置生命周期管理[17]以清理这些删除标记很重要,因为如果删除标记的数量达到 1000 个,List 操作可能会阻塞。Hudi 项目维护人员建议使用生命周期规则在一天后清理删除标记。
前提条件
- • 下载并安装[18] Apache Spark。
-
• 下载并安装[19] MinIO。记录控制台的 IP 地址、TCP 端口、访问密钥和密钥。
-
• 下载并安装[20] MinIO 客户端。
-
• 下载 AWS 和 AWS Hadoop 库并将它们添加到您的类路径中,以便使用 S3A 处理对象存储。
-
• AWS:aws-java-sdk:1.10.34(或更高版本)
-
• Hadoop:hadoop-aws:2.7.3(或更高版本)
-
• 下载 Jar 文件[21],解压缩并将它们复制到
/opt/spark/jars。
创建一个 MinIO 存储桶
使用 MinIO Client 创建一个存储 Hudi 数据的存储桶:
mc alias set myminio http://
mc mb myminio/hudi 使用 Hudi 启动 Spark
使用配置为使用 MinIO 进行存储的 Hudi 启动 Spark shell。确保使用您的 MinIO 设置为 S3A 配置条目。
spark-shell
--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0,org.apache.hadoop:hadoop-aws:3.3.4
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
--conf 'spark.hadoop.fs.s3a.access.key='
--conf 'spark.hadoop.fs.s3a.secret.key='
--conf 'spark.hadoop.fs.s3a.endpoint=:9000'
--conf 'spark.hadoop.fs.s3a.path.style.access=true'
--conf 'fs.s3a.signing-algorithm=S3SignerType' 然后在 Spark 中初始化 Hudi。
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord请注意,可以使用外部配置文件[22] 简化配置。
创建表
尝试使用 Scala 创建一个简单的小型 Hudi 表。Hudi DataGenerator 是一种基于示例行程模式生成示例插入和更新的快速简便的方法。
val tableName = "hudi_trips_cow"
val basePath = "s3a://hudi/hudi_trips_cow"
val dataGen = new DataGenerator向Hudi插入数据,向MinIO写表
下面将生成新的行程数据,将它们加载到 DataFrame 中,并将我们刚刚创建的 DataFrame 作为 Hudi 表写入 MinIO。如果表已经存在,模式(覆盖)将覆盖并重新创建表。行程数据依赖于记录键(uuid)、分区字段(地区/国家/城市)和逻辑(ts)来确保行程记录对于每个分区都是唯一的。我们将使用默认的写入操作 upsert。当没有更新的工作负载时可以使用 insert 或 bulk_insert ,这会更快。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)打开浏览器并使用您的访问密钥和密钥在http://登录 MinIO。您将在存储桶中看到 Hudi 表。
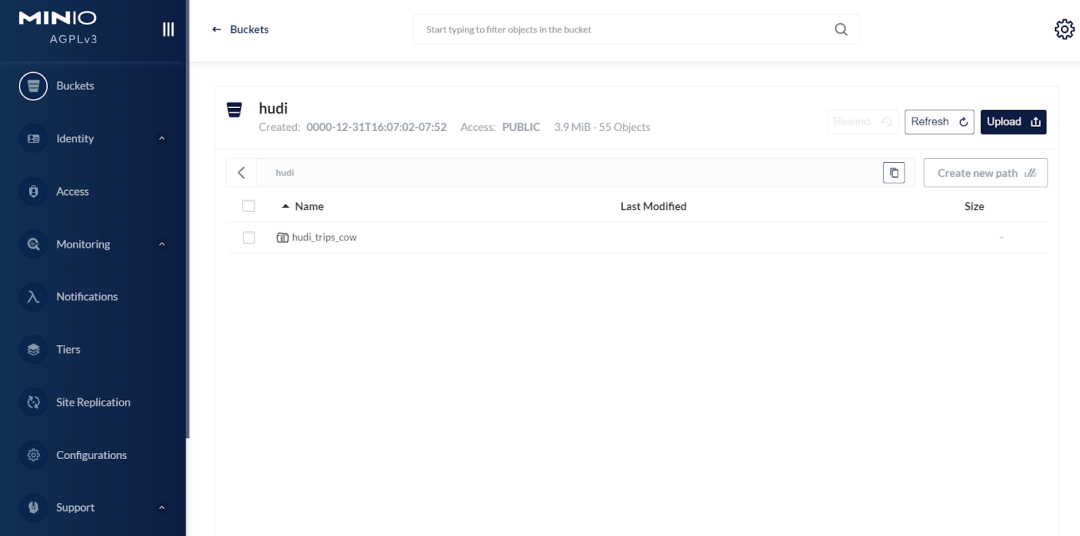
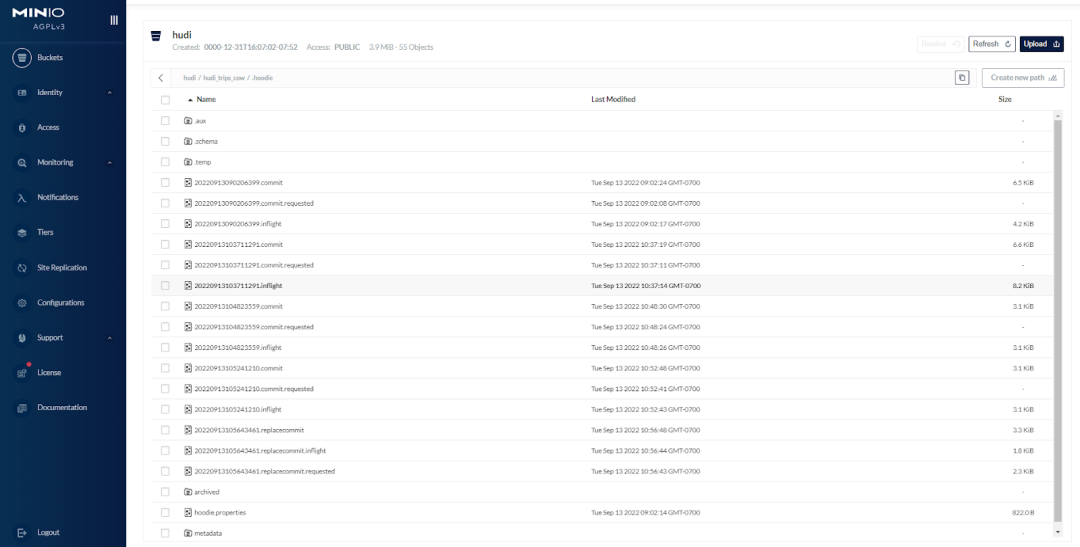
该存储桶还包含一个包含元数据的 .hoodie路径,以及包含americas、asia数据的路径。
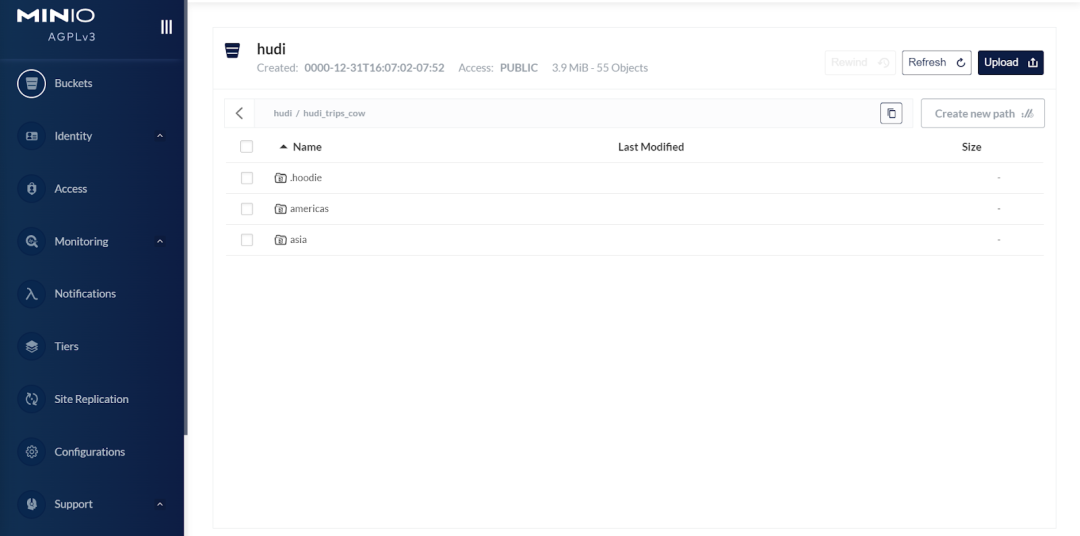
看看元数据,这是完成整个教程后 .hoodie路径的截图。我们可以看到我在 2022 年 9 月 13 日星期二 9:02、10:37、10:48、10:52 和 10:56 修改了表。
查询数据
让我们将 Hudi 数据加载到 DataFrame 中并运行示例查询。
// spark-shell
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()Hudi时间旅行
我们可以去看 1988 年的 Hootie and the Blowfish 音乐会。每次写入 Hudi 表都会创建新的快照。将快照视为可用于时间旅行查询的表版本。尝试一些时间旅行查询(您必须更改时间戳以与您相关)。
spark.read.
format("hudi").
option("as.of.instant", "2022-09-13 09:02:08.200").
load(basePath)更新数据
这个过程类似于我们之前插入新数据的过程。为了展示 Hudi 更新数据的能力,我们将对现有行程记录生成更新,将它们加载到 DataFrame 中,然后将 DataFrame 写入已经保存在 MinIO 中的 Hudi 表中。请注意我们使用的是追加保存模式。一般准则是使用追加模式,除非您正在创建新表,因此不会覆盖任何记录。使用 Hudi 的一种典型方式是实时摄取流数据,将它们附加到表中,然后根据刚刚附加的内容编写一些合并和更新现有记录的逻辑。或者如果表已存在,则使用覆盖模式写入会删除并重新创建表。
// spark-shell
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)查询数据将显示更新的行程记录。
增量查询
Hudi 可以使用增量查询提供自给定时间戳以来更改的记录流。我们需要做的就是提供一个开始时间,从该时间开始更改将被流式传输以查看通过当前提交的更改,并且我们可以使用结束时间来限制流。增量查询对于 Hudi 来说非常重要,因为它允许您在批处理数据上构建流式管道。
// spark-shell
// reload data
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2) // commit time we are interested in
// incrementally query data
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark.sql("select _hoodie_commit_time, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()时间点查询
Hudi 可以查询到特定时间和日期的数据。
// spark-shell
val beginTime = "000" // Represents all commits > this time.
val endTime = commits(commits.length - 2) // commit time we are interested in
//incrementally query data
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
spark.sql("select _hoodie_commit_time, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()使用软删除删除数据
Hudi 支持两种不同的删除记录方式。软删除保留记录键并将所有其他字段的值清空。软删除保留在 MinIO 中,并且仅使用硬删除从数据湖中删除。
// spark-shell
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
// fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()
// fetch two records for soft deletes
val softDeleteDs = spark.sql("select * from hudi_trips_snapshot").limit(2)
// prepare the soft deletes by ensuring the appropriate fields are nullified
val nullifyColumns = softDeleteDs.schema.fields.
map(field => (field.name, field.dataType.typeName)).
filter(pair => (!HoodieRecord.HOODIE_META_COLUMNS.contains(pair._1)
&& !Array("ts", "uuid", "partitionpath").contains(pair._1)))
val softDeleteDf = nullifyColumns.
foldLeft(softDeleteDs.drop(HoodieRecord.HOODIE_META_COLUMNS: _*))(
(ds, col) => ds.withColumn(col._1, lit(null).cast(col._2)))
// simply upsert the table after setting these fields to null
softDeleteDf.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY, "upsert").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
// reload data
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
// This should return the same total count as before
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
// This should return (total - 2) count as two records are updated with nulls
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()使用硬删除删除数据
相比之下,硬删除就是我们认为的删除。记录键和相关字段将从表中删除。
// spark-shell
// fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
// fetch two records to be deleted
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
// issue deletes
val deletes = dataGen.generateDeletes(ds.collectAsList())
val hardDeleteDf = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
hardDeleteDf.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
// run the same read query as above.
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// fetch should return (total - 2) records
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()写覆盖
当数据湖获得更新现有数据的能力时,它就变成了Lakehouse。我们将生成一些新的行程数据,然后覆盖我们现有的数据。此操作比 Hudi 一次为您计算整个目标分区的 upsert 更快。在这里我们指定配置以绕过 upsert 将为您执行的自动索引、预组合和重新分区。
// spark-shell
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.
read.json(spark.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
// Should have different keys now for San Francisco alone, from query before.
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)Schema演进和分区
模式演进允许您更改 Hudi 表的模式以适应数据随时间发生的变化。下面是一些关于如何查询和发展模式和分区的示例。如需更深入的讨论,请参阅 Schema Evolution | Apache Hudi[23]。请注意如果您运行这些命令,它们将改变 Hudi 表模式,使其与本教程不同。
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
-- Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
-- Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = 'value')
#Alter table examples
--rename to:
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl2;
--add column:
ALTER TABLE hudi_cow_nonpcf_tbl2 add columns(remark string);
--change column:
ALTER TABLE hudi_cow_nonpcf_tbl2 change column uuid uuid bigint;
--set properties;
alter table hudi_cow_nonpcf_tbl2 set tblproperties (hoodie.keep.max.commits = '10');目前,show partitions仅适用于文件系统,因为它基于文件系统表路径。本教程使用 Spark 来展示 Hudi 的功能。但是Hudi 可以支持多种表类型/查询类型,并且可以从 Hive、Spark、Presto 等查询引擎查询 Hudi 表。Hudi 项目有一个演示视频[24],它在基于 Docker 的设置上展示了所有这些,所有相关系统都在本地运行。
总结
Apache Hudi 是第一个用于数据湖的开放表格式,在流式架构中值得考虑。Hudi 社区和生态系统生机勃勃,越来越重视用 Hudi/对象存储替换 Hadoop/HDFS,以实现云原生流式数据湖。将 MinIO 用于 Hudi 存储为多云数据湖和分析铺平了道路。MinIO 包括主动-主动复制以在本地、公共/私有云和边缘位置之间同步数据,从而实现企业所需的出色功能,例如地理负载平衡和快速热热故障转移。
推荐阅读
万字长文:基于Apache Hudi + Flink多流拼接(大宽表)最佳实践
华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
基于 Apache Hudi 的湖仓一体技术在 Shopee 的实践
引用链接
[1] 云存储: [https://hudi.apache.org/docs/cloud](https://hudi.apache.org/docs/cloud)[2] Uber: [https://eng.uber.com/uber-big-data-platform/](https://eng.uber.com/uber-big-data-platform/)[3] 亚马逊: [https://aws.amazon.com/blogs/big-data/how-amazon-transportation-service-enabled-near-real-time-event-analytics-at-petabyte-scale-using-aws-glue-with-apache-hudi/](https://aws.amazon.com/blogs/big-data/how-amazon-transportation-service-enabled-near-real-time-event-analytics-at-petabyte-scale-using-aws-glue-with-apache-hudi/)[4] 字节跳动: [http://hudi.apache.org/blog/2021/09/01/building-eb-level-data-lake-using-hudi-at-bytedance](http://hudi.apache.org/blog/2021/09/01/building-eb-level-data-lake-using-hudi-at-bytedance)[5] Robinhood: [https://s.apache.org/hudi-robinhood-talk](https://s.apache.org/hudi-robinhood-talk)[6] 流式数据湖: [https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform/](https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform/)[7] Hadoop FileSystem API: [https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/fs/FileSystem.html](https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/fs/FileSystem.html)[8] 优化: [https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform/#writers](https://hudi.apache.org/blog/2021/07/21/streaming-data-lake-platform/#writers)[9] 水印: [https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/event-time/generating_watermarks/](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/event-time/generating_watermarks/)[10] Snowflake: [https://blog.min.io/minio_and_snowflake/](https://blog.min.io/minio_and_snowflake/)[11] SQL Server: [https://blog.min.io/sqlserver2022/](https://blog.min.io/sqlserver2022/)[12] 最近的一项基准测试: [https://min.io/resources/docs/MinIO-Throughput-Benchmarks-on-NVMe-SSD-32-Node.pdf](https://min.io/resources/docs/MinIO-Throughput-Benchmarks-on-NVMe-SSD-32-Node.pdf)[13] 小文件优化: [https://blog.min.io/minio-optimizes-small-objects/](https://blog.min.io/minio-optimizes-small-objects/)[14] Apache Hudi Spark 指南: [https://hudi.apache.org/docs/next/quick-start-guide](https://hudi.apache.org/docs/next/quick-start-guide)[15] 删除标记: [https://blog.min.io/minio-versioning-metadata-deep-dive/](https://blog.min.io/minio-versioning-metadata-deep-dive/)[16] Cleaner 实用程序: [https://hudi.apache.org/docs/hoodie_cleaner](https://hudi.apache.org/docs/hoodie_cleaner)[17] 生命周期管理: [https://docs.min.io/docs/minio-bucket-lifecycle-guide.html](https://docs.min.io/docs/minio-bucket-lifecycle-guide.html)[18] 下载并安装: [https://spark.apache.org/downloads.html](https://spark.apache.org/downloads.html)[19] 下载并安装: [https://min.io/download](https://min.io/download)[20] 下载并安装: [https://min.io/download](https://min.io/download)[21] 下载 Jar 文件: [https://jar-download.com/artifacts/org.apache.hadoop/hadoop-aws/3.3.4](https://jar-download.com/artifacts/org.apache.hadoop/hadoop-aws/3.3.4)[22] 外部配置文件: [https://hudi.apache.org/docs/next/configurations#externalized-config-file](https://hudi.apache.org/docs/next/configurations#externalized-config-file)[23] Schema Evolution | Apache Hudi: https://hudi.apache.org/docs/next/schema_evolution[24] 演示视频: [https://www.youtube.com/watch?v=VhNgUsxdrD0](https://www.youtube.com/watch?v=VhNgUsxdrD0)
本文转载自apachehudi,原文链接:https://mp.weixin.qq.com/s/jBciMVsdWmRHRjEyyckQlQ。