


分享嘉宾:杜军令 字节跳动 大数据工程师
出品平台:DataFunTalk
导读:Doris是一种MPP架构的分析型数据库,主要面向多维分析、数据报表、用户画像分析等场景。自带分析引擎和存储引擎,支持向量化执行引擎,不依赖其他组件,兼容MySQL协议。
01
Doris简介
Apache Doris具备以下几个特点:
-
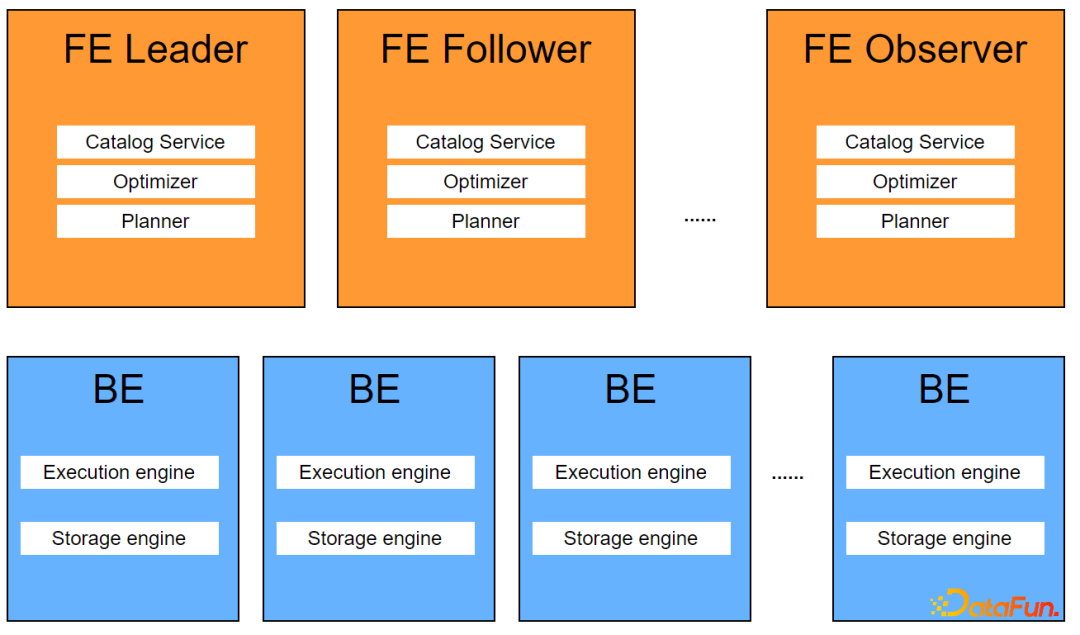
良好的架构设计,支持高并发低延时的查询服务,支持高吞吐量的交互式分析。多FE均可对外提供服务,并发增加时,线性扩充FE和BE即可支持高并发的查询请求。
-
支持批量数据load和流式数据load,支持数据更新。支持Update/Delete语法,unique/aggregate数据模型,支持动态更新数据,实时更新聚合指标。
-
提供了高可用,容错处理,高扩展的企业级特性。FE Leader错误异常,FE Follower秒级切换为新Leader继续对外提供服务。
-
支持聚合表和物化视图。多种数据模型,支持aggregate, replace等多种数据模型,支持创建rollup表,支持创建物化视图。rollup表和物化视图支持动态更新,无需用户手动处理。
-
MySQL协议兼容,支持直接使用MySQL客户端连接,非常易用的数据应用对接。
Doris 由 Frontend(以下简称FE)和 Backend(以下简称BE)组成,其中FE负责接受用户请求、编译、优化、分发执行计划、元数据管理、BE节点的管理等功能,BE负责执行由FE下发的执行计划,存储和管理用户数据。
02
数据湖格式Hudi简介
Hudi是下一代流式数据湖平台,为数据湖提供了表格式管理的能力,提供事务,ACID,MVCC,数据更新删除,增量数据读取等功能。支持Spark, Flink, Presto, Trino等多种计算引擎。
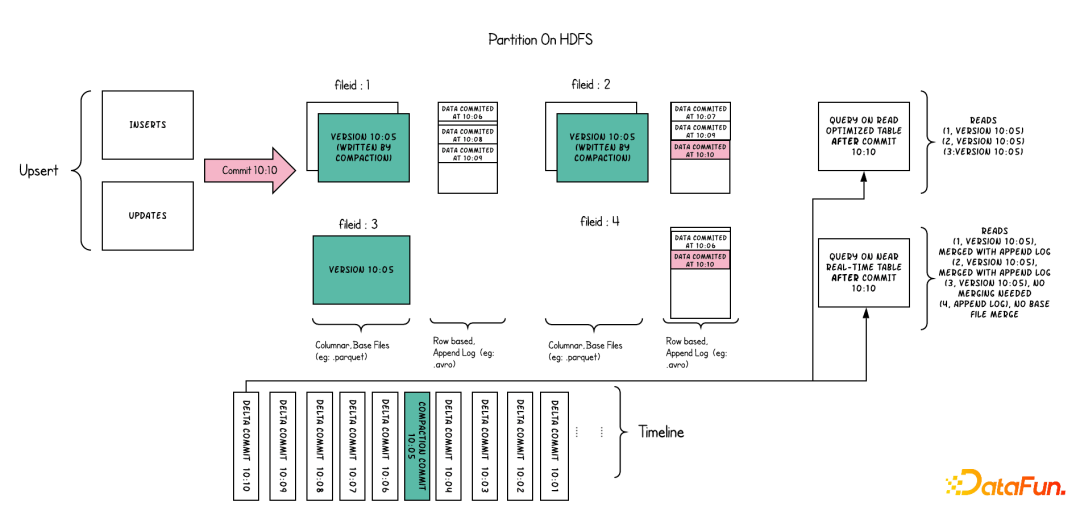
Hudi根据数据更新时行为不同分为两种表类型:

针对Hudi的两种表格式,存在3种不同的查询类型:

03
Doris分析Hudi数据的技术背景
在数仓业务中,随着业务对数据实时性的要求越来越高,T+1数仓业务逐渐往小时级、分钟级,甚至秒级演进。实时数仓的应用也越来越广,也经历了多个发展阶段。目前存在着多种解决方案。
1. Lambda架构
Lambda将数据处理流分为在线分析和离线分析两条不同的处理路径,两条路径互相独立,互不影响。
离线分析处理T+1数据,使用Hive/Spark处理大数据量,不可变数据,数据一般存储在HDFS等系统上。如果遇到数据更新,需要overwrite整张表或整个分区,成本比较高。
在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。
该套方案存在以下缺点:
-
同一套指标可能需要开发两份代码来进行在线分析和离线分析,维护复杂。
-
数据应用查询指标时可能需要同时查询离线数据和在线数据,开发复杂。
-
同时部署批处理和流式计算两套引擎,运维复杂。
-
数据更新需要overwrite整张表或分区,成本高。
2. Kappa架构
随着在线分析业务越来越多,Lambda架构的弊端就越来越明显,增加一个指标需要在线离线分别开发,维护困难,离线指标可能和在线指标对不齐,部署复杂,组件繁多。于是Kappa架构应运而生。
Kappa架构使用一套架构处理在线数据和离线数据,使用同一套引擎同时处理在线和离线数据,数据存储在消息队列上。
Kappa架构也有一定的局限:
-
流式计算引擎批处理能力较弱,处理大数据量性能较弱。
-
数据存储使用消息队列,消息队列对数据存储有有效性限制,历史数据无法回溯。
-
数据时序可能乱序,可能对部分在时序要求方面比较严格的应用造成数据错误。
-
数据应用需要从消息队列中取数,需要开发适配接口,开发复杂。
3. 基于数据湖的实时数仓
针对Lambda架构和Kappa架构的缺陷,业界基于数据湖开发了Iceberg, Hudi, DeltaLake这些数据湖技术,使得数仓支持ACID, Update/Delete,数据Time Travel, Schema Evolution等特性,使得数仓的时效性从小时级提升到分钟级,数据更新也支持部分更新,大大提高了数据更新的性能。兼具流式计算的实时性和批计算的吞吐量,支持的是近实时的场景。
以上方案中其中基于数据湖的应用最广,但数据湖模式无法支撑更高的秒级实时性,也无法直接对外提供数据服务,需要搭建其他的数据服务组件,系统较为复杂。基于此背景下,部分业务开始使用Doris来承接,业务数据分析师需要对Doris与Hudi中的数据进行联邦分析,此外在Doris对外提供数据服务时既要能查询Doris中数据,也要能加速查询离线业务中的数据湖数据,因此我们开发了Doris访问数据湖Hudi中数据的特性。
04
Doris分析Hudi数据的设计原理
基于以上背景,我们设计了Apache Doris中查询数据湖格式Hudi数据,因Hudi生态为java语言,而Apache Doris的执行节点BE为C++环境,C++ 无法直接调用Hudi java SDK,针对这一点,我们有三种解决方案。
①实现Hudi C++ client,在BE中直接调用Hudi C++ client去读写Hudi表。
该方案需要完整实现一套Hudi C++ client,开发周期较长,后期Hudi行为变更需要同步修改Hudi C++ client,维护较为困难。
②BE通过thrift协议发送读写请求至Broker,由Broker调用Hudi java client读取Hudi表。
该方案需要在Broker中增加读写Hudi数据的功能,目前Broker定位仅为fs的操作接口,引入Hudi打破了Broker的定位。第二,数据需要在BE和Broker之间传输,性能较低。
③在BE中使用JNI创建JVM,加载Hudi java client去读写Hudi表。
该方案需要在BE进程中维护JVM,有JVM调用Hudi java client对Hudi进行读写。读写逻辑使用Hudi社区java实现,可以维护与社区同步;同时数据在同一个进程中进行处理,性能较高。但需要在BE维护一个JVM,管理较为复杂。
④使用BE arrow parquet c++ api读取hudi parquet base file,hudi表中的delta file暂不处理。
该方案可以由BE直接读取hudi表的parquet文件,性能最高。但当前不支持base file和delta file的合并读取,因此仅支持COW表Snapshot Queries和MOR表的Read Optimized Queries,不支持Incremental Queries。
综上,我们选择方案四,第一期实现了COW表Snapshot Queries和MOR表的Read Optimized Queries,后面联合Hudi社区开发base file和delta file合并读取的C++接口。
05
Doris分析Hudi数据的技术实现
Doris中查询分析Hudi外表使用步骤非常简单。
1. 创建Hudi外表
建表时指定engine为Hudi,同时指定Hudi外表的相关信息,如hive metastore uri,在hive metastore中的database和table名字等。
建表仅仅在Doris的元数据中增加一张表,无任何数据移动。
建表时支持指定全部或部分hudi schema,也支持不指定schema创建hudi外表。指定schema时必须与hiveMetaStore中hudi表的列名,类型一致。
Example:
PlaintextCREATE TABLE example_db.t_hudiENGINE=HUDIPROPERTIES ("hudi.database" = "hudi_db","hudi.table" = "hudi_table","hudi.hive.metastore.uris" = "thrift://127.0.0.1:9083");CREATE TABLE example_db.t_hudi (column1 int,column2 string)ENGINE=HUDIPROPERTIES ("hudi.database" = "hudi_db","hudi.table" = "hudi_table","hudi.hive.metastore.uris" = "thrift://127.0.0.1:9083");
2. 查询Hudi外表
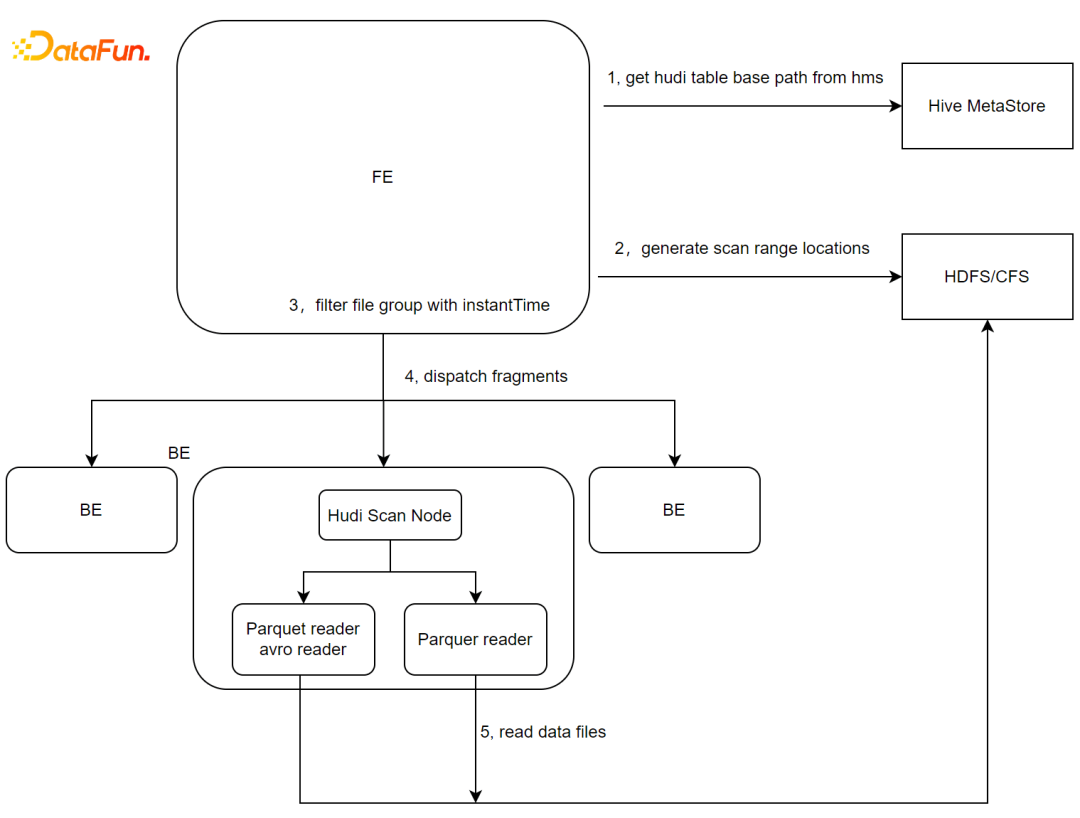
查询Hudi数据表时,FE在analazy阶段会查询元数据获取到Hudi外表的的hive metastore地址,从Hive metastore中获取hudi表的schema信息与文件路径。
-
获取hudi表的数据地址。
-
FE规划fragment增加HudiScanNode。HudiScanNode中获取Hudi table对应的data file文件列表。
-
根据Hudi table获取的data file列表生成scanRange。
-
下发HudiScan 任务至BE节点。
-
BE节点根据HudiScanNode指定的Hudi外表文件路径调用native parquet reader进行数据读取。
06
后期规划
目前Apche Doris查询Hudi表已合入社区,当前已支持COW表的Snapshot Query,支持MOR表的Read Optimized Query。对MOR表的Snapshot Query暂时还未支持,流式场景中的Incremental Query也没有支持。
后续还有几项工作需要处理,我们和社区也在积极合作进行中:
-
MOR表的Snapshot Query。MOR表实时读需要合并读取Data file与对应的Delta file,BE需要支持Delta file AVRO格式的读取,需要增加avro的native读取方式。
-
COW/MOR表的Incremental Query。支持实时业务中的增量读取。
-
BE读取Hudi base file和delta file的native接口。目前BE读取Hudi数据时,仅能读取data file,使用的是parquet的C++ SDK。后期我们和联合Hudi社区提供Huid base file和delta file的C++/Rust等语言的读取接口,在Doris BE中直接使用native接口来查询Hudi数据。
推荐阅读
基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
使用 Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
本文转载自 杜军令 ApacheHudi,原文链接:https://mp.weixin.qq.com/s/0goEVO554PgAbKjC4p4V1A。