


分享嘉宾:孙超 小红书 软件工程师
编辑整理:王宇翔
出品平台:DataFunTalk
导读:本文主要介绍了小红书数据流团队基于Apache Iceberg在实时数仓领域的探索与实践。目前小红书对数据湖技术的探索主要分为三个方向,第一个方向是在小红书云原生架构下,对于大规模日志实时入湖的实践,第二个方向是业务数据的CDC实时入湖实践,第三个方向是对实时数据湖分析的探索。
今天的分享也主要围绕这三个方向展开,并在最后介绍我们对未来工作的规划:
-
日志数据入湖
-
CDC实时入湖
-
实时湖分析探索
-
未来规划
01
日志数据入湖
1. 小红书数据平台架构
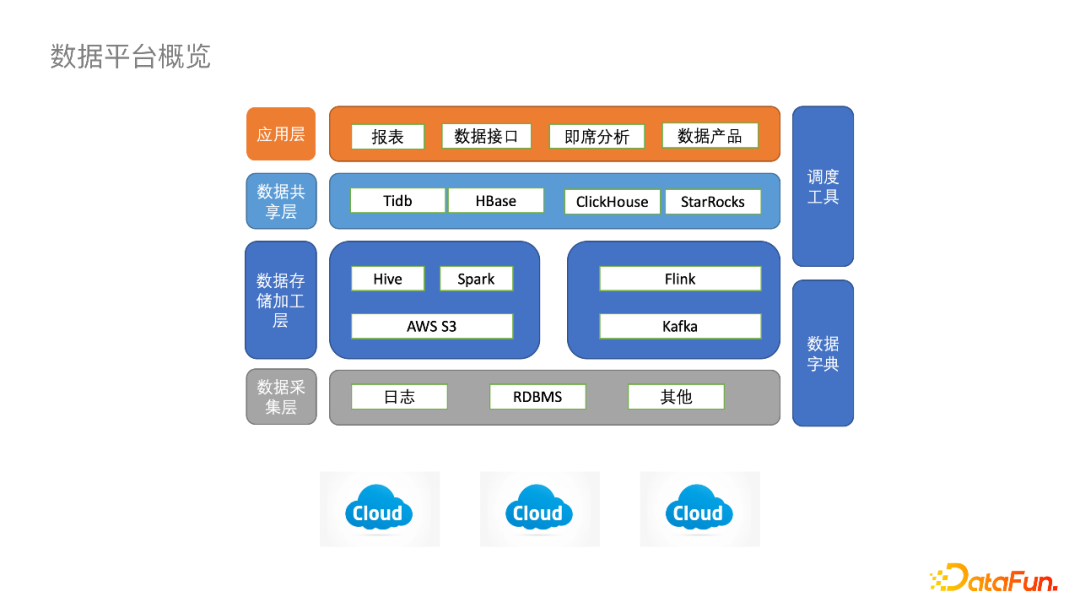
在进入主题之前先介绍一下小红书数据平台的基本架构。
总体来说,小红书数据平台与其他互联网公司大同小异,主要不同在于小红书的基础架构是“长”在多朵公有云之上的。在数据采集层,日志和RDBMS的数据源来自不同的公有云;在数据存储加工层,绝大多数数据会存储于AWS S3对象存储;同时,数仓体系也是围绕着S3来建设的,实时ETL链路基于Kafka、Flink,离线分析链路基于AWS EMR上的Spark、Hive、Presto等;在数据共享层,诸如Clickhouse、StarRocks、TiDB等OLAP引擎,为上层报表提供一些近实时的查询。以上就是小红书数据平台整体的架构组成。
2. APM日志数据入湖
接下来我们用APM(Application Performance Monitor)的例子来介绍Iceberg如何在当前架构体系下运转。
(1)使用Iceberg之前的APM链路
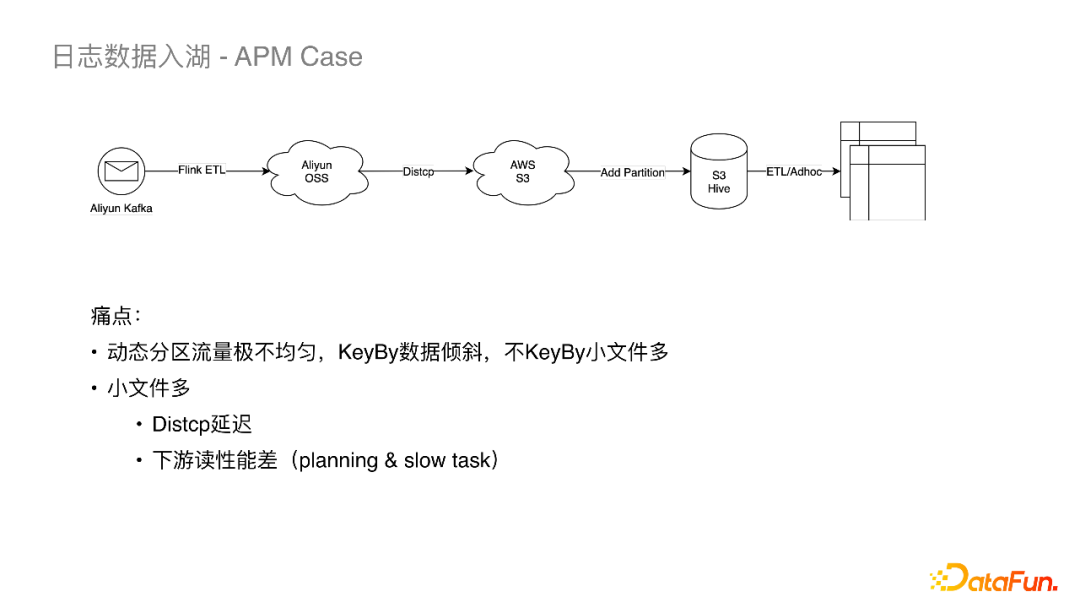
APM主要记录小红书APP前端和客户端性能相关的埋点日志,可以达到百万每秒的RPS。以前的离线链路是先将埋点数据发送到阿里云的Kafka,通过Flink作业落到阿里云的OSS对象存储,然后通过Distcp搬到AWS S3上,之后通过Add Partition落地到Hive表里,接下来下游的EMR集群会对落地的数据做一些离线的ETL作业调度和Adhoc的查询。整条链路中,数仓同学的痛点是Flink ETL作业上数据需要按业务分区动态写入,但是各点位分区之间的流量非常不均匀。这就涉及到动态写分区时候是否要加Keyby,如果加Keyby就会发生数据倾斜,不加Keyby每个写算子的Subtask都会为每个分区创建一个Writer,而分区Writer又至少创建一个文件,同时 Flink Checkpoint 又会放大这个写放大,最终导致小文件数爆炸。
小文件数多后会导致以下几个后果:
-
Distcp会变得非常慢,导致数据延迟在小时级以上。
-
流量小的很多文件集中在一个Task,导致查询性能差。
(2)基于Iceberg的改良链路
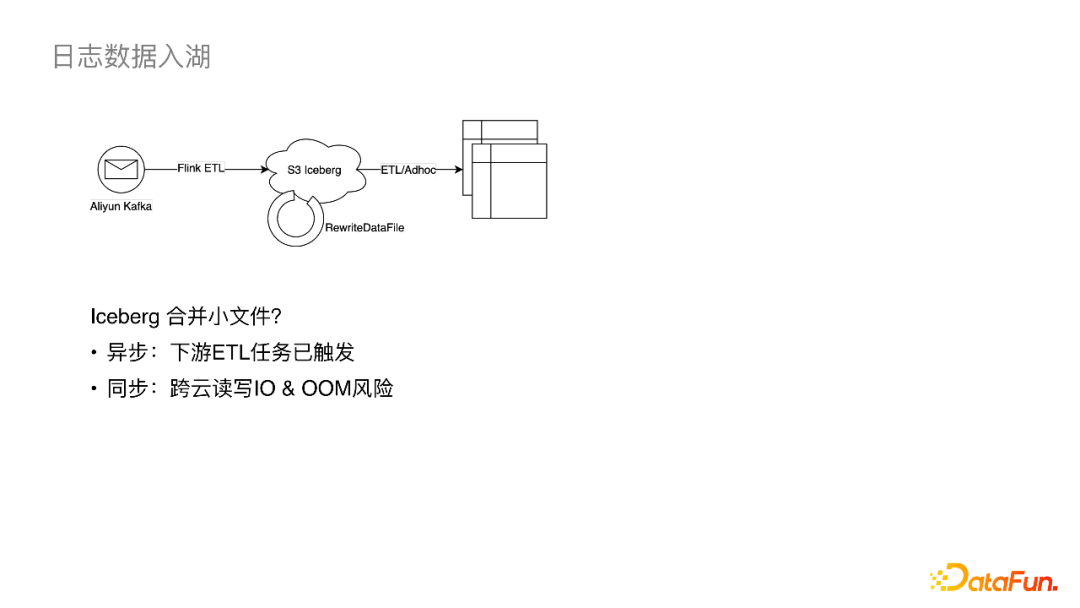
Iceberg支持事务,我们可以利用这个特性来异步合并小文件,这样既不影响主流的写入又可以保障一致性,基于此想法我们可以得到以上的架构图。
该架构简化了落OSS 的步骤,Kafka数据可以直接通过Flink落到S3的Iceberg,之后异步执行合并小文件作业,此后下游就可以直接基于Iceberg做ETL调度。这个链路的问题在于:
-
异步的小文件合并为周期调度,但是Iceberg在commit之后,下游ETL读文件作业会立即执行,在这之后再挂异步合并作业的意义就不大了。
-
如果同步合并小文件,即在Flink入湖作业中挂一个合并算子,这样会引入跨云IO,并增加Flink作业的OOM风险。
所以我们还是决定通过加入Shuffle,从源头解决数据倾斜的问题。我们自主设计了一个EvenPartitionShuffle的算法做数据Shuffle。Iceberg支持将分区级别的统计信息写入到元数据中,这样就可以拿到不同分区的流量分布,再根据下游的并行度,就可以将问题转化为一个类背包问题,类似于Spark的AQE。

对于评估这个算法可以抽象出以下两个指标:
-
Fanout:下游Subtask的分区个数。
-
Residual:下游Subtask的分配流量和与目标流量差距。
这两个指标反映出小文件的个数以及数据倾斜的均匀程度,我们也在这两个指标的评估下来不断调整背包算法。从最终的效果来看,线上作业IcebergStreamWriter各Subtask数据负载还是比较均匀的,也极大减少了小文件数。

以上方案的优缺点如下:
优点:
-
小文件的问题得到了解决。
-
Writer算子内存占用减少。
缺点:
-
引入了Shuffle。
-
流量动态变化。暂时还不能根据流量变化动态调整分区分布,因为当前是在Flink 作业启动的时候读取Iceberg的元数据。
(3)将基于Iceberg的链路应用于小红书多云架构
当解决以上问题之后,让我们来看看如何将以上链路应用在小红书的多云架构上。有两个问题需要解决:跨云流式读写的问题,以及Iceberg与下游系统的集成。
①跨云流式读写

关于Iceberg多云架构下读写的问题,我们先来看以上架构图的组件与数据流。在上面的架构图中高亮标出了Iceberg两个比较重要的抽象:Catalog与FileIO。
Catalog保存了Iceberg最新的元数据的指针,并且需要保证指针变更的原子性。Iceberg提供了HiveCatalog和HadoopCatalog两种实现。HadoopCatalog依赖于文件系统rename接口的原子性,而rename在对象存储上并不是原子操作(对于最新版本的HadoopCatalog,加一个显式的锁可以保证原子性,但是当时还没有这方面的实现)。所以我们选用了HiveCatalog,对于HiveMetastore,离线数仓包括Iceberg都是读写一个RDS库,所以通过EMR集群的HMS也能直接访问到Flink写进来的Iceberg表。
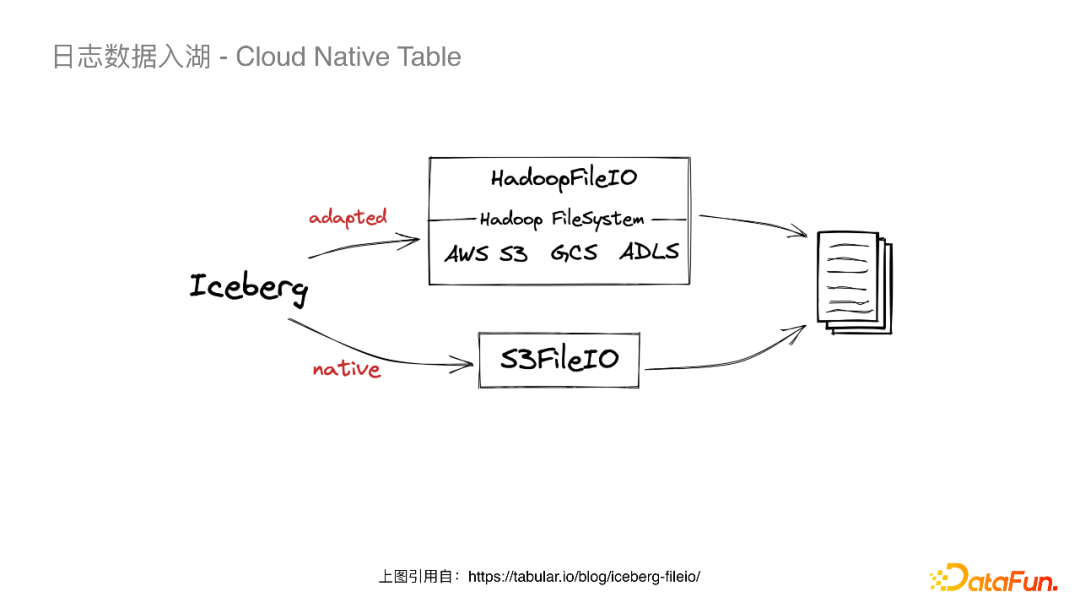
FileIO是Iceberg读写存储系统的接口。HiveCatalog默认是HadoopFileIO,我们可以在中间封装一层S3AFileSystem来读写S3。当我们走完这条链路时发现Flink读写都是正常的,但是离线所依赖的EMRFS不支持S3A的Schema。于是我们调研了Iceberg原生的S3FileIO,发现它的实现非常简单直接,且可控性非常高,于是在经过了一些大规模的压测,并解决了一些问题后就选择了S3FileIO。
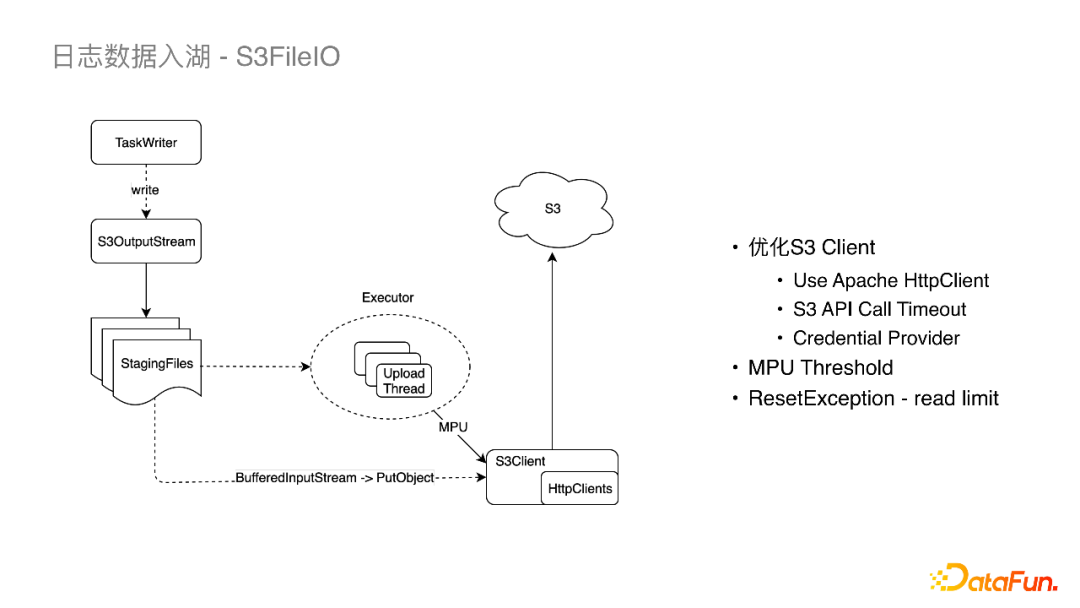
接下来具体介绍S3FileIO是怎么实现的。
首先Flink TaskWriter在接收数据向下游写到S3OutputStream。用户可设置一个MPU阈值,当大于阈值时,会有一个线程池异步地使用MPU上传文件到S3,否则就会走另一条路径,将StagingFiles串在一起,通过PutObject请求写到S3。
对于以上链路,我们也对S3FileIO做了一些优化以支持大流量的作业。
(1)S3Client上的优化:
-
HttpsClients,我们将S3原生的HttpsClients(Java8自带的HTTP URL Connection)更换为了Apache HttpClient,其在Socket链接以及易用性上有一些提升。在写的过程中我们也遇到了一些问题,多云机器带来的问题是每个厂商机器的内核是不太一样的,例如在某云上发现有写S3超时的问题,我们与厂商一起抓包发现是内核参数的问题。
-
API Call Timeout,将S3的Timeout配置项暴露给Iceberg。
-
Credential Provider,S3 SDK从FlinkConf中读取密钥。
(2)MPU Threshold
Flink做Checkpoint的时候,所有的Writer都会将数据刷到S3,这时候的毛刺会非常大。我们的方案是降低MPU的阈值以及ParquetWriter的RowGroup。降低Parquet的RowGroup就意味着它刷到S3OutputStream可以更早一点,降低MPU阈值就可以更早地上传StagingFile。通过以上优化我们把CheckPoint在上传到S3的延迟中从2分钟降到了几十秒。
(3)ResetException
当S3OutputStream通过BufferedInputStream把两个StagingFile合并到一起并上传时,当遇到诸如网络问题时会重试,它重试的机制是通过InputStreaming的mark和reset来做的,但是默认的mark limit是128KB,BufferedInputStream超过128KB之后就会丢数据,重试时就会出现ResetException。我们将mark limit改成 StagingFiles Size +1,保证所有的数据都会缓存避免以上问题。
②下游系统集成

接下来要解决的是跟下游生态系统集成的问题。
-
第一个问题是Batch Read
Iceberg与Hive最明显的区别就是分区的可见性语义,Hive在整个分区写完后可见,而Iceberg在commit后就立即可见。但是下游离线调度的小时级任务比较依赖于HivePartition的可见性。
在此我们做了一个Sensor,其原理是Flink在写的时候将Watermark写进Iceberg表的Table Property。下游的离线调度就可以使用我们基于Airflow的Watermark Sensor去定期的轮询HMS,查询Watermark是否已经达到分区时间,条件满足之后就会触发Spark的调度。
-
第二个问题是Adhoc查询
总结:
我们目前在生产环境已经落地了几个比较大的作业,单作业的吞吐达到了GB/S以及百万级别的RPS,数据的就绪时间大概在五分钟左右,由Flink Checkpoint来控制。下游的读耗时得益于小文件问题的解决以及Iceberg基于文件的Planning,使下游读耗时减少了30%~50%。
02
CDC实时入湖
1. Mysql全量入仓
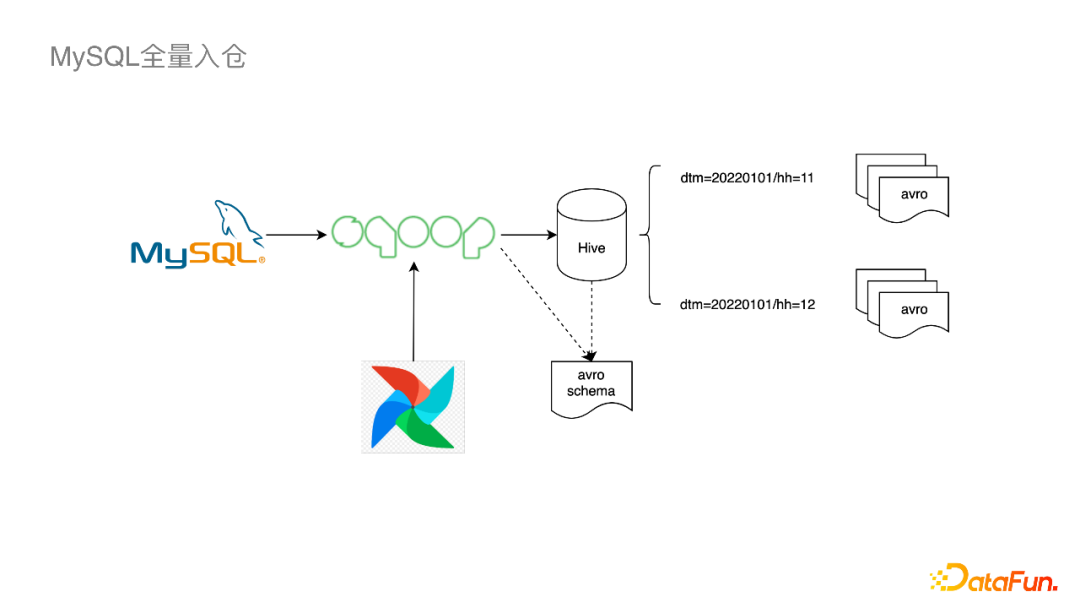
小红书数仓数据的另一重要来源是MySQL,目前的Mysql2Hive链路是全量入仓这种比较传统的模式,主要通过Airflow定时调度,使用Sqoop去小时级别或天级别从MySQL拉数据写到Hive表相应的分区里面。
其中比较特殊的一点是为了解决Schema Evolution,每次拉取数据的时候都会生成一个Avro Shema,对应的Hive表选用了行存储的Avro表,而不是通常会使用的基于列存的Parquet文件的表。它的缺点是不如列存高效,但是它解决了一个问题——下游的用户不需要考虑schema变化的情况。这条链路的好处是简单实用直接,缺点是MySQL压力大,下游查询不够高效。
2. CDC增量入仓
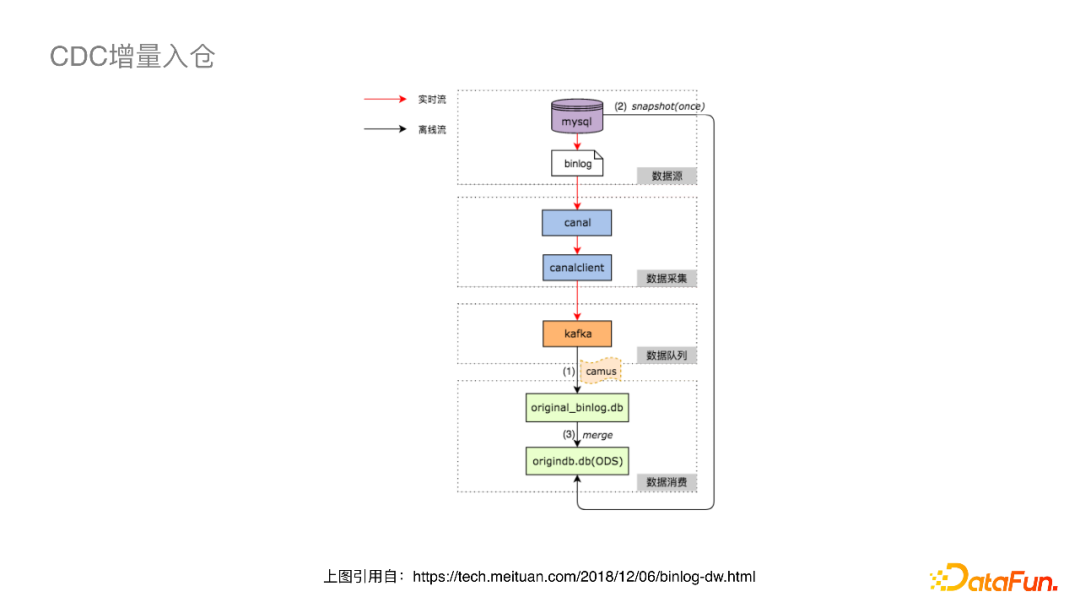
关于CDC如何增量入离线数仓的问题,大厂都有一些比较成熟稳定的方案。
如上图, ODS一般有两张表,一张增量表一张全量表,开始会有一个全量表的导入,之后会通过实时流进增量表,然后通过Merge任务进行周期性的合并操作。这个链路已经在很多厂都有了成熟稳定的实践,缺点是链路比较长。
3. CDC实时入湖
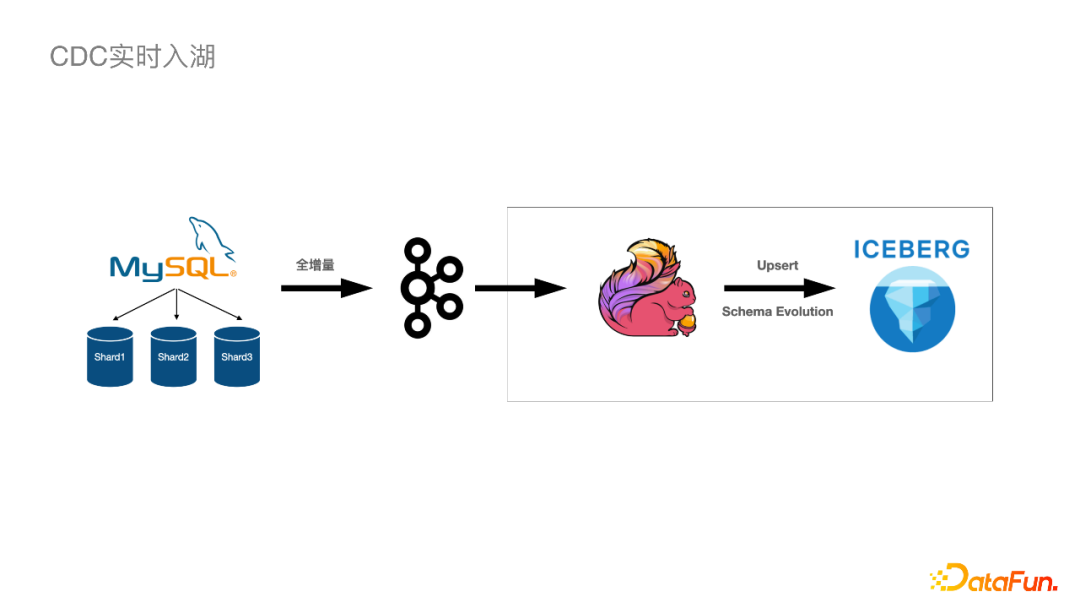
我们最终的链路如上图,将MySQL的上游数据库通过全增量数据发送到Kafka,然后使用Flink将数据Upsert到Iceberg里面,同时会处理一些Schema Evolution的情况,这条链路就非常简洁。
整条链路中我们需要特别注意,同⼀主键(业务主键+ Shard Key)的Binlog应该保序。以下是在整条链路中保持Exactly-Once语义所做的事情:
①Binlog
-
全增量,先发全量再发增量。
-
At-Least-Once,保证重复发送时保证有序(最终⼀致性)。
-
MQ Producer根据主键Hash(且分桶数固定,不受扩容影响)。
②Flink
-
Shuffle Key 只能是主键的⼦集 + Immutable Columns。
③ Iceberg sink
-
Upsert Mode。
(1)Merge on Read
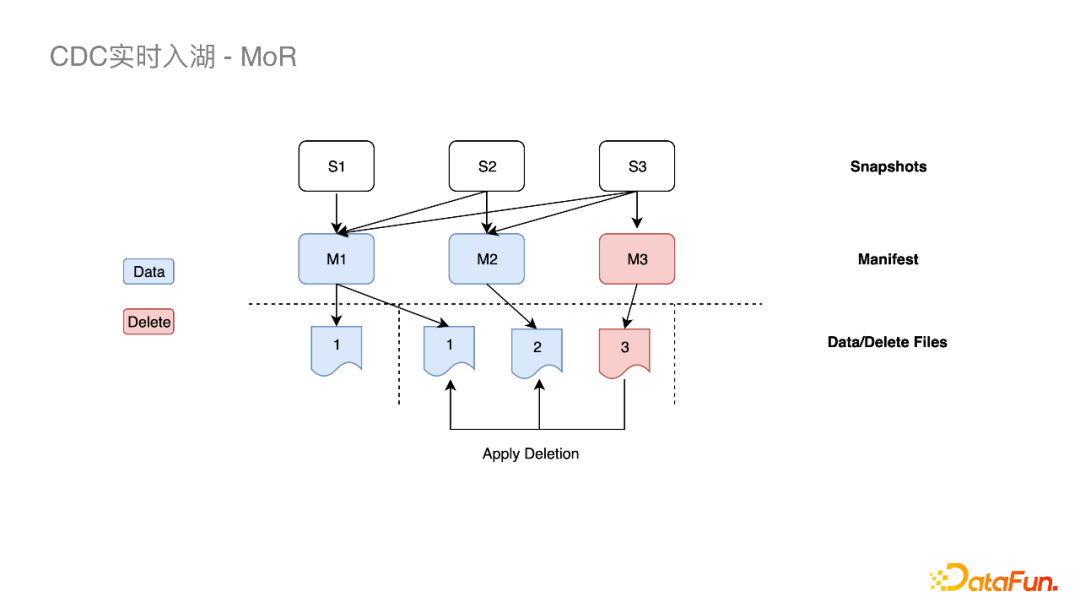
这个方案我们在实践中也发现一些问题,最核心的就是DeleteFile多导致的MOR查询性能差。
Iceberg查询时,每个DataFile都需要读取相应的DeleteFile进内存进行过滤,会使得Task的IO负载很重,这样我们的优化思路就转换为如何减少DeleteFile。而出现DeleteFile过多的原因是,Update的实现要先把当前行删掉再Insert,删掉这行就至少会生成一个DeleteFile。我们对此所作的优化是去除重复的Insert事件,这样只需要对Update做Delete。当下游Insert很多,Update很少的时候就会有比较大的收益。
(2)Hidden Partition
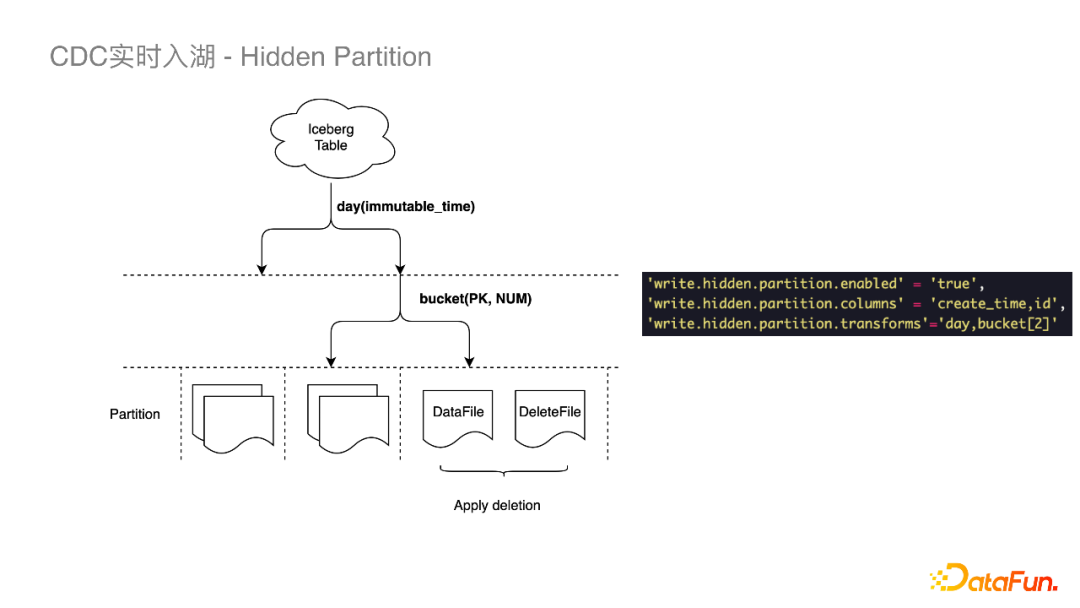
Iceberg的分区与Hive不同的是它的分区信息可以被隐藏起来,不需要用户去感知,在建表或者修改分区策略之后,新插入的数据自动计算所属分区。
利用隐藏分区我们可以做到以下优化:
-
在读数据时可以只查询关联分区,忽略其他分区。
-
错峰做File Compaction,减少冲突。例如在写当前小时分区时我们可以对之前的分区做File Compaction。
对于FlinkSQL原生不支持隐藏分区的问题,我们通过Table Property去定义隐藏分区,在建表的时候去建相应的分区。
(3)Auto Schema Evolution
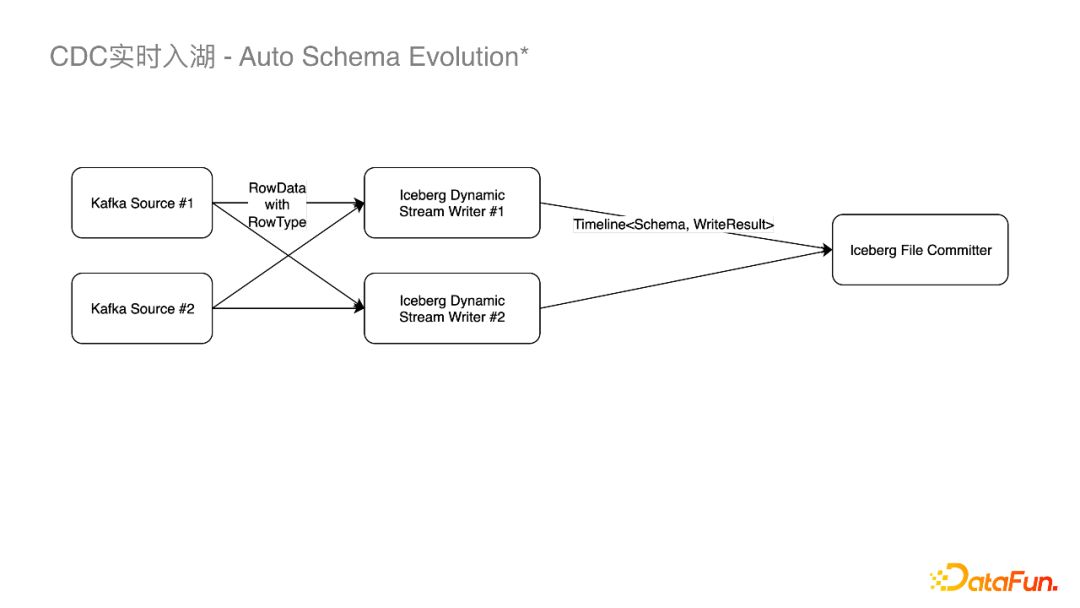
在实时流处理Binlog,一个绕不开的问题是上游的Schema变更了下游怎么及时的检测到,再去做相应的Writer的变更,下游表的变更。有一种解决方案是当消费到上游变更的Event事件时,我们会在平台把作业重新改掉重启,也就是先变更下游的Iceberg的Table Schema,再变更Flink SQL,之后重新启动作业。但在平台化之前,对于一些常用的场景,比如加列,已经能覆盖线上很多Schema Evolution的场景。为了让Flink作业能自动监测到加列并且有序的正确的提交到Iceberg,我们将Binlog中的Schema随着每条数据记录一起发送,当数据往下发到Iceberg的Dynamic Streaming Writer时,就可以和Writer里面保存的上一个Schema去做比较,假设只是加列,那么我们就会做两件事情:
-
关掉当前的Writer,以新的Schema去建立新的Writer写数据。
-
以Schema变更的时间点为分割,对Schema变更前的数据先提交,再对Schema 进行Update,之后再提交 Schema变更后的文件。
(4)CDC实时入湖其他工作

除此之外,CDC与实时链路我们还做了其它一些工作:
-
Binlog Format。支持解析Canal PB格式。
-
Progressive Compaction。Compaction是我们接下来工作的重点,尤其在MySQL的量比较小的时候,如果想维持五分钟级别的CheckPoint,小文件问题就会非常突出。如何避开流式任务正在写的Partition去做Compaction 也是目前在做的事情。
以上就是我们目前正在做的CDC入湖的一些工作。
03
实时湖分析探索
我们想用Iceberg 来做一些更面向未来的事情。
1. 实时分析链路

首先介绍一下目前分析的实时链路。
Kafka通过Flink做一些Join和聚合操作之后,最后会生成一张大宽表存储到ClickHouse中以提供秒级或者毫秒级的返回功能,Kafka在其中也用做了事实表的存储。以上架构图来自FLIP-188,FLIP-188要做的事情就是如何实现流批一体的存储。我们数仓同学的需求是要对中间结果进行一些查询操作或者利用其进一步生成下游的表,这些操作只利用Kafka是做不了的。常见的做法是利用Kafka再接一个任务,将中间结果写到Iceberg或者Hudi表里面。
2. 流批一体存储
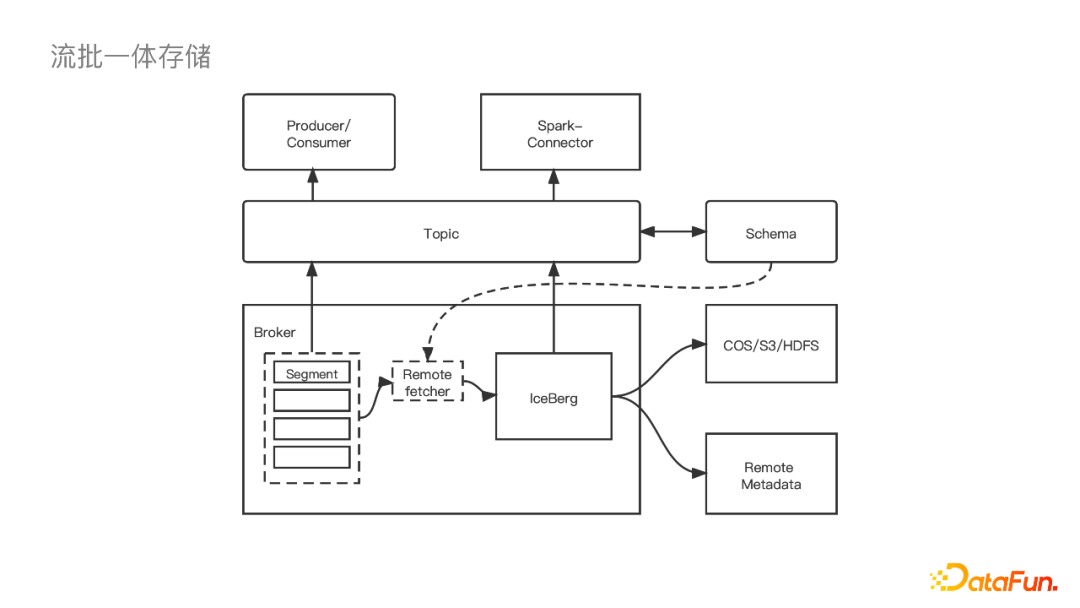
我们实现流批一体存储是通过直接在Kafka里双写一份数据到Iceberg的列存储上。这除了让Kafka做扩容更简单,更重要的是支持一些离线数仓的用法,我们不必再启动一个Flink的作业去写到S3。要实现这样的功能首先需要一个Schema的概念,也就是如何把Kafka的Schema映射到下游表的Schema,对此我们让用户在我们的平台上来自定义,同时有一个Remote Fetcher模块来拿到这个Schema,之后通过Iceberg写到下游。真正的写线程是在Broker里面,可以根据Leader去动态迁移。之后集群中的Controller节点上启动一个单独的Commiter进程,接受Fetcher传来的数据文件列表,定期commit。
3. Iceberg外表
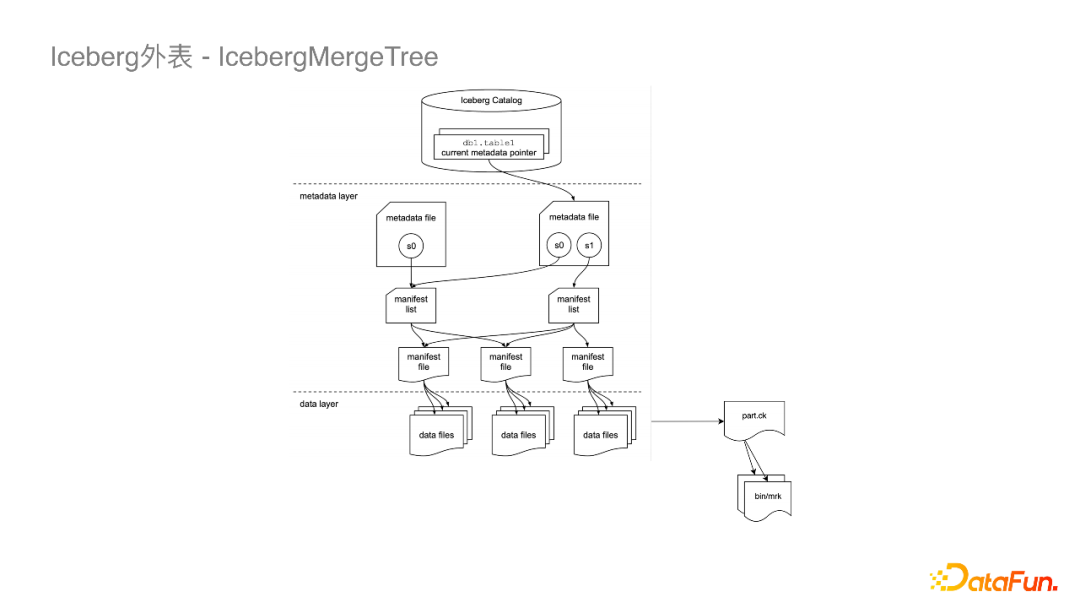
ClickHouse社区版是存算耦合的,离线数仓想用这部分的数据就比较困难。我们公司内部的ClickHouse已经实现了存算分离的架构,数据是存储于对象存储的。在此基础上,我们和ClickHouse团队合作做了Iceberg的外表。Iceberg外表没有使用Paruqet这种开放式的文件格式,而是使用了MergeTree的格式。上图是一张Iceberg传统的数据文件组织形式图,它的Metadata层分成了Manifest List和Manifest File,之后会指向一些DataFile。这些DataFile与ClickHouse里面的part概念很像,所以我们就将Manifest File指向了一个part.ck文件,part.ck其实也是一层衍生的元数据文件,它的下游会再去读一些bin/mark的文件,这样就可以完成对ClickHouse数据的读取。
04
未来规划
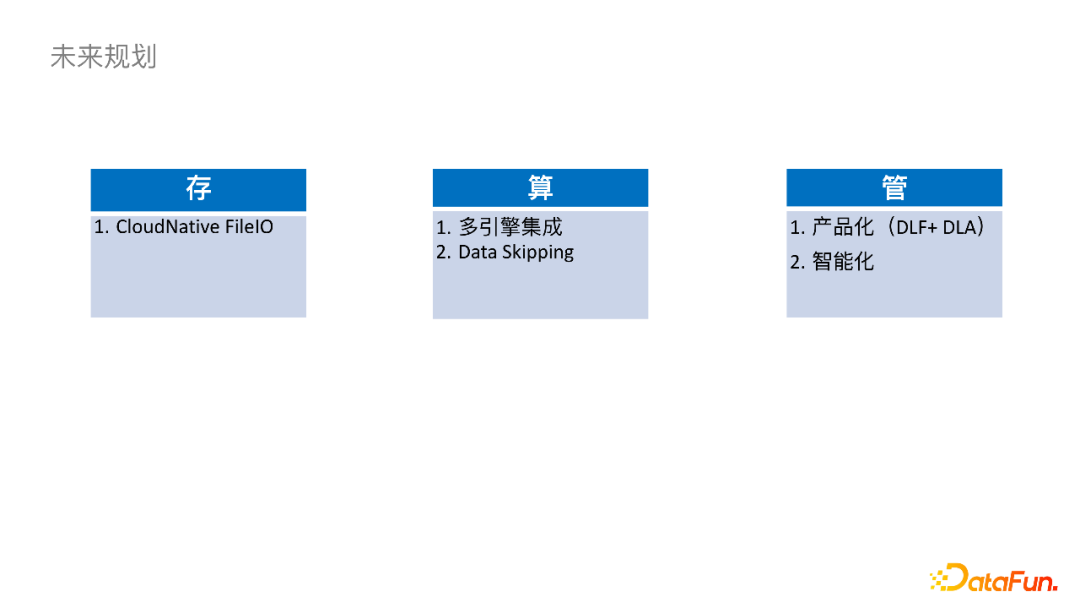
未来规划主要有存、算、管三个方向。
-
首先在存储方面,我们需要对CloudNative FileIO持续优化,比如进一步减少Checkpoint的毛刺、进一步提高吞吐、提高跨云读写的稳定性。
-
关于计算,我们会跟更多引擎去集成,目前已经集成了Spark引擎,同时正在集成ClickHouse。另外StarRocks社区已经集成了Iceberg外表的Connector,我们以后也会在上面做一些应用。在查询方面,计划通过改变数据的组织形式,或者添加一些二级索引来做Data Skipping去加速查询。
-
管理方面,让Iceberg持续稳定的运行下去还是需要外挂表维护作业的,这对下游数仓同学来说还是引入了运维压力。我们接下来会将其服务化,思考如何智能地拉起一些作业,以及运用什么策略可以减少冲突的概率。
这就是我们正在做的和将来准备做的一些事情。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

本文转载自孙超 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/rw3iKYiHoGvTQG04nK0Y8w。