
K8s 的 cpuManager 完成节点侧的 CPU 资源分配和隔离(core pinning and isolation,如何做到隔离)。

-
发现机器上的 CPU 拓扑 -
上报给 K8s 层机器的可用资源(包含 kubelet 侧的调度) -
分配资源供 workload 执行 -
追踪 pod 的资源分配情况
本文大致介绍 K8s 中 CPU 管理的现状与限制,结合社区文档分析当前社区动态。
CPU 管理的现状与限制
kubelet 将系统的 CPU 分为 2 个资源池:
-
独占池(exclusive pool):同时只有一个任务能够分配到 CPU -
共享池(shared pool):多个进程分配到 CPU
原生的 K8s cpuManager 目前只提供静态的 CPU 分配策略。当 K8s 创建一个 pod 后,pod 会被分类为一个 QoS:
-
Guaranteed -
Burstable -
BestEffort
并且 kubelet 允许管理员通过 –reserved-cpus 指定保留的 CPU 提供给系统进程或者 kube 守护进程(kubelet, npd)。保留的这部分资源主要提供给系统进程使用。可以作为共享池分配给非 Guaranteed 的 pod 容器。但是 Guaranteed 类 pod 无法分配这些 cpus。
目前 K8s 的节点侧依据 cpuManager 的分配策略来分配 numa node 的 cpuset,能够做到:
-
容器被分配到一个 numa node 上。 -
容器被分配到一组共享的 numa node 上。
cpuManager 当前的限制:
-
最大 numa node 数不能大于 8,防止状态爆炸(state explosion)。 -
策略只支持静态分配 cpuset,未来会支持在容器生命周期内动态调整 cpuset。 -
调度器不感知节点上的拓扑信息。下文会介绍相应的提案。 -
对于线程布局(thread placement)的应用,防止物理核的共享和邻居干扰。CPU manager 当前不支持。下文有介绍相应的提案。
相关 issues
1、针对处理器的异构特征,用户可以指定服务所需要的硬件类别[1]。
异构计算的异构资源有着不同额性能和特征和多级。比如 Intel 11th gen,性能内核(Performance-cores, P-cores)是高性能内核,效率内核(Efficiency-cores,)是性能功耗比更优的内核。
ref:https://www.intel.cn/content/www/cn/zh/gaming/resources/how-hybrid-design-works.html
这个 issue 描述的用户场景是,可以将 E-cores 分配给守护进程或者后台任务,将 P-cores 分配给性能要求更高的应用服务。支持这种场景需要对 CPU 进行分组分配。但是 issue 具体的方案讨论。因为底层硬件差异,目前无法做到通用。目前 K8s 层需要设计重构方案。
当前相关需求的落地方案都是在 K8s 上使用扩展资源的方式来标识不同的异构资源。这种方法会产生对于原生 CPU/ 内存资源的重复统计。
2、topologyManager 的 best-effort 策略优化[2]。
issue 提到 best-effort 的策略,迭代每个 provider hint,依据位与运算聚合结果。如果最后的结果为 not preferred,topologyManager 应该尽力依据资源的倾向做到 preferred 的选择。这个想法的初衷是因为 CPU 资源相比其他外设的 numa 亲和更重要。当多个 provider hint 相互冲突时,如果 CPU 有 preferred 的单 numa node 分配结果,应该先满足 CPU 的分配结果。比如 CPU 返回的结果为 [‘10’ preferred, ‘11’ non-preferred]),一个设备返回的结果 [‘01’, preferred]。topologyManager 应该使用 ’10’ preferred 作为最后的结果,而不是合并之后的 ’01’ not preferred。
而社区对于这种的调度逻辑的改变,建议是创建新的 policy 以提供类似调度器优选(scoring)的算法系统。
3、严格的 kubelet 预留资源[3]。
希望提供新的参数 StrictCPUReservation,表示严格的预留资源,DefaultCPUSet 列表会移除 ReservedSystemCPUs.
4、bug:释放 init container 的资源时,释放了重新分配给 main container 的资源[4]。
这个 issue 已经修复:在 RemoveContainer 阶段,排除还在使用的容器的 cpuset。剩下的 cpuset 才可以释放回 DefaultCPUSet。
5、支持原地垂直扩展:针对已经部署到节点的 pod 实例,通过 resize 请求,修改 pod 的资源量[5]。
原地垂直扩展的意思是:当业务调整服务的资源时,不需要重启容器。
原地垂直扩容是个复杂的功能,这里大致介绍设计思路。详细实现可以看 PR: https://github.com/kubernetes/kubernetes/pull/102884。
kube-scheduler 依然使用 pod 的 Spec…Resources.Requests 来进行调度。依据 pod 的 Status.Resize 状态,判断缓存中 node 已经分配的资源量。
-
Status.Resize = “InProgress” or “Infeasible”,依据 Status…ResourcesAllocated(已经分配的值)统计资源量。 -
Status.Resize = “Proposed”,依据 Spec…Resources.Requests(新修改的值) 和 Status…ResourcesAllocated(已经分配的值,如果 resize 合适,kubelet 也会将新 requests 更新这个属性),取两者的最大值。
kubelet 侧的核心在 admit 阶段来判断剩余资源是否满足 resize。而具体 resize 是否需要容器重启,需要依据 container runtime 来判断。所以这个 resize 功能其实是尽力型。通过 ResizePolicy 字段来判断:

还值得注意点是当前 PR 主要是在 kata、docker 上支持原地重启,windows 容器还未支持。
有趣的社区提案
调度器拓扑感知调度
Redhat 将他们实现的一套拓扑调度[6]的方案贡献到社区:https://github.com/kubernetes/enhancements/pull/2787
扩展 cpuManager 防止理核不在容器间共享:
kep:https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2625-cpumanager-policies-thread-placement
防止同一个物理核的虚拟分配带来的干扰。
设计文档里引入新参数 cpumanager-policy-options:full-pcpus-only,期望分配独占一个物理 CPU。当指定了 full-pcpus-only 参数以及 static 策略时,cpuManager 会在分配 cpusets 会额外检查,确保分配 CPU 的时候是分配整个物理核。从而确保容器在物理核上的竞争。
具体例子比如,一个容器申请了 5 个独占核(虚拟核),CPU 0-4 都分配个了服务容器。CPU 5 也被锁住不能再分配给容器。因为 CPU 5 和 CPU 4 同在一个物理核上。

增加 cpuMananger 跨 numa 分散策略:distribute-cpus-across-numa[7]
-
full-pcpus-only:上面已经描述:full-pcpus-only确保容器分配的 CPU 物理核独占 。 -
distribute-cpus-across-numa:跨 numa node 均匀分配容器。
开启 distribute-cpus-across-numa 时,当容器需要分配跨 numa node 时,statie policy 会跨 numa node 平均分配 CPU。非开启的默认逻辑是优选填满一个 numa node。防止跨 numa node 分配时,在一个余量最小的 numa node 上分配。从整个应用性能考虑,性能瓶颈收到落在剩余资源较少的 numa node 上性能最差的 worker(process?)。这个选项能够提供整体性能。
接下来介绍几个社区 slack 里讨论的几个提案:
-
CPU Manager Plugin Model -
Node Resource Interface -
Dynamic resource allocation
CPU Manager Plugin Model
CPU Manager Plugin Model:kubelet cpuManager 的插件框架。在不改动资源管理主流程前提下,支持不同的 CPU 分配场景。依据业务需求,实现更细粒度的控制 cpuset。
kubelet 在 pod 绑定成功之后,会将 pod 压入本地调度队列里,依次执行 pod 的 cpuset 的调度流程。调度流程本质上借鉴了 kube-scheduler 的调度框架。
插件可扩展点:
一个插件可以实现 1 个或多个可扩展点:
-
Sort:将调度到节点上的 pod 排序处理。例如依据 pod QoS 判定的优先顺序。 -
Filter:过滤无法分配给 pod 的 CPU。 -
PostFilter:当没有合适的 CPU 时,可以通过 PostFilter 进行预处理,然后将 pod 重新进行处理。 -
PreScore:对于单个 CPU 评分,提供给后面流程来判定分配组合的优先级。 -
Select:依据 PreScore 的结果选择一个 CPU 组合的最优解,最优解的结构是一组 CPU。 -
Score:依据 Select 的结果——CPU 分配组合评分。 -
Allocate:在分配 cpuset 之后,调用该插件。 -
Deallocate:在 PostFilter 之后,释放 CPU 的分配。
三个评分插件的区别:
-
PreScore:返回以 CPU 为 key,value 为单个 CPU 对于 pod 容器的亲和程度。 -
Select:依据插件的领域知识(比如同一个 numa 的 CPU 分配结构聚合),将 CPU 组合的分数聚合。返回是一组最佳 CPU。 -
Score:依据所有的 CPU 组合,评分分配组合依据插件强约束逻辑。
方案提出了两种扩展插件的方案。当前在 kubelet 的容器管理中,topologyManager 主要完成下列事项:
-
调度用 hintProvider,获得各个子管理域的可分配情况 -
编排整体的拓扑分配决策 -
提供“scopes”和 policies 参数来影响整体策略
其他子管理域的子 manager(如 cpuManager)作为 hintProvider 提供单个分配策略。在 CPU Manager Plugin Model 中,子 manager 作为模型插件接口提供原有功能。
方案 1:扩展子 manager,让 topologyManager 感知 cpuset
通过当前的值回去 numa node 的分配扩展到能够针对单个 cpuset 的分配倾向。扩展插件以 hint providers 的形式执行,主流程不需要修改。
缺点:其他 hintProvider(其他资源的分配)并不感知 CPU 信息,导致 hintProvider 的结果未参考 CPU 分配。最终聚合的结果不一定是最优解。
方案 2:扩展 cpuManager 为插件模型
topologyManager 依然通过 GetTopologyHints() 和 Allocate() 调用 cpuManager,cpuManager 内部进行扩展调度流程。具体的扩展方式可以通过引入新的 policy 配置,或者通过调度框架的方式直接扩展。
缺点:cpuManager 的结果并不决定性的,topologyManager 会结合其他 hints 来分配。
可以看到 CPU Manager Plugin Model 当前提案还出于非常原始的阶段,主要是 Red Hat 的人在推。并未在社区充分讨论。
Node Resource Interface
该方案来自 containerd。主要是在 CRI 中扩展 NRI 插件。
containerd
containerd 主要工作在平台和更底层的 runtime 之间。平台是指 docker、k8s 这类容器平台,runtime 是指 runc, kata 等更底层的运行时。containerd 在中间提供容器进程的管理,镜像的管理,文件系统快照以及元数据和依赖管理。下图是 containerd 架构总览图:
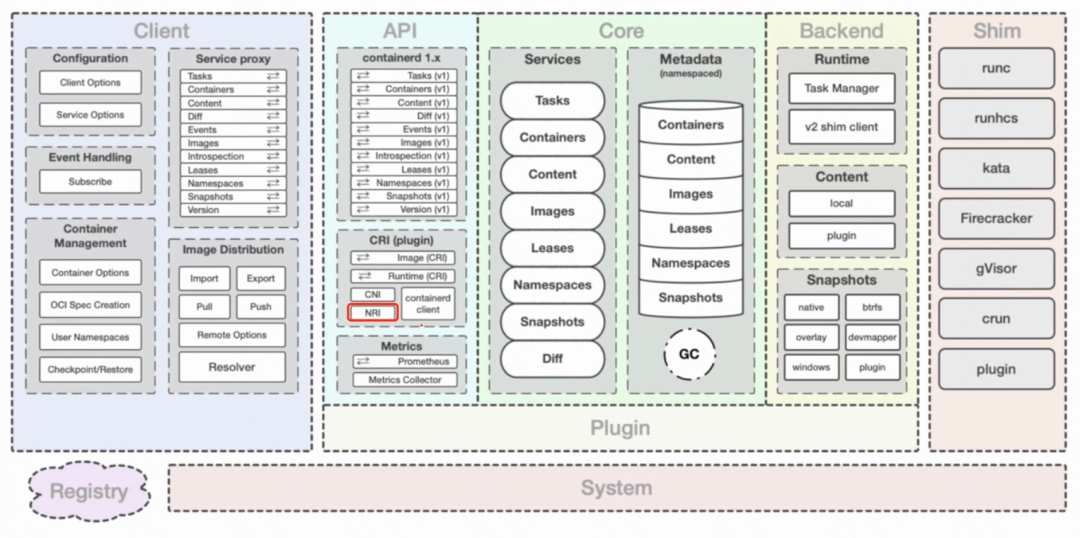
-
client 是用户交互的第一层,提供接口给调用方。 -
core 定义了核心功能接口。所有的数据都通过 core 管理存储(metadata store),所有其他组件 / 插件不需要存储数据。 -
backend 中的 runtime 负责通过不同 shim 与底层 runtime 打交道。 -
api 层主要提供两大类 gRPC 服务:image,runtime。提供了多种插件扩展。
在 CRI 这一层,包含了 CRI、CNI、NRI 类型的插件接口:

-
CRI plugin:容器运行时接口插件,通过共享 namespace、cgroups 给 pod 下所有的容器,负责定义 pod。 -
CNI plugin:容器网络接口插件,配置容器网络。当 containerd 创建第一个容器之后,通过 namespace 配置网络。 -
NRI plugin:节点资源接口插件,管理 cgroups 和拓扑。
NRI
NRI 位于 containerd 架构中的 CRI 插件,提供一个在容器运行时级别来管理节点资源的插件框架。
cni 可以用来解决批量计算,延迟敏感性服务的性能问题,以及满足服务 SLA/SLO、优先级等用户需求。例如性能需求通过将容器的 CPU 分配同一个 numa node,来保证 numa 内的内存调用。当然除了 numa,还有 CPU、L3 cache 等资源拓扑亲和性。
当前 kubelet 的实现是通过 cpuManager 的处理对象只能是 guaranteed 类的 pod, topologyManager 通过 cpuManager 提供的 hints 实现资源分配。
kubelet 当前也不适合处理多种需求的扩展,因为在 kubelet 增加细粒度的资源分配会导致 kubelet 和 CRI 的界限越来越模糊。而上述 CRI 内的插件,则是在 CRI 容器生命周期期间调用,适合做 resoruce pinning 和节点的拓扑的感知。并且在 CRI 内部做插件定义和迭代,可以做到上层 kubernetes 以最小代价来适配变化。
在容器生命周期中,CNI/NRI 插件能够注入到容器初始化进程的 Create 和 Start 之间:
Create->NRI->Start
以官方例子clearcfs[8]:在启动容器前,依据 qos 类型调用 cgroup 命令,cpu.cfs_quota_us 为-1 表示不设上限。
可以分析出 NRI 直接控制 cgroup,所以能有更底层的资源分配方式。不过越接近底层,处理逻辑的复杂度也越高。
Dynamic resource allocation
KEP 里翻到了这个动态资源分配,方案提供了一套新的 K8s 管理资源和设备资源的模型。核心思想和存储类型(storageclass)类似,通过挂载来实现具体设备资源的声明和消费,而不是通过 request/limit 来分配一定数量的设备资源。
用例:
-
设备初始化:为 workload 配置设备。基于容器需求的配置,但是这部分配配置不应该直接暴露给容器。 -
设备清理:容器结束后清理设备参数 / 数据等信息 . -
Partial allocation:支持部分分配,一个设备共享多个容器。 -
optional allocation:支持容器声明软性 (可选的) 资源请求。例如:GPU and crypto-offload engines 设备的应用场景。 -
Over the Fabric devices:支持容器使用网络上的设备资源。
动态资源分配的设计目的是提供更灵活控制、用户友好的 api,资源管理插件化不需要重新构建 K8s 组件。
通过定义动态资源分配的资源分配协议和 gRPC 接口来管理新定义 K8s 资源 ResourceClass 和 ResourceClaim:
-
ResourceClass 指定资源的驱动和驱动参数 -
ResourceClaim 指定业务使用资源的实例
立即分配和延迟分配:
-
立即分配:ResourceClaim 创建时就分配。对于稀缺资源的分配能够有效使用(allocating a resource is expensive)。但是没有保障由于其他资源(CPU,内存)导致节点无法调度。 -
延迟分配:调度成功才分配。能够处理立即分配带来的问题。
调用流程
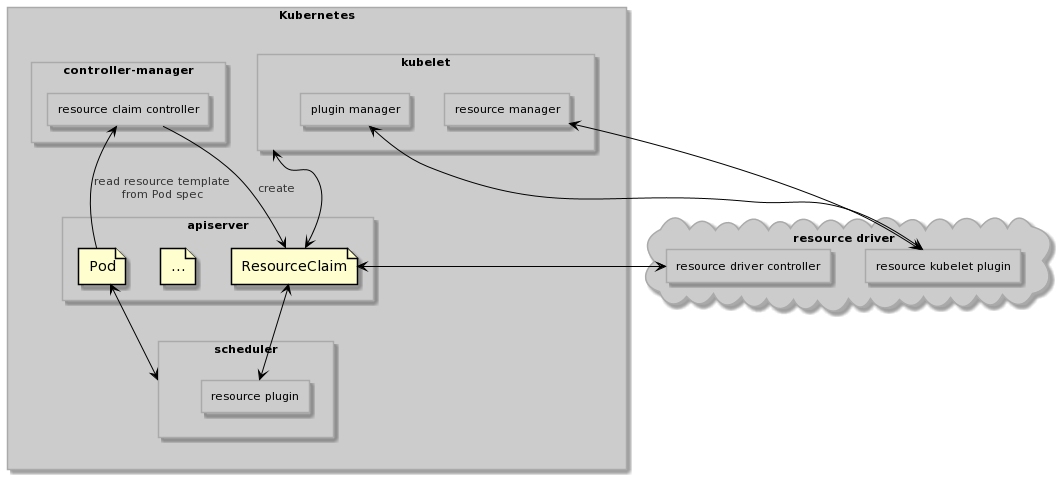
-
用户创建 带有 resourceClaimTemplate 配置的 pod。 -
资源声明 controller 创建 resourceClaim。 -
依据 resourceClaim 的 spec 中,立即分配(immediate allocation)和延迟分配(delayed allocation)处理。 -
立即分配:资源驱动 controller 发现 resourceClaim 的创建时并 claim。 -
延迟分配:调度器首先处理,过滤不满足条件的节点,获得候选节点集。资源驱动再过滤一次候选节点集不符合要求的节点。 -
当资源驱动完成资源分配之后,调度器预留资源并绑定节点。 -
节点上的 kubelet 负责 pod 的执行和资源管理(调用驱动插件)。 -
当 pod 删除时,kubelet 负责停止 pod 的容器,并回收资源(调用驱动插件)。 -
pod 删除之后,gc 会负责相应的 resourceClaim 删除。
这块文档没有具体描述:在立即分配的场景中,如果没有调度器工作,resoruce driver controller 来节点选择机制是怎么样的。
总 结
可以看到未来社区会对 kubelet 容器管理做一次重构,来支持更复杂的业务场景。近期在 CPU 资源管理上会落地的调度器拓扑感知调度,和定制化的 kubelet CPU 分配策略。在上述的一些 case 中,有发展潜力的是 NRI 方案。
-
支持定制化扩展,kubelet 可以直接载入扩展配置无需修改自身代码。 -
通过与 CRI 交互,kubelet 将部分复杂的 CPU 分配需求下放到 runtime 来处理。

本文转载自Edwardesire,原文链接:https://edwardesire.com/posts/the-trending-of-cpu-management-in-k8s/。