
摘要:本文整理自科大讯飞中级大数据工程师汪李之在 Flink Forward Asia 2021 的分享。本篇内容主要分为四个部分:
-
业务简介
-
数仓演进
-
场景实践
-
未来展望
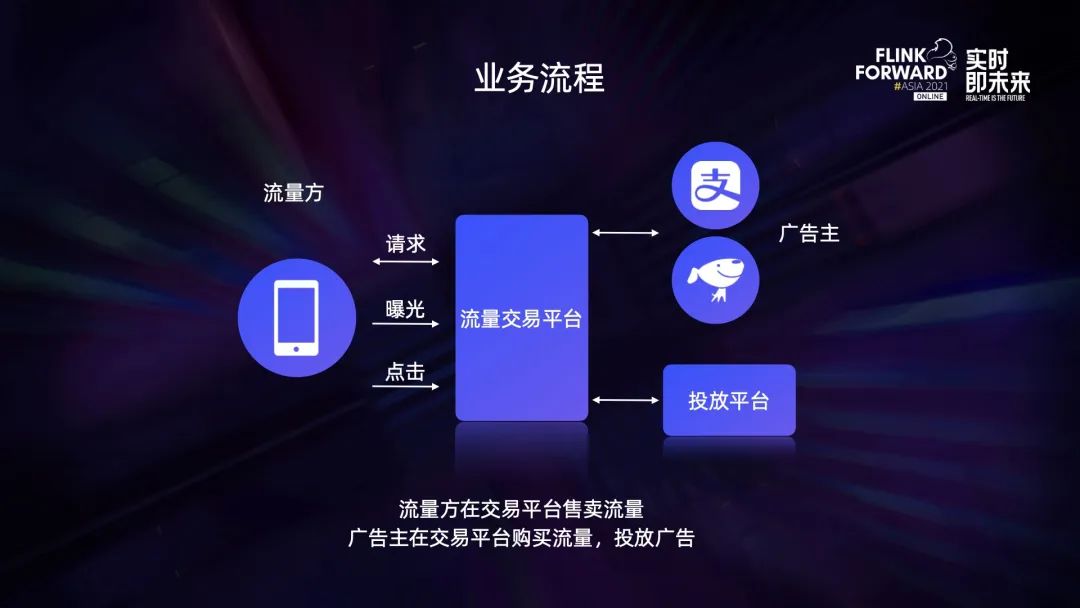
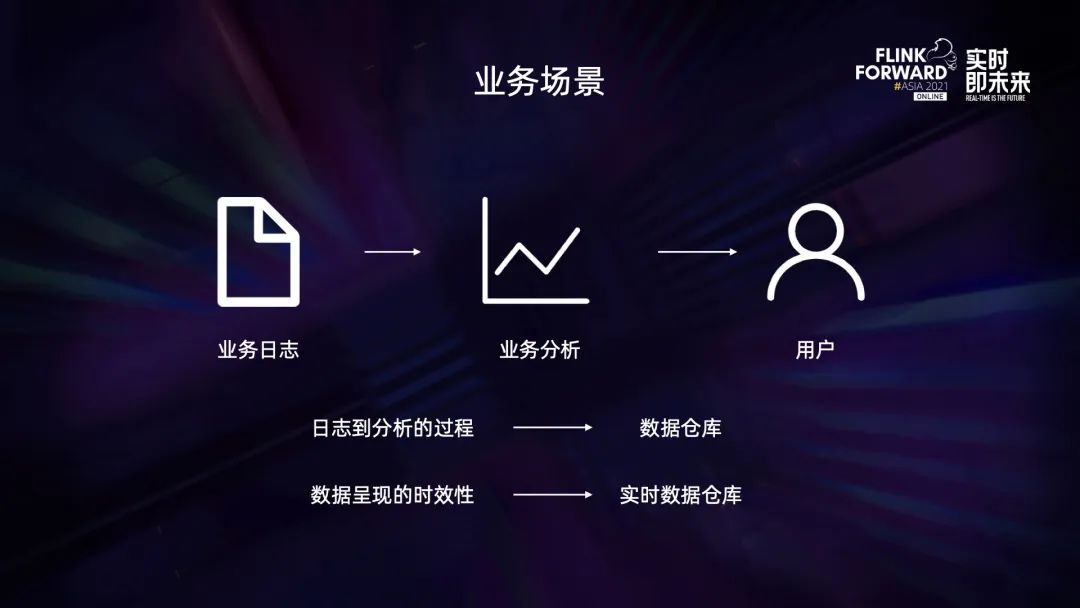
业务简介

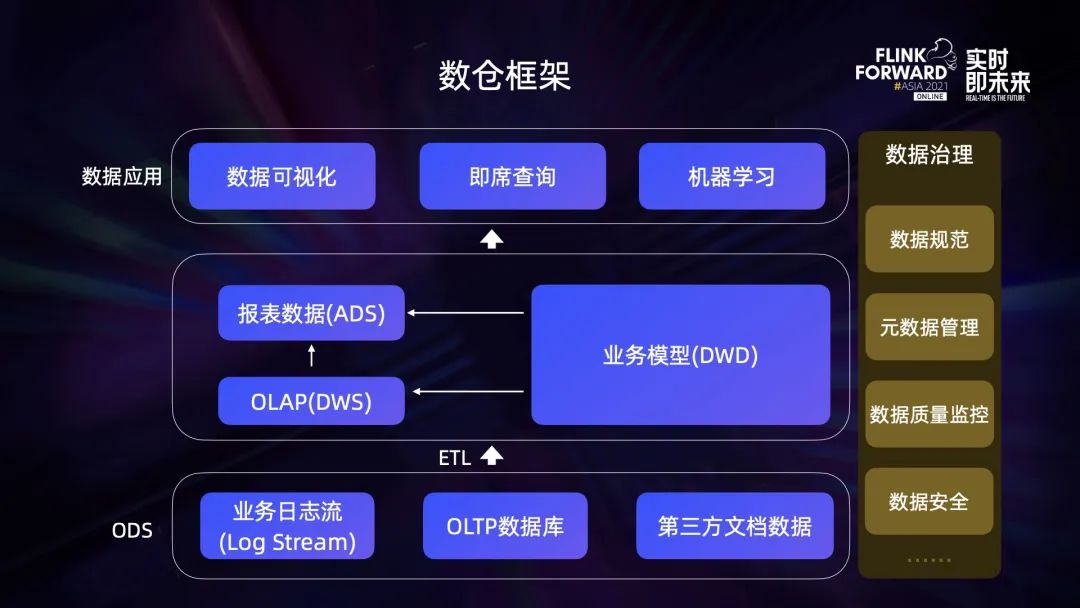
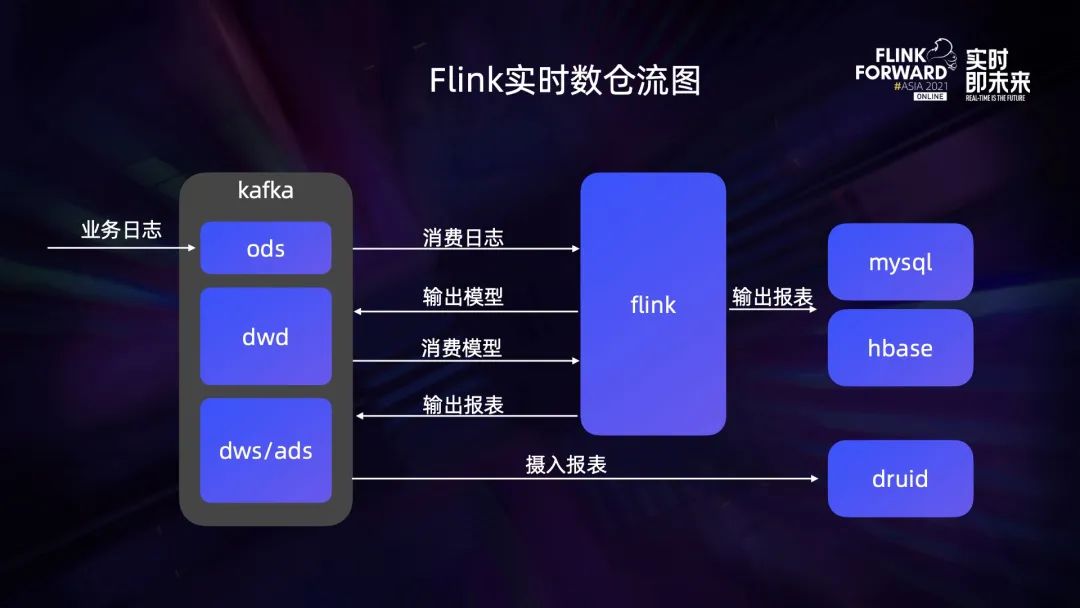
数仓演进


场景实践
3.1 ODS – 日志消费负载均衡
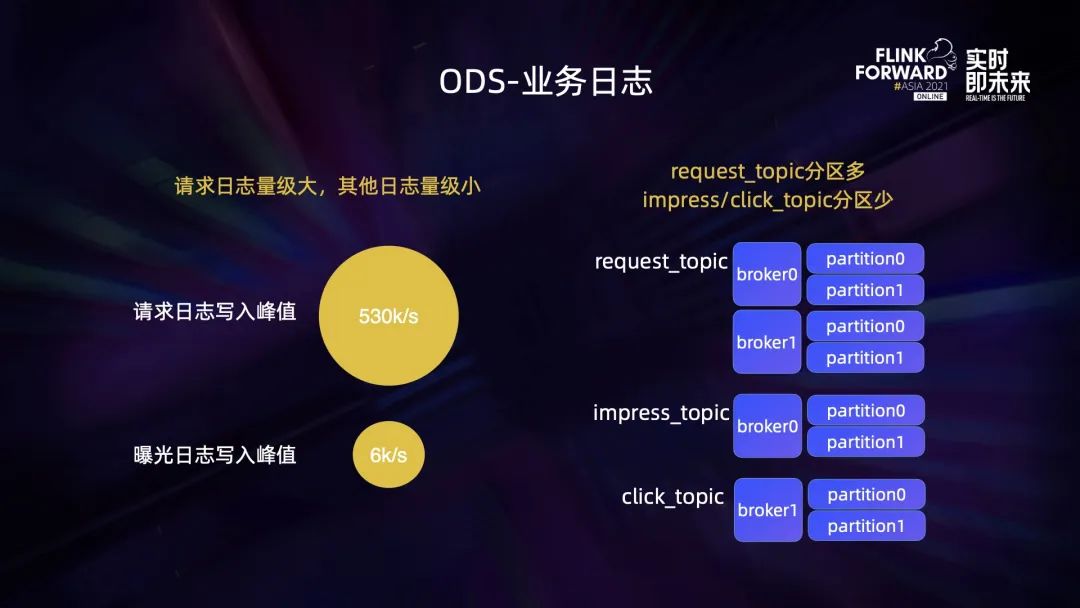

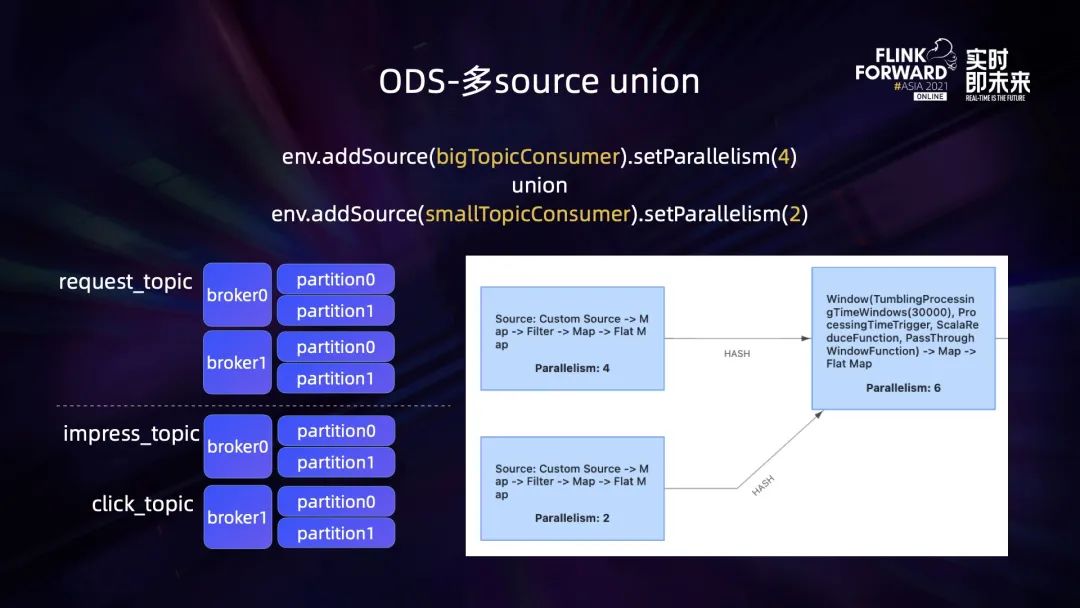
3.2 DWD – 日志关联及状态缓存



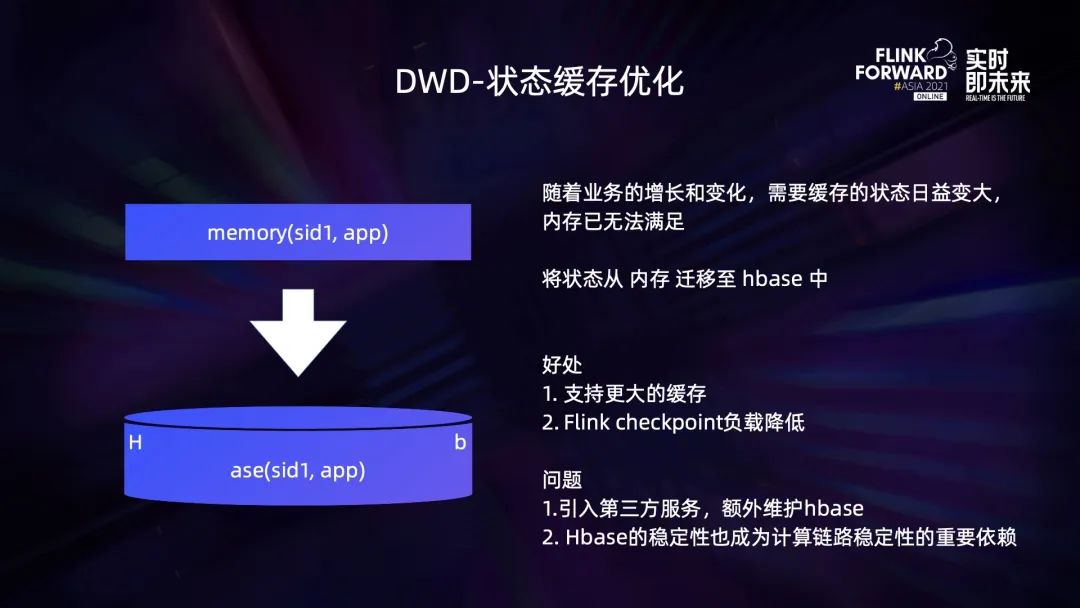
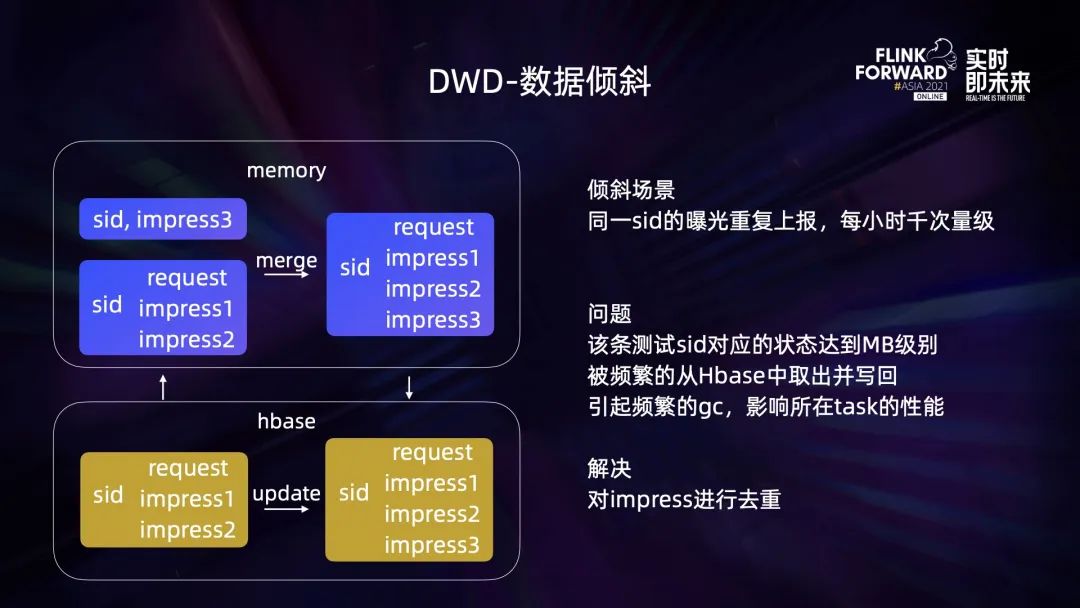
3.3 DWS – 实时 OLAP

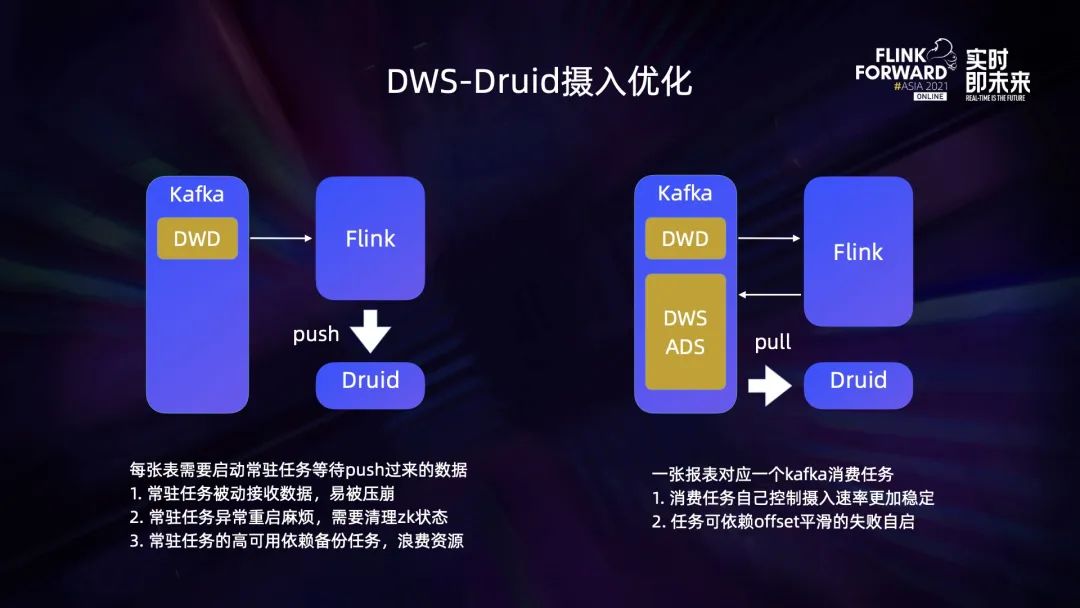
3.4 ADS – 跨源查询

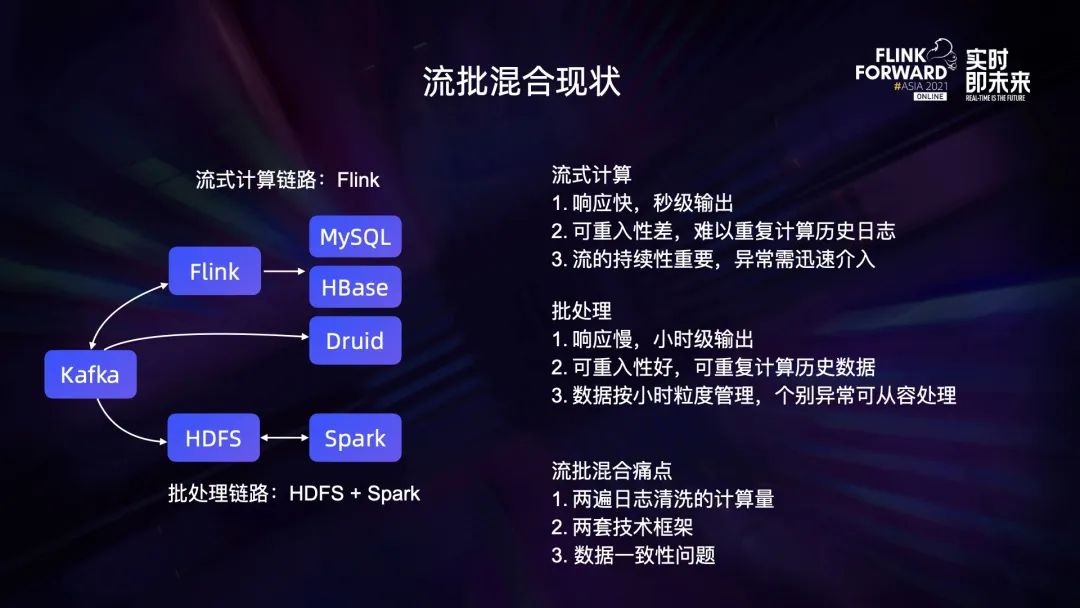
3.5 流批混合现状
-
响应快,秒级输出; -
可重入性差,难以重复计算历史日志; -
流的持续性重要,异常需迅速介入。
-
响应慢,小时级输出; -
可重入性好,可重复计算历史数据; -
数据按小时粒度管理,个别异常可从容处理。
-
两遍日志清洗的计算量; -
两套技术框架; -
数据一致性问题。
未来展望
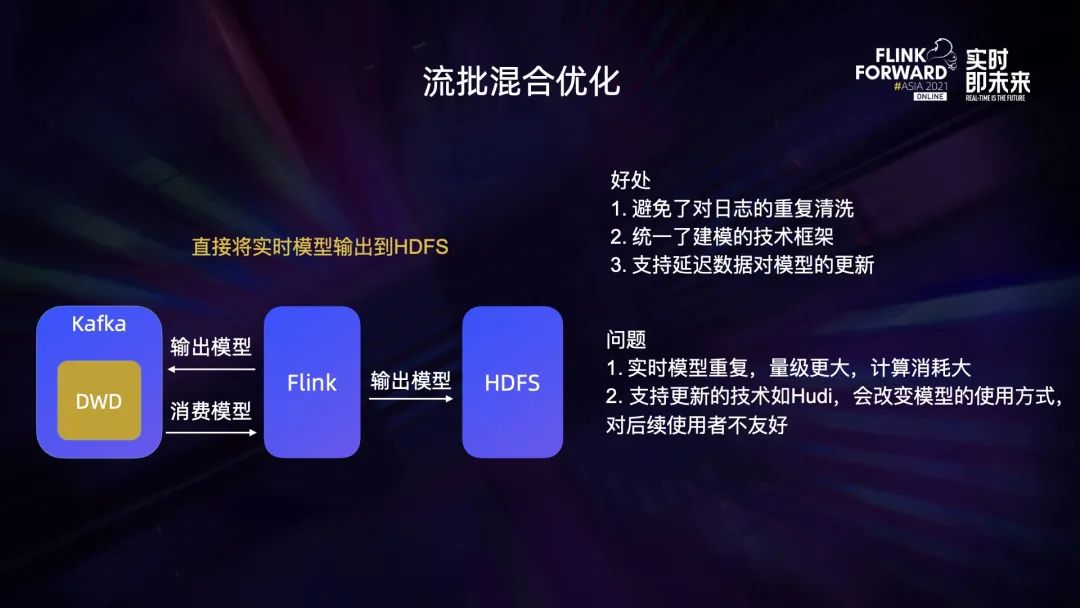
流批混合优化,直接将实时模型输出到 HDFS。
-
避免了对日志的重复清洗; -
统一了建模的技术框架; -
支持延迟数据对模型的更新。
-
实时模型重复,量级更大,计算消耗大; -
支持数据更新的技术如 Hudi,会改变模型的使用方式,对后续使用者不友好。

本文转载自汪李之@科大讯飞 Apache Flink,原文链接:https://mp.weixin.qq.com/s/5AynaTa401LGgnZNLGpE-g。