
小编有话说
市场的变幻,政策的完善,技术的革新……种种因素让我们面对太多的挑战,这仍需我们不断探索、克服。
今年,网易数帆将持续推出新栏目「金融专家说」「技术专家说」「产品专家说」等,聚集数帆及合作伙伴的数字化转型专家天团,聚焦大数据、云原生、人工智能等科创领域,带来深度技术解读及其在各行业落地应用等一系列知识分享,为企业数字化转型成功提供有价值的参考。
今天是第5期,由网易数帆大数据离线技术专家尤夕多带来能帮助标准化企业级离线数仓优化存储,提高性能,且已在网易内部实践验证过的成熟技术方案,为大家提供技术思路参考。
Spark 企业级离线数仓面临的痛点
BY $columns ,这本质上是增加一次额外的 Shuffle 来对数据重新分区,产出的文件质量强依赖于这个 Shuffle 字段,然而在大部分场景中,数据倾斜是必然的,这造成了部分计算分区需要处理特别大的数据量,不仅带来文件倾斜问题,在性能上也会拖累整个任务完成时间。
1)存在优化上限;通过优化调试很难判断最佳的取模范围,只能给一个相对可以接受的优化结果
2)有很大的优化代价;需要非常了解字段的数据分布情况,再经过不断调试验证最终找到较为合理的值
3)维护成本比较高;可能过1个月,数据发生了一些变化,那么之前优化的取模值就变得不合理
BY $column,这本质上是在写之前增加一次分区内的排序来提高数据压缩率。或者结合 Shuffle增加 DISTRIBUTE BY $columns SORT BY $columns 让相同数据落到一个分区后再做局部排序进一步提高数据压缩率。那么问题来了,首先这也绕不过
小文件 & 文件倾斜的问题,这里就不再重复。其次传统的字典排序不能很好的保留多维场景下数据的聚集分布,这里的多维在数仓场景下可以理解成多字段。而优秀的数据聚集分布可以在查询阶段提高数据文件的 Data Skipping 比例。我们目前大部分任务都只考虑任务本身的性能,需要逐渐重视下游任务查询的性能,从而形成一个良好的循环。
Z-Order 提出了以下这些解决方案,并且已经在线上环境取得了非常好的效果。
Rebalance + Z-Order
BY + SORT BY,我们提出了新一代的优化方案 REBALANCE
+ Z-Order。REBALANCE 可以在尽可能满足 DISTRIBUTE BY 语义的情况下同时解决 小文件 & 文件倾斜问题。这里用“尽可能满足”这个词是因为,文件倾斜本质上是由于计算分区倾斜导致,那么我们把倾斜分区拆成多个的同时也就破坏了 DISTRIBUTE BY 语义,当然这不影响数准确性,也不会带来其他问题。基于 Z-Order 算法的排序替换了默认的字典排序,允许在多维场景下继续保留多维数据的聚集分布,在提高压缩率的同时可以加速下游任务的查询性能。
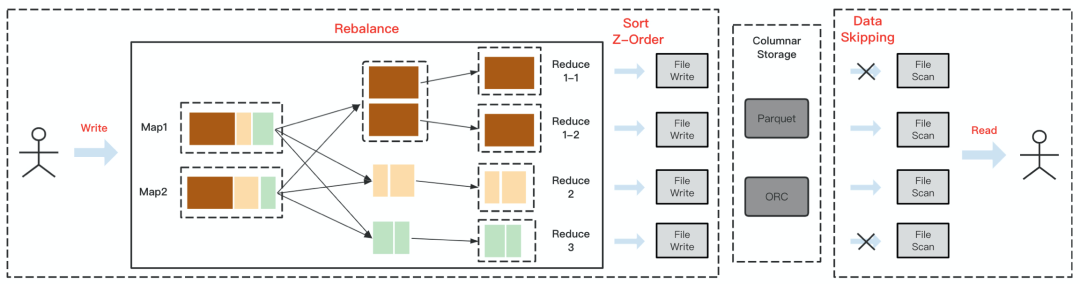

Z-Order 运作原理,涉及表的上游任务以及下游任务。首先 Rebalance 以Shuffle 的形式存在,并在 Shuffle 读阶段做分区的拆分和合并,保证每个 Reduce 分区处理相同规模的数据量。基于 Z-Order 的 Data Skipping 优化强依赖于文件格式,我们知道 Parquet 和 ORC 这类主流的列式存储格式会在写数据的同时记录数据的统计信息,比如 Parquet默认会以 Row Group 粒度记录字段的min/max 值,在查询这个文件的过程中,我们会把被 Push Down 的谓语条件和这些统计值做对比,如果不满足条件那么我们可以直接 Skip 这个 Row Group 甚至整个文件,避免拉取无效的数据,这就是 Data Skipping 过程。
在实际操作中,由于引入了一次 Shuffle,任务会多一个 Stage,但执行时间却大幅度缩短。这是因为原本的任务在最后一个 Stage 存在数据膨胀和严重倾斜的情况,导致单个计算分区处理的数据量非常大。经过 Rebalance 后,额外的 Stage 把膨胀的数据打散,并且解决了倾斜问题,最终得到了 4 倍性能提升。不过此时出现了另一个问题,数据压缩率下降了,计算分区内的数据膨胀+倾斜虽然跑的慢,反而有着较高的压缩率。
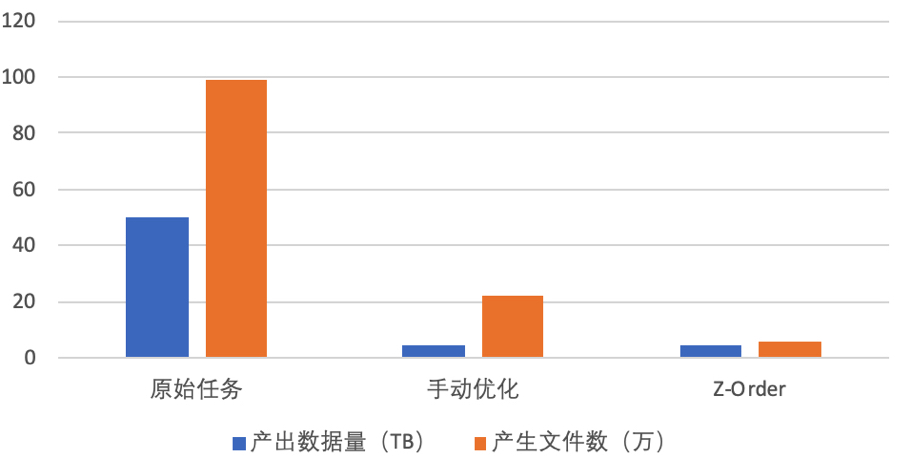
为了解决压缩率的问题,我们增加了 Z-Order 优化,可以看到压缩率提升了 12 倍
,对比 Spark2 时期的任务也有近 25% 的提升。而且由于 IO 下降,计算性能也没有因为多一次 Z-Order 变慢。从而实现同时治理任务性能,小文件以及数据压缩率的目标。
Two-Phase Rebalance + Z-Order
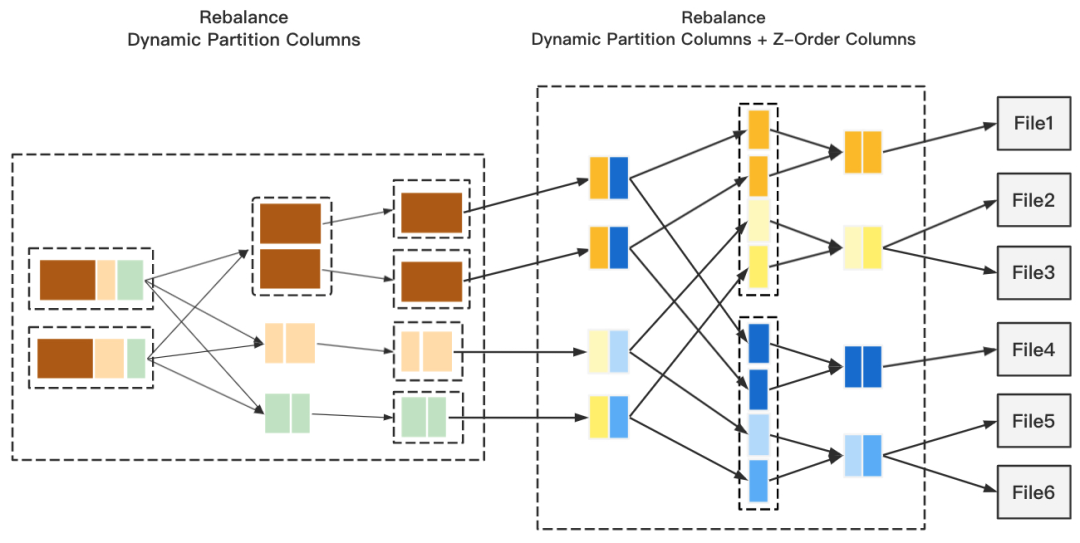
Z-Order 字段,保证输出最大的压缩率,最后通过 Z-Order 完成分区内的排序。这里可能有同学会问,为什么第二阶段 Rebalance 不会产生小文件?这是由于AQE Shuffle Read 在拆分 Reduce 分区过程中继承了 Map 顺序性,也就是说 Redcue 分区拉取到的 Map 一定是连续的,而我们在第一阶段 Rebalance 后,连续的 Map 意味着他们拥有相同的分区值,所以我们可以实现尽可能的避免小文件产生。
Two Phase Rebalance + Z-Order + Zstd
+ Z-Order 已经满足了优化的需求,但是由于相比手动优化会多一次 Shuffle,导致任务过程中的 Shuffle 数据量会增加。这是临时数据,在任务结束后会自动清理,但如果我们本地磁盘冗余不够,也会出现存储空间不足的问题。因此我们引入了更高压缩率的算法 Zstd,在尽可能减少对任务性能影响的前提下减少 Shuffle 过程数据量。
小结
专家简介

尤夕多
网易数帆大数据离线技术专家,Apache Kyuubi PMC member,Apache Spark Contributor。

本文转载自网易有数,原文链接:https://mp.weixin.qq.com/s/eIGSugPvEzTewxHix-xL0g。