
欢迎来到第21期“论文与代码通讯”。本周,我们讨论:
- 视觉合成任务的统一方法
- 扩展视觉模型的技术
- 2021年11月的顶级趋势论文
- 最新的研究成果,
- 等等
提高视觉合成
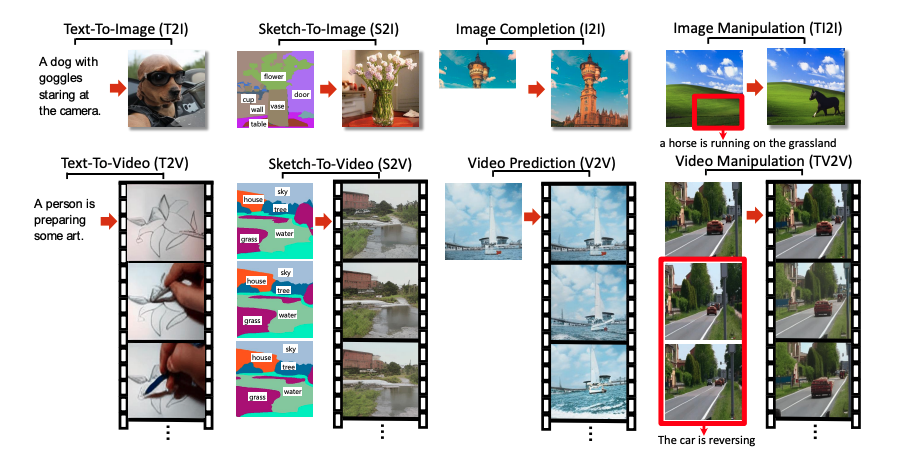

随着可视化数据在Web上变得越来越可用和流行,需要构建更好的系统,以便为各种可视化场景生成新的数据或操作可视化数据。Wu等人(2021)提出了一种新的多模态预训练模型NÜWA,这是一种通用的3D转换器,可同时支持多模态的视觉合成任务。
NÜWA是什么: NÜWA由一个接受文本或视觉输入的自适应编码器和一个由8个视觉任务共享的预训练解码器组成。为了降低计算复杂度和提高结果的视觉质量,提出了一种三维近距离注意机制(3D Nearby Attention mechanism, 3DNA)。3DNA考虑了空间和时间轴的局部性特征,以更好地处理可视化数据的性质。(参见下面的完整架构)。NÜWA在文本到图像生成、文本到视频生成和其他视觉任务上实现了最先进的结果。它还显示了文本引导的图像处理和文本引导的视频处理的良好的零样本学习能力。
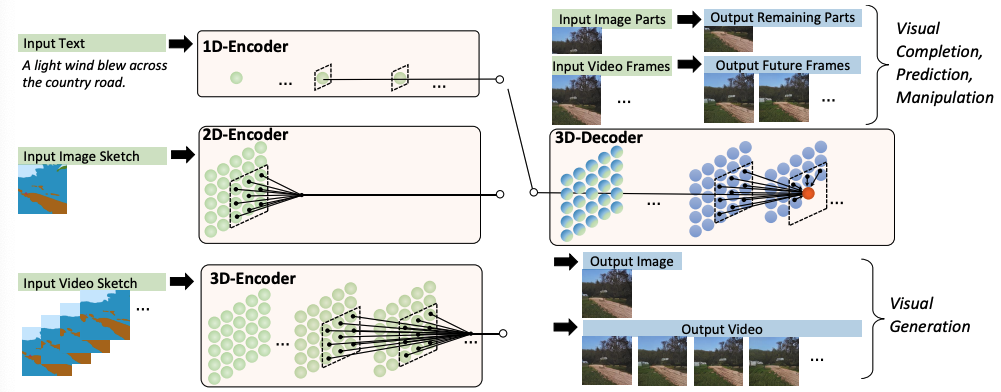
同样值得了解的是: 以往基于VQ-VAE的方法,如DALL-E和CogView,已经表明大规模的预训练可以应用于视觉合成任务。然而,这些模型的一个局限性是它们分别对待模态。NÜWA,另一方面,受益于图像和视频数据,如图所示。与NÜWA的另一个区别是,它利用VQ-GAN而不是VQ-VAE进行可视化标记化,作者认为这可以导致更好的生成质量。统一的模型让我们得以一窥未来ai平台可以让内容创造者以创造性的方式创造视觉世界。
扩展视觉模型
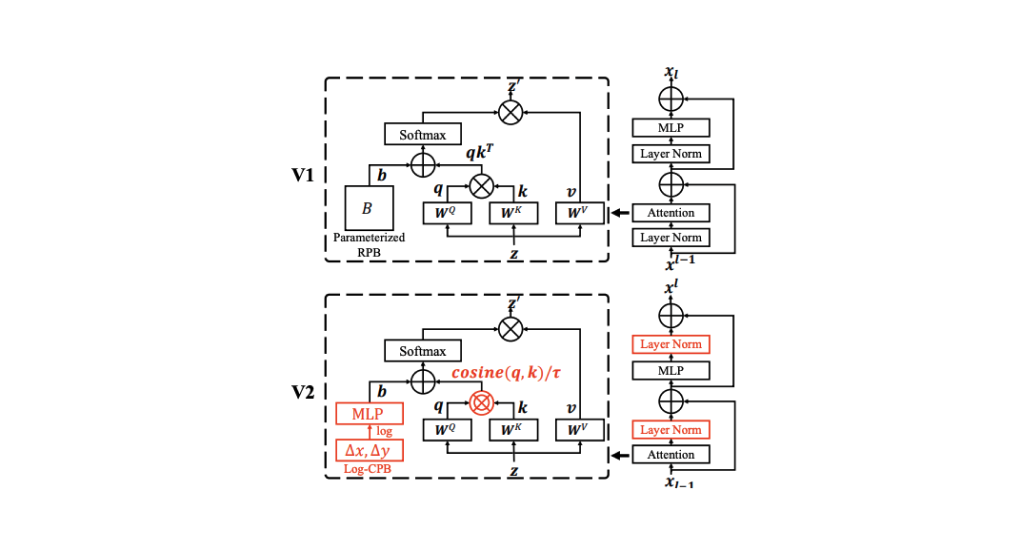
在我们之前的问题中,我们定期讨论了扩展大型 NLP 语言模型的新技术。 另一方面,视觉模型的扩展一直滞后。 一些作品试图通过大规模标记图像数据集来扩展视觉变换器,并且仅应用于图像分类。 文献中的一些报告指出了大规模训练中的不稳定问题。 也不清楚如何有效地跨窗口分辨率传输模型。 为了解决其中一些问题,Liu 等人。 (2021) 最近提出了一些有效扩展视觉模型的技术。
为什么重要:首先,为了提高像 Swin Transformer 这样的大型视觉模型的容量和稳定性,采用了后归一化技术和缩放余弦注意方法。 为了将在低分辨率图像上预先训练的模型有效地转移到更高分辨率的对应模型,采用了对数间隔连续相对位置偏差技术。 (参见上图中的调整)。 简而言之,提出了几种技术,用于将 Swin Transformer 参数缩放到 3B,并支持使用更高分辨率的图像进行训练。 由此产生的架构被称为 Swin Transformer V2,它在各种视觉基准测试中创造了新的记录。 (请参阅此处的结果摘要)。
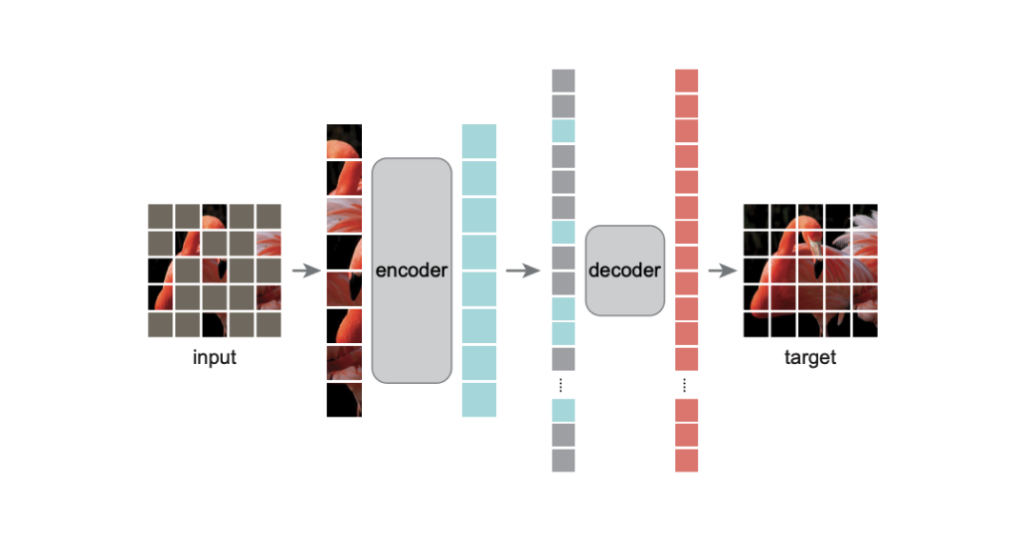
您可能还喜欢:最近的另一篇论文旨在通过掩码自动编码 (MAE) 训练可扩展的视觉学习者。 作者提出了一种简单的 MAE 方法:在预训练期间,大量随机的图像块子集被屏蔽并重建丢失的像素。 在编码器-解码器框架中,编码器仅应用于补丁的可见子集,而解码器处理编码的补丁和掩码标记以重建像素中的原始图像。 补丁的掩蔽产生了一项自我监督任务,并允许对大型视觉模型进行高效和有效的训练。 预训练后,仅使用编码器部分为模型实现高性能的多个识别任务生成表示。 在此处查看结果摘要。
11月十大热门文章
以下是2021年11月关于带代码的论文的十大趋势论文:
? MetaFormer is Actually What You Need for Vision
? Neural Visual World Creation
? Masked Autoencoders are Scalable Vision Learners
? Attention Mechanisms in Computer Vision: A Survey
? Florence: A New Foundation Model for Computer Vision
? FastFlow
? Rethinking KeyPoint Representations
新的带有代码的论文
? BASIC: 提出了一种用于 ImageNet 上最先进的零样本迁移学习图像分类的组合缩放方法。
? Restormer: 介绍了一种高效的基于Transformer的高分辨率图像恢复模型。在诸如离焦去模糊和图像去噪等图像恢复任务上,它的表现优于以往的模型。
⚙️ ML-Decoder: 提出了一种新的基于注意力的分类方法,并重新设计了针对MS-COCO和其他图像数据集的多标签分类的解码器体系结构。
在这里浏览论文与代码报告的所有最新成果。
最新研究数据集和工具
数据集
- RedCaps – 是从 Reddit 收集的 1200 万个图像-文本对的大规模数据集。
- CytoImageNet – 用于生物图像迁移学习的大规模预训练数据集。
- LSUI – 包含5K图像对的大规模水下图像数据集,涉及更丰富的水下场景。
工具
TorchGeo – 用于将空间数据集成到 PyTorch 深度学习生态系统的 Python 库。
tsflex – 一个独立于域的 Python 工具包,用于时间序列的处理和特征提取。
本文转载自paperwithcode,原文链接:https://paperswithcode.com/newsletter/21。