
本期作者

周晖栋
哔哩哔哩资深开发工程师
目前主要负责B站实时团队增量数仓、Hudi数据湖方向。
黄靖
哔哩哔哩资深开发工程师
专注于实时计算相关大数据技术,目前负责Hudi数据湖在B站的建设和应用。


陈世治
哔哩哔哩资深开发工程师
负责B站实时湖仓一体架构的建设,专注于Flink与Hudi生态结合的实时数据湖实践与落地。
1. 背景
众所周知,越实时的数据越有价值。直播、推荐、审核等领域中有越来越多的场景需要近实时的数据来进行数据分析。我们在探索和实践增量数据湖的过程中遇到许多痛点,如时效性、数据集成同步和批流一体的存储介质不统一的问题。本文将介绍我们针对这些痛点所进行的思考与实践方案。
1.1 时效性痛点
传统数仓以小时/天级分区,数据完整才可查。然而,一些用户并不需要数据完整,只需要最近的数据做一些趋势分析。因此,现状无法满足用户越来越强的数据时效性需求。传统数仓ETL上一个任务完成后,才能开始下一个任务。即使是小时分区,层级处理越多,数据最终产出时效性越低。
1.2 数据集成同步痛点
业界成熟的方案是通过阿里巴巴 datax系统同步mysql 从库数据到hive表。定期全量或者增量进行同步。需要单独设置从库以应对数据同步时对db请求的压力。此外,db从库成本高,不可忽视。
增量同步面临如何解决历史分区数据修改问题。如果一条数据被更新了,那么仅通过增量同步,可能会在两个分区里分别存在更新前和更新后的数据。用户需要自行合并更新数据后,才能使用。
1.3 批流一体的存储介质不统一
业务下游即有时效性要求场景,也有离线ETL场景。Flink sql可以统一流批计算过程,但无统一存储,仍需要将实时、离线数据分开存储在kafka、hdfs。
2. 思考与方案
增量化数据湖建设选型采用Flink + Hudi。我们需要数据湖的ACID 事务保障、流批读写操作的支持。并且,相对于 Iceberg 的设计,Hudi 对 Upsert 的支持设计之初的主要支持方案在upsert能力、小文件合并能力上有明显优势。Append性能在版本迭代中逐渐完善。活跃的社区在陆续迭代增量消费、流式消费能力。综合对比,最终选择基于Hudi搭建增量数据湖生态。
3. HUDI内核优化
Hudi cow模式每次写入都需要进行合并,有io放大问题。Hudi 0.8起支持了mor模式,仅更新部分需要更新的数据文件。
但这会带来数据质量问题,主要是一些极端情况下的数据丢失、数据重复、数据延迟问题。我们在实际测试生产过程中发现了一些问题,尝试解决并反馈给社区。
3.1 底层数据可靠性优化
Hudi compaction大概代码结构
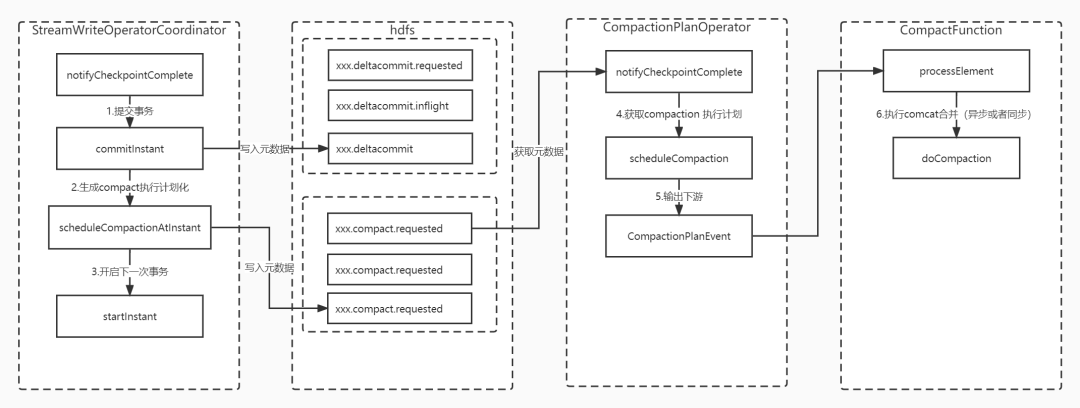

StreamWriteOperatorCoordinator 算子中的notifyCheckpointComplete逻辑:
-
提交当前事务并将元数据deltacommit写入hdfs
-
调用调度生成compant 执行计划并将compact.requested元数据写入hdfs
-
开启下一次事务
CompactionPlanOperator 算子中的notifyCheckpointComplete逻辑:
-
在0.9版本中通过sheduleCompation方法获取最后一个compact执行计划
-
将compact.requested执行计划转化为CompactionPlanEvent下发下游
CompactFuncation
-
processElement 最后执行doCompaction 完成合并
3.1.1 log跳过坏块bug,造成数据丢失
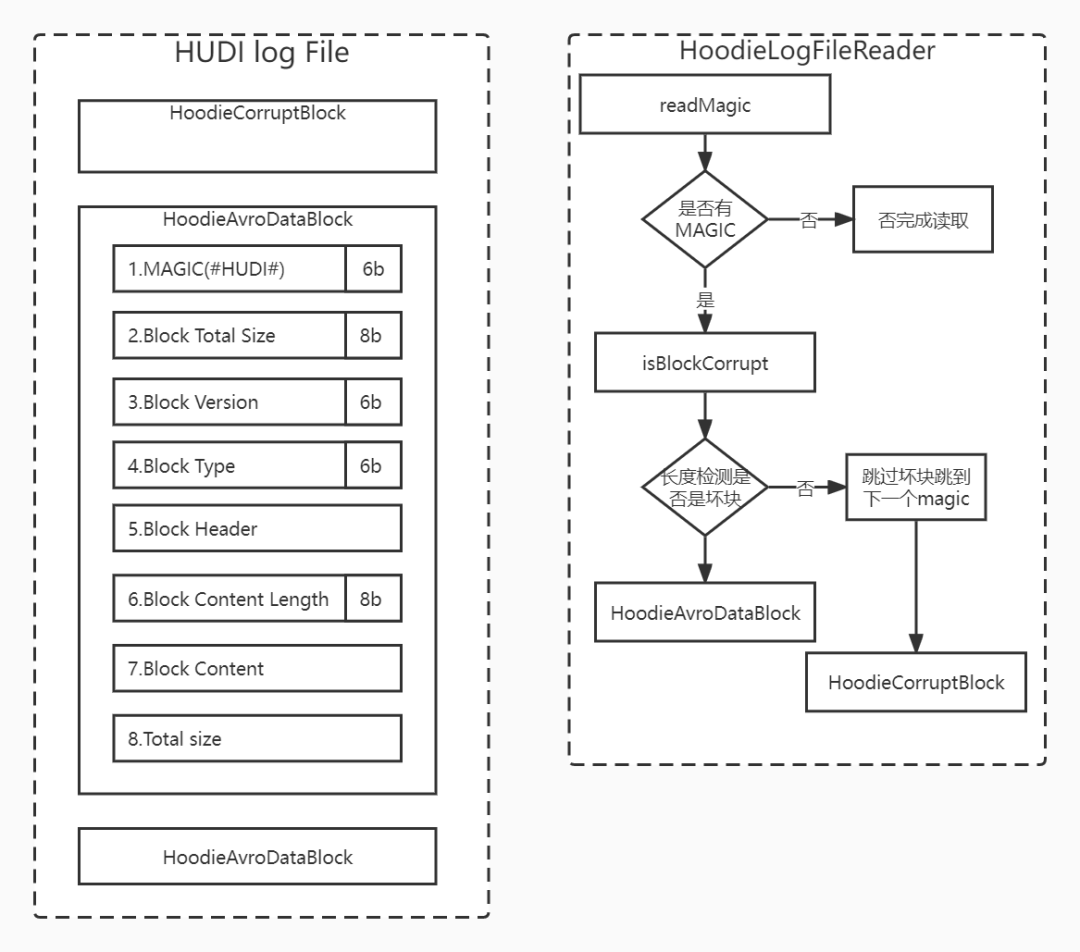
hudi log文件由一个个block 块组成,一个log中可能包含多个deltacommit 写入的块信息,每个块通过MAGIC进行分割,每个块包含的内容如上图所示。其中Block Header 会记录每个块的deltacommit instantTime,在compact 的过程中会扫描读取需要合并的块。HoodieLogFileReader是用来读取log文件,会将log 文件转化为一个个块对象。首先会读取MAGIC分隔,如果存在会读下一位置块的总大小,判断是否超过当前文件总大小来界定是否为坏块,检测到坏块会跳过坏块内容并创建坏块对象HoodieCorruptBlock,跳过的坏块是从当前block total size 位置以后检索MAGIC(#HUDI#),每次读取1兆大小,一直读取到下一个MAGIC分割为止,找到MAGIC后跳到当前MAGIC位置,后面可以接着在读完整的块信息。
上述提到坏块的位置是从block total size 位置以后检索的,当文件在极端情况下只写入MAGIC内容还没有写入内容任务会出现异常,此时会写入连续MAGIC,在读取的过程中会把MAGIC当做Block Total size 读取,在检索的过程中会将下一个正常的块给跳过,当成坏块返回。在合并的过程中这部分块数据就丢失了。这里跳过的坏块位置应该从MAGIC之后开始检索而不是block total size之后,读取时出现连续MAGIC就不会跳过正常块。
相关pr:https://github.com/apache/hudi/pull/4015
3.1.2 compaction和回滚的log合并,导致数据重复
在HoodieMergedLogRecordScanner 会扫描有效的块信息,极端情况下log 文件写入的块写入是完整的,但是deltacommit元数据提交前任务失败,并且log中的块信息也比deltacommit元数据的instant Time 还小,此时会被认为是有效的块被合并。因为deltacommit元数据没有写入成功,check point 重新启动将之前的数据进行回放。回放时被分配的flieId可能不同,当这部分数据被合并会发现数据重复并且fileId不一样现象。
在扫描log是否为效块时,如果当前时间线比现有没归档的时间线的元数据小的时候,加入已经归档的时间线,进行协同判断是否为有效块,不再只将未归档的时间线作为筛选条件。
相关pr:https://github.com/apache/hudi/pull/5052
3.1.3 数据非连续场景,最后一次数据不会触发compaction,导致RO表数据延迟
上述流程中调度compaction 执行计划必须在上一次事务提交成功后才会触发,如果一段数据都没有数据写入,compact 即使满足时间条件或者commit个数条件都不会形成compact 执行计划。上游没有执行计划下游Compaction 算子不会触发合并,用户在查询ro表,部分数据会一直查询不到。
去掉必须commitInstant 提交成功才调度生成compact执行计划的绑定,每次checkpoint 后都检查是否满足条件触发并生成Compaction 执行计划,避免最新数据无法被合并。当没有新数据写入的场景下元数据只有deltacommit.requested和deltacommit.inflight元数据不能直接用当前时间为compact instantTime。上游可能随时写入数据避免合并没有写完的数据,在生成compact执行计划也会检查元数据的deltacommit 和compact 元数据避免出现合并没写完的数据。此时compact instantTime可以为最近没完成的deltacommit instantTime 和最新完成compact 之间的时间。这样生成compaction执行计划元数据下游完成compact 合并就不会延迟了。
相关pr:https://github.com/apache/hudi/pull/3928
3.1.4 CompactionPlanOperator每次只取最后一次compaction,导致数据延迟
在StreamWriteOperatorCoordinator算子notifyCheckpointComplete方法中生产compact执行计划,在CompactionPlanOperator 算子notifyCheckpointComplete方法中消费执行计划下发操作合并数据。在极端情况下如果设置compact策略为一个commit就触发compact合并操作,这样在两个算子notifyCheckpointComplete中会不断的生产和消费compact 执行计划,一旦消费一端的compact出现异常任务失败,这样会堆积很多的compact.requested执行计划,而每次CompactionPlanOperator只会获取一个执行计划元数据,这样数据会产生堆积和延迟,总有一部分执行计划无法执行。在0.8版本取最后一次的compaction执行计划,这样会新的commit一直在合并,老的数据一直无法合并造成丢失数据的假像。后续社区改为获取最新的一次,如果下游出现某种原因的失败导致compact执行计划挤压,数据延迟会越来越大。
CompactionPlanOperator获取所有的compact 执行计划转化为CompactionPlanEvent下发下游,将CompactFunction 方法改为默认同步模式。异步模式中底层使用newSingleThreadExecutor线程池避免在同步的过程队列持有大量对象。
相关pr:https://issues.apache.org/jira/browse/HUDI-3618
3.1.5 log中没有符合时间线块,parquet 文件重新生成,之前记录丢失
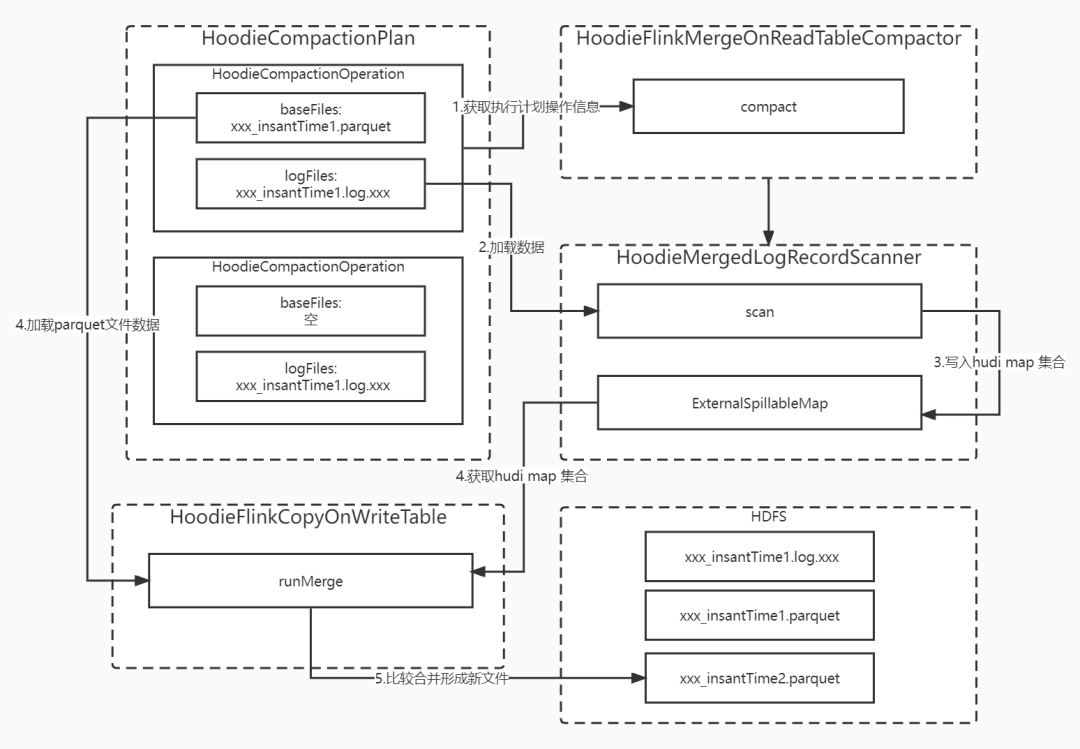
compact 执行计划包含多个HoodieCompactionOperation,每个HoodieCompactionOperation包含log文件和parquet 文件,但可能也只有logFlies 说明只有新增数据。在做compact 合并时会获取HoodieCompactionOperation中的log文件和parquet 文件信息,构建HoodieMergedLogRecordScanner将log文件中符合合并要求的块数据刷入ExternalSpillableMap中,在merge 阶段根据parquet 数据和ExternalSpillableMap的数据比较合并形成新的parquet文件,新文件的instantTime为compact 的instantTime。
在HoodieMergedLogRecordScanner中扫描log file文件中,需要符合时间线要求的log 块信息,如果没符合要求的块被扫描到,后续的merge操作不会运行,新的parquet 文件版本也没有。下一次compact 的执行计划获取的FileSlice只会有log 文件而没parquet文件,在执行compact runMerge 会当新增操作写入,没有和之前合并parquet数据合并之前的数据全部丢失,新parquet 文件中只有下一次log 产生的数据,导致数据丢失。
不论扫描是否符合要求,块信息都强制写入新的parquet文件,这样下一次compact合并执行计划中获取FileSlice都会有log 文件和parquet文件,可以正常进行handleUpdate 合并,保证数据不丢失。
3.2 Table Service优化
3.2.1 独立的table service — compaction外挂
背景:
目前社区提供了多种表服务方案,但实际生产应用中,尤其是平台化过程中,会面临多种问题。
原方案分析:
为了对比各方案的特点,我们基于hudi v0.9提供的表服务进行分析。
首先,我们将表服务拆解为调度+执行2阶段的过程。
根据调度后是否立刻执行,可以将调度分为inline调度(即调度后立马执行)与async调度(即调度后只生成plan,不立马执行)两种,
根据执行调用的方式,可分为sync执行(同步执行)、async执行(通过相应service异步执行,如AsyncCleanService)两种,
此外,相对于写入job,表服务作为一种数据编排job,本质上是区别于写入job的,根据这些服务是否内嵌在写入job中,我们将其称为内嵌模式和standalone模式两种模式。
以下,对社区提供的Flink on Hudi的多种表服务方案进行分析:
方案一 内嵌同步模式:在ingestion作业中,inline schedule + sync compact/cluster & inline schedule clean + async clean

该模式的问题很明显:每次写入后,立即通过内联调度并执行compact作业,完成后才开始新的instant,在流程上即直接影响数据写入的性能,在实际生产中不会采用。
方案二 内嵌异步模式:在ingestion作业中, async schedule + sync/async compact/cluster && inline schedule + sync/async clean
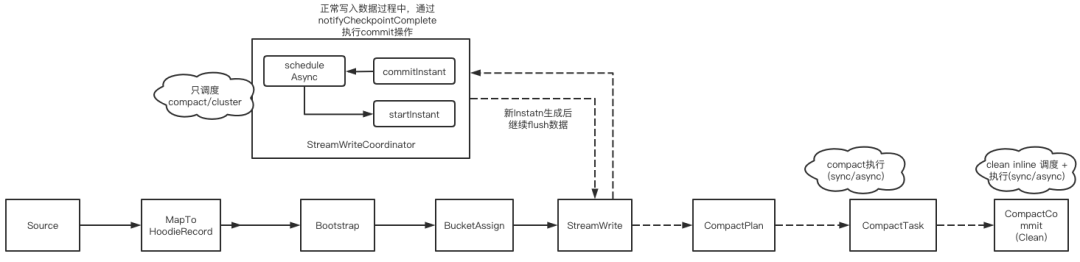
不同于方案一,该模式将资源消耗较大的compact/cluster等操作异步化至专门算子处理,ingestion流程仅保留了轻量的调度操作,对clean操作增加了同步/异步选择。
但依旧存在缺点,ingestion作业的流式处理,叠加上表服务的间歇性批处理,对资源消耗曲线新增造成很多冲激毛刺,甚至是很多作业oom的元凶,使得作业配置时不得不预留足够多资源,造成高优先资源闲时浪费。
方案三 standalone模式:ingestion作业 + compact/cluster作业组合
目前社区该方案尚不完善,其中写入作业流程参考方案一,对compact/cluster/clean等action提供单独的编排作业,以compact为例,HoodieFlinkCompactor的流程如下:
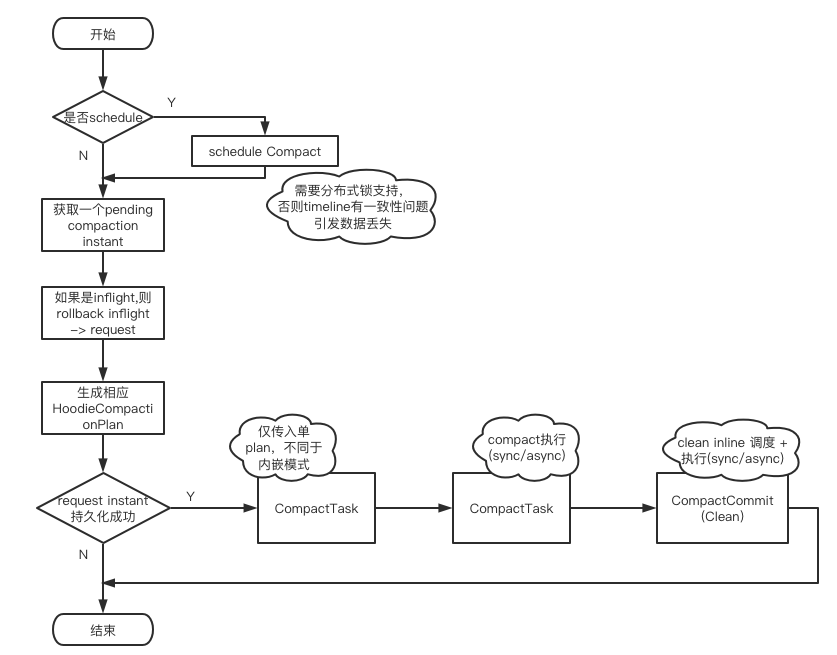
该方案通过抽象出单独的数据编排作业,从作业级别隔离使用,克服了方案二的弊端,从平台化的角度看,符合我们的需求。
选定方向后,就需要面对该方案目前的诸多缺陷,包括如下几点:
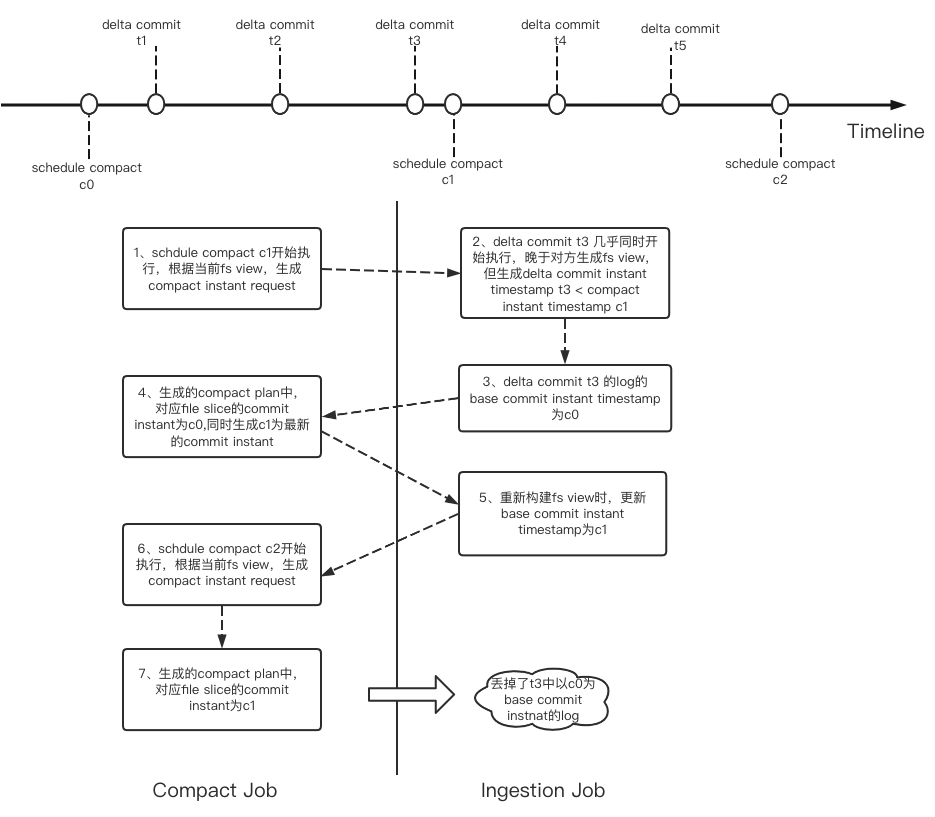
1. 在单writer模型下,编排作业的schedule模式不可用,会有的timeline一致性问题,导致数据丢失。
相对于ingestion作业,compact/cluster job本质上是另一个writer,多writer处于并发下,在无锁状态下timeline一致性是无法保证的,极端情况下会出现丢数据的问题,如下图所示:
2. 写入作业和编排作业没有standalone模式下的协同能力。
首先,是clean action的问题,虽然hudi内核能力已经健全,但目前表服务层面仅暴露出inline调度+执行的方法,导致无论写入还是编排作业都会包含clean,架构上过于混乱与不可控;
其次,编排作业CompactPlanSource与内嵌模式写入作业的CompactPlan是两个不同算子,dag未保持线性,不利于不同模式的切换;
此外,还存在作业编排调度不具备接收外部策略的能力,无法进行平台化,集成公司智能调度、专家诊断等系统等问题。
优化方案:
首先,解决timeline一致性问题,目前hudi社区已经有occ(乐观并发控制)运行模式的支持,引入了分布式锁(hive metastore、zookeeper)。但flink模块的相关支持尚在初始阶段中,我们内部也在进行相应应用测试,但发现距生产应用尚有诸多问题需要解决。
由于调度操作本身较为轻量,本期暂时把表服务scheduler保留在写入作业中,仍旧保持以单writer模型运行,以规避多writer问题。
其次,针对性优化hudi底层的表服务调度机制,将clean action也拆解为调度+执行的的使用范式,通过inlineScheduleEnabled配置,默认为true进行后向兼容,在standalone模式下,inlineScheduleEnabled为false。
然后,重构写入作业与编排作业,完善对3种运行模式的支持。具体包括:
对写入作业的表服务scheduler优化,提供DynamicConfigProvider支持外部策略集成;重写Clean算子,支持多种运行模式的切换;
对编排作业,重构作业使作业dag与内嵌模式线性一致;支持单instant,全批以及service常驻模式;优化写入与编排作业间的配置传递,使其达到托管任务的要求任意启停;
重构后的写入与编排作业(以compact为例)如下:

3.2.2 metaStore解决分区ready问题
增量化数仓,需要支持近实时业务场景分钟级数据可见性,需要在写入数据时就创建hiveMetaStore分区信息。
而离线依赖建hiveMetaStore分区即数据完整的语义。如何解决是一个问题。

任务调度,依赖调度系统。在数据ready后,通知调度系统,可以进行下游任务调度。与建分区讨论关系不大。
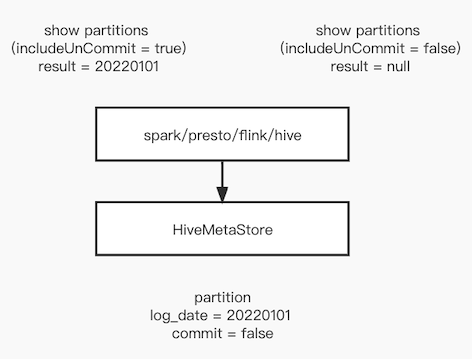
离线依赖hiveMetaStore问题,我们通过改造 hiveMetaStore ,赋予分区一个新的commit属性,若数据未ready 则commit为false,分区不可见。保持原有语义不变。
对于adhoc来说,带hint includeUnCommit=true标识查询,可在数据未完成时查询到数据。
对于离线来说,当分区的commit属性被置为true,才能查到分区。满足分区可见即数据完整的语义。
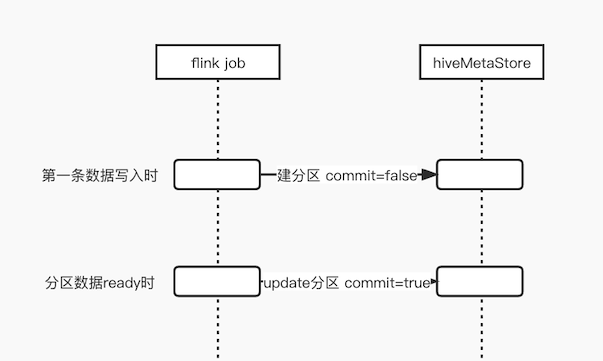
对于flink job来说,在数据第一次写入时,创建分区,并赋予分区commit=false标签,使得adhoc可以查到最新写入的数据。
在处理完分区数据,判断分区数据ready后,更新分区commit=true。此时,数据ready,分区对离线可见,满足“分区可见即数据完整”的语义。
4. 场景落地实践
4.1 增量化数仓
传统数仓TL上一个任务完成后,才能开始下一个任务。即使是小时分区,层级处理越多,数据最终产出时效性越低。
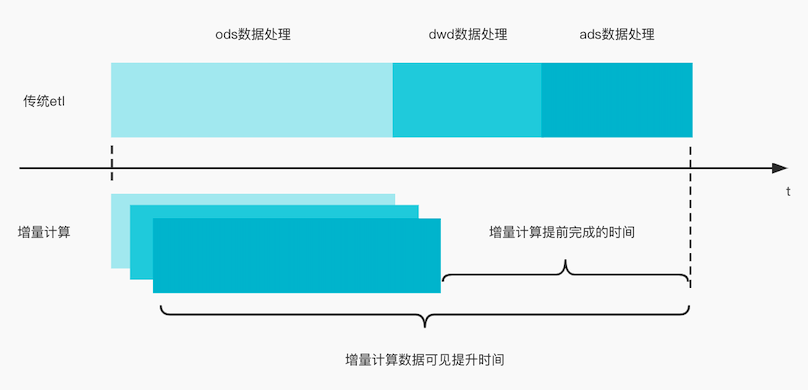
采用增量计算方式,每次计算读取上一次增量。这样当上游数据完整后,只需要额外计算最后一次增量的时间即可完成,可以提升数据完成时效性。
同时在第一批数据写入到ods层后就可增量计算至下一层直至产出,数据即可见,大大提升数据可见时效性。
具体实现方式是:通过hudi source,flink增量消费hudi数据。支持数仓跨层增量计算,如ods → dwd → ads 都使用hudi串联。支持同其他数据源做join、groupby,最终产出继续落hudi。
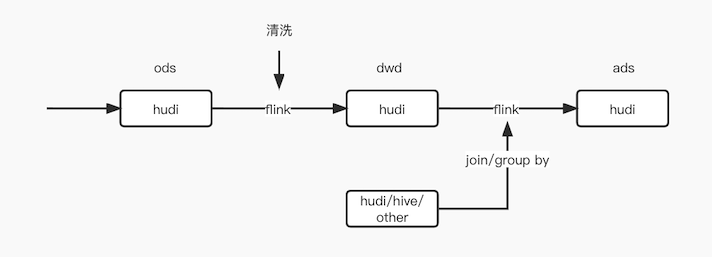
对于审核数据等有较高时效性诉求,可以采用此方案加速数据产出,提升数据可见时效性。
4.2 CDC到HUDI
4.2.1 面临的问题
1. 原有datax同步方式 简单来说就是 select * ,对mysql来说是慢查询,有阻塞业务库风险,所以需要单独开辟mysql从库满足入仓需求,有较高的mysql从库机器成本,是降本增效的对象之一。
2. 原有同步方式不能满足日益增加的时效性需求,仅能支持天/小时同步,无法支持到分钟级数据可见粒度。
3. 原有同步方式落hive表,不具备update能力,如果一条记录经过update,则可能在两个以mtime为时间分区都存在此数据,业务使用还需要做去重,使用成本较高。
4.2.2 解决思路
通过flink cdc消费mysql增量+全量数据,分chunk进行select,无需单独为入仓开辟mysql从库。
落hudi支持update、delete,相当于hudi表是mysql表的镜像。
同时支持分钟级可见,满足业务时效性诉求。
4.2.3 整体架构
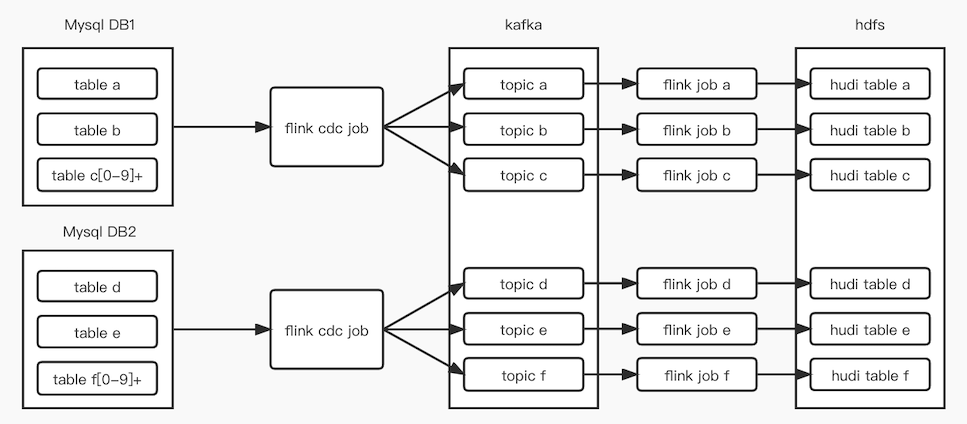
一个db库用一个flink cdc job进行mysql数据同步,一张表的数据分流到一个kafka topic中,由一个flink job消费一个kafka topic,落到hudi表中。
4.2.4 数据质量保障 – 不丢不重
flink cdc source
简单来说就是:全量 + 增量 通过changlog stream 方式将数据变更传递给下游。
全量阶段:分chunk读取, select * + binlog修正,无锁的将全量数据读出并传递给下游。
增量阶段:伪装成为一个从库,读取binlog数据传递给下游。
flink
通过flink checkpoint机制,将处理完成的数据位点记录到checkpoint中,如果后续发生异常则从checkpoint可保证数据不丢不重。
kafka
kafka client开启ack = all ,当所有副本都接收到数据后,才ack,保证数据不丢。
kafka server 保证replicas大于1,避免脏选举。
这里不会开启kafka事务(成本较高),保证at least once 即可。由下游hudi做去重。
hudi sink
hudi sink同样基于flink checkpoint实现类似二阶段提交方式,实现数据写hudi表不丢失。
通过增加由flink cdc生成的单调递增的“版本字段”进行比较,单条记录版本高的写入,低的舍弃。同时解决去重和乱序消费问题。
4.2.5 字段变更
mysql业务库进行了字段变更、新增字段怎么办?
面临的问题
1. 数据平台新增字段有安全准入问题,需要用户确认,是否需要加密入仓。
2. 字段类型变更,需要用户确认下游任务是否兼容。
3. hudi的column evalution能力有限,比如int转string类型就无法支持。
解决思路
与dba约定,部分变更支持自动审批(如新增字段、int类型转long等)通过。并且异步通知berserker(b站大数据平台系统),由berserker变更①hudi表信息,以及②更新flink job信息。
超出约定变更部分(如int转varchar等),走人工审批,需要berserker确认① hudi表变更完成、②写入hudi的flink job变更完成后,再放行mysql ddl变更工单。
我们改造了 Flink cdc job,可以感知mysql字段变更,向下游kafka发送变更后数据,不受审批约束,将变更后的数据暂存在kafka topic中,此kafka对用户不可见。下游写入hudi任务不变更照常消费,不写入新增字段,用户确认数据可入仓后,再从kafka回放数据,补充写入新增字段。
方案
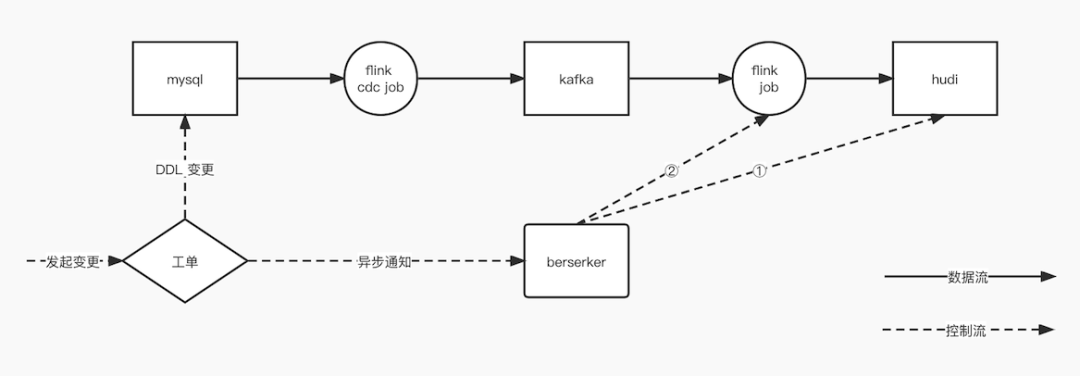
mysql字段类型和hudi类型存在不对应情况。flink job 消费kafka 定义字段类型和 hudi 表定义字段不对应,需要berserker在拼flink sql时候,额外拼入转换的逻辑。
Flink cdc sql 自动感知字段变更改造
flink cdc原生sql是需要定义mysql表的字段信息的,那么当mysql出现字段变更时,是必然无法做到自动感知,并传递变更后数据给下游的。
原生flink cdc source会对所有监听到的数据在反序列化时根据sql ddl定义做column转换和解析,以row的形式传给下游。
我们在cdc-source中新增了一种的format方式:changelog bytes序列化方式。该format在将数据反序列化时在不再进行column转换和解析,而是将所有column直接转换为changelog-json二进制传输,外层将该二进制数据直接封装成row再传给下游。对下游透明,下游hudi在消费kafka数据的时候可以直接通过changelog-json反序列化进行数据解析。
并且由于该改动减少了一次column的转换和解析工作,通过实际测试下来发现除自动感知schema变更外还能提升1倍的吞吐。
4.3 实时DQC
dqc kafka监控存在几个痛点:
-
基于kafka的实时dqc很难做同比环比的指标判断。
-
dqc实时链路是单独的开发的,和离线dqc不通用。维护成本高。
-
针对同一条流多个监控规则,是需要设立多个flink job,每个job计算一个指标。不能复用,资源开销大。
架构
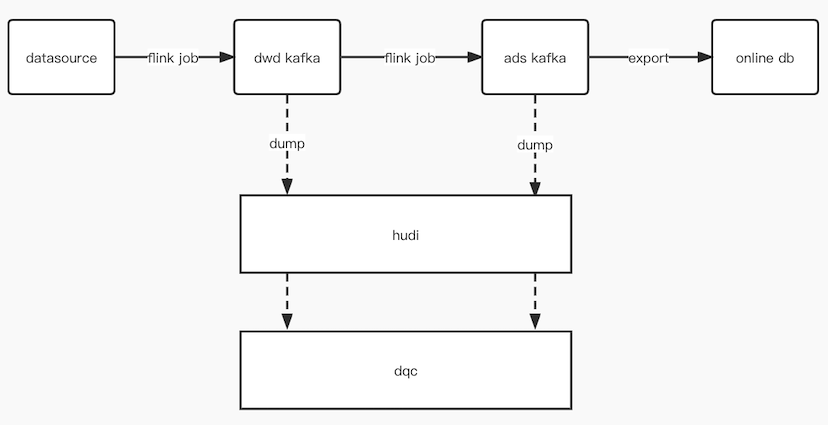
将kafka数据dump到hudi表后,提供dqc数据校验。不影响生产秒级/亚秒级数据时效,又可以解决以上痛点。
hudi提供分钟级的监控,可以满足实时dqc监控诉求。时间过短,可能反而会因为数据波动产生误告警。
hudi以hive表的形式呈现,使得实时dqc可以和离线dqc逻辑一致,可以很容易的进行同环比告警,易于开发维护。
实时DQC on Hudi 使得实时链路数据变得更易观测。
4.4 实时物化
背景
有些业务方需要对实时产出的数据进行一个秒级的聚合查询。
如实时看板需求,需要一分钟一个数据点来展示DAU曲线,等多指标聚合查询场景。
同时结果数据要写入update存储,实时更新。
难点
在较大数据规模下,基于明细产出几十上百个聚合计算结果,要求秒级返回,几乎不可能。
目前公司内支持update类型的存储主要是redis/mysql,计算结果导入意味着数据出仓,脱离了hdfs存储体系,同时也要使用对应的client进行查询,开发成本较高。
现有的hdfs体系内计算加速方案如物化、预计算大都是基于离线场景,对实时数据提供物化查询能力较弱。
目标
支持hdfs体系内的update存储。让数据无需出仓导入外部存储,可以直接使用olap引擎高效查询。
通过sql就可以简单定义实时物化表。查询时通过sql解析,命中物化表查询则可秒级返回多个聚合查询结果。
方案
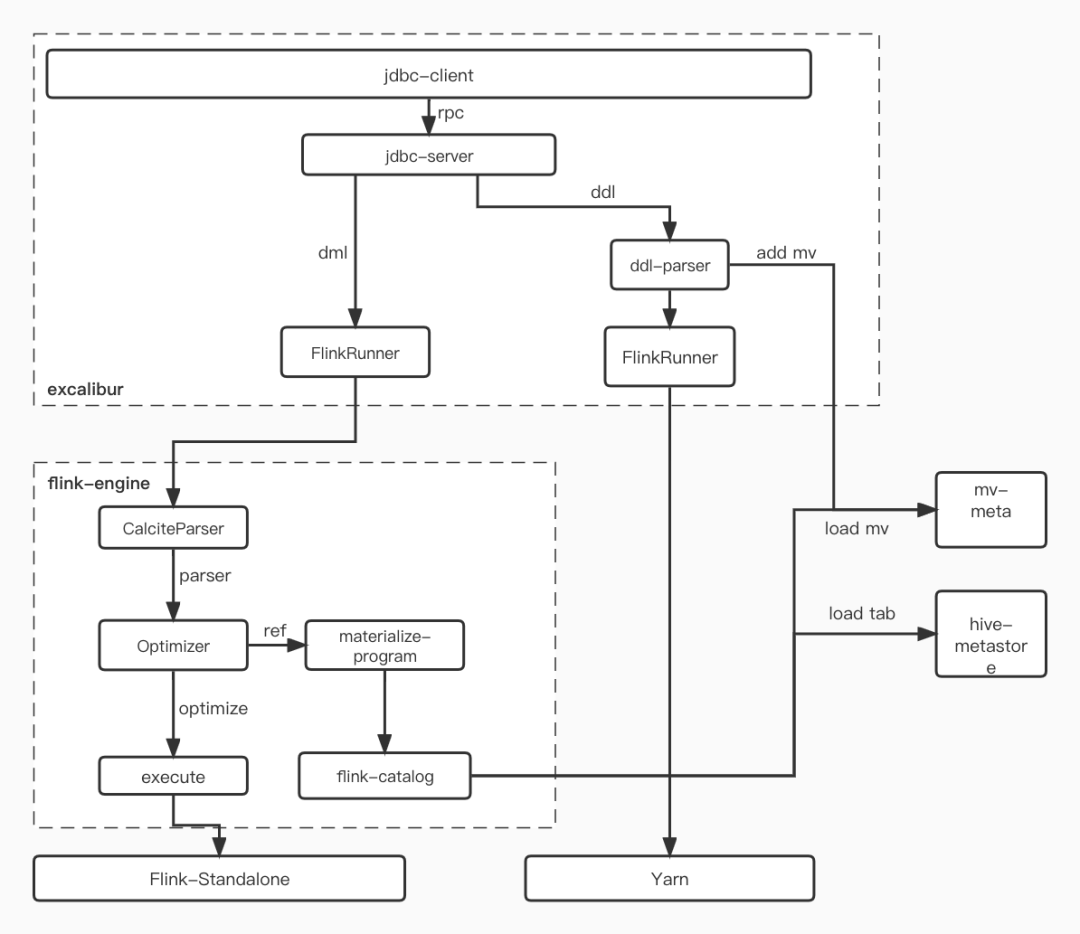
基于flink + hudi提供实时物化的能力。
通过sql自定义物化逻辑到基于hudi的物化表。将明细数据写入明细hudi表中,并拉起一个flink job 进行实时聚合计算,将计算结果upsert到物化的hudi表中。
在查询时通过sql解析,如果规则命中物化表,则查询物化表中的数据,从而达到加速查询的效果。
5. 未来展望
5.1 HUDI内核能力增强及稳定性优化
Hudi timeline支持 乐观锁解决并发冲突,支持多流同时写一张表。从底层支持新增数据和回补数据同时写入hudi。
支持更丰富的schema evalution。避免重新建表、重新导入数据的繁重操作。
Hudi meta server,统一实时表离线表,支持instance版本等信息。支持flink sql上使用time travel,满足取数据快照等诉求
Hudi manager 根据不同的表按需调配compaction、clustering、clean。用于离线ETL的表,低峰期进行compaction,资源上削峰填谷。对于近线分析的表,积极compaction以及clustering,减少查询摄取文件数,提升查询速度。
5.2 切换弱实时场景从Kafka到HUDI
在弱实时场景上实现流批统一存储。Kafka对于突发流量以及拉取历史数据达到性能瓶颈时,难易紧急扩容分摊读写负载。可以将分钟级的弱实时使用场景,从Kafka切换到HUDI,利用HUDI可读取增量数据的能力,满足业务需求,并且HUDI基于分布式文件系统可快速扩容副本的能力,满足紧急扩容的需求。
本文转载自实时团队 哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/pjZAjgHF-HdZNjr7LfY9JA。