
导读 过去的几年里,随着大数据的进一步发展,现代数据栈的生态愈加丰富完善,而数据湖在这期间几乎已成为现代数据栈的必备品,它的出现大大简化了用户管理数据的难度,让用户更加关心于数据本身,而非组件本身。T3 出行在数据湖基础上,对现代数据栈进行了一些探索,并初步打造了特征平台。在本文中,我将给大家分享下 T3 出行结合公司业务场景,在现代技术栈这方面,做的一些探索于与实践,以及在此基础上打造的特征平台。
主要会围绕下面四点展开:
1. 什么是 Modern Data Stack
2. T3 出行的业务场景
3. T3 出行 MDS 的初步打造
4. 特征平台 On MDS
分享嘉宾|李心恺 T3出行 大数据高级工程师
编辑整理|明丘 某新势力自动驾驶大数据团队
出品社区|DataFun
什么是 Modern Data Stack
1. Modern Data Stack 的特点


2. 为什么要有 Modern Data
Stack
3. Modern Data Stack 组成
02
T3 出行的业务场景
1. 支付长尾

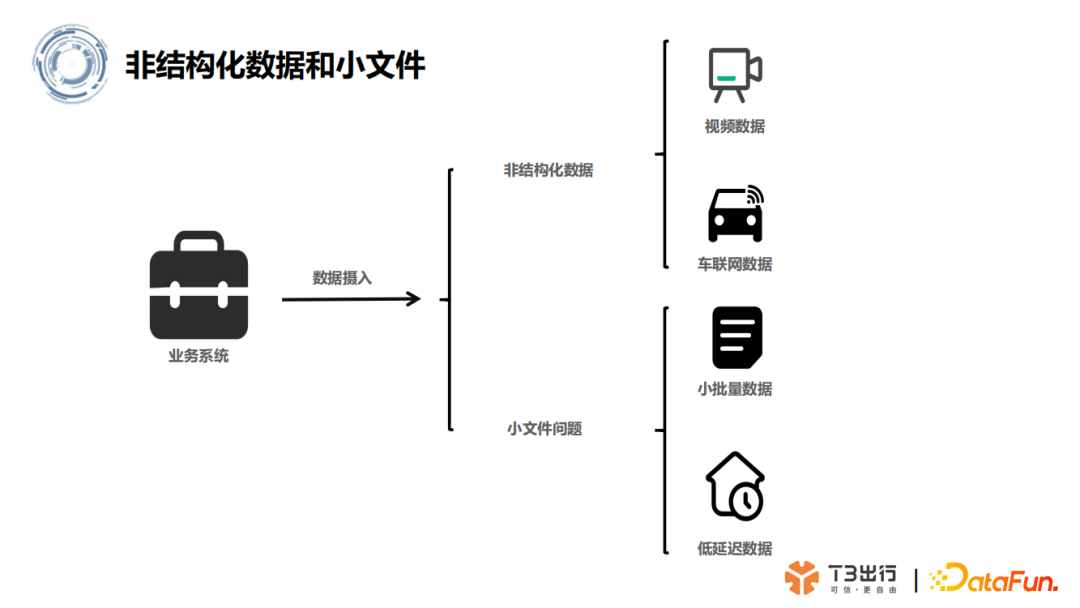
2. 非结构化数据和大量小文件
3. 算法业务场景

03
T3 出行的 MDS 初步打造
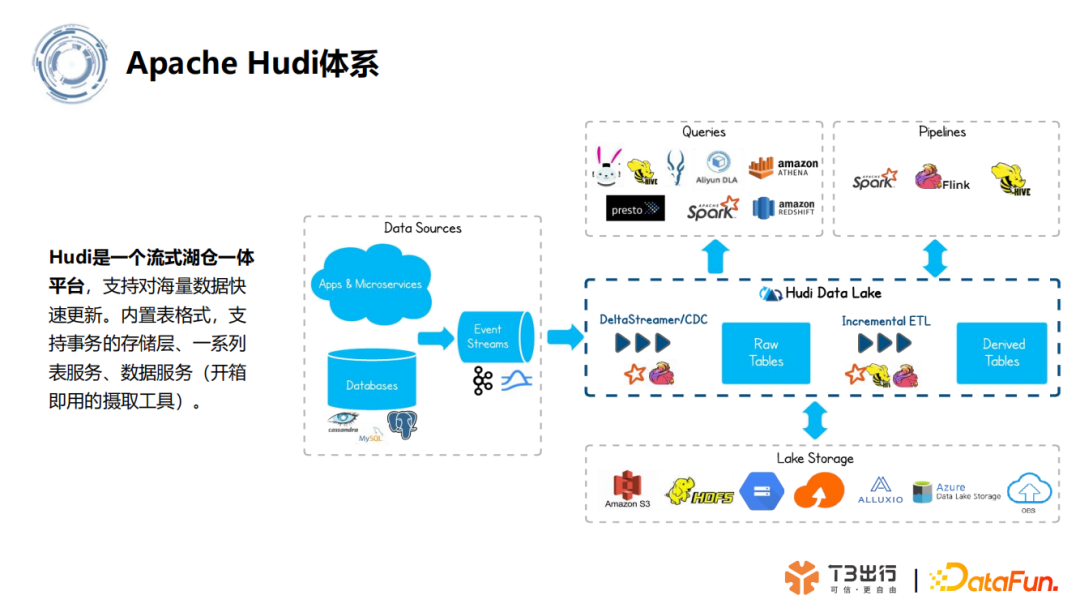
1. Apache Hudi 体系
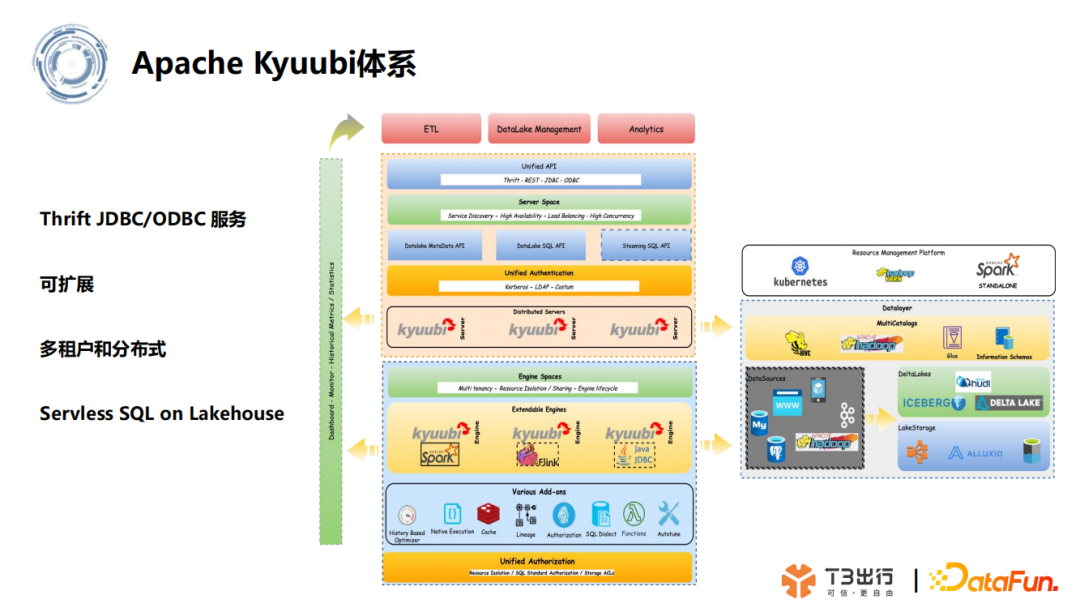
2. Apache Kyuubi 体系
JDBC/ODBC 服务,由网易数帆发起,具备多租户和分布式等特性,为大数据查询引擎如 Spark、Flink 等提供 SQL 等查询服务。它最早是对 Spark Thrift Server 做加强,弥补了 Spark Thrift Server 多租户授权、高可用性特性的缺失,并在此基础上做了相关的拓展。后续 Kyuubi 开始演化精进,向统一网关的场景发展,以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。
-
在开源的版本基础上做了些拓展功能,添加了监控管理页面。 -
最新的开源版本 Kyuubi 除去支持 Spark,还支持了 Doris 、Trino、Presto 以及 Flink,公司会更新使用版本,引入新特性。 -
监控和配置进行持久化存储,引擎配置可以在线更新。 -
在 Kyuubi 引擎管理的基础上,加强一些更细粒度的管理,如用户的流量管控、查询频次等,希望基于这个统一网关做更多的拓展。
3. T3 数据分析处理流程
(1)数据分析流程
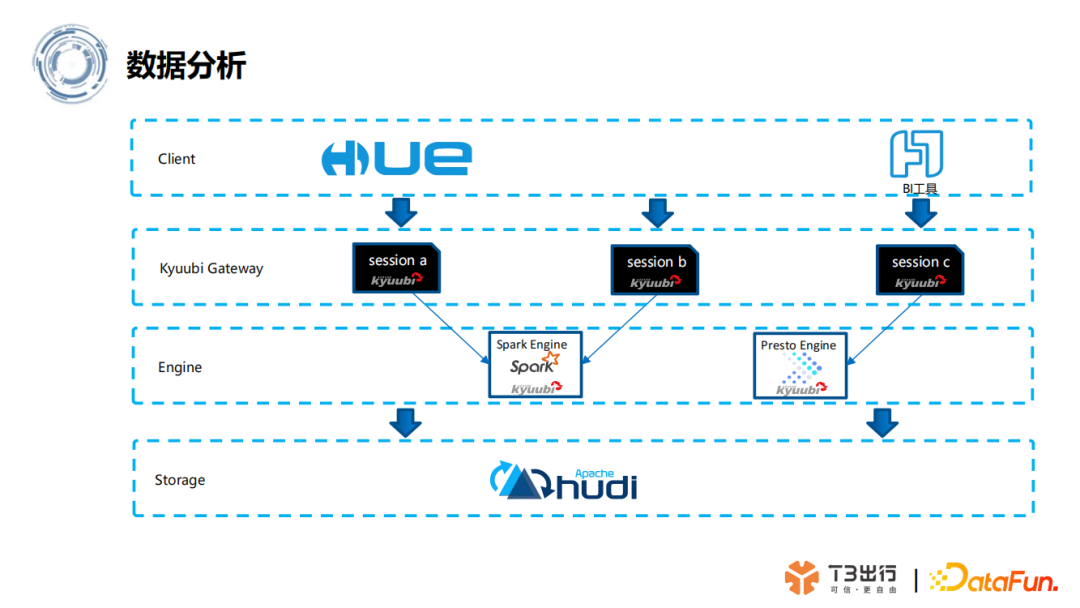
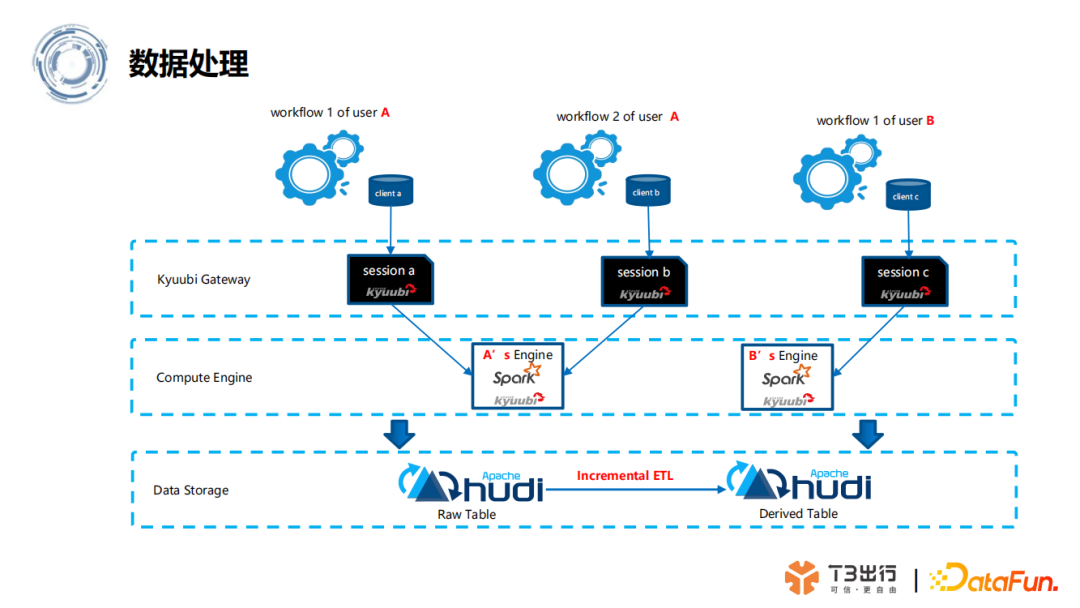
(2)数据处理流程
schedule 多租户管理,再结合 Kyuubi 的租户管理能力,T3 实现了 Spark 资源隔离,让不同的租户,即不同业务部门,连接不同的资源池,使用不同的资源配置。目前 T3 的任务日调度量大概是5万多,已经平稳运行了大半年,可以说这个架构还是很稳定的。
4. T3 整体的数据湖架构

04
特征平台 On MDS
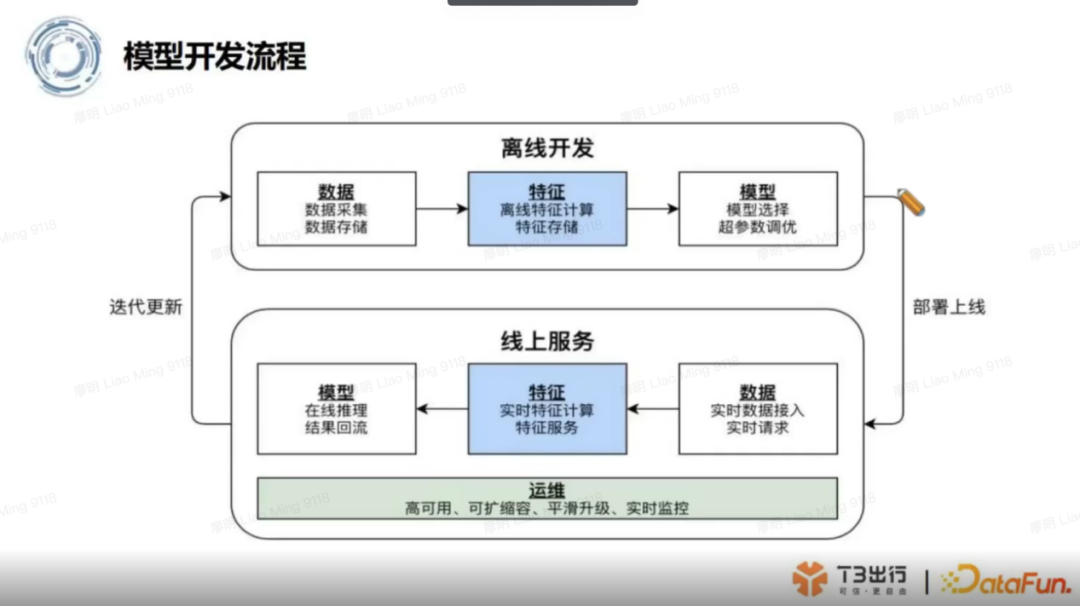
1. 模型开发流程
2. 特征平台作用

3. 特征平台的整体流程

4. 特征平台技术栈选型

(1)Metricflow

(2)数据集语义

(3)Feast-特征存储管理

(4)元数据管理
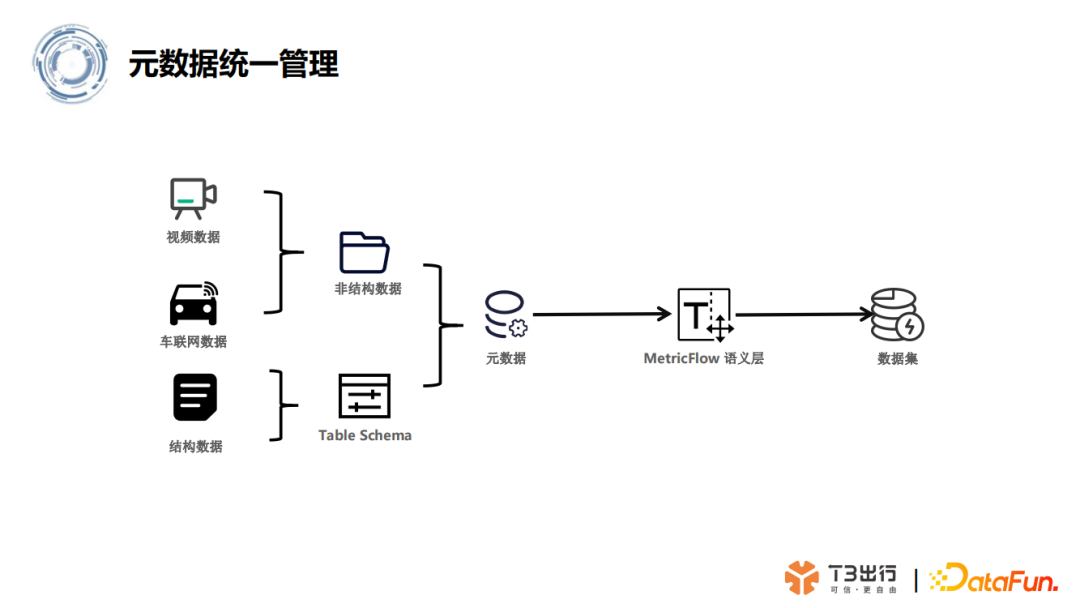
5. 特征平台内部架构

6. 特征平台 On MDS 架构
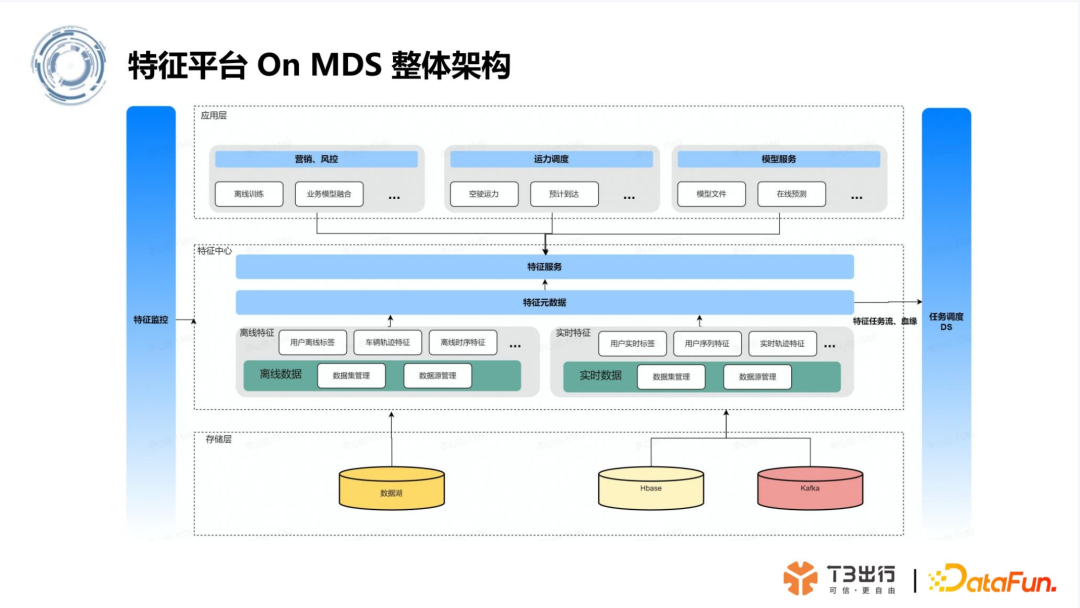
05
总结
06
问答环节
Q1:特征计算是在什么样的团队,是业务团队还是数据团队?
Q2:风控是自研的还是组件?有什么组件可以推荐。
Q3:特征工程有哪些基本的组件?


分享嘉宾
INTRODUCTION

李心恺
T3出行
大数据高级工程师
T3出行大数据高级开发工程师,T3出行算法平台负责人。
本文转载自李心恺 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/itCTCoSM-YcaZvPQWNIBvA。