
第一部分
简介
Flink 可以同时支持有限数据集和无限数据集的分布式处理。在最近几个版本中,Flink 逐步实现了流批一体的 DataStream API 与 Table / SQL API。大部分用户都同时有流处理与批处理的需求,流批一体的开发接口可以帮助这些用户减小开发、运维与保证两类作业处理结果一致性等方面的复杂度, 例如阿里巴巴双十一的场景[1] 。
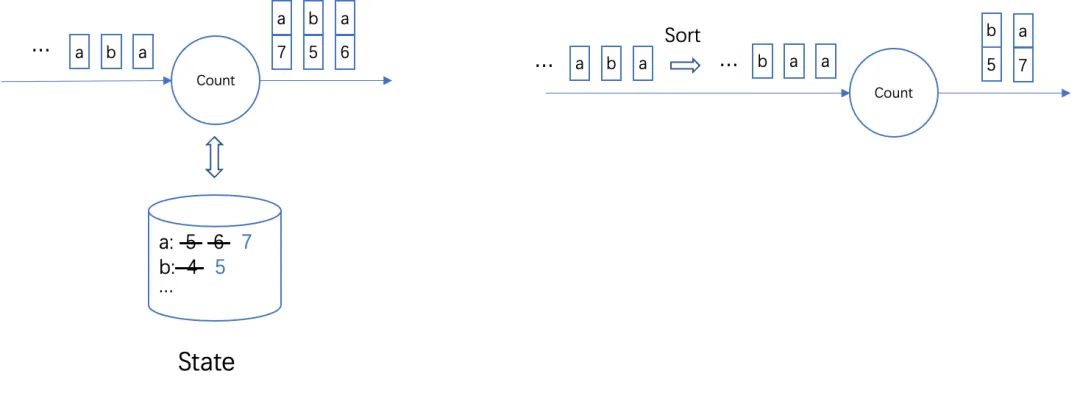

-
支持任务结束后继续进行 Checkpoint 操作。 -
修正作业结束的流程,保证所有数据都可以被正常提交。
支持包含结束任务的 Checkpoint
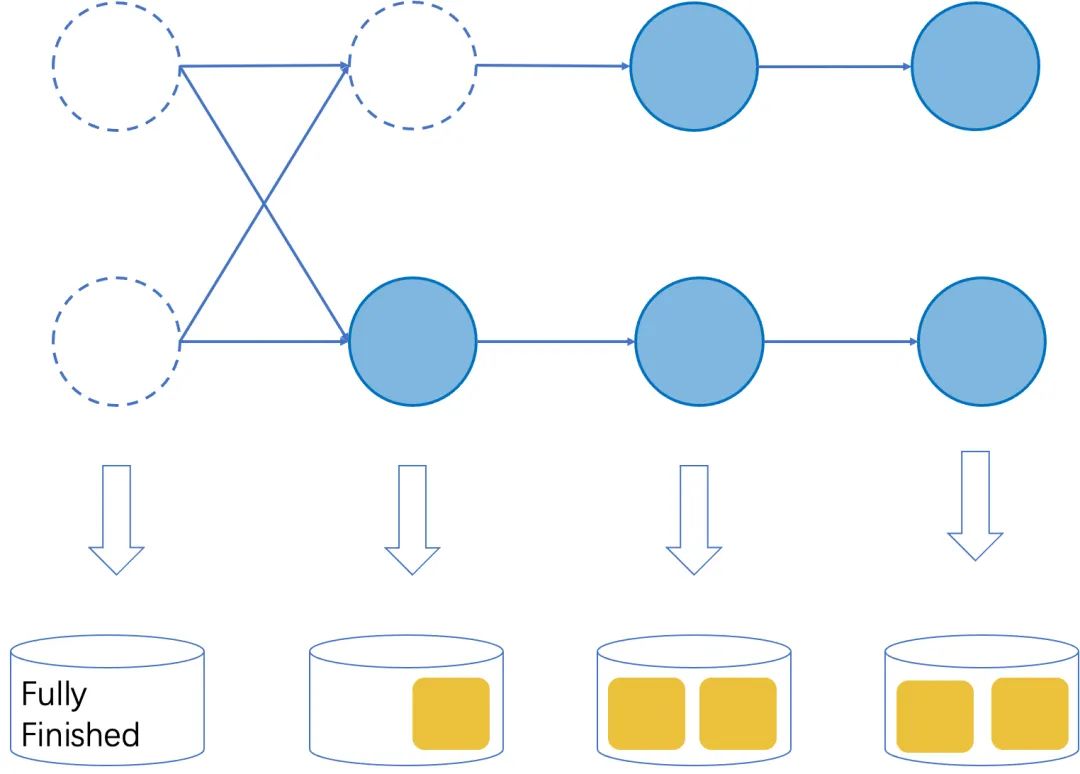
修正作业结束的流程
-
所有数据源都是有限的,这种情况下作业会在处理完所有输入数据并提交所有输出到外部系统后结束。 -
用户显式执行 stop-with-savepoint [–drain] 操作。这种情况下作业会创建一个 Savepoint 后结束。如果指定了 –drain,作业将永久结束,这种情况下需要完成所有外部系统中临时数据的提交。另一方面,如果没有指定该参数,那么作业预期后续会基于该 Savepoint 重启,这种情况下则不需要一定完成所有临时数据的提交,只要保持 Savepoint 中记录的状态与外部系统中临时数据的状态一致即可。

-
finish() 标记着所有的算子已经执行完成,并且不会再产生新的数据。因此,只有当作业正常结束并且已经完全执行完成(即所有数据源执行结束或者用户使用了stop-with-savepoint –drain)的情况下才会调用。 -
close() 在所有情况下都会调用,用于释放任务占用的资源。
包含结束任务的 Checkpoint 实现
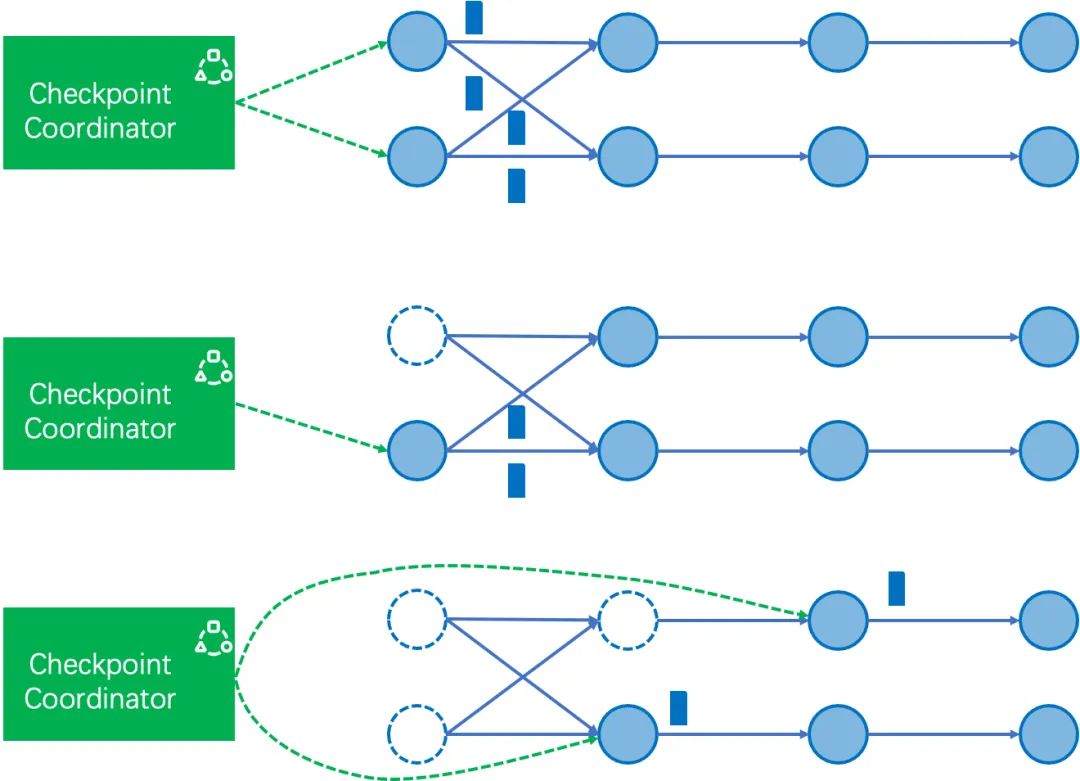
-
完全执行结束:如果一个算子的所有并发实例都执行完成,该算子可以被认为完全执行结束,在重启后可以跳过该算子的执行。我们就需要对这些算子打标。 -
部分执行结束:如果一个算子的部分实例执行完成,那么它在作业重启后需要继续执行剩余的逻辑。整体上我们可以认为这种情况下算子的状态是由所有仍在执行的并发实例的状态组成的,这些状态可以代表尚未执行完成的逻辑。 -
没有完成的实例:这种情况下算子状态与现有实现相同。
-
Broadcast State 在重启后总是将第一个并发实例的状态广播给所有的新的并发实例。但是,如果第一个并发实例已经执行结束,那么它的状态将为空,这将导致所有并发实例的状态变为空,算子将从头执行,这是不符合预期的。 -
Union Operator State 在重启后会将所有算子的状态聚合后分发给所有的新的并发实例。基于这一行为,许多算子可能会选择其中一个并发实例来存储所有并发实例共享的状态。类似的,如果所选中的并发实例已经执行结束,那么这部分状态就丢失了。
修正后的作业结束流程
原作业结束流程
■ 所有数据源结束
MAX_WATERMARK (Long.MAX_VALUE) 然后开始结束任务。在结束过程中,任务将依次对所有算子调用 endOfInput()、close()、和dispose(),然后向下游发送 EndOfPartitionEvent 事件。后续任务在收所有输入边中都读到 EndOfPartitionEvent 事件后,也会开始执行结束流程,这一过程不断重复直到所有任务都结束。1. Source operators emit MAX_WATERMARK
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event-time timers
b. Emit MAX_WATERMARK
3. Source tasks finished
a. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
4. On received EndOfPartitionEvent for non-source tasks
a. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
■ 用户执行 stop-with-savepoint –drain
1. Trigger a savepoint
2. Sources received savepoint trigger RPC
a. If with –-drain
i. source operators emit MAX_WATERMARK
b. Source emits savepoint barrier
3. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
4. On received savepoint barrier for non-source operators
a. The task blocks till the savepoint succeed
5. Finish the source tasks actively
a. If with –-drain
ii. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
6. On received EndOfPartitionEvent for non-source tasks
a. If with –-drain
i. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
修正后作业结束流程
1. Source tasks finished due to no more records or stop-with-savepoint.
a. if no more records or stop-with-savepoint –-drain
i. source operators emit MAX_WATERMARK
ii. endInput(inputId) for all the operators
iii. finish() for all the operators
iv. emit EndOfData[isDrain = true] event
b. else if stop-with-savepoint
i. emit EndOfData[isDrain = false] event
c. Wait for the next checkpoint / the savepoint after operator finished complete
d. close() for all the operators
e. Emit EndOfPartitionEvent
f. Task cleanup
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
3. On received EndOfData for non-source tasks
a. If isDrain
i. endInput(int inputId) for all the operators
ii. finish() for all the operators
b. Emit EndOfData[isDrain = the flag value of the received event]
4. On received EndOfPartitionEvent for non-source tasks
a. Wait for the next checkpoint / the savepoint after operator finished complete
b. close() for all the operators
c. Emit EndOfPartitionEvent
d. Task cleanup
结论
本文转载自高赟@阿里 Apache Flink,原文链接:https://mp.weixin.qq.com/s/jjZj20GDcscixv5mLECPJA。