摘要:Apache Flink 社区在 1.16 版本引入了 Hybrid Shuffle Mode [1],它是传统的 Batch Shuffle 和 Pipelined Shuffle 的结合,让 Flink 批处理具备了更强大的能力。Hybrid Shuffle 的核心思想是打破调度约束,根据可用资源的情况来决定是否需要调度下游任务,同时在条件允许时支持全内存不落盘的数据传输。
为了全面理解 Hybrid Shuffle 的潜力,我们基于 Flink 1.17 版本在多个场景下对 Hybrid Shuffle 进行了测试。本文将基于测试结果详细分析 Hybrid Shuffle 的优势场景,并基于我们的经验给出一些使用建议。
相比于传统的批式 Shuffle, Hybrid Shuffle 主要具备以下优势:
Hybrid Shuffle 打破了 Pipelined Shuffle 所有 Task 必须同时调度,Blocking Shuffle 必须分 Stage 调度的约束:
Hybrid Shuffle 打破了批作业所有数据必须全部落盘并从磁盘消费数据的约束,在上下游同时运行的情况下,它支持直接从内存消费数据,从而在提升作业性能的同时大幅减少磁盘 IO 带来的额外开销。
Hybrid Shuffle 的上述两个优势让它具备了传统批处理所没有的能力,我们对其进行了一系列的实验和分析,主要分为以下几个方面。
填补资源空隙
资源空隙指在作业运行的某些时间点,存在一些空闲的 Slot,导致集群资源不能被充分利用。Flink Blocking Shuffle 由于上下游 Stage 之间的调度约束,在上游 Task 没有完全结束时,下游 Task 无法被调度,从而产生了资源空隙。这种现象在部分 Task 存在数据倾斜的场景下尤为显著。
下图展示了一种 Blocking Shuffle 存在资源空隙的例子以及与之对应的 Hybrid Shuffle 的情况。可以看出 Blocking Shuffle 在这种情况下有 2 个 Slot 是无法被利用的,而 Hybrid Shuffle 的全部 3 个 Slot 都是在使用中的。
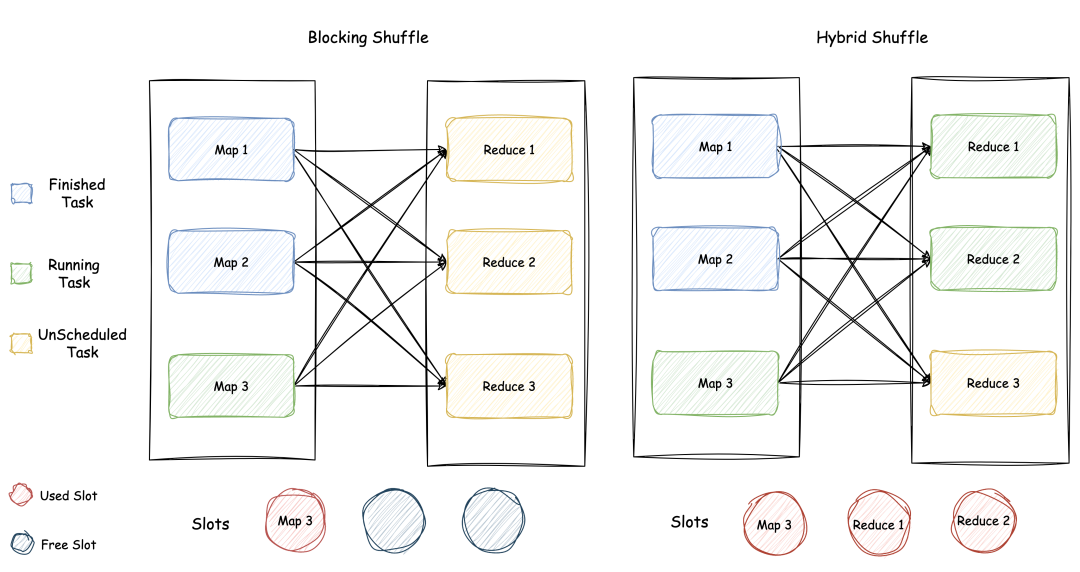

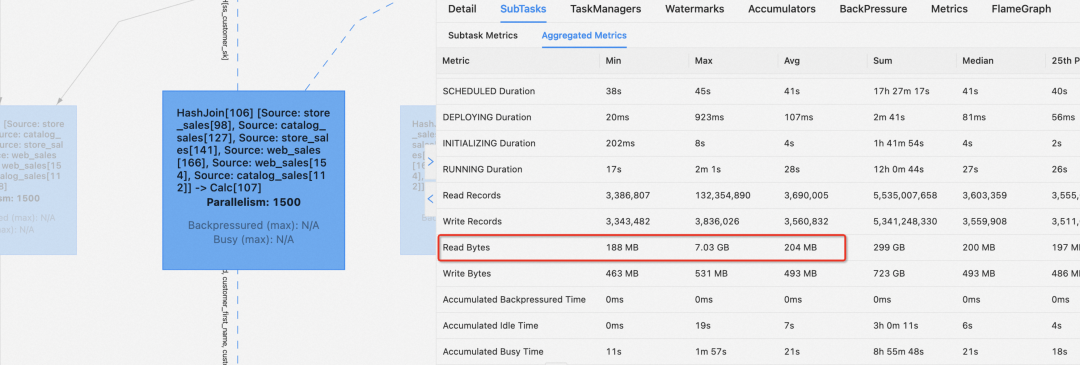
值得一提的是:数据倾斜现象是广泛存在的,以 TPC-DS q4 为例:其中一个 HashJoin 算子平均读取的数据量为 204MB,而其中有一个倾斜的 Task 读取的数据量达到了 7.03 GB。测试发现,Hybrid Shuffle 相比 Blocking Shuffle 在该 Query 上的总执行时间减少了 18.74%。
减少磁盘负载
Flink Blocking Shuffle 的中间数据会全量落盘,Shuffle Write 和 Shuffle Read 阶段分别进行磁盘的写和读操作。这会带来两个主要问题:
Hybrid Shuffle 引入了全落盘和选择性落盘两种落盘策略:
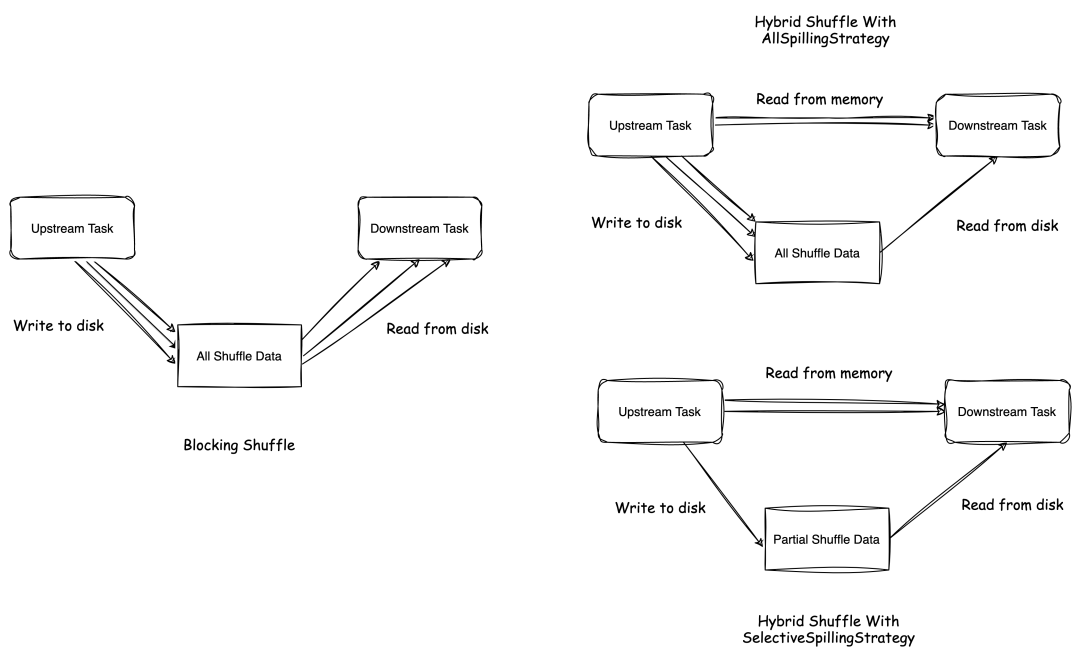
为了对比不同 Shuffle 模式和落盘策略对磁盘 IO 负载的影响,我们进行了如下实验:
-
测试不同 Shuffle 和落盘策略下从磁盘读取和写入的数据量占总数据量的比例:

-
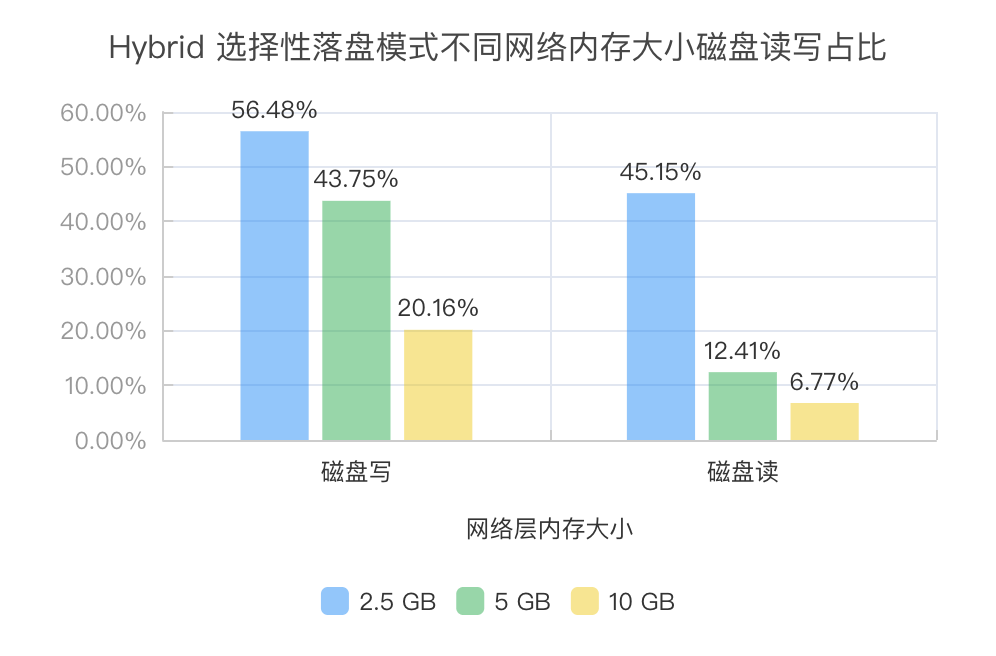
测试 Hybrid Shuffle 选择性落盘模式不同网络层内存大小下从磁盘读取和写入的数据量占总数据量的比例:
基于上述分析和实验结果,我们总结了以下三条 Hybrid Shuffle 的使用建议:
适当减少算子的并行度
算子的并行度是影响 Flink 作业执行性能的一个重要维度。对于使用 Blocking Shuffle 的批作业来说,一般会把算子的并行度调得比较大,来获得更好的分布式执行能力。
而在 Hybrid Shuffle 模式下,由于其具有提前调度下游任务的能力。在总资源不变的情况下,适当减少算子的并行度可以让更多的 Stage 同时运行,减少落盘的IO数据量,从而获得更好的性能。
为了证明这个结论,我们对 Hybrid Shuffle 和 Blocking Shuffle 在总资源(Slot 数)固定的情况下分别调整不同的算子并行度(500, 750, 1000, 1500, 2000)进行 TPC-DS 测试。按总执行时间衡量,测试结果如下:
Hybrid Shuffle 取得最优的并行度相对较小,但是 Blocking 取得最优效果的并行度却和总 Slot 数保持一致。这是由于 Hybrid Shuffle 可以以减少并行度为代价来换取上下游更好的并行。而 Blocking Shuffle 如果并行度设置得比较小,会存在空闲资源无法被利用的情况。
同样需要注意的是,对于 Hybrid Shuffle 来说,虽然在较低并行度下整体执行时间是最优的。但我们也发现有些 Query 并行度比较大的时候才会有更好的效果。这是由于这些 Query 中存在少数计算比较重的算子,在并行度比较小的时候,这些算子会成为整个作业的瓶颈。
以 TPC-DS q93.sql 为例,其拓扑如下:
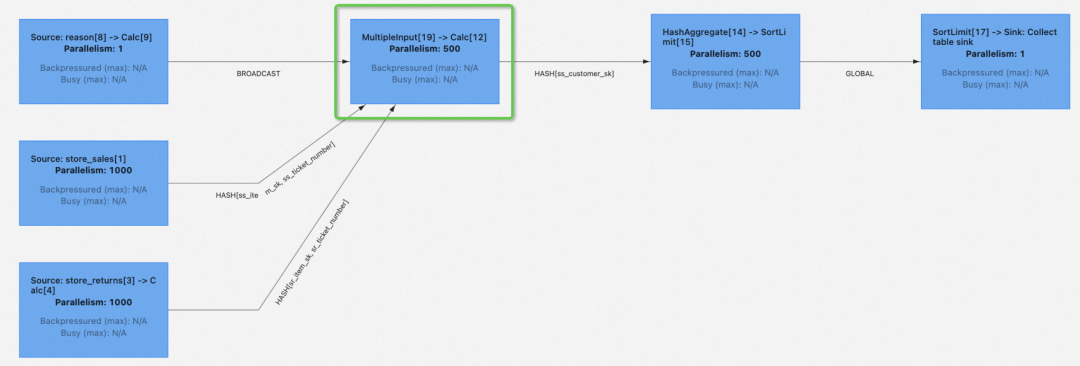
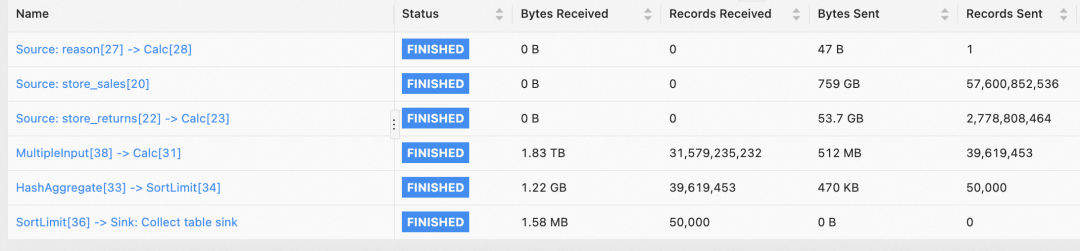
绿框中的 MultipleInput -> Calc 节点是整个作业的瓶颈,通过采样分析我们发现:其处理的数据量远大于其他算子,且单条数据处理得比较慢。即使下游任务全部已经被调度起来,仍然要等待该瓶颈节点处理完成。一旦该节点变成 Finished 状态,整个作业马上就会结束。
对于由 n 个 Stage 串联而成的拓扑,将第 i 个 Stage 在并行度较高(上下游无法同时运行)和并行度较低(上下游可以同时运行)时的执行时间分别记作 和 。则两种并行度下的总执行时间分别为:
注:为了更简单的说明问题,这里只考虑了多个 Stage 同时运行或先后运行,没有考虑一个 Stage 部分结束另一个 Stage 部分开始的情况。
缩减并行度的本质是让 Stage 自身的执行时间变慢, 也就是让 大于 ,但是让其可以同时运行。如果上游的 Stage 执行很慢而下游 Stage 执行很快,那么缩减并行度后上游 Stage 变慢增加的时间会比较多,而下游 Stage 其实不需要提前那么多时间开始执行,就会造成损失大于收益。
回到上述的 Query 中:MultipleInput -> Calc 是整个作业的瓶颈, 该 Stage 在高/低并行度下的执行时间分别记作 和 。则 (1) 式的结果主要取决于 ,而 (2) 式的结果等于 ,而缩减并行度带来的性能损失( – )相对较大,总体表现为作业执行时间变长了。当我们把该作业的默认并行度从 500 增加到 1500 时,作业性能得到明显提升,总执行时间减少了 47%。因此,在 Hybrid Shuffle 模式下算子的并行度也并非设置的越小越好。
适当增加网络层内存
网络层内存的大小对 Flink Shuffle 阶段的性能会产生较大的影响。如果这部分内存不足,网络层 Buffer 竞争会变得激烈,从而导致作业的反压。
■ 避免因网络层内存不够而报错
Hybrid Shuffle 需要更多的内存才能保证 Shuffle 阶段的正常运行。主要原因是:相比 Blocking Shuffle,Hybrid Shuffle 目前的实现中网络内存需求和 Task 的并行度不解耦。社区在 Hybrid Shuffle 方向上接下来工作的重点之一就是对此进行改进。
两种 Shuffle 模式 Shuffle Write 和 Shuffle Read 阶段对网络层内存的最小需求如下表所示:
■ 提升从内存读取的比例
对于 Blocking Shuffle 来说,数据只能从磁盘进行消费,积攒到一定程度之后直接落盘就可以释放所占据的内存,因此网络层内存只要能保证不产生激烈的 Buffer 竞争即可。即便配置得非常充足,对性能也不会产生很大的影响。而在 Hybrid Shuffle 的模式下,增加网络层内存可以提升从内存读取的比例。这是因为 Hybrid Shuffle 对内存中数据的驱逐策略是考虑内存池的使用率的,内存越充足,数据在内存中的存活时间就越久,也就越有可能被下游直接消费,进而减少磁盘 IO 开销。
为了探究网络层内存大小对不同 Shuffle 实现的影响,分别在 TPC-DS 10T 数据集上进行了测试。以 TaskManager 总内存 24G,网络层内存 2.5G 为基准,同时增大 TaskManager 总内存和网络层内存(每增加 1G 网络层内存,TaskManager 总内存也随之增大 1G)。性能相对基准配置的提升比例如下图所示:
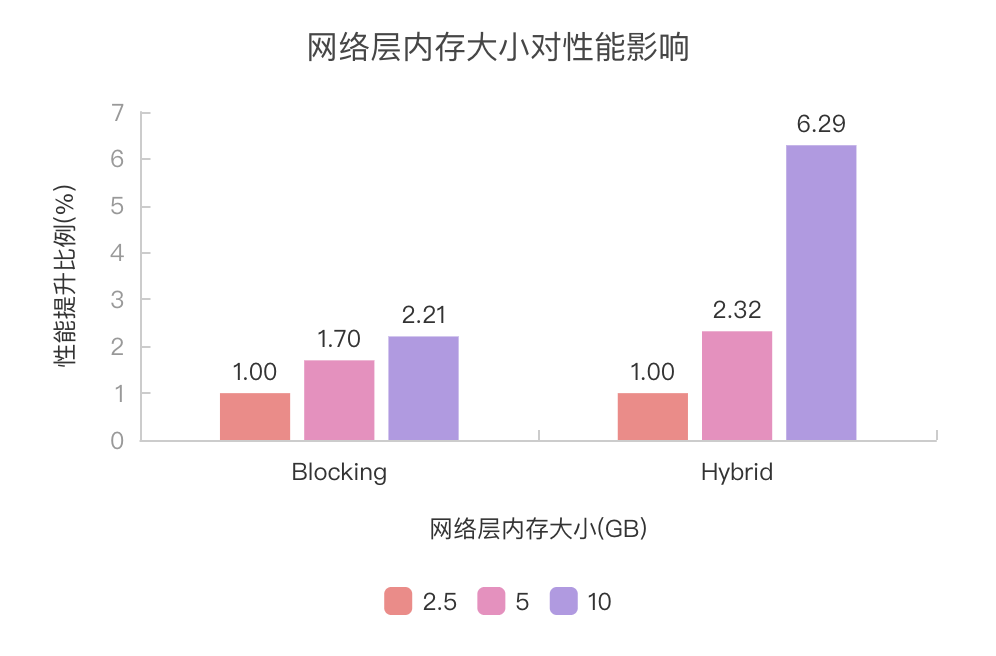
从实验结果可以看出,随着网络层内存的提升,两者的性能都有提升。Blocking Shuffle 提升的比例不是很明显,而 Hybrid Shuffle 则对网络层内存大小比较敏感。
尽量避免同时使用 Hybrid Shuffle 和动态并行度
Flink 支持在运行时对批作业动态设置并行度,其原理是: 按 Stage 对作业进行调度,根据上游已经结束 Stage 的统计信息(主要是产出的数据量)推断下游 Stage 的并行度然后进行调度。
动态并行度模式对调度有天然约束:下游 Stage 必须等上游 Stage Finished 之后才可以调度。Hybrid Shuffle 可以支持这种模式,但是这也就意味着 Hybrid Shuffle 在调度上的优势无法发挥出来。
为了验证两种 Shuffle 模式在动态并行度和非动态并行度下的表现,分别对 Blocking Shuffle 和 Hybrid Shuffle 在 TPC-DS 数据集上进行测试,配置默认并行度(parallelism.default) 为 1500,实验结果如图所示。
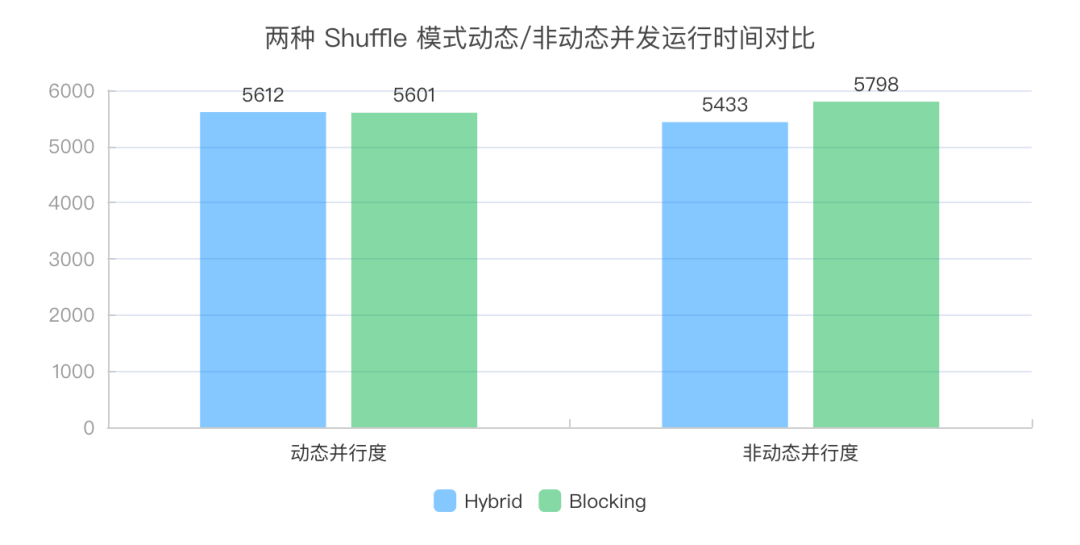
从图中可以看出,Hybrid Shuffle 在动态并行度模式下相比 Blocking Shuffle 总执行时间差别不大,性能基本相同。同时,其非动态并行度模式相比动态并行度有一定的性能优势,这主要是由于非动态并行度模式下,Hybrid Shuffle 可以在部分上游任务结束之后提前调度下游任务。而 Blocking Shuffle 的动态并行度却比非动态并行度模式性能要好,这是由于动态并行度降低了数据量比较小的 Task 在调度,部署等方面的额外开销。
本文主要分析了 Hybrid Shuffle 产生性能优势的原因,基于此进行了实验测试和分析,并给出了相应的使用建议:
希望本文可以帮助读者了解到在什么样的场景下应该选择 Hybrid Shuffle 以及如何对其进行调优。
[1] FLIP-235: Hybrid Shuffle Mode:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-235%3A+Hybrid+Shuffle+Mode
本文转载自郭伟杰@阿里 Apache Flink,原文链接:https://mp.weixin.qq.com/s/TgfxufmlqZu0OKuz6zorVg。
