
本文为字节跳动基于数据湖技术的近实时场景实践,主要包括以下几部分内容:数据湖技术的特性、近实时技术的架构、电商数仓实践、未来的挑战与规划。

 文 | 汶园 来自字节跳动数据平台数据BP团队
文 | 汶园 来自字节跳动数据平台数据BP团队

数据湖技术特性
数据湖概念
字节数据湖
-
Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。
-
Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS)
-
Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。
-
Hudi 支持 Merge on Read / Copy on Write 两种表类型,以及Read Optimized / Real Time 两种Query模式,用户可以在海量的低加工的数据之上,根据实际需求,在 “数据可见实时性“和 “数据查询实时性” 上做出灵活的选择。
(其中,Read Optimized Query 是 面向 数据可见实时性 需求的;Real Time Query 是面向数据查询实时性 需求的)
业界目前有多套开源的数据湖的实现方案,字节数据湖是基于 Apache Hudi 深度定制,适用于商用生产的数据湖存储方案,其特性如下:
-
字节数据湖为打通实时计算与离线计算 ,及实时数据、离线数据共通复用提供了桥梁。Hudi的开源实现支持多种引擎,在字节跳动的实现中,集成了Flink、Spark、Presto,同时支持streaming和batch计算。
-
字节数据湖拥有良好的元数据管理能力,并在此之上实现了索引。使用行、列存储并用的存储格式,为高性能读写提供坚实的基础。
-
字节数据湖新增了多源拼接功能,对于需要融合多种数据源或者构建集市型数据集的场景,多源拼接功能简化了数据操作,使数据集的构建更加简便。
-
字节数据湖支持 read optimize 和 real time两种 query 模式。同时提供 upsert(主键更新)、append(非主键更新)两种数据更新能力,应用扩展性强,对用户使用友好。
近实时技术架构
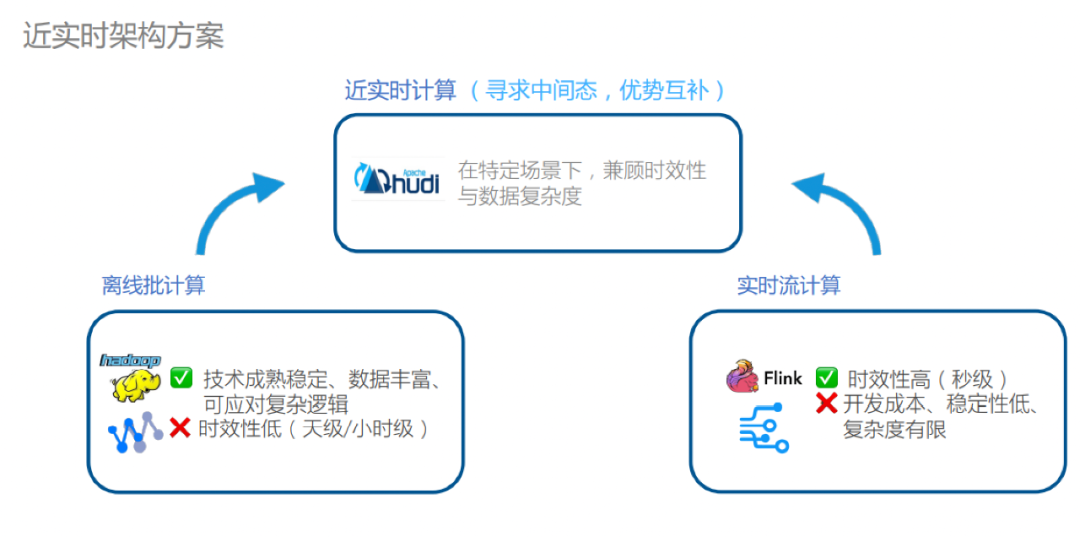
近实时场景特点
-
面向分析型的需求,主要用户为分析师、运营人员或决策层,其特点是需求量大,并且要求数据研发快速响应。从数据内容来讲,分析型需求旺,需要从多视角、多维度进行分析,实验性质比较强,需要在底层加工的时候进行跨数据域的关联。不嵌入到具体的产品功能或者业务流程中,所以对延迟和质量 SLA 的容忍度较高。
-
面向运维型的需求,主要用户是数据研发人员和数据运维人员。这类场景需要成本低廉、操作便捷的存储来提高研发和运维的效率。
数据湖技术适用性
-
复用流批的结果: -
对于流式计算来说,可以利用批式计算的结果解决历史累积结果、数据冷启动、数据回溯等问题。 -
对于批计算来说,通过将次日凌晨大数据量的批式计算,转换为复用用流计算当日更新增量的结果, 从而提高离线数据的产出时效性 。降低数据基线破线的风险。
-
统一存储:字节数据湖采用HDFS作为底层存储层,通过将ods、dwd这类偏上游的数仓层次的数据入湖,并将加工dws、app层的计算放在湖内, 从而把实时计算的“中间数据”、“结果数据”都落入数据湖中,实现了与基于hive存储的离线数据 在 存储上的统一。
-
简化计算链路:利用了数据湖多元拼接的功能,减少join操作,解决多数据源的融合问题,简化数据链路。也可以通过将离线维表导入到近实时计算中,复用离线计算的结果,从而简化链路。
近实时架构方案
近实时架构方案演进
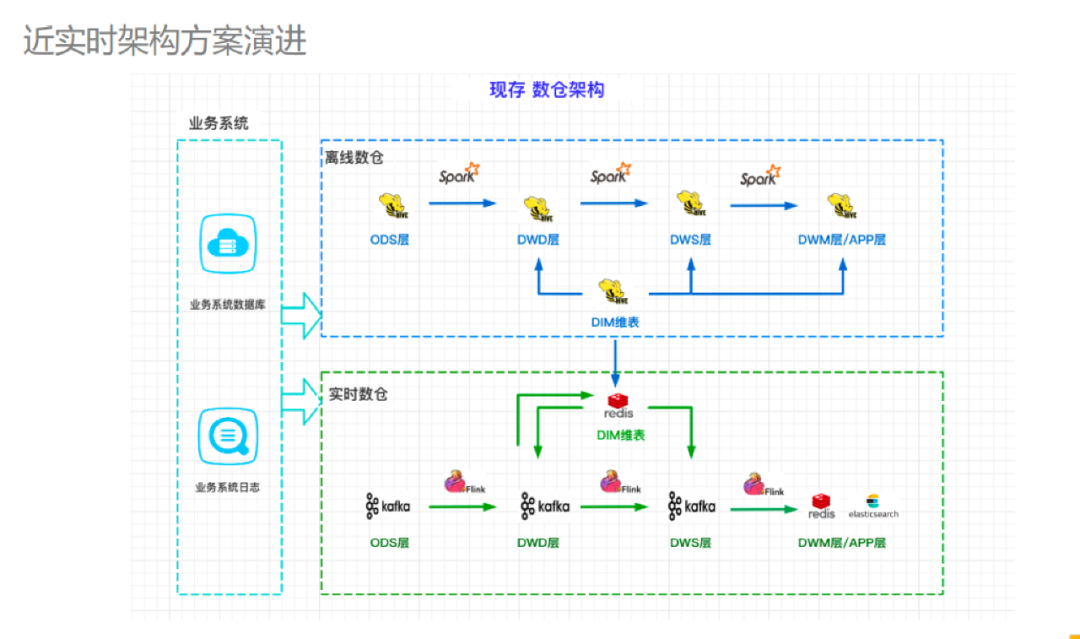

传统离线数仓中的 DWD 层通常不面向应用,这点和基于数据湖的架构是有所区别的。数据湖的思想是 schema-on-read,希望尽量把更多原始的信息开放给用户,不进行过度的加工,从图中大家也可以看到,数据湖中的DWD 层是面向 Presto 查询,提供给用户构建数据看板或分析报表,也可以经过更深度的加工后提供给用户。
电商数仓实践
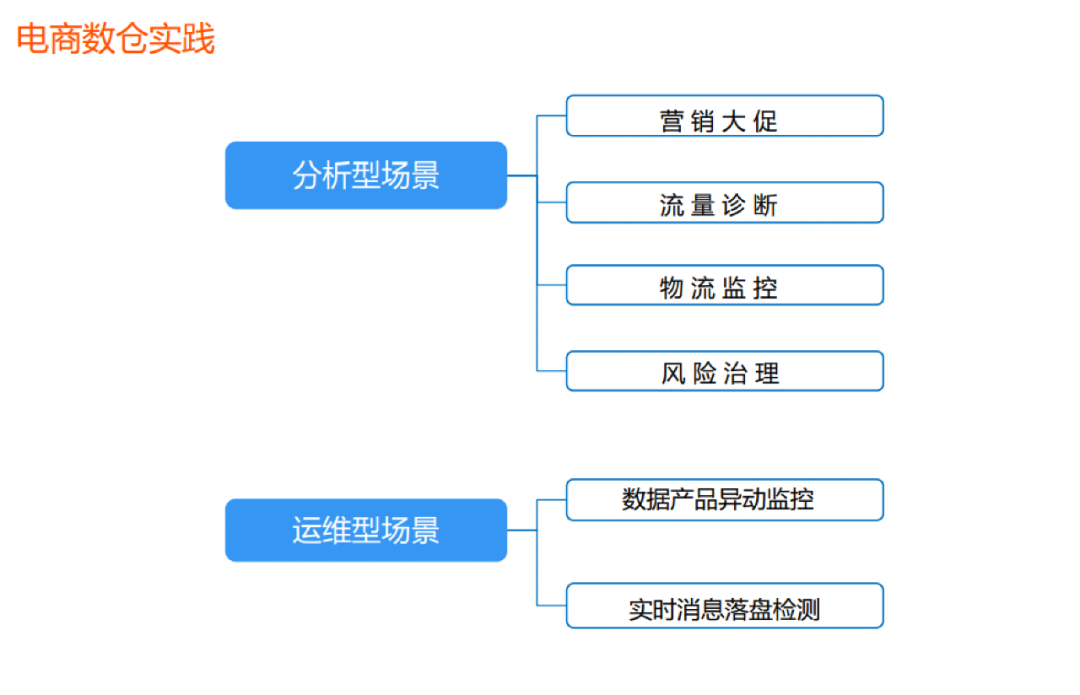
分析型场景实践
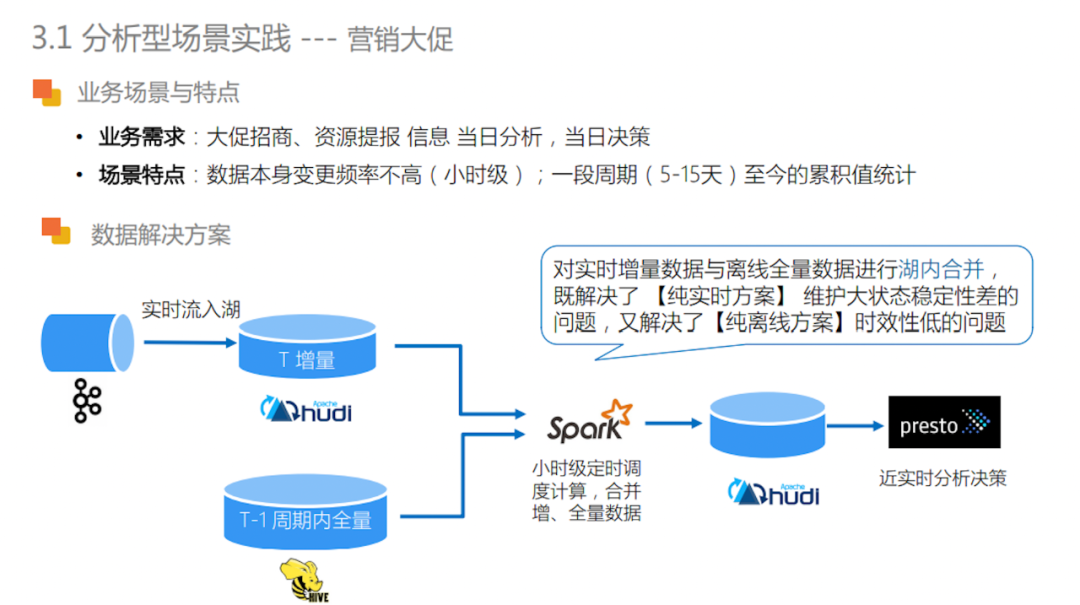
营销大促
对于618、双11等购物节日,平台需要提前进行大促招商和资源提报,业务有当日分析和当日决策的需求。营销大场景的特点是数据本身变更频率不高(小时级),但是需要支持一段周期(5-15天) 至今的累积值统计 。之前的纯离线方案,是每小时对 T – 1的数据进行全量计算,下游使用Presto 分析。这种方案的缺点是数据的时效性差,且往往小时级任务难以保证一小时内产出数据结果。
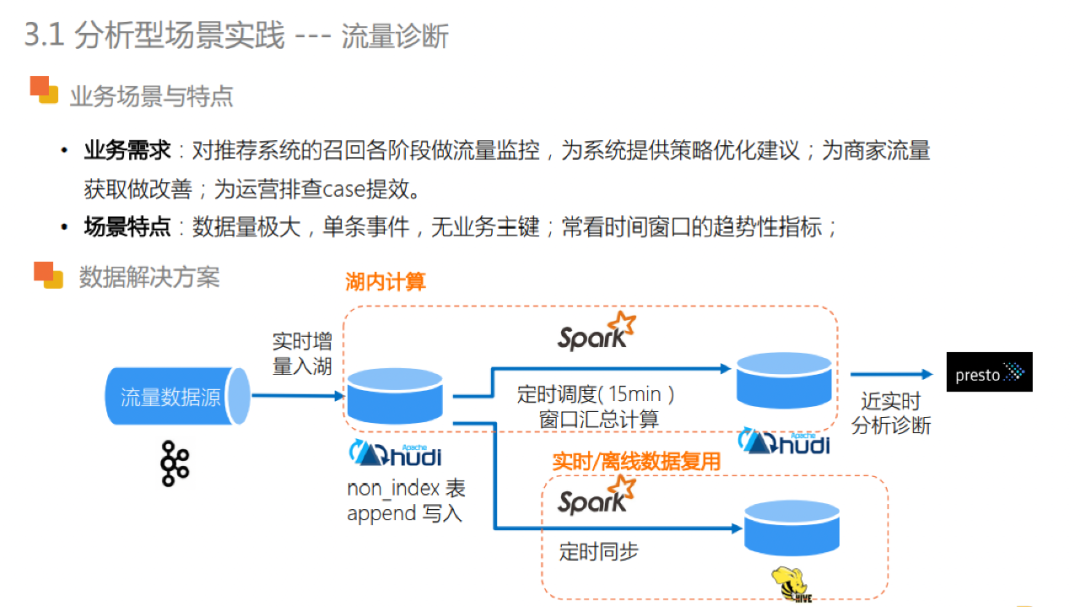
流量诊断
流量诊断这类场景是对推荐系统召回的各阶段流量进行实时监控分析,从而为推荐系统提供策略优化建议。同时,也能够改善商家的流量获取、为运营同学排查 case 提效。
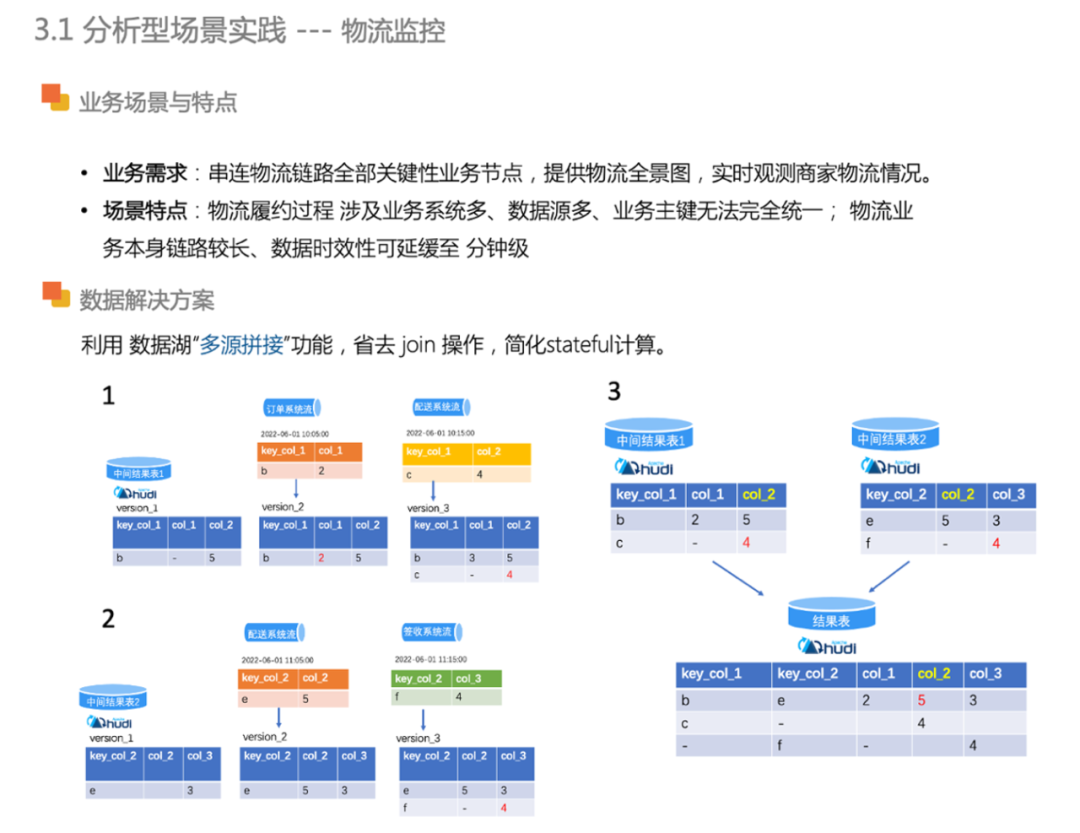
物流监控
风险治理

风险治理是电商交易业务中不可或缺的环节。风险治理通过会话、举报、评论、交易等多业务视角去近实时地分析,预判出商家的欺诈行为,或者识别黑灰产业、资金资损的风险事件。这类需求的特点是:对于实时性要求不高(业务变化15 分钟可见),但是需要支持灵活的自主查询,来满足下游报表、看板,数据集等多样的需求。
其次,风险治理需要关联多个数据域,进行整体的风险排查。比如推断疑似黑灰产商家,需要查验资质信息、举报信息或者交易的信息。在分析的过程中,需要关联很多离线维表来获取商家的资质、等级、评分等信息,再做最终的预判。这类需求特点和近实时分析所支持的场景是相吻合的。因此,可采用基于数据湖的解决方案,利用数据湖的海量低加工的数据处理特性,将多数据源实时增量入库,避免过多的 join 或者是汇总计算,同时又把离线的表去做复用。整体直接面向查询引擎,由用户去决定在查询分析时候的 schema ,也就是转化为 schema on read 的模式。
运维型场景实践
该类场景面向的用户主要是:数据研发人员、数据运维人员。
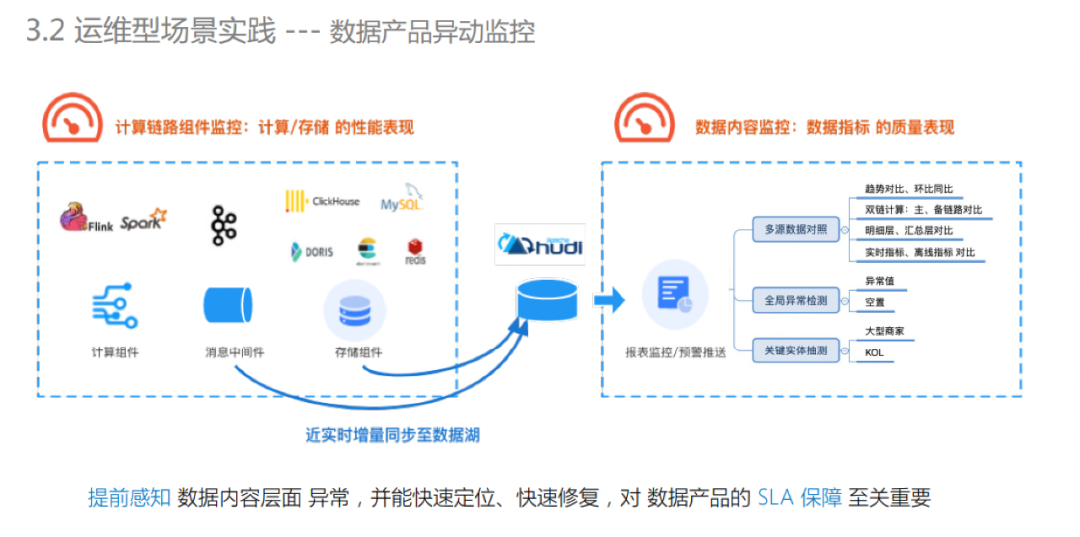
数据产品异动监控
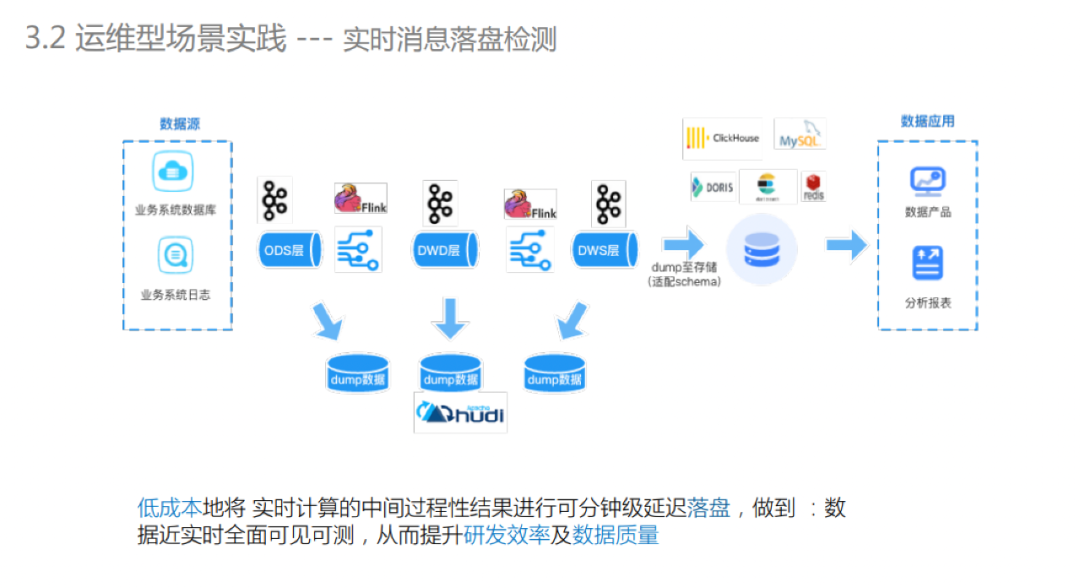
实时消息落盘检测
下图是大家比较熟悉的实时数据链路,和离线链路最大的不同之处在于中间的计算结果都是基于消息队列存储,不支持数据的全局观测和整体数据校验。
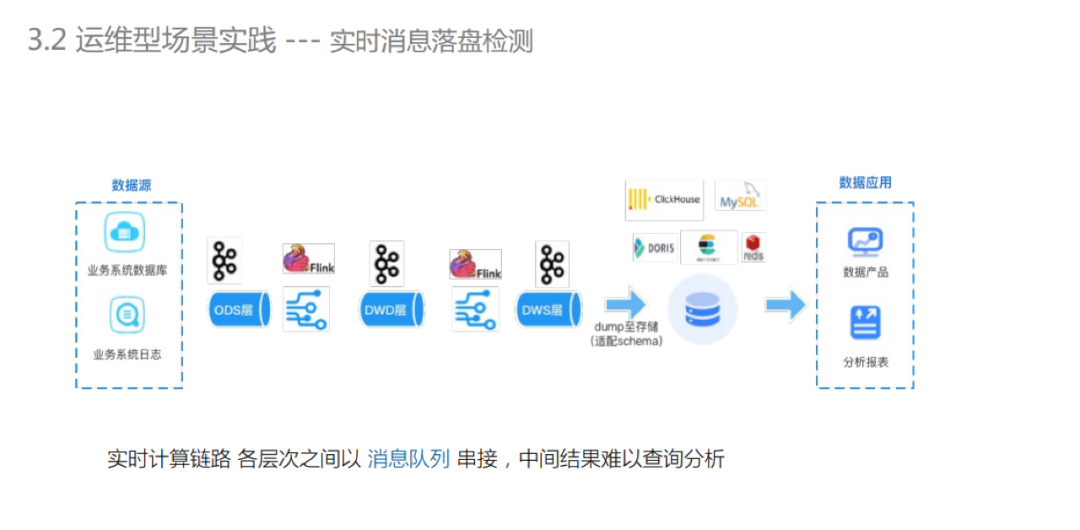
通过CDC将消息队列里的数据落盘到数据湖中,实现中间数据的全面可见、可测,对于提高数据研发同学的效率和数据质量有很大帮助。
未来挑战与规划
随着在抖音电商场景的落地,数据湖技术在近实时场景支持业务的可行性得到了验证。最后从数据研发的角度,讲一下数据湖未来的挑战和规划。
-
为了今后接入更多、更大数据量的业务,对数据湖性能提出了更高的要求。对于实时数仓来说,主要是数据可见性提升和数据查询RT的提升。 -
和 Flink、Spark 更深度集成,例如在 failover 阶段提供更强的稳定性保障。 -
在良好的读写性能、稳定性保障的基础上,由近实时分析型应用转向近实时产品型应用。
本文转载自马汶园 字节跳动数据平台,原文链接:https://mp.weixin.qq.com/s/q12CVO32r2OC0lUVZ2fUzg。