


1.概述
2.数仓的基本建设目标
3.业界数仓建设分析
◆3.1 数仓理论发展
◆3.2 数仓架构历程

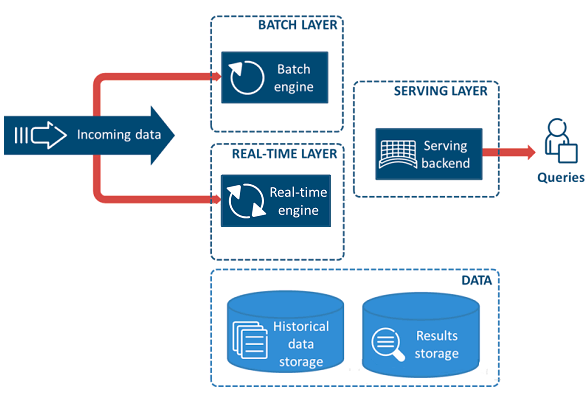

◆3.3 常见互联网数仓架构
3.3.1 美团数仓架构图

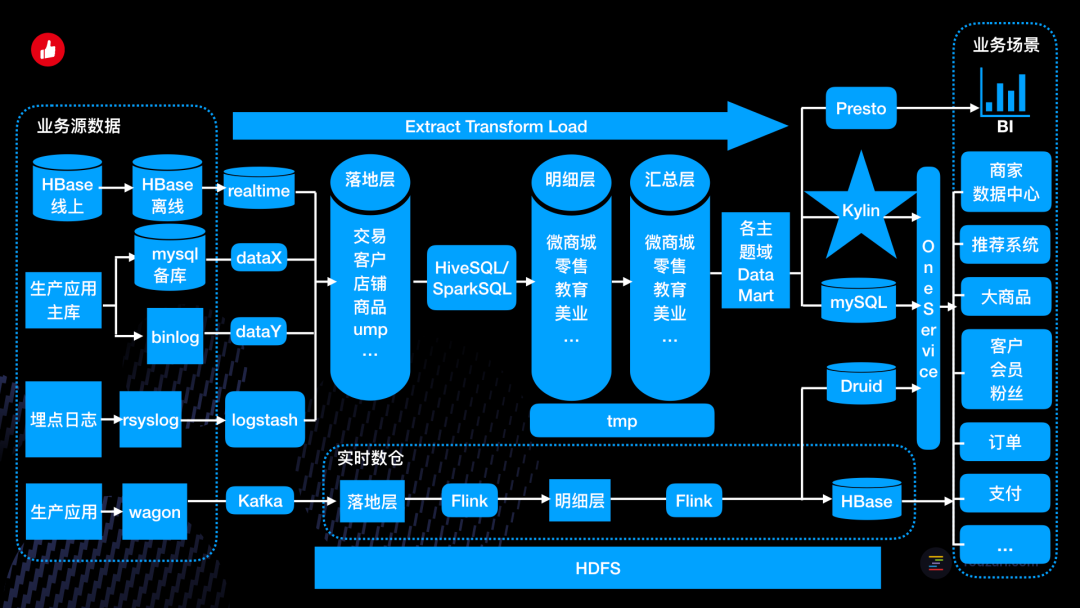
3.3.2 有赞数仓架构图
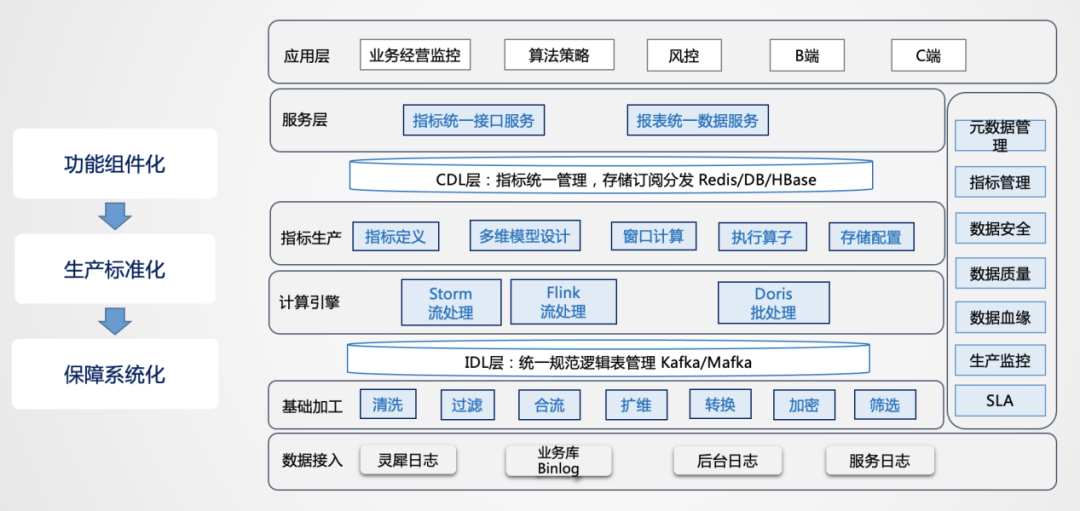
4.兴盛优选数仓架构&建设实践
◆4.1 基于数据湖的Lambda架构
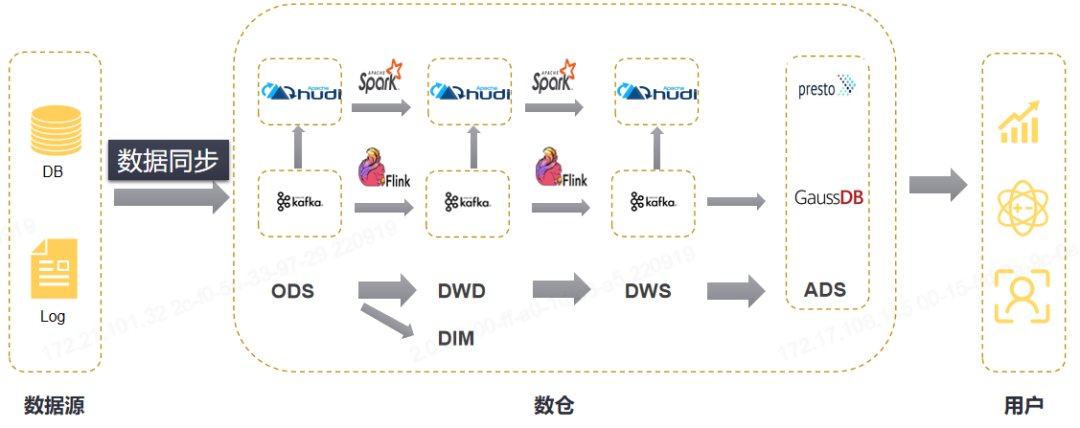
◆4.2 模型架构
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
◆4.3 数仓建设实践
4.3.1 数据接入
4.3.2 数据标准

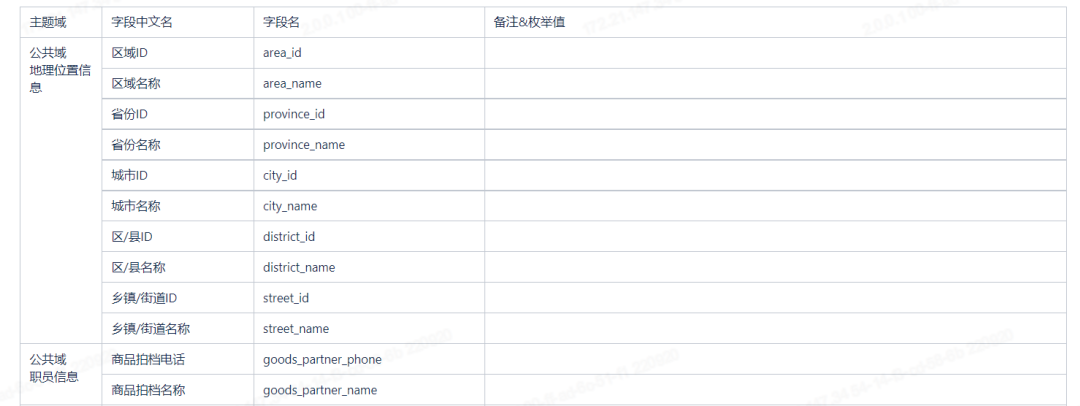
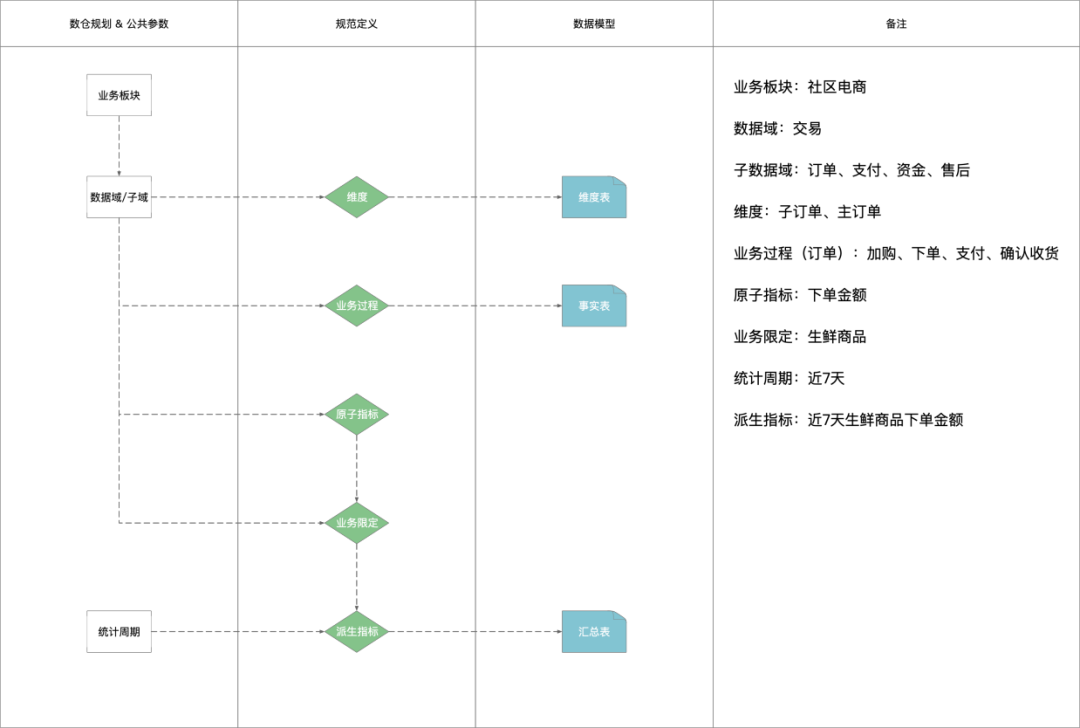
4.3.3 数据模型
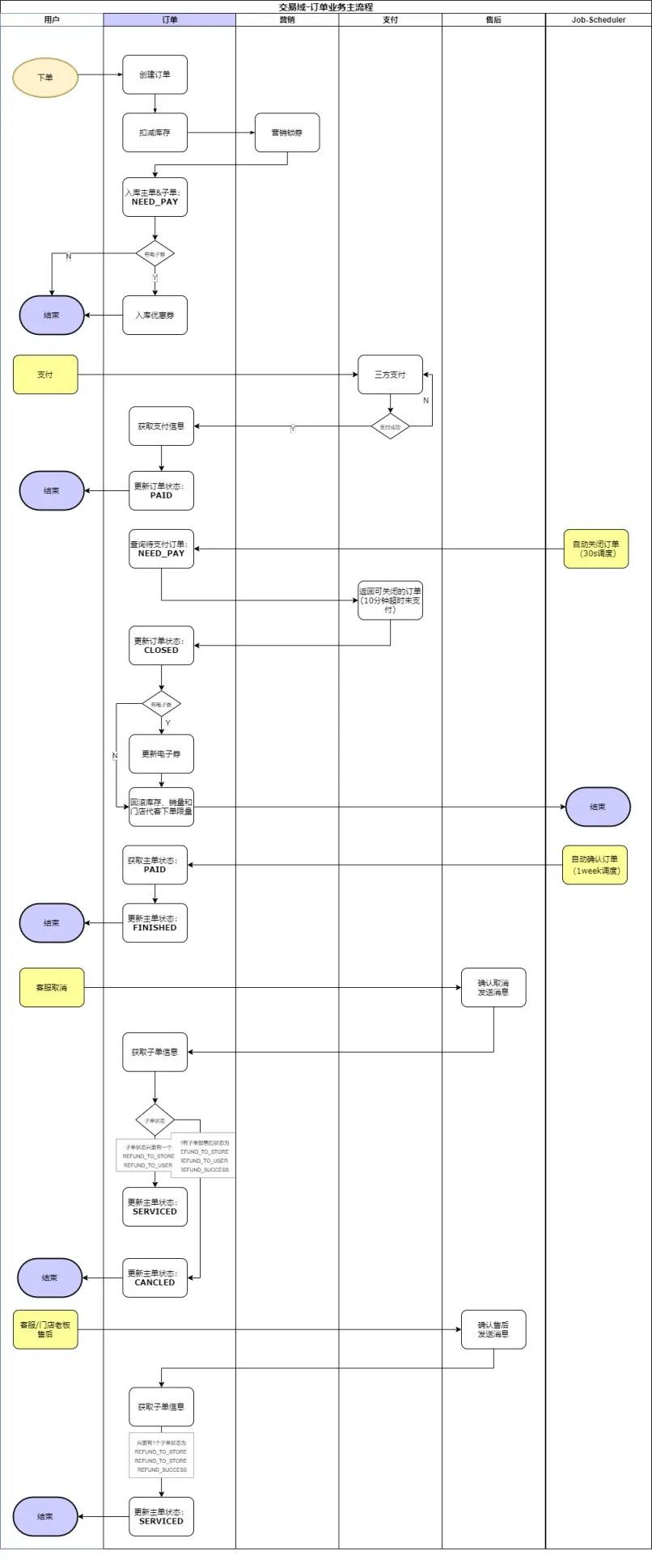
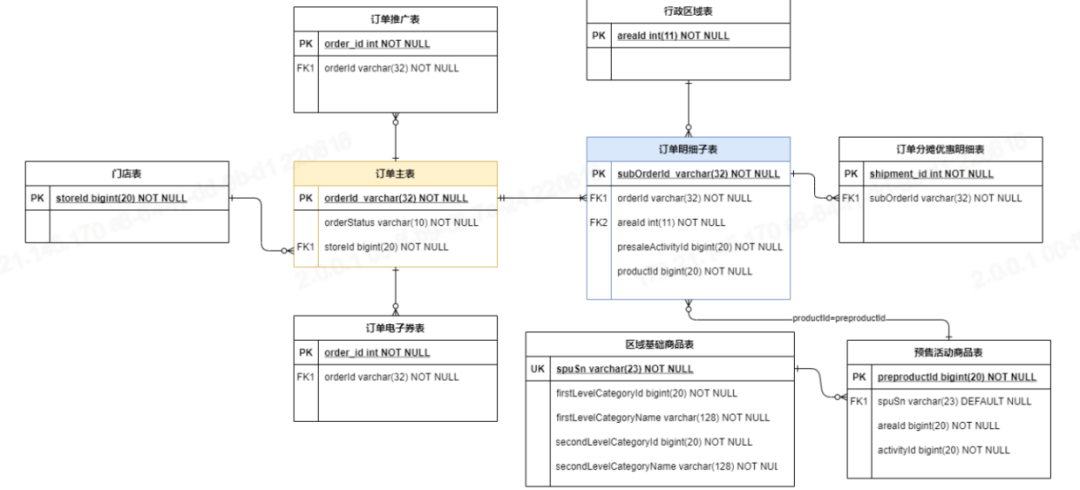
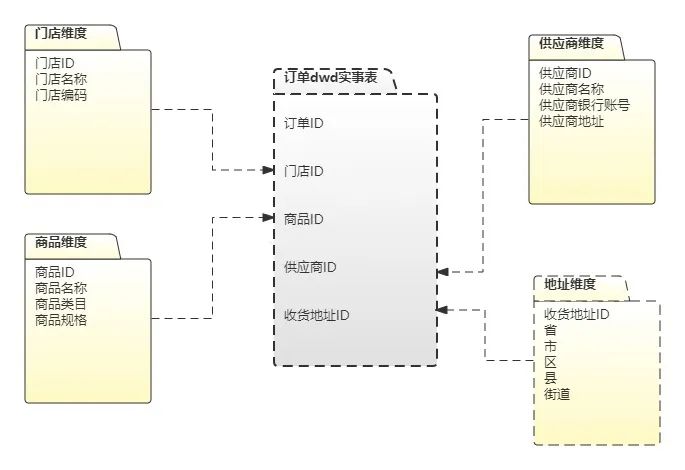
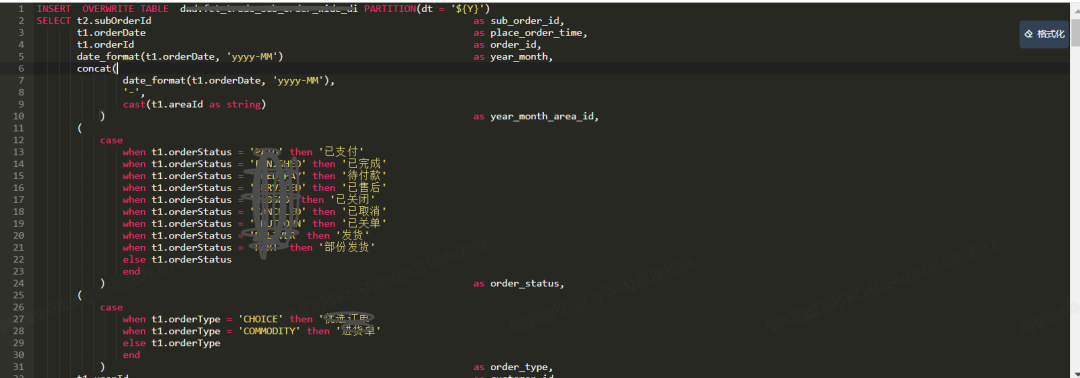
4.3.4 数据质量
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.3.5 数据服务
5.总结
本文转载自兴盛优选技术社区,原文链接:https://mp.weixin.qq.com/s/InyyeMK_pkr1ngHiKKXxwQ。