


1 背景
2 严选应用
-
支持严选10万多SKU预测未来360天销量,准确率业内领先; -
落地于采购补货、营销策略等多种场景。
 供应链采购补货系统
供应链采购补货系统-
支持按省份、按仓库的预测; -
实现全国仓库的库存均衡,商品就近发货。
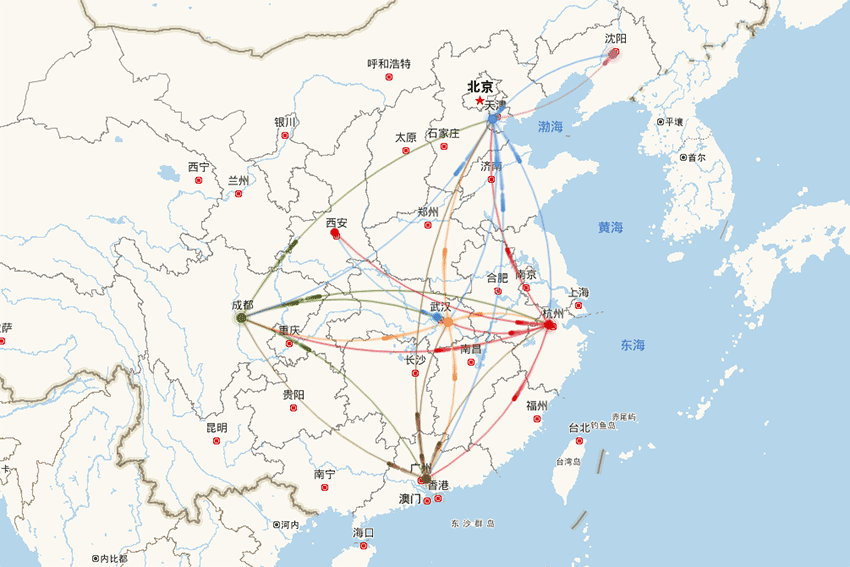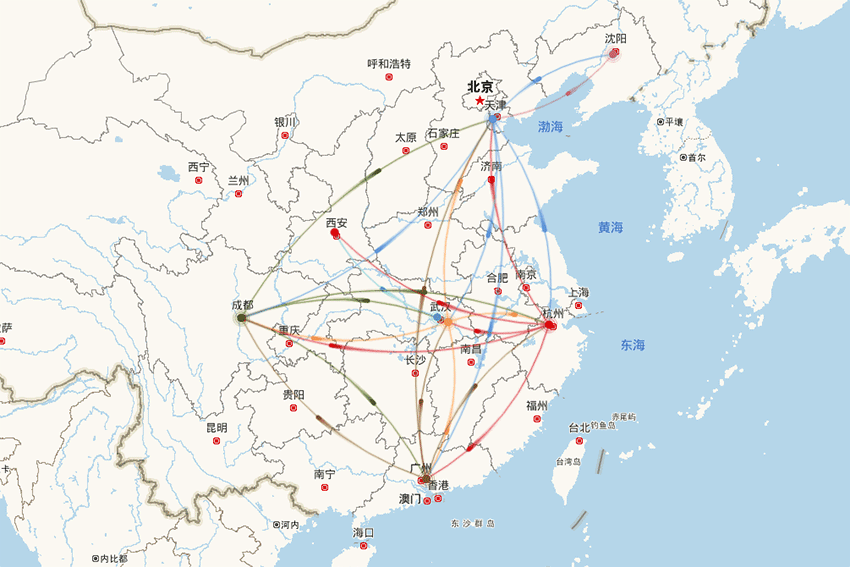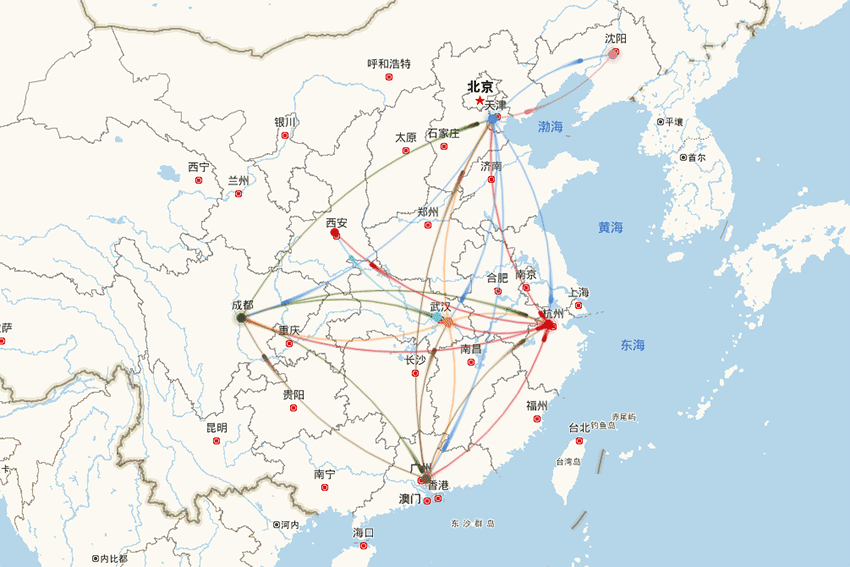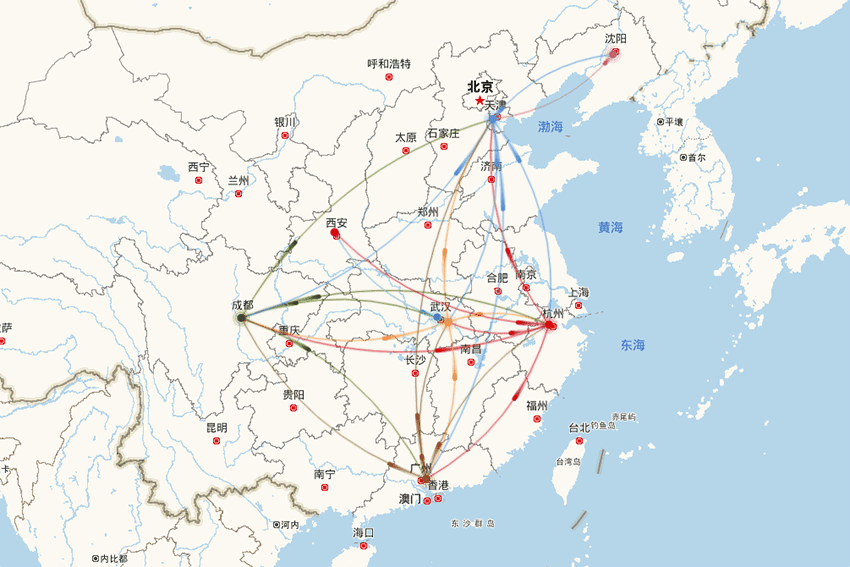
-
支持严选2000多仓库未来60天的各仓库日维度单量预测,包含新仓的冷启动预测,准确率业内领先; -
支撑业务侧进行仓库产能评估和安排、物流车辆资源储备和调度等决策。
-
严选自建DSP广告投放平台,平台接入流量每天百亿级,对接上千家媒体,广告位十万级; -
实现了小时级的大规模预测,预测每个广告位在未来两天每小时的流量,准确率业内领先。

-
预测严选APP内7大流量入口包括搜索页、推荐页、类目页、商详页、个人页等关键流量入口的流量。
3 时序预测算法实践
-
特征数据的构建、收集、落地; -
算法模型的设计、实现; -
算法服务的整合、开发。
3.1 整体架构
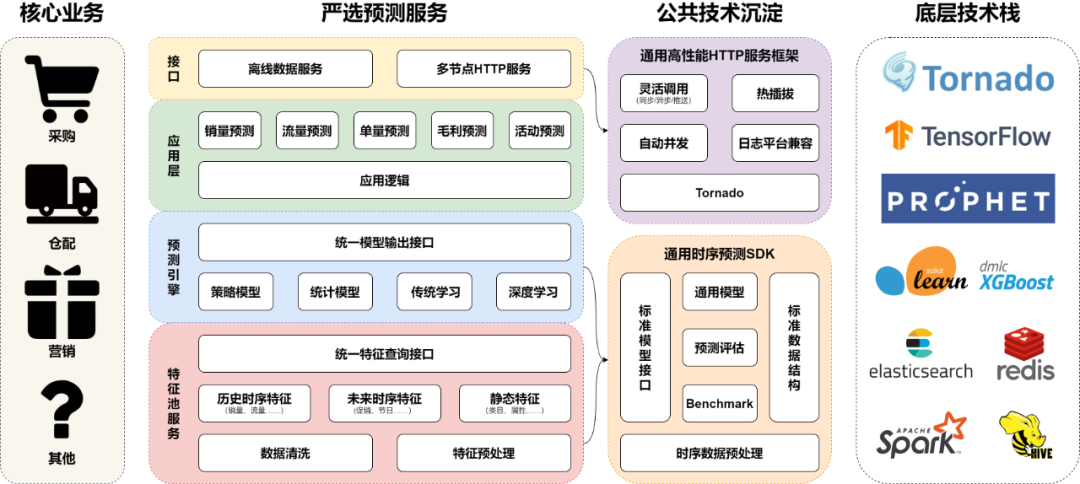
3.2 数据特征
-
用户数据 -
用户属性:性别、年龄、地区、手机型号、消费水平、社会身份、类目偏好、社交关系…… -
用户行为:浏览、点击、加购、购买、评论、分享…… -
商品数据 -
商品特性:类目、迭代关系、相似性、价格、毛利、文案…… -
商品销售:销量、折扣、促销、好评、复购、退货、地域、履约…… -
业务数据 -
后端仓配:选址、容量、人力、配送…… -
前端营销:预算、计划、竞争关系、渠道属性、经营模式、市场计划…… -
外部数据 -
行业相关:节假日、自然气候、原材料…… -
流量媒体:属性、类型、规模……
3.3 算法模型
-
优点:预测结果具有较好的可解释性,计算效率高。 -
缺点:算法本身处理复杂场景能力有限,需要额外的预处理、后处理环节,通过一些策略规则对预测数据进行补充优化,需要引入大量的专家经验。 -
应用模型:Linear-Regression、ARIMA、Holt-Winters、Prophet……
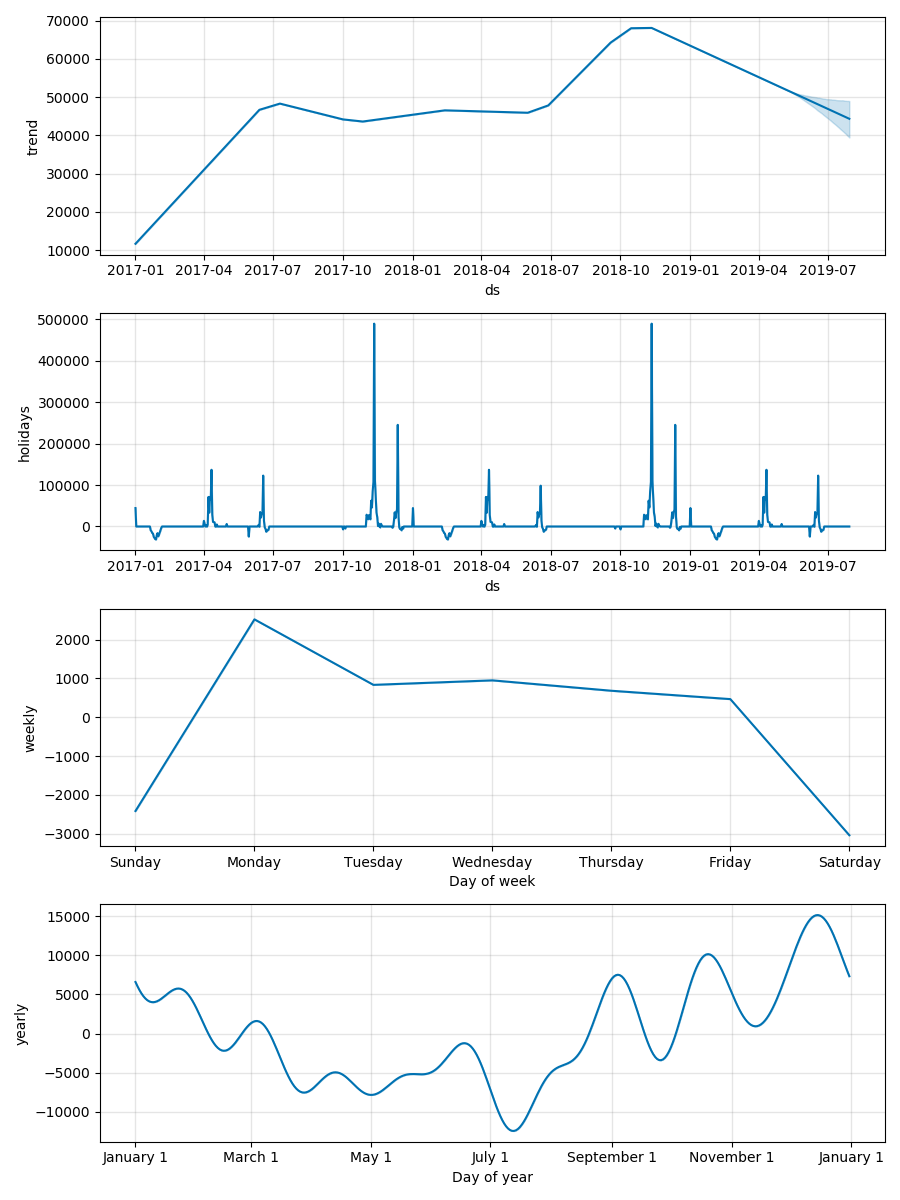
-
优点:可以处理复杂的业务场景,较为方便的考虑时序或非时序的各种特征数据,目前在大部分实际应用中有更高的预测准确率。 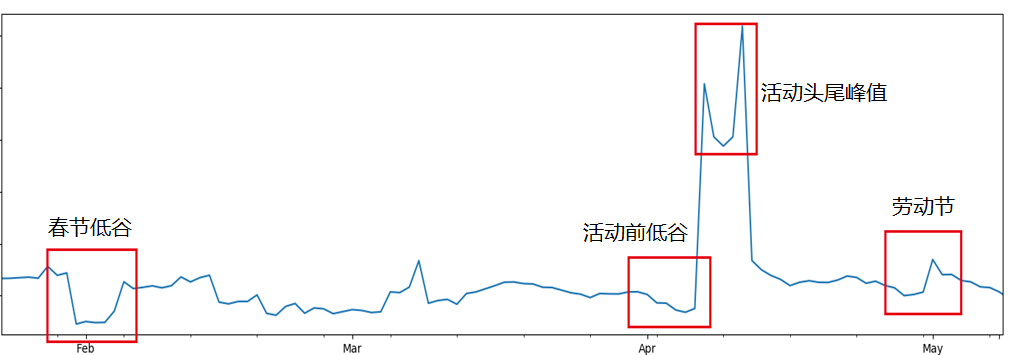
使用传统机器学习模型预测结果包含了更多细节 -
缺点:预测结果的可解释性较差,同样需要一定的专家经验来进行特征工程,对训练用的历史数据有一定要求,数据量(数量&质量)不够时很难学到有效的预测模型 -
应用模型:XGBoost、LightGBM……
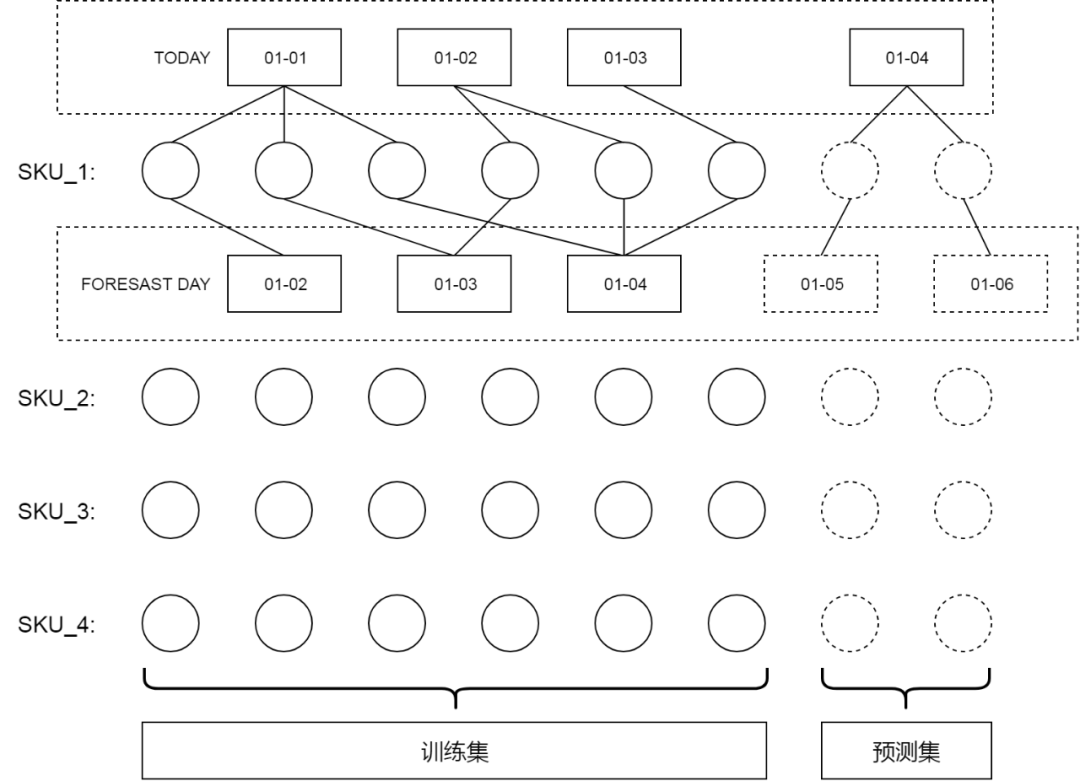
-
优点:可以处理更加复杂的情况,对人工经验、特征工程的依赖更少,具有较高的自由度,可以端到端的解决各种预测问题。

-
缺点:预测结果的可解释性最差,对历史数据的要求最高,并且训练过程计算量最大,效率较低。 -
应用模型:DeepTCN、MASS、DeepAR、LSTNet、TFT、Informer……
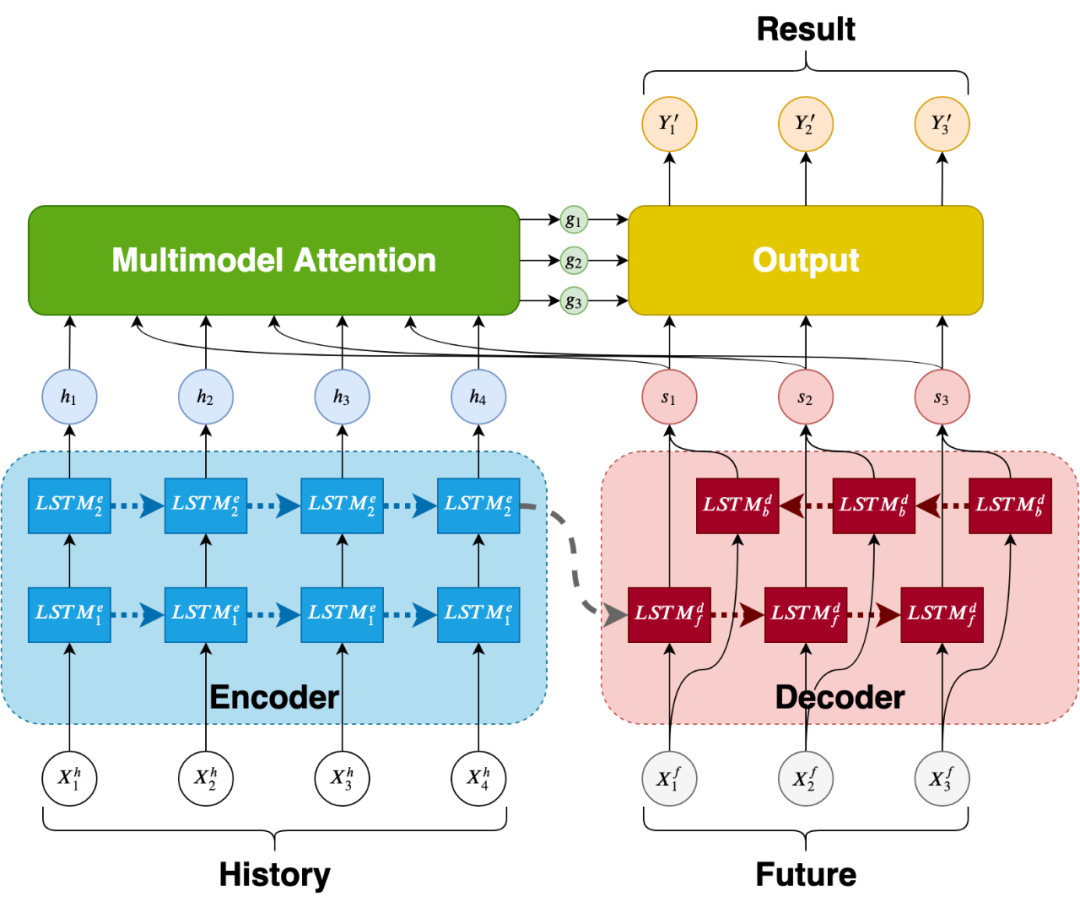
3.4 算法服务
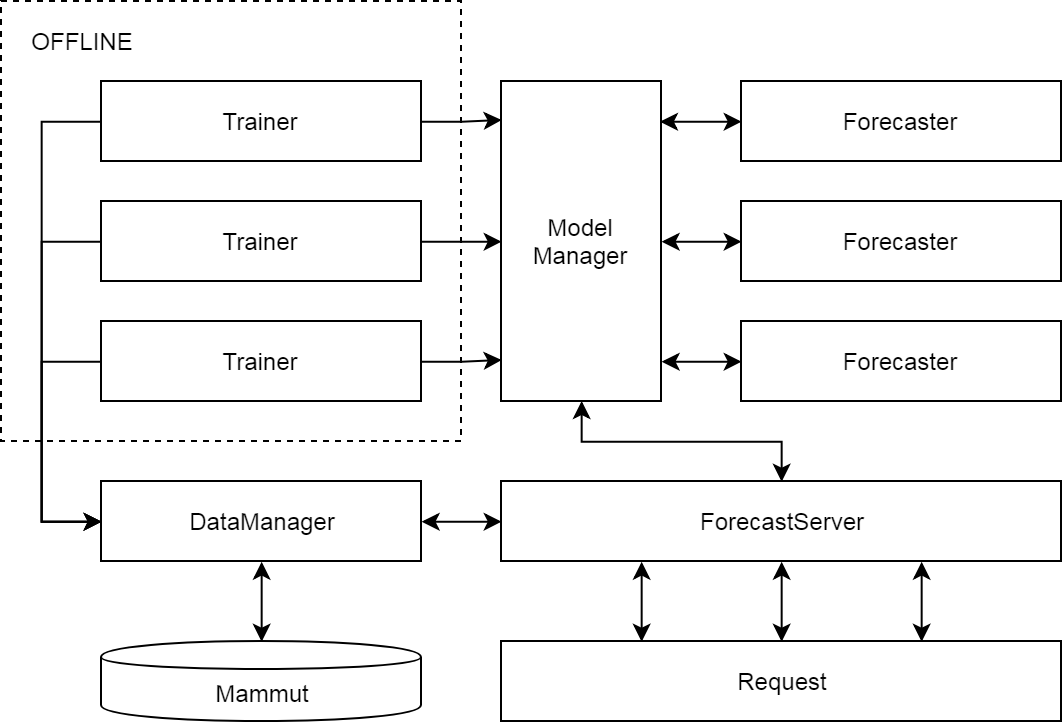
4 后记
-
未来与历史的差异性 所有的预测算法都是基于“历史与未来的规律一致”这一假设前提才得以成立的。然而在实际场景中,规律本身也是在不断变化的,未来发生的事情并不一定能在历史上找到参考。例如当下流行的带货直播,这一形式在早几年的数据中并没有可供参考的样本,同时也一定程度的改变了当下用户的消费习惯,这对于商品销量预测带来了很大的挑战。 -
未知事件影响 实际业务场景中产生的时序数据,都是在各种“事件”的综合影响下产生的。时间时序预测算法可以预测时序数据的走势、时序数据在不同“事件”下的变化表现,却无法预测“事件”本身的发生。大到疫情的发生,小到某次促销活动,这些“事件”本身并不具备可预测性,却对数据影响巨大。
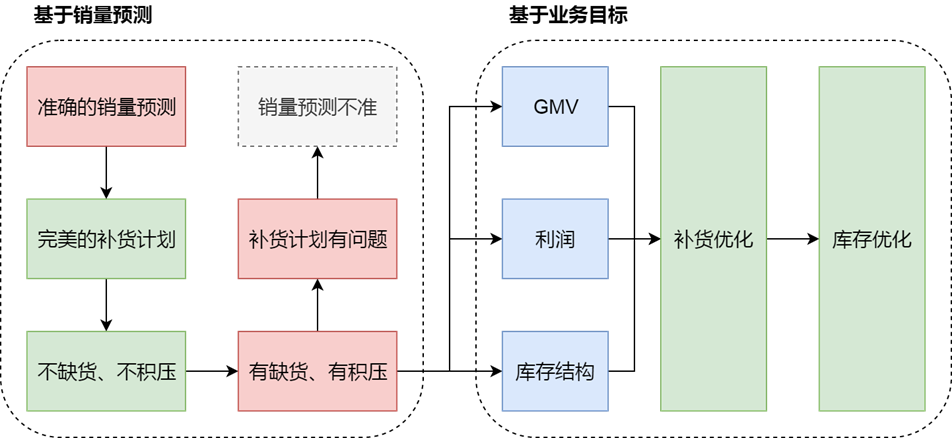
本文转载自严选技术,原文链接:https://mp.weixin.qq.com/s/Dqlq069Qq-XwxAembyyggw。