


总第520篇
2022年 第037篇

-
导语
-
1 背景
-
2 分析
-
3 模型推理
-
3.1 分布式
-
3.2 CPU加速
-
3.3 GPU加速
-
4 特征服务CodeGen优化
-
4.1 全流程CodeGen优化
-
4.2 传输优化
-
4.3 高维ID特征编码
-
5 样本构建
-
5.1 流式样本
-
5.2 结构化存储
-
6 数据准备
-
6.1 做“加法”
-
6.2 做“减法”
-
6.3 做“乘法”
-
6.4 做“除法”
-
7 总结与展望
导语
1 背景

2 分析
-
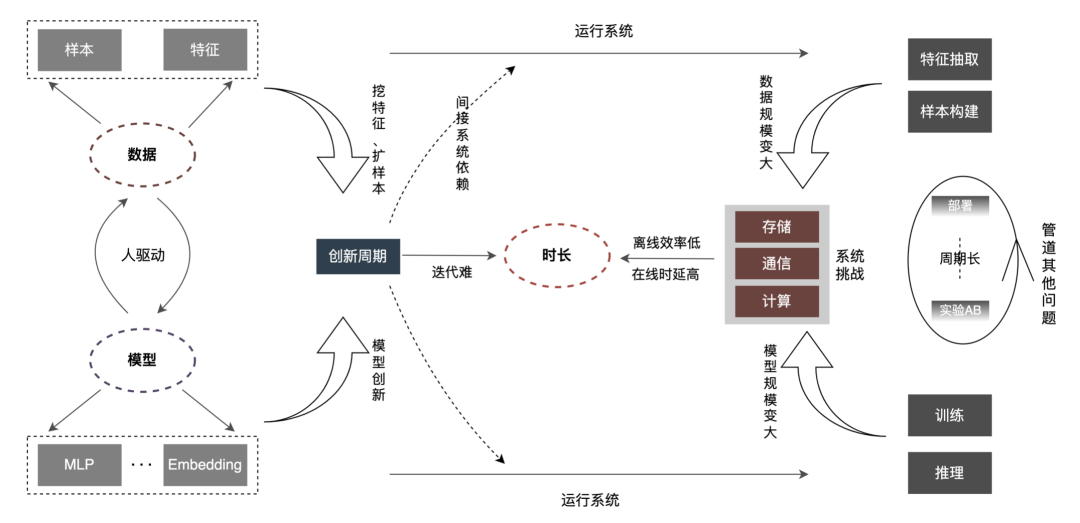
在线时延:特征层面,在线请求不变的情况下,特征量的增加,带来的IO、特征计算耗时增加等问题尤为突出,需要在特征算子解析编译、特征抽取内部任务调度、网络I/O传等方面重塑。在模型层面,模型历经百M/G到几百G的变化,在存储上带来了2个数量级的上升。此外,单模型的计算量也出现了数量级的上涨(FLOPs从百万到现在千万),单纯的靠CPU,解决不了巨大算力的需求,建设CPU+GPU+Hierarchical Cache推理架构来支撑大规模深度学习推理势在必行。
-
离线效率:随着样本、特征的数倍增加,样本构建,模型训练的时间会被大大拉长,甚至会变得不可接受。如何在有限的资源下,解决海量样本构建、模型训练是系统的首要问题。在数据层面,业界一般从两个层面去解决,一方面不断优化批处理过程中掣肘的点,另一方面把数据“化批为流”,由集中式转到分摊式,极大提升数据的就绪时间。在训练层面,通过硬件GPU并结合架构层面的优化,来达到加速目的。其次,算法创新往往都是通过人来驱动,新数据如何快速匹配模型,新模型如何快速被其他业务应用,如果说将N个人放在N条业务线上独立地做同一个优化,演变成一个人在一个业务线的优化,同时广播适配到N个业务线,将会有N-1个人力释放出来做新的创新,这将会极大地缩短创新的周期,尤其是在整个模型规模变大后,不可避免地会增加人工迭代的成本,实现从“人找特征/模型” 到“特征/模型找人”的深度转换,减少“重复创新”,从而达到模型、数据智能化的匹配。
-
Pipeline其他问题:机器学习Pipeline并不是在大规模深度学习模型链路里才有,但随着大模型的铺开,将会有新的挑战,比如:① 系统流程如何支持全量、增量上线部署;② 模型的回滚时长,把事情做正确的时长,以及事情做错后的恢复时长。简而言之,会在开发、测试、部署、监测、回滚等方面产生新的诉求。
3 模型推理
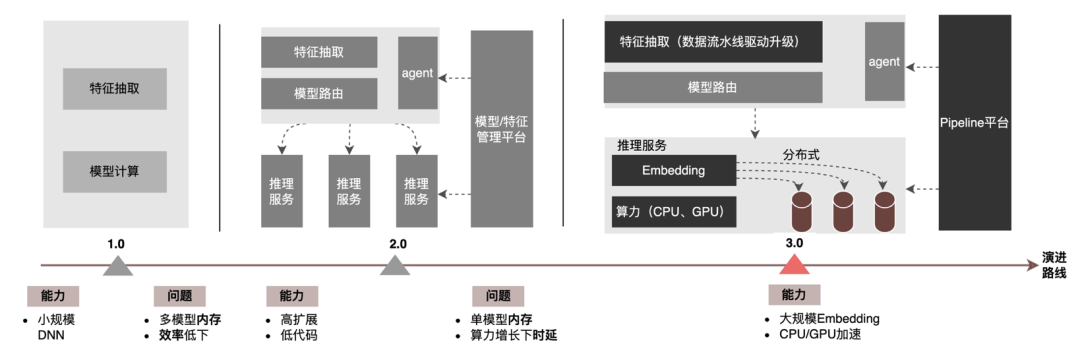
3.1 分布式
-
Sparse参数:参数量级很大,一般在亿级别,甚至十亿/百亿级别,这会导致存储空间占用较大,通常在百G级别,甚至T级别。其特点:①单机加载困难:在单机模式下,Sparse参数需全部加载到机器内存中,导致内存严重吃紧,影响稳定性和迭代效率;②读取稀疏:每次推理计算,只需读取部分参数,比如User全量参数在2亿级别,但每次推理请求只需读取1个User参数。
-
Dense参数:参数规模不大,模型全连接一般在2~3层,参数量级在百万/千万级别。特点:① 单机可加载:Dense参数占用在几十兆左右,单机内存可正常加载,比如:输入层为2000,全连接层为[1024, 512, 256],总参数为:2000 * 1024 + 1024 * 512 + 512 * 256 + 256 = 2703616,共270万个参数,内存占用在百兆内;② 全量读取:每次推理计算,需要读取全量参数。
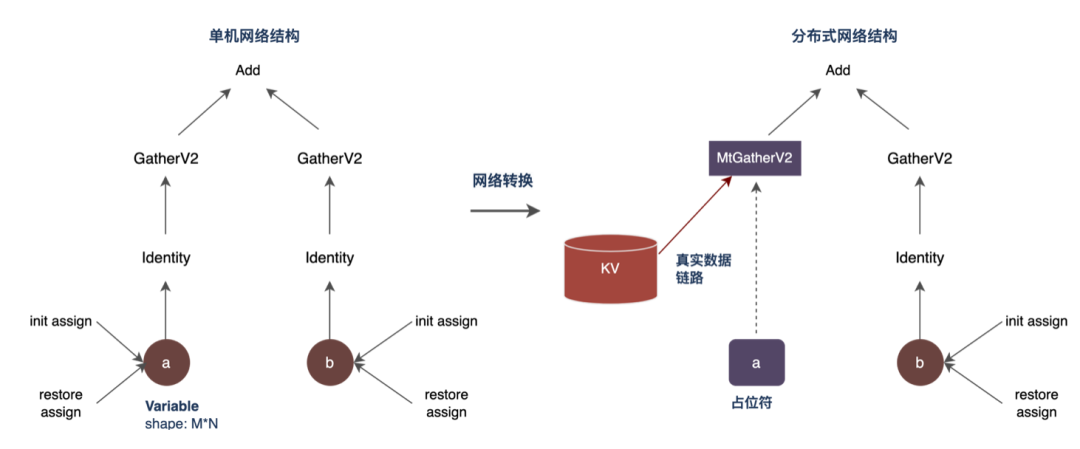
3.1.1 模型网络结构转换
-
分布式算子替换:遍历模型网络,将需要替换的GatherV2算子替换为自定义分布式算子MtGatherV2,同时修改上下游节点的Input/Output。
-
原生Embedding表固化:原生Embedding表固化为占位符,既能保留模型网络结构完整,又能避免Sparse参数对单机内存的占用。
-
请求查询:将输入ID进行去重以降低查询量,并通过分片的方式并发查询二级缓存(本地Cache + 远端KV)获取Embedding向量。
-
模型管理:维护对模型Embedding Meta注册、卸载流程,以及对Cache的创建、销毁功能。
-
模型部署:触发模型资源信息的加载,以及对Embedding数据并行导入KV的流程。

3.1.2 Sparse参数导出
-
分片并行导出:解析模型的Checkpoint文件,获取Embedding表对应的Part信息,并根据Part进行划分,将每个Part文件通过多个Worker节点并行导出到HDFS上。
-
导入KV:提前预分配多个Bucket,Bucket会存储模型版本等信息,便于在线路由查询。同时模型的Embedding数据也会存储到Bucket中,按分片并行方式导入到KV中。

3.2 CPU加速
-
指令集优化:如果使用TensorFlow模型,在编译TensorFlow框架代码时,直接在编译选项里加入指令集优化项即可。实践证明引入AVX2、AVX512指令集优化效果明显,在线推理服务吞吐提升30%+。
-
加速库优化:加速库通过对网络模型结构进行优化融合,以达到推理加速效果。业界常用的加速库有TVM、OpenVINO等,其中TVM支持跨平台,通用性较好。OpenVINO面向Intel厂商硬件进行针对性优化,通用性一般,但加速效果较好。
-
线性算子融合:OpenVINO通过模型优化器,将模型网络中的多层算子进行统一线性融合,以降低算子调度开销和算子间的数据访存开销,比如将Conv+BN+Relu三个算子合并成一个CBR结构算子。
-
数据精度校准:模型经过离线训练后,由于在推理的过程中不需要反向传播,完全可以适当降低数据精度,比如降为FP16或INT8的精度,从而使得内存占用更小,推理延迟更低。

-
网络分布:CTR模型网络结构整体抽象为三部分:Embedding层、Attention层和MLP层,其中Embedding层用于数据获取,Attention层包含较多逻辑运算和轻量级的网络计算,MLP层则为密集网络计算。
-
加速网络选择:OpenVINO针对纯网络计算的加速效果较好,可以很好地应用于MLP层。另外,模型大部分数据存储在Embedding层中,MLP层占内存只有几十兆左右。如果针对MLP层网络划分出多个Batch,模型内存占用在优化前(Embedding+Attention+MLP)≈ 优化后(Embedding+Attention+MLP×Batch个数),对于内存占用的影响较小。因此,我们最终选取MLP层网络作为模型加速网络。
3.3 GPU加速
3.3.1 加速分析
-
异构计算:我们的思路跟CPU加速比较一致,200G的深度学习CTR模型不能直接全放入到GPU里,访存密集型算子适用(比如Embedding相关操作)CPU,计算密集型算子(比如MLP)适用GPU。
-
GPU使用需要关注的几个点:① 内存与显存的频繁交互;② 时延与吞吐;③ 扩展性与性能优化的Trade Off;④ GPU Utilization 。
-
推理引擎的选择:业界常用推理加速引擎有TensorRT、TVM、XLA、ONNXRuntime等,由于TensorRT在算子优化相比其他引擎更加深入,同时可以通过自定义plugin的方式实现任意算子,具有很强的扩展性。而且TensorRT支持常见学习平台(Caffe、PyTorch、TensorFlow等)的模型,其周边越来越完善(模型转换工具onnx-tensorrt、性能分析工具nsys等),因此在GPU侧的加速引擎使用TensorRT。
-
模型分析:CTR模型网络结构整体抽象为三部分:Embedding层、Attention层和MLP层,其中Embedding层用于数据获取,适合CPU;Attention层包含较多逻辑运算和轻量级的网络计算,MLP层则重网络计算,而这些计算可以并行进行,适合GPU,可以充分利用GPU Core(Cuda Core、Tensor Core),提高并行度。
3.3.2 优化目标
-
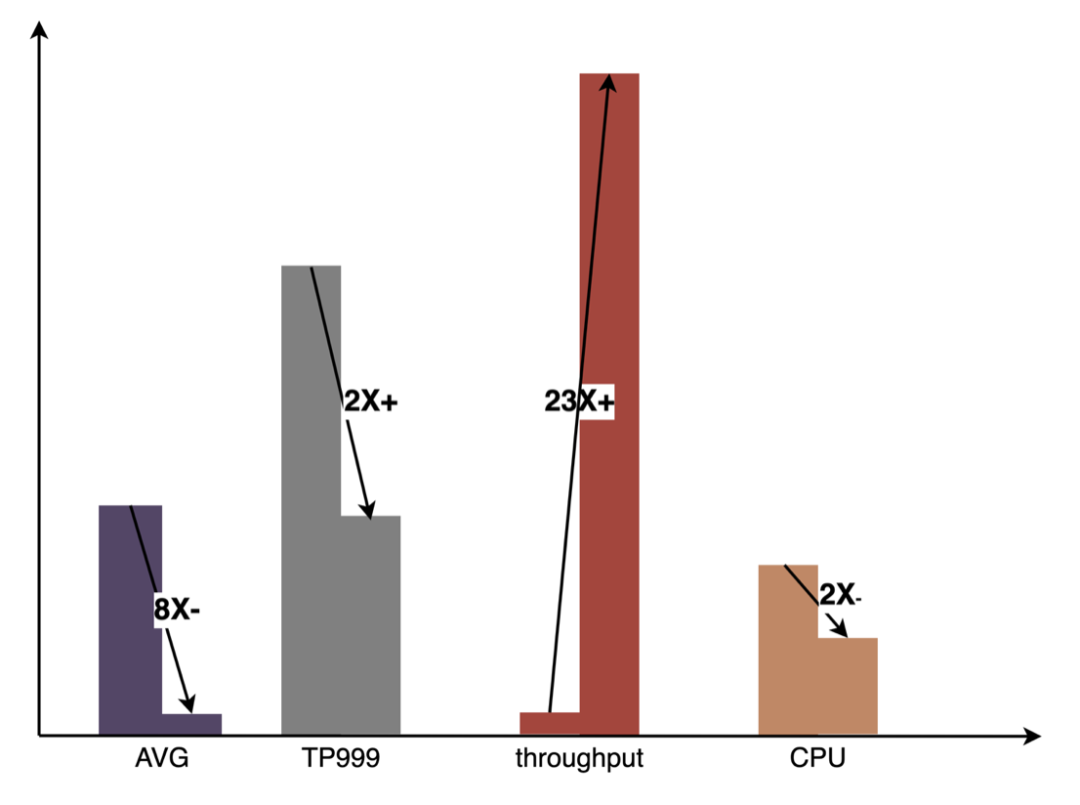
延时和资源约束下的吞吐:当register、Cache等共享资源不需要竞争时,提高并发可有效提高资源利用率(CPU、GPU等利用率),但随之可能带来请求延时的上涨。由于在线系统的延时限制非常苛刻,所以不能只通过资源利用率这一指标简单换算在线系统的吞吐上限,需要在延时约束下结合资源上限进行综合评估。当系统延时较低,资源(Memory/CPU/GPU等)利用率是制约因素时,可通过模型优化降低资源利用率;当系统资源利用率均较低,延时是制约因素时,可通过融合优化和引擎优化来降低延时。通过结合以上各种优化手段可有效提升系统服务的综合能力,进而达到提升系统吞吐的目的。
-
计算量约束下的计算密度:CPU/GPU异构系统下,模型推理性能主要受数据拷贝效率和计算效率影响,它们分别由访存密集型算子和计算密集型算子决定,而数据拷贝效率受PCIe数据传输、CPU/GPU内存读写等效率的影响,计算效率受各种计算单元CPU Core、CUDA Core、Tensor Core等计算效率的影响。随着GPU等硬件的快速发展,计算密集型算子的处理能力同步快速提高,导致访存密集型算子阻碍系统服务能力提升的现象越来越突出,因此减少访存密集型算子,提升计算密度对系统服务能力也变得越来越重要,即在模型计算量变化不大的情况下,减少数据拷贝和kernel launch等。比如通过模型优化和融合优化来减少算子变换(比如Cast/Unsqueeze/Concat等算子)的使用,使用CUDA Graph减少kernel launch等。
3.3.3 模型优化
1. 计算与传输去重:推理时同一Batch只包含一个用户信息,因此在进行inference之前可以将用户信息从Batch Size降为1,真正需要inference时再进行展开,降低数据的传输拷贝以及重复计算开销。如下图,inference前可以只查询一次User类特征信息,并在只有用户相关的子网络中进行裁剪,待需要计算关联时再展开。
-
自动化过程:找到重复计算的结点(红色结点),如果该结点的所有叶子结点都是重复计算结点,则该结点也是重复计算结点,由叶子结点逐层向上查找所有重复结点,直到结点遍历查找完,找到所有红白结点的连接线,插入User特征扩展结点,对User特征进行展开。

3.3.4 融合优化
-
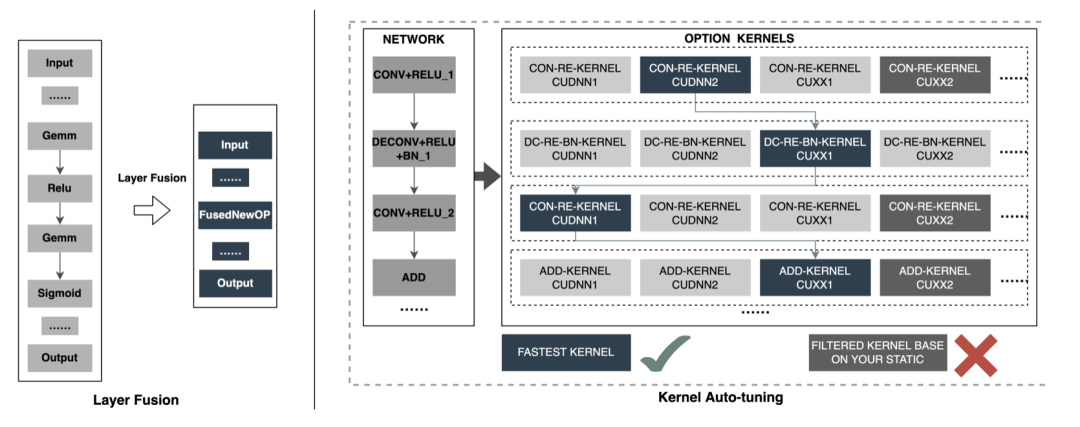
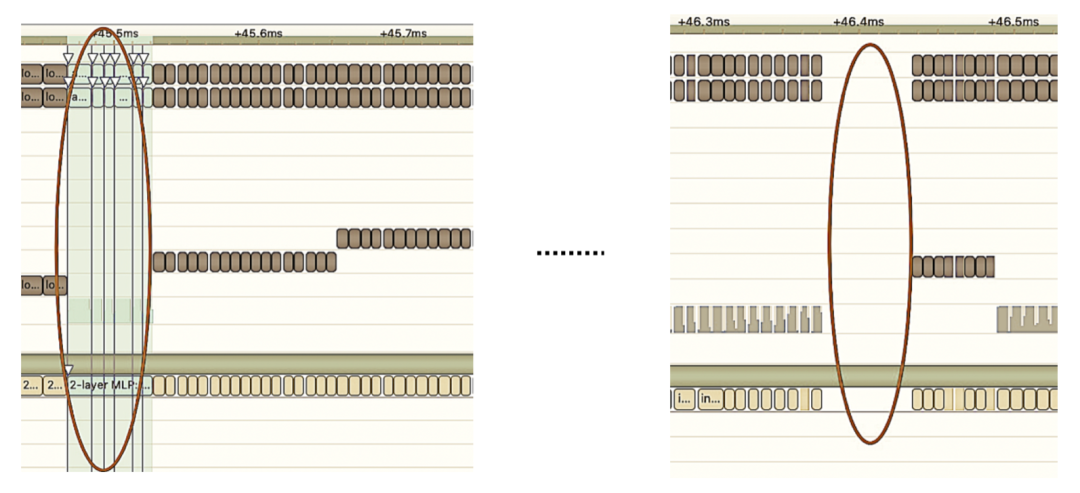
Layer Fusion:TensorRT通过对层间的横向或纵向合并,使网络层的数量大大减少,简单说就是通过融合一些计算op或者去掉一些多余op,来减少数据流通次数、显存的频繁使用以及调度的开销。比如常见网络结构Convolution And ElementWise Operation融合、CBR融合等,下图是整个网络结构中的部分子图融合前后结构图,FusedNewOP在融合过程中可能会涉及多种Tactic,比如CudnnMLPFC、CudnnMLPMM、CudaMLP等,最终会根据时长选择一个最优的Tactic作为融合后的结构。通过融合操作,使得网络层数减少、数据通道变短;相同结构合并,使数据通道变宽;达到更加高效利用GPU资源的目的。
-
Kernel Auto-Tuning:网络模型在inference时,是调用GPU的CUDA kernel进行计算。TensorRT可以针对不同的网络模型、显卡结构、SM数量、内核频率等进行CUDA kernel调整,选择不同的优化策略和计算方式,寻找适合当前的最优计算方式,以保证当前模型在特定平台上获得最优的性能。上图是优化主要思想,每一个op会有多种kernel优化策略(cuDNN、cuBLAS等),根据当前架构从所有优化策略中过滤低效kernel,同时选择最优kernel,最终形成新的Network。

3.3.5 引擎优化
-
多模型:由于外卖广告中用户请求规模不确定,广告时多时少,为此加载多个模型,每个模型对应不同输入的Batch,将输入规模分桶归类划分,并将其padding到多个固定Batch,同时对应到相应的模型进行inference。
-
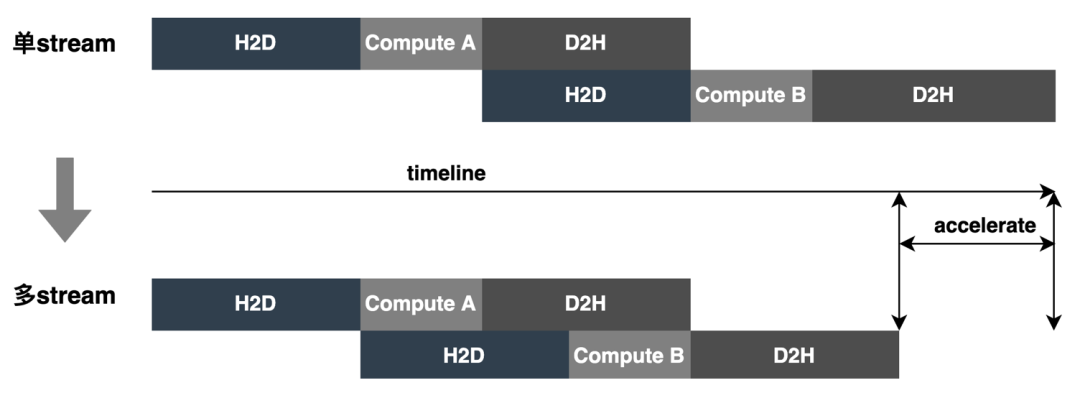
Multi-contexts和Multi-streams:对每一个Batch的模型,使用多context和多stream,不仅可以避免模型等待同一context的开销,而且可以充分利用多stream的并发性,实现stream间的overlap,同时为了更好的解决资源竞争的问题,引入CAS。如下图所示,单stream变成多stream:
-
Dynamic Shape:为了应对输入Batch不定场景下,不必要的数据padding,同时减少模型数量降低显存等资源的浪费,引入Dynamic Shape,模型根据实际输入数据进行inference,减少数据padding和不必要的计算资源浪费,最终达到性能优化和吞吐提升的目的。
-
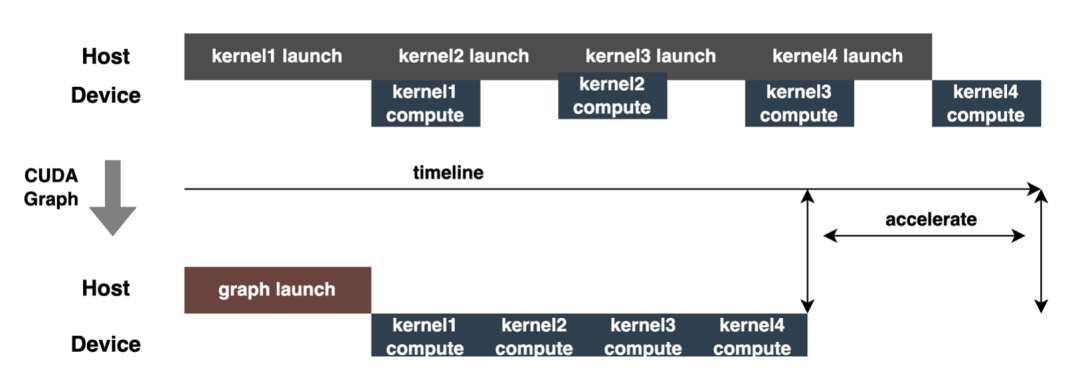
CUDA Graph:现代GPU每个operation(kernel运行等)所花费的时间至少是微秒级别,而且,将每个operation提交给GPU也会产生一些开销(微秒级别)。实际inference时,经常需要执行大量的kernel operation,这些operation每一个都单独提交到GPU并独立计算,如果可以把所有提交启动的开销汇总到一起,应该会带来性能的整体提升。CUDA Graph可以完成这样的功能,它将整个计算流程定义为一个图而不是单个操作的列表,然后通过提供一种由单个CPU操作来启动图上的多个GPU操作的方法减少kernel提交启动的开销。CUDA Graph核心思想是减少kernel launch的次数,通过在推理前后capture graph,根据推理的需要进行update graph,后续推理时不再需要一次一次的kernel launch,只需要graph launch,最终达到减少kernel launch次数的目的。如下图所示,一次inference执行4次kernel相关操作,通过使用CUDA Graph可以清晰看到优化效果。
-
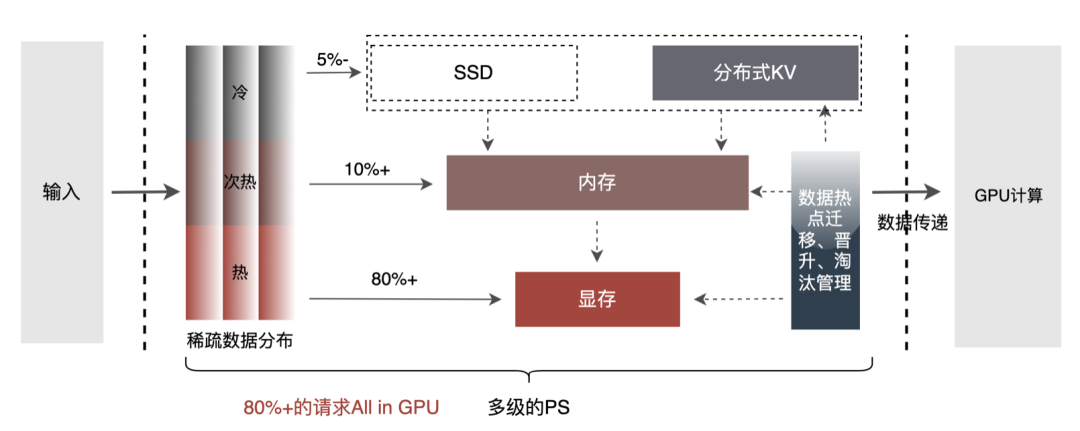
多级PS:为了进一步挖掘GPU加速引擎性能,对Embedding数据的查询操作可通过多级PS的方式进行:GPU显存Cache->CPU内存Cache->本地SSD/分布式KV。其中,热点数据可缓存在GPU显存中,并通过数据热点的迁移、晋升和淘汰等机制对缓存数据进行动态更新,充分挖掘GPU的并行算力和访存能力进行高效查询。经离线测试,GPU Cache查询性能相比CPU Cache提升10倍+;对于GPU Cache未命中数据,可通过访问CPU Cache进行查询,两级Cache可满足90%+的数据访问;对于长尾请求,则需要通过访问分布式KV进行数据获取。具体结构如下:
3.3.6 Pipeline
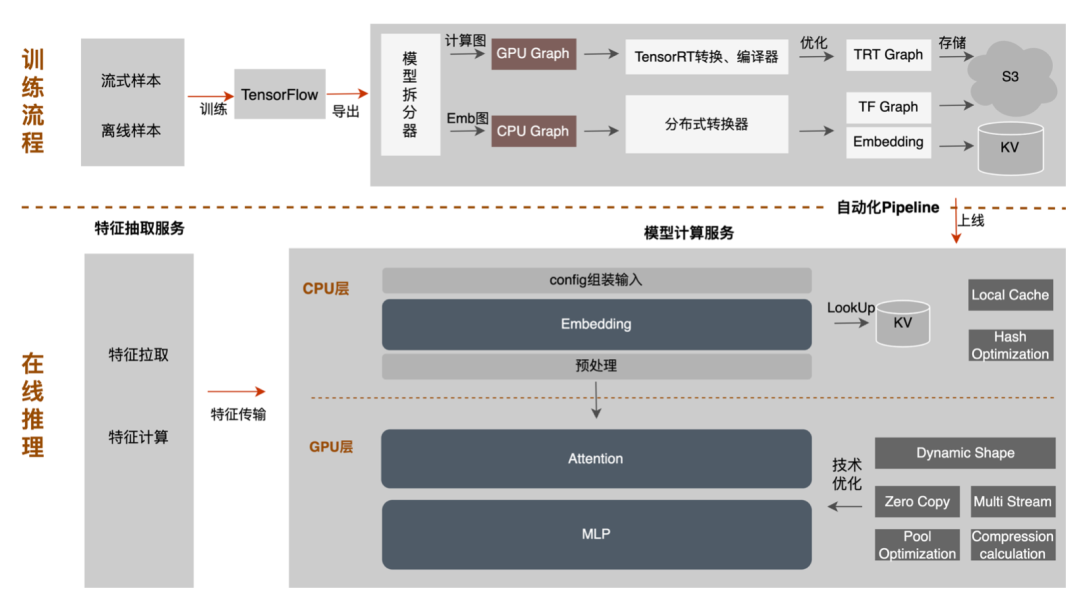
-
离线侧:只需提供模型拆分节点,平台会自动将原始TF模型拆分成Embedding子模型和计算图子模型,其中Embedding子模型通过分布式转换器进行分布式算子替换和Embedding导入工作;计算图子模型则根据选择的硬件环境(GPU型号、TensorRT版本、CUDA版本)进行TensorRT模型的转换和编译优化工作,最终将两个子模型的转换结果存储到S3中,用于后续的模型部署上线。整个流程都是平台自动完成,无需使用方感知执行细节。 -
在线测:只需选择模型部署硬件环境(与模型转换的环境保持一致),平台会根据环境配置,进行模型的自适应推送加载,一键完成模型的部署上线。
4 特征服务CodeGen优化
4.1 全流程CodeGen优化

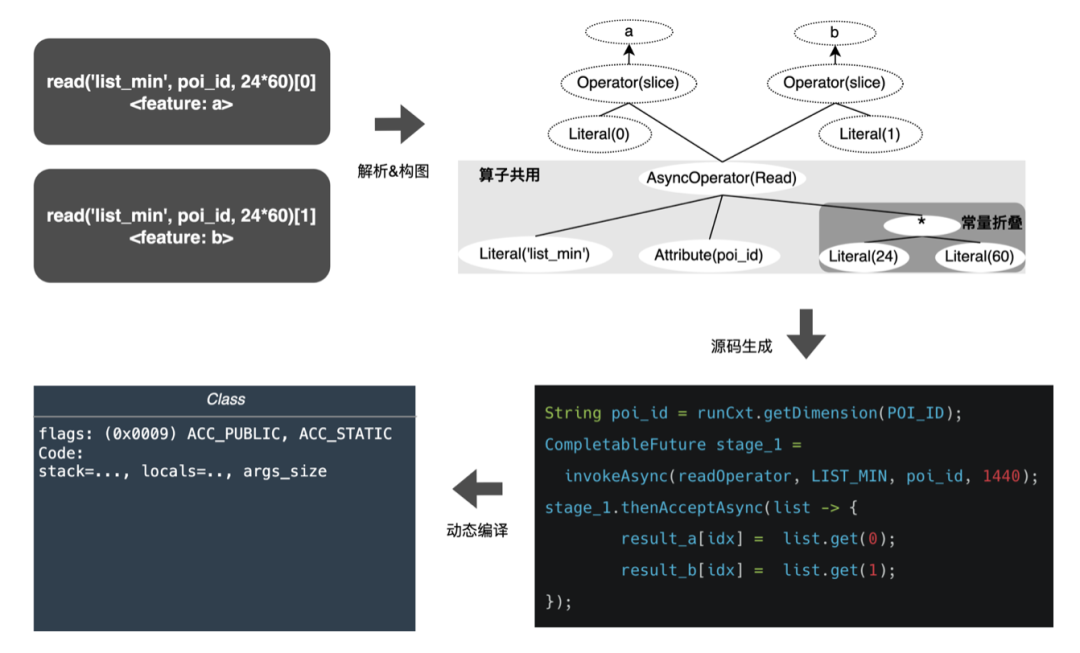
-
前端:每个模型对应一张节点DAG图,逐个解析每个特征计算DSL,生成AST,并将AST节点添加到图中。 -
优化器:针对DAG节点进行优化,比如公共算子提取、常量折叠等。 -
后端:将经过优化后的图编译成字节码。
-
读取算子:从存储系统获取特征的过程,是个IO型任务。比如查询远程KV系统。 -
转换算子:特征获取到本地之后对特征进行转换,是个计算密集型任务。比如对特征值做Hash。
-
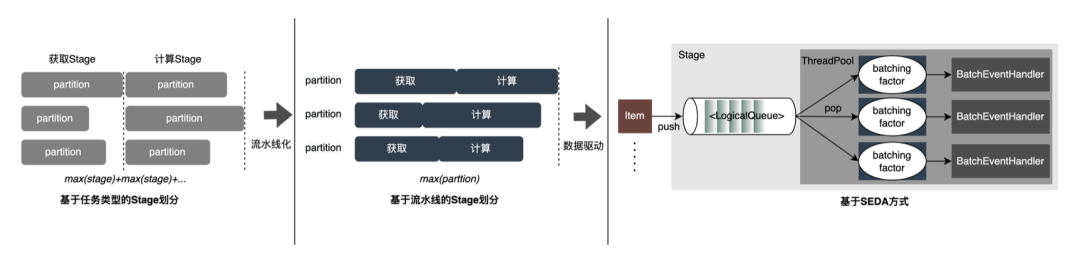
基于任务类型划分Stage:将整个流程划分成获取和计算两种Stage,Stage内部分片并行处理,上一个Stage完成后再执行下一个Stage。这是我们早期使用的方案,实现简单,可以基于不同的任务类型选择不同的分片大小,比如IO型任务可以使用更大的分片。但缺点也很明显,会造成不同Stage的长尾叠加,每个Stage的长尾都会影响整个流程的耗时。
-
基于流水线划分Stage:为了减少不同Stage的长尾叠加,可以先将数据分片,为每个特征读取分片添加回调,在IO任务完成后回调计算任务,使整个流程像流水线一样平滑。分片调度可以让上一个Stage就绪更早的分片提前进入下一个Stage,减少等待时间,从而减少整体请求耗时长尾。但缺点就是统一的分片大小不能充分提高每个Stage的利用率,较小的分片会给IO型任务带来更多的网络消耗,较大的分片会加剧计算型任务的耗时。
-
基于SEDA(Staged Event-Driven Architecture)方式:阶段式事件驱动方式使用队列来隔离获取Stage和计算Stage,每个Stage分配有独立的线程池和批处理处理队列,每次消费N(batching factor)个元素。这样既能够实现每个Stage单独选择分片大小,同时事件驱动模型也可以让流程保持平滑。这是我们目前正在探索的方式。
4.2 传输优化

-
扩展性差:数据格式统一,不兼容非数值类型的特征值。
-
传输性能损耗:基于矩阵格式,需要对特征做对齐,比如Query/User维度需要被拷贝对齐到每个Item上,增大了请求计算层的网络传输数据量。
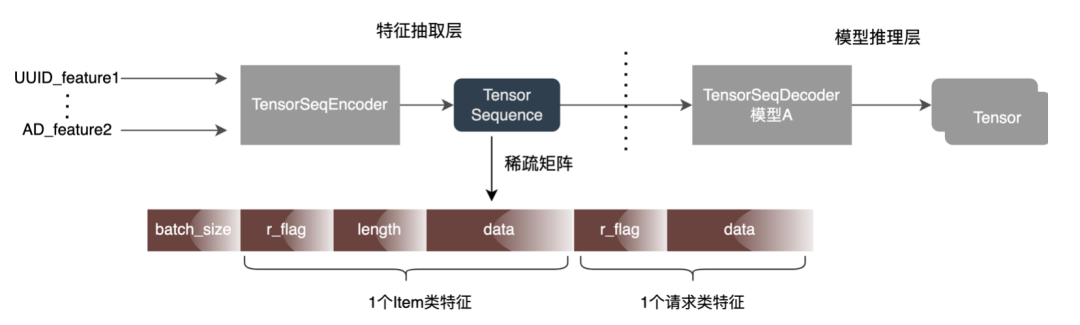
4.3 高维ID特征编码
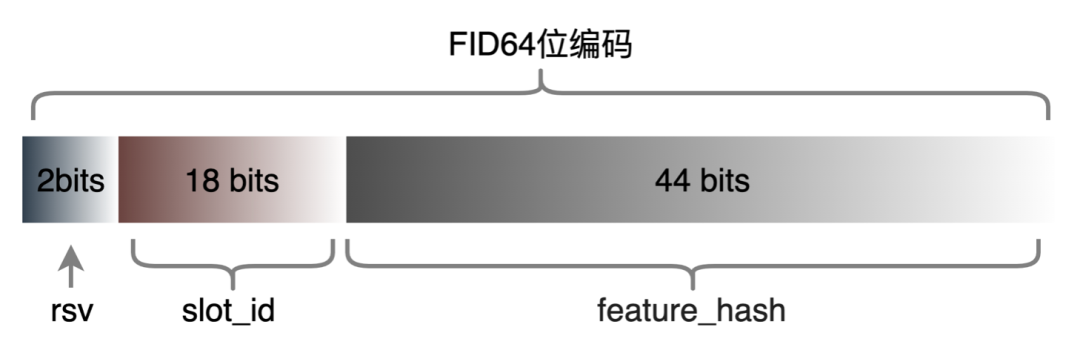
5 样本构建
5.1 流式样本

-
就绪时间长:在现有资源限制下,跑那么大数据几乎要在T+2才能将样本数据就绪,影响算法模型迭代。 -
资源耗费大:现有样本收集方式是将所有请求计算特征后与曝光、点击进行拼接,由于对未曝光Item进行了特征计算、数据落表,导致存储的数据量较大,耗费大量资源。
5.1.1 常见的方案
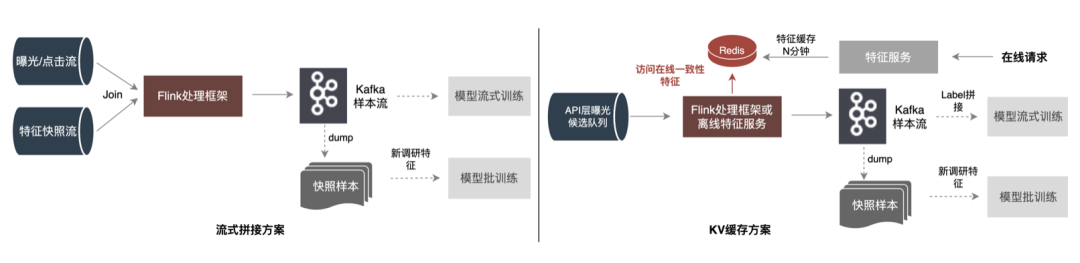
-
流式拼接方案:借助流式处理框架(Flink、Storm等)低延迟的流处理能力,直接读取曝光/点击实时流,与特征快照流数据在内存中进行关联(Join)处理;先生成流式训练样本,再转存为模型离线训练样本。其中流式样本和离线样本分别存储在不同的存储引擎中,支持不同类型的模型训练方式。此方案的问题:在数据流动环节的数据量依然很大,占用较多的消息流资源(比如Kafka);Flink资源消耗过大,如果每秒百G的数据量,做窗口Join则需要30分钟×60×100G的内存资源。 -
KV缓存方案:把特征抽取的所有特征快照写入KV存储(如Redis)缓存N分钟,业务系统通过消息机制,把候选队列中的Item传入到实时计算系统(Flink或者消费应用),此时的Item的量会比之前请求的Item量少很多,这样再将这些Item特征从特征快照缓存中取出,数据通过消息流输出,支持流式训练。这种方法借助了外存,不管随着特征还是流量增加,Flink资源可控,而且运行更加稳定。但突出的问题还是需要较大的内存来缓存大批量数据。
5.1.2 改进优化
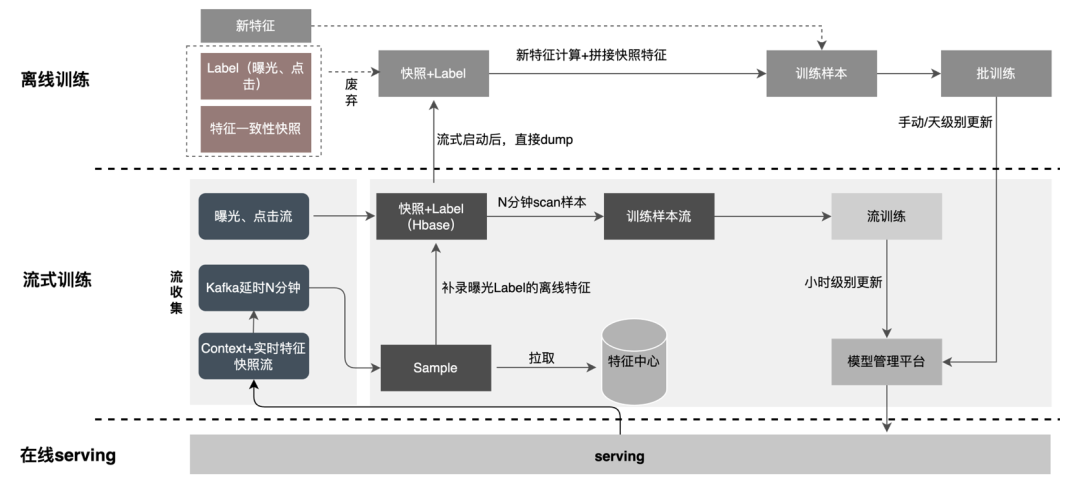
-
样本流中只有上下文+实时特征,增加读取数据流稳定性,同时由于只需要存储实时特征,Kafka硬盘存储下降10+倍。
-
曝光流作为主流,写入到HBase中,同时为了后续能让其他流在HBase中Join上曝光,将RowKey写入Redis;后续流通过RowKey写入HBase,曝光与点击、特征的拼接借助外存完成,保证数据量增大后系统能稳定运行。
-
样本流延时消费,后台服务的样本流往往会比曝光流先到,为了能Join上99%+的曝光数据,样本流等待窗口统计至少要N分钟以上;实现方式是将窗口期的数据全部压在Kafka的磁盘上,利用磁盘的顺序读性能,省略掉了窗口期内需要缓存数据量的大量内存。
5.2 结构化存储
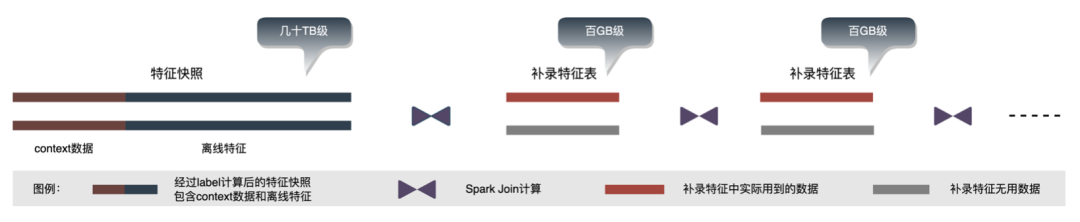
-
数据冗余:补录特征的离线表一般为全量数据,条数在亿级别,样本构建用到的条数约为当日DAU的数量即千万级别,因此补录的特征表数据在参与计算时存在冗余数据。
-
Join顺序:补录特征的计算过程即维度特征补全,存在多次Join计算,因此Join计算的性能和Join的表的顺序有很大关系,如上图所示,如果左表为几十TB级别的大表,那么之后的shuffle计算过程都会产生大量的网络IO、磁盘IO。
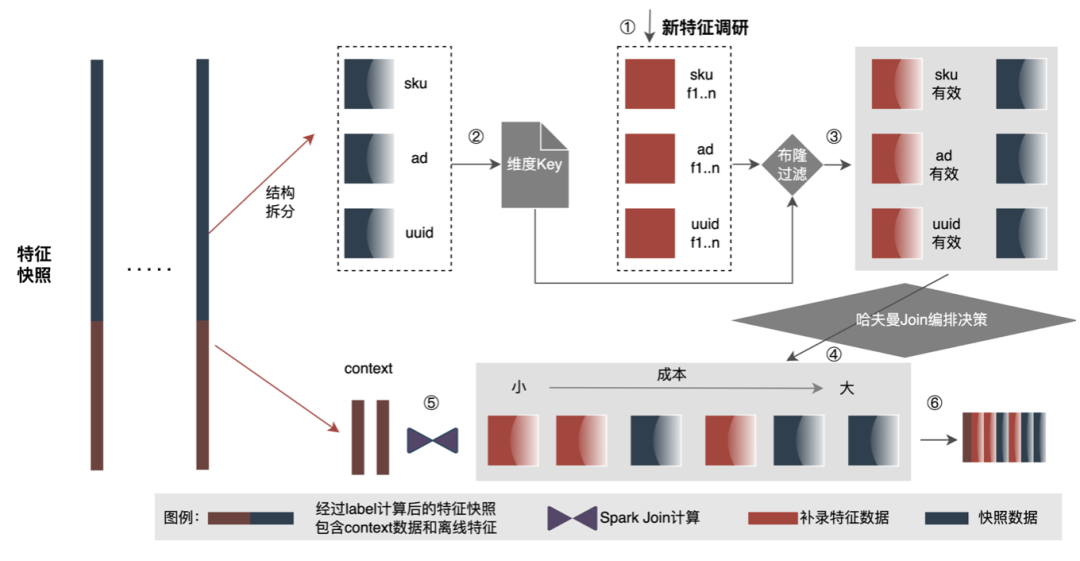
-
结构化拆分。数据拆分成Context数据和结构化存储的维度数据代替混合存储。解决Label样本拼接新特征过程中携带大量冗余数据问题;并且做结构化存储后,针对离线特征,得到了很大的存储压缩。
-
高效过滤前置。数据过滤提前到Join前,减少参与特征计算的数据量,可以有效降低网络IO。在拼接过程中,补录特征的Hive表一般来说是全量表,数据条数一般为月活量,而实际拼接过程中使用的数据条数约为日活量,因此存在较大的数据冗余,无效的数据会带来额外的IO和计算。优化方式为预计算使用的维度Key,并生成相应的布隆过滤器,在数据读取的时候使用布隆过滤器进行过滤,可以极大降低补录过程中冗余数据传输和冗余计算。
-
高性能Join。使用高效的策略去编排Join顺序,提升特征补录环节的效率和资源占用。在特征拼接过程中,会存在多张表的Join操作,Join的先后顺序也会极大影响拼接性能。如上图所示,如果拼接的左表数据量较大时,那么整体性能就会差。可以使用哈夫曼算法的思想,把每个表看作一个节点,对应的数据量量看成是他的权重,表之间的Join计算量可以简单类比两个节点的权重相加。因此,可以将此问题抽象成构造哈夫曼树,哈夫曼树的构造过程即为最优的Join顺序。
6 数据准备
6.1 做“加法”

-
特征感知:通过上线墙或业务间存量方式触发特征推荐,这些特征已经过一定验证,可以保证特征推荐的成功率。
-
样本生产:样本生产时通过配置文件抽取特征,流程自动将新增特征加到配置文件中,然后进行新样本数据的生产。获取到新特征后,解析这些特征依赖的原始特征、维度、和UDF算子等,将新特征配置和依赖的原始数据融合到基线模型的原有配置文件中,构造出新的特征配置文件。自动进行新样本构建,样本构建时通过特征名称在特征仓库中抽取相关特征,并调用配置好的UDF进行特征计算,样本构建的时间段可配置。
-
模型训练:自动对模型结构和样本格式配置进行改造,然后进行模型训练,使用TensorFlow作为模型训练框架,使用tfrecord格式作为样本输入,将新特征按照数值类和ID类分别放到A和B两个组中,ID类特征进行查表操作,然后统一追加到现有特征后面,不需要修改模型结构便可接收新的样本进行模型训练。
-
自动配置新模型训练参数:包括训练日期、样本路径、模型超参等,划分出训练集和测试集,自动进行新模型的训练。
-
模型评测:调用评估接口得到离线指标,对比新老模型评测结果,并预留单特征评估结果,打散某些特征后,给出单特征贡献度。将评估结果统一发送给用户。

6.2 做“减法”

-
特征打分:通过WOE(Weight Of Evidence, 证据权重)等多种评估算法给出模型的所有特征评分,打分较高特征的质量较高,评估准确率高。
-
效果验证:训练好模型后,按打分排序,分批次对特征进行剔除。具体通过采用特征打散的方法,对比原模型和打散后模型评估结果,相差较大低于阈值后结束评估, 给出可以剔除的特征。
-
端到端方案:用户配置好实验参数和指标阈值后,无需人为干涉,即可给出可删除的特征以及删除特征后模型的离线评估结果。
6.3 做“乘法”
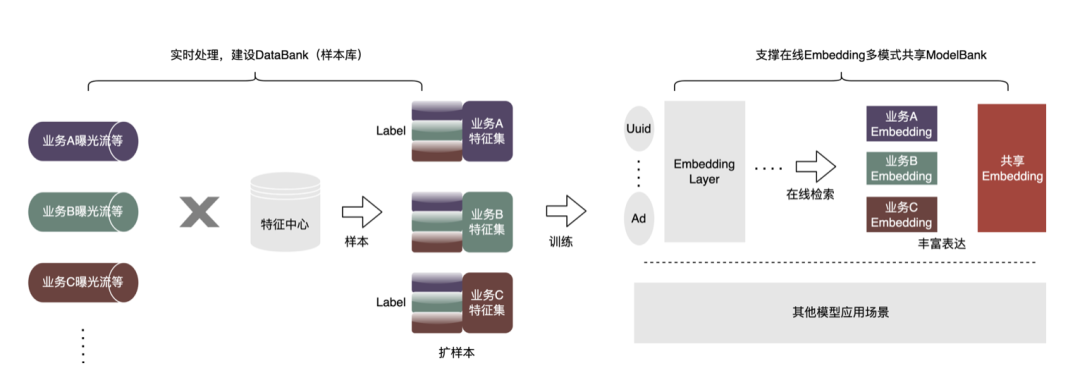
-
扩样本:基于Flink流式处理框架,建设了高扩展样本库DataBank,业务A很方便复用业务B、业务C的曝光、点击等Label数据去做实验。尤其是为小业务线,扩充了大量的价值数据,这种做法相比离线补录Join,一致性会更强,特征平台提供了在线、离线一致性保障。
-
做共享:在样本就绪后,一个很典型的应用场景就是迁移学习。另外,也搭建Embedding共享的数据通路(不强依赖“扩样本”流程),所有业务线可以基于大的Embedding训练,每个业务方也可以update这个Embedding,在线通过建立Embedding版本机制,供多个业务线使用。
6.4 做“除法”

-
问题抽象:如果我们能得到每个特征的价值得分,又可以拿到特征的成本(存储、通信、计算加工),那么问题就转换成了在已知模型结构、固定资源成本下,如何让特征的价值最大化。
-
成本约束下的价值评估:基于模型的特征集,平台首先进行成本和价值的统计汇总;成本包括了离线成本和在线成本,基于训练好的评判模型,得出特征的综合排序。
-
分场景建模:可以根据不同的资源情况,选择不同的特征集,进行建模。在有限的资源下,选择价值最大的模型在线Work。另外,可以针对比较大的特征集建模,在流量低峰启用,提升资源利用率的同时给业务带来更大收益。还有一种应用场景是流量降级,推理服务监控在线资源的消耗,一旦资源计算达到瓶颈,切换到降级模型。
7 总结与展望
-
全链路GPU化:在推理层面,通过GPU的切换,支撑更复杂业务迭代的同时,整体成本也极大的降低,后面会在样本构建、特征服务上进行GPU化改造,并协同推进离线训练层面的升级。
-
样本数据湖:通过数据湖的Schema Evolution、Patch Update等特性构建更大规模的样本仓库,对业务方进行低成本、高价值的数据透出。
-
Pipeline:算法全生命周期迭代过程中,很多环节的调试,链路信息都不够“串联”,以及离线、在线、效果指标的视角都比较割裂,基于全链路的标准化、可观测大势所趋,并且这是后续链路智能化弹性调配的基础。现在业界比较火的MLOps、云原生都有较多的借鉴思路。
-
数据、模型智能匹配:上文提到在模型结构固定前提下,自动为模型加、减特征,同理在模型层面,固定一定特征输入前提下,去自动嵌入一些新的模型结构。以及在未来,我们也将基于业务领域,通过平台的特征、模型体系,自动化地完成数据、模型的匹配。
8 本文作者
本文转载自 校娅 沈元 朱迪等 美团技术团队,原文链接:https://mp.weixin.qq.com/s/ESk1SJDnWAD6kHhJXl_tbw。