
?云原生架构下,基于 Hadoop 技术栈搭建数据平台应该如何改造? 理想汽车大数据平台涉及的组件多, 在从 Hadoop 到云原生演进的过程中边探索,边实践,积累了不少一手经验;同时,他们率先在对象存储上使用 JuiceFS,实现平台级文件共享、跨平台使用海量数据等场景。
01
理想汽车在Hadoop时代的技术架构

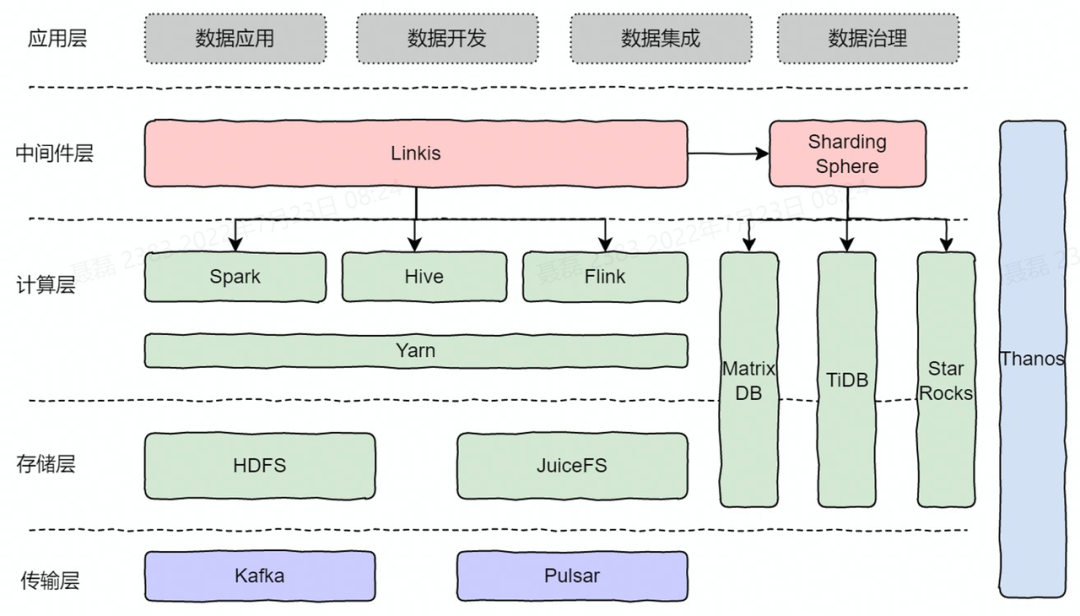
理想汽车大数据平台当前架构
-
• 传输层:Kafka 和 Pulsar 。平台构建初期整体都用的 Kafka,Kafka 的云原生能力比较差,Pulsar 在设计之初就是按照云原生架构设计的,并且有一些非常适合 IoT 场景的能力,和我们的业务场景也比较匹配,所以我们近期引进了 Pulsar;
-
• 存储层是 HDFS + JuiceFS;
-
• 计算层目前的主要的计算引擎是 Spark 、Hive 和 Flink,这些计算引都是跑在现在的 Yarn 上。三个计算引擎是通过 Apache Linkis 去管理的,Linkis 是微众银行开源的,目前我们对 Linkis 用的也是比较重的;
-
• 图片的右侧数据库,第一个 MatrixDB ,它是一个商业版的时序数据库,TiDB 主打做 OLTP 和 OLAP 的混合场景,目前我们主要用它来做 TP 的场景。StarRocks 负责 OLAP 的场景;
-
• ShardingSphere,是想要用它的 Database Plus 的概念去把底下的数据库统一的去做一个网关层的管理。目前还在探索阶段,有很多新增特性我们都很感兴趣;
-
• Thanos 是一个云原生的监控方案,我们已经将组件、引擎和机器的监控都整合到 Thanos 方案里;
-
• 应用层是四个主要的中台产品,包括数据应用、数据开发、数据集成和数据治理。
特点
-
• 第一,整个方案的组件是比较多的,用户对这些组件的依赖性强,且组件之间互相的依赖性也比较强。建议大家在未来组件选型的时候尽量选择云原生化比较成熟的组件;
-
• 第二,我们的数据是有明确的波峰波谷。出行场景一般都是早高峰晚高峰,周六周日人数会比较多;
-
• 第三个特点,我们数据的热度基本上都是最热的,一般只访问最近几天或者最近一周的数据。但是产生了大量的数据,有的时候可能需要大量回溯,因而数据也需要长久的保存,这样对数据的利用率就差了很多。最后,整个数据体系目前从文件层面看缺少一些有效的管理手段。从建设至今,基本上还是以 HDFS 为主,有大量的无用数据存在,造成了资源的浪费,这是我们亟待解决的问题。
大数据平台的痛点
-
• 第一,组件多,部署难度高、效率低。围绕 Hadoop 的大数据组件有 30 多个,常用的也有 10 几个之多。有些组件之间有强依赖和弱依赖,统一的配置和管理变得非常复杂。
-
• 第二,机器成本和维护成本比较高。为了业务的稳定运行,离线和实时集群进行了分开部署。但上面提到的业务特点,我们业务波峰波谷现象明显,整体利用率不高。集群组件繁多需要专门人员管理和维护。
-
• 第三,跨平台数据共享能力。目前跨集群共享数据只能通过 DistCp 方式同步到其他 Hadoop 集群。无法方便快捷的同步到其他平台和服务器上。
-
• 第四,数据的安全和隐私合规。基于不同的数据安全需求,普通用户通过 Ranger 进行管理,特殊安全需求只能通过构建不同集群并设置单独 VPC 策略的方式来满足,造成很多数据孤岛和维护成本。
02
理想汽车云原生的演进与思考
-
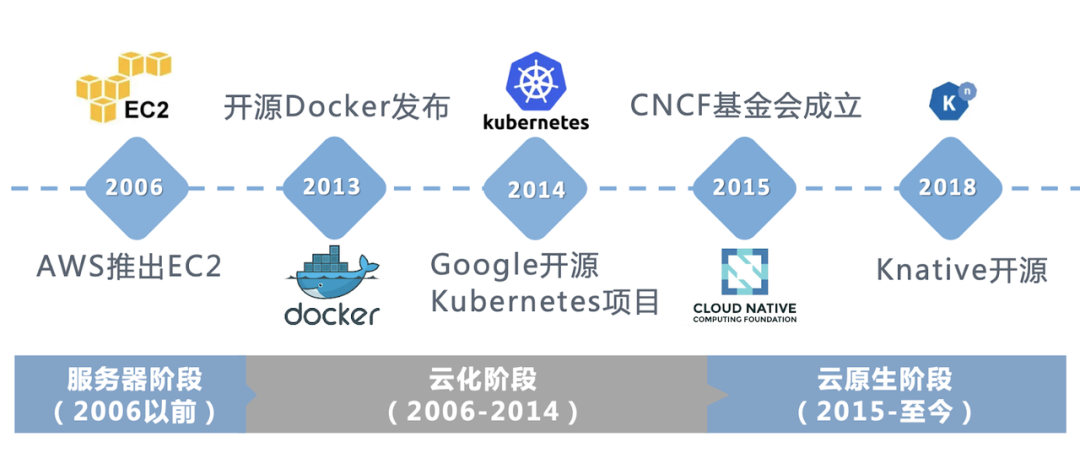
• 第一个阶段, AWS 提出了云原生的概念,并且在 2006 年推出了 EC2,这个阶段是服务器阶段,上文提到的云计算阶段;
-
• 第二个阶段,云化阶段,主是在开源 Docker 发布和谷歌开源了 Kuberneters 之后。Kubernetes 是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过 Kubernetes 能够进行应用的自动化部署和扩缩容;
-
• 第三个阶段,2015 年的时候成立了 CNCF 基金会,在主推云原生概念,帮助云原生整体发展的更好。最后是 Knative 的开源,Knative 一个很重要的目标就是制定云原生、跨平台的 Serverless 编排标准。衍生到现在,已经是云原生 2.0 阶段,即 Serverless 这个阶段。我个人理解大数据的发展应该也是朝着 Serverless 的方向去发展。比如现在 AWS 整个在线的服务基本上都做到了 Serverless。
大数据云原生架构
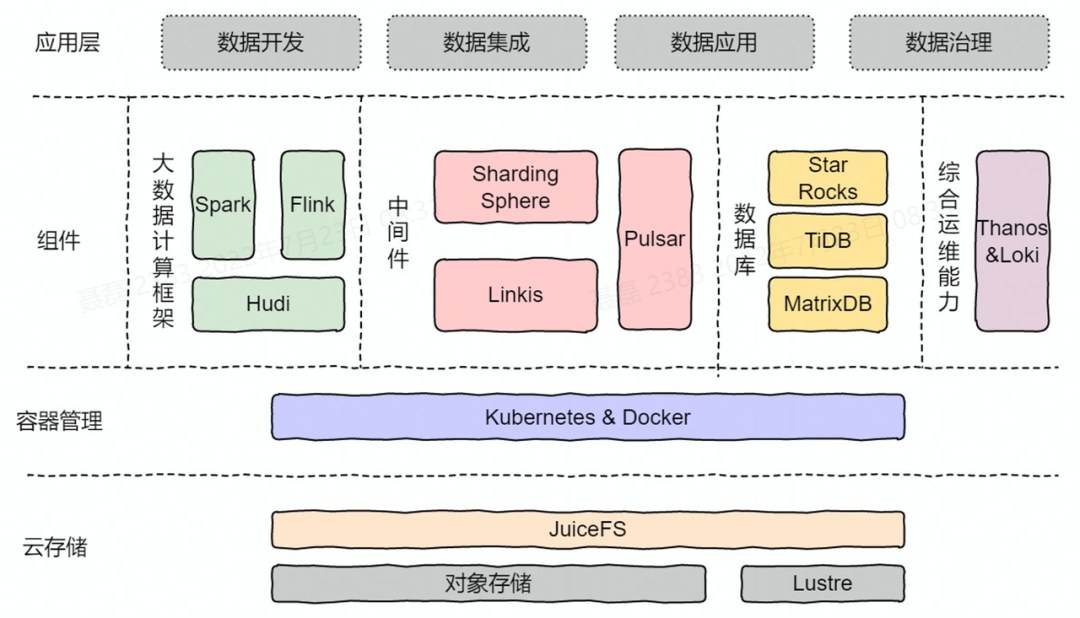
-
• 存储层,云原生化之后所有的存储基本上都是对象存储了。上面的架构图引出了 Lustre,下文会详细介绍。大家可以理解为「云存储」这一层主要是以 JuiceFS 来管理对象存储和 Lustre 并行分布式文件系统(注:由于 Lustre 的单副本问题,我们目前也在考虑使用云服务商提供的并行文件系统产品);
-
• 容器层,主要是在计算、存储、网络之上,全部都用 Kubernetes 加 Docker 来替代,所有的组件都是在这上面生长出来的;
-
• 组件部分,首先是大数据计算框架,我们可能会废弃掉 Hive,直接沿用 Spark 和 Flink,通过 Hudi 去做数据湖 2.0 的底层能力支撑并逐步替换HDFS;
-
• 中间件部分,除了 Pulsar 以外还有 Kafka,目前 Kafka 的云原生化做的并不是特别好,我个人更倾向于用 Pulsar 去替换 Kafka。目前线上已经使用Linkis适配了所有Spark引擎,后面会进行Flink的适配和整合。ShardingSphere 在 5.1.2 版本刚刚支持云原生,我们会按计划进行场景验证和能力探索;
-
• 数据库层,还是 TiDB、StarRocks、MatrixDB,目前这三个数据库已经有云原生的能力,它们都支持对象存储。但这一块还没有单独去测过,我们目前用的还都是物理机。因为对于数据库来说,当前对象存储提供的IO能力还无法满足数据库的性能要求,会使得数据库的整体性能大打折扣;
-
• 运维方面,由 Thanos 方案多加了一个 Loki,主要是做云原生的日志收集。但是 Loki 和 Thanos 只是其中两个,未来我理解应该会朝着阿里开源的SREWorks能力看齐,把整个的质量成本效率和安全全部都封在综合运维能力里边,这样就可以把整个的云原生管理起来;
-
• 可观测性,云原生领域最近比较热门的概念。现在大家做的组件,有一些是在有热度之后,才开始发展云原生的,它并不是一开始生在云上,它只是后面希望长在云上。这种情况下它会遇到一些问题,第一个问题,就是没有全面的可见性的监控。我们考虑后续如何把这些组件整体的出一个方案,在所有组件上到云原生后可以有效的监控。
-
1. 统一使用云原生的存储作为所有组件(包括数据库)的底层存储;
-
2. 所有组件都运行在容器中;
-
3. 使用 Serverless 架构服务上层应用。
-
但是这样也给目前的数据平台产品带来挑战,就是如何设计具备 Serverless
能力的产品来给用户使用。
大数据云原生的优势
大数据云原生的难点
03
JuiceFS在云原生方案的探索和落地
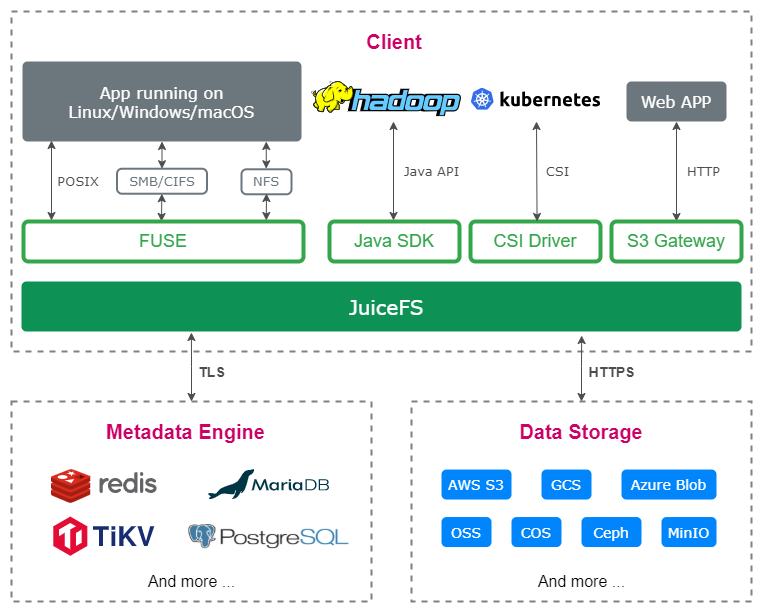
-
• 第一, JuiceFS 是多协议兼容。完全兼容 POSIX、HDFS 和 S3 协议 ,目前用下来都是百分百兼容的,没有遇到任何问题。
-
• 第二,跨云的能力。当企业有一定规模之后,为了避免系统性风险,都不会只使用一个云服务商。不会绑在一个云上,都会是多云操作的。这种情况下,JuiceFS 的跨云数据同步的能力就起到了作用。
-
• 第三,云原生的场景。JuiceFS 支持 CSI,目前 CSI 这个场景我们还没有用,我们基本上都是用 POSIX 去挂载的,但是使用 CSI 的方式会更简单更兼容,我们现在也正在往云原生上去发展,但整个的组件还没有真正上到 Kubernetes。
JuiceFS 在理想汽车的应用
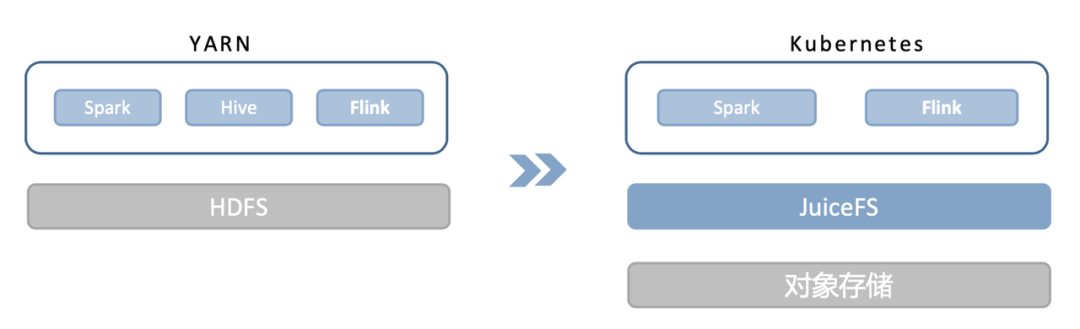
场景1:从 HDFS 将数据持久化到对象存储
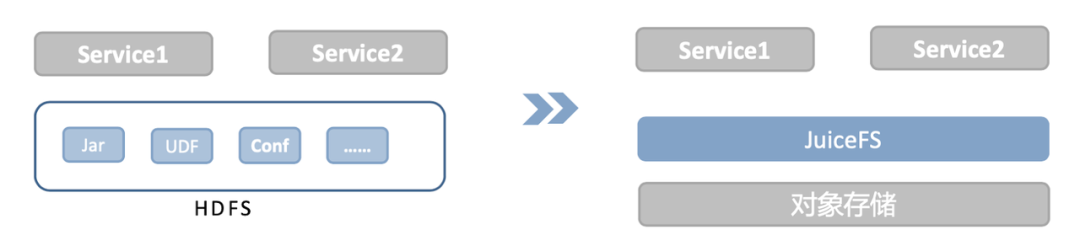
场景2:平台级别的文件共享
场景3:海量数据跨平台使用

新场景:云原生存储加速 – Lustre 作为读缓存 (测试中)

JuiceFS 在大数据云原生的整体方案

目前使用 JuiceFS 遇到的一些难题
juicefs.prefetch、juicefs.max-uploads 和 juicefs.memory-size。其中在调优 juicefs.memory-size 配置的过程中遇到了一些问题,这个配置的默认值是 300MB,官方的建议是 设置默认值 4 倍大小的堆外内存,也就是 1.2GB。目前我们大部分任务都是配置到 2GB 的堆外内存,但是有些任务即使配置了超过 2GB 的内存也偶尔会写入失败(HDFS 可以稳定写入)。不过这个并不一定是 JuiceFS 的问题,也有可能是 Spark 或者对象存储的原因导致。因此目前我们也在计划把 Spark 和 JuiceFS 深度适配以后,再一步一步来找原因,争取把这些坑都趟过去,在保证任务稳定的情况下把内存降下来。04
未来和展望
基于 Flink + Hudi + JuiceFS 的实时数据湖方案
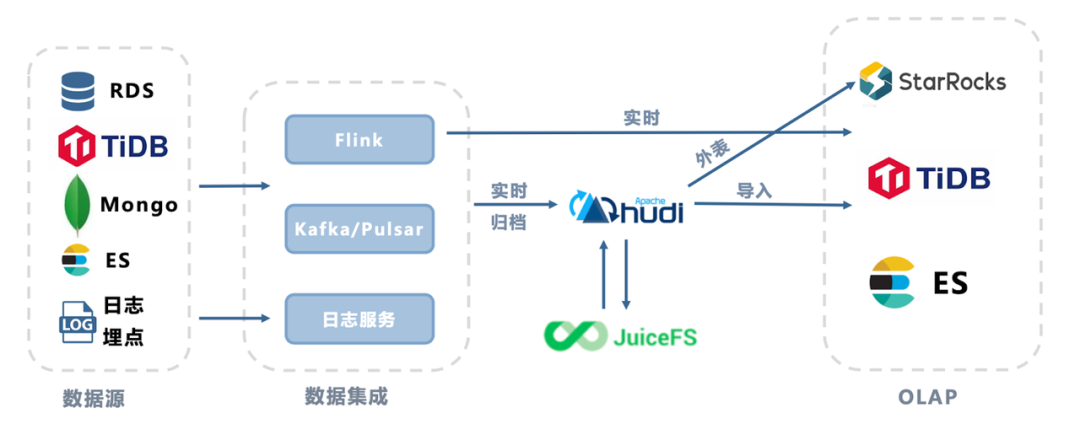
大数据云原生的远期规划
本文转载自聂磊 ApacheHudi,原文链接:https://mp.weixin.qq.com/s/cCUeOff0r5vaHlkiAegNwQ。