
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据、数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系。本文介绍了字节跳动Data Catalog系统的构建和迭代过程,将分为上、下篇发布。上篇主要围绕Data Catalog调研思路及技术架构展开。


文 | 邱艺朴、大滨 来自字节跳动数据平台开发套件团队
DataLeap
01 – 元数据与Data Catalog
02 – Data Catalog的业务价值
03 – 旧版本痛点
-
用户层面痛点: -
数据生产者: 多引擎环境下,没有便捷、友好的数据组织形式,来一站式的管理各类存储、计算引擎的技术与业务元数据。 -
数据消费者: 各种引擎之间找数难,元数据的业务解释零散造成理解数难,难以信任。 -
技术痛点: -
扩展性:新接入一类元数据时,整套系统伤筋动骨,开发成本月级别。
-
可维护性:经过一段时间的修修补补,整个系统显得很脆弱,研发人员不敢随便改动;存储依赖重,同时使用了MySQL、ElasticSearch、图数据库等系统存储元数据,维护成本很高;接入一种元数据会增加2~3个ETL任务,运维成本直线上升。
04 – 新版本目标
-
产品能力上,帮助数据生产者方便快捷组织元数据,数据消费者更好的找数和理解数。 -
系统能力上,将接入新型元数据的成本从月级别降低为星期甚至天级别,架构精简,单人业余时间可运维。
DataLeap
调研与思路
01 – 业界产品调研
|
产品分类 |
产品名称 |
支持元数据种类 |
重要产品功能 |
机器学习能力 |
|
独角兽 |
C** |
40+ |
搜索、血缘、标签、评价与打分、认证、问答、Connector市场等 |
有 |
|
A** |
60+ |
搜索、血缘、标签、问答、Connector市场等 |
有 |
|
|
开源 |
A** A** |
10+ |
搜索、血缘、标签等 |
无 |
|
L** D** |
40+ |
搜索、血缘、标签、统计大盘等 |
无 |
|
|
商业化 |
A** P** |
30+ |
搜索、血缘、标签、统计大盘等 |
无 |
02 – 升级思路
-
对于搜索、血缘这类核心能力,做深做强,对齐业界领先水平。 -
对于各产品间特色功能,挑选适合字节业务特点的做融合。 -
技术体系上,存储和模型能力基于Apache Atlas改造,应用层支持从旧版本平滑迁移。
DataLeap
技术与产品概览
01 – 架构设计
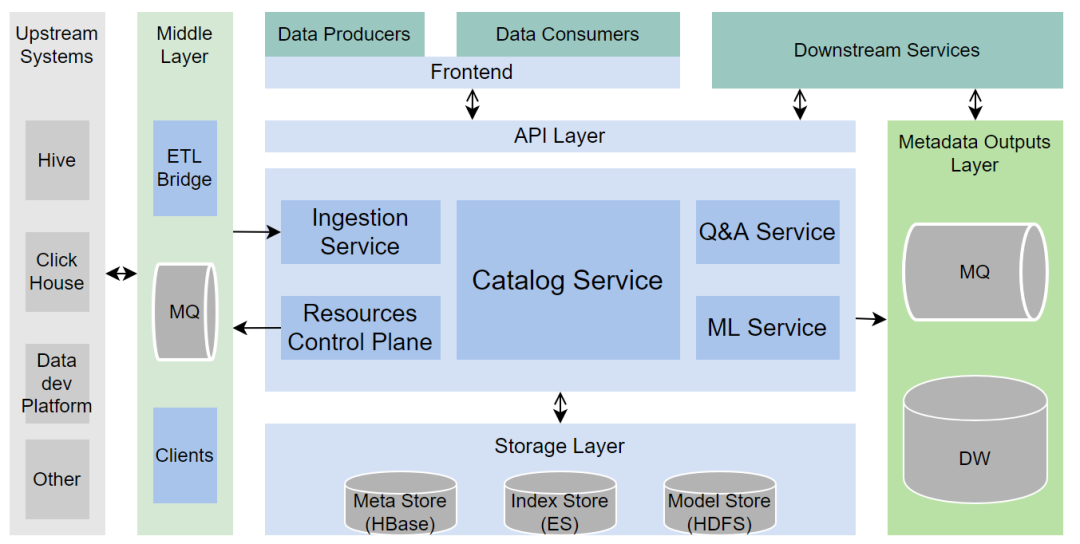
元数据的接入
-
元数据接入支持T+1和近实时两种方式
-
上游系统:包括各类存储系统(比如Hive、 Clickhouse等)和业务系统(比如数据开发平台、数据质量平台等)
-
中间层:
-
ETL Bridge:T+1方式运行,通常是从外部系统拉取最新元数据,与当前Catalog系统的元数据做对比,并更新差异的部分
-
MQ:用于暂存各类元数据增量消息,供Catalog系统近实时消费
-
与上游系统打交道的各类Clients,封装了操作底层资源的能力
核心服务层
-
Catalog Service:支持元数据的搜索、详情、修改等核心服务
-
Ingestion Service:接受外部系统调用,写入元数据,或主动从MQ中消费增量元数据
-
Resource Control Plane:通过各类Clients,与底层的存储或业务系统交互,操作底层资源,比如建库建表,能力可插拔
-
Q&A Service:问答系统相关能力,支持对元数据的字段含义、使用场景等提问和回答,能力可插拔
-
ML Service:负责封装与机器学习相关的能力,能力可插拔
-
API Layer:以RESTful API的形式整合系统中的各类能力
-
Meta Store:存放全量元数据和血缘关系,当前使用的是HBase -
Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch -
Model Store:存放推荐、打标等的算法模型信息,使用HDFS,当ML Service启用时使用
元数据的消费
-
数据的生产者和消费者,通过Data Catalog的前端与系统交互
-
下游在线服务可通过OpenAPI访问元数据,与系统交互
-
Metadata Outputs Layer:提供除了API之外的另外一种下游消费方式 -
MQ:用于暂存各类元数据变更消息,格式由Catalog系统官方定义 -
Data warehouse:以数仓表的形式呈现的全量元数据
02 – 产品功能升级
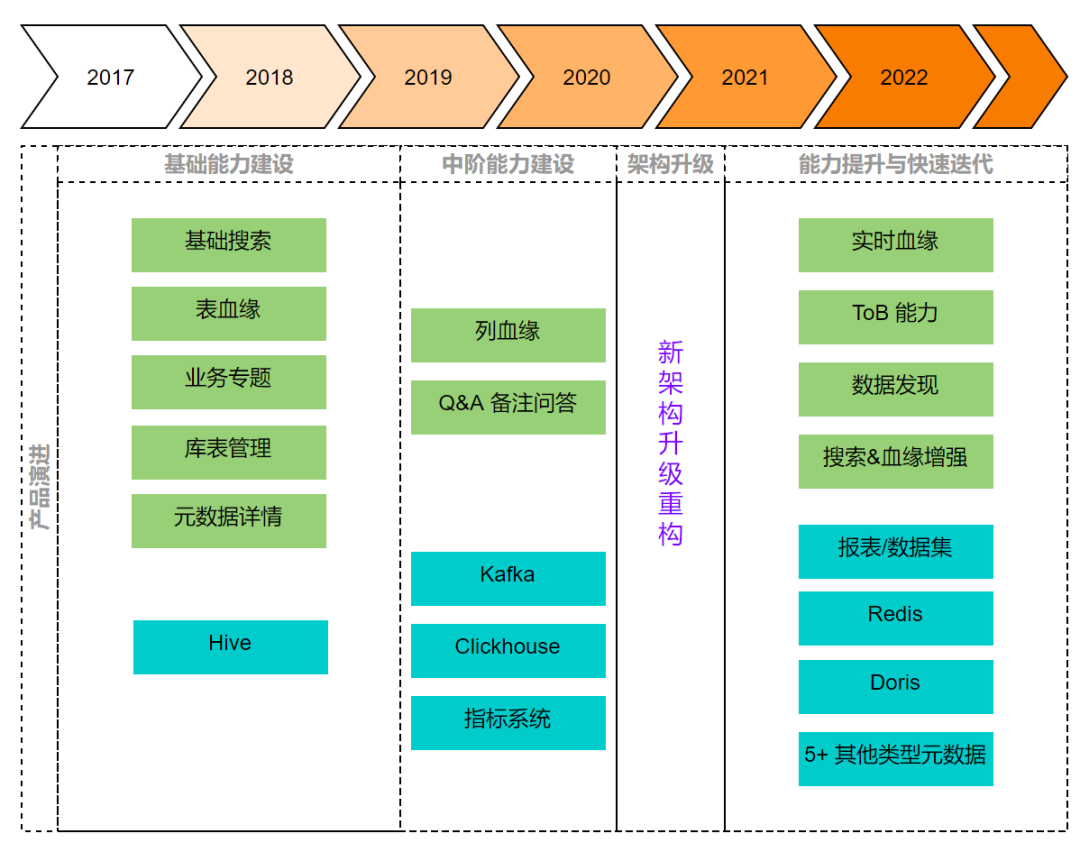
产品能力上的升级迭代,大致分为以下几个阶段:
-
基础能力建设(2017-2019):数据源主要是离线数仓Hive,支持了Hive相关库表创建、元数据搜索与详情展示、表之间血缘,以及将相关表组织成业务视角的数据专题等
-
中阶能力建设(2019-2020年中):数据源扩展了Clickhouse与Kafka,支持了Hive列血缘,Q&A问答系统等
-
架构升级(2020年中-2021年初):产品能力迭代放缓,基于新设计升级架构
-
能力提升与快速迭代(2021年至今):数据源扩展为包含离线、近实时、业务等端到端系统,搜索和血缘能力有明显增强,探索机器学习能力,产品形态更成熟稳定。另外我们还具备了ToB售卖的能力。
在下篇中,重点介绍Data Catalog关键技术和未来规划,敬请期待。
本文转载自开发套件团队,原文链接:https://mp.weixin.qq.com/s/XoZvyU0ME6HS8VpT_1qv3A。
[…] Catalog系统的构建和迭代过程,将分为上、下篇发布。上篇围绕Data Catalog调研思路及技术架构展开。下篇重点介绍Data […]