
本期作者

陈昱康
哔哩哔哩离线平台负责人
卜凡
哔哩哔哩高级开发工程师


吴剑亮
哔哩哔哩资深开发工程师
1.背景
在过去一年的时间里,B站离线平台资源调度侧的主要挑战有两个方面:
1) 随着业务的不断增长,离线集群规模快速膨胀,用户对资源的需求在持续增大,主集群长期处于Pending较高的状态,资源需求超过交付量
2) 出于降本增效的考虑,消解Pending的方法不能仅靠物理机的增加了,而是需要在物理机整体数量不变的基础上通过超卖来提升集群整体的资源利用率。
为了应对上述挑战,调度侧在向内与向外两个方向上进行了积极的探索。“向内”聚焦于单台物理机,通过超配的方式不断提高单台物理机的利用率,使得单台节点能够处理更多的任务;“向外”与云平台部门合作,共同探索混部技术的落地,到目前为止,已经完成了离线超配,离在线混部、在离线混部等集群建设以及潮汐混部的技术实现,使得不同集群间的资源能够被更充分地调动。
为此我们自研了组件Amiya,旨在解决大数据集群资源缺口问题,自上线后较好的完成了Yarn离线集群以及在离线混部集群资源超配的工作。以离线主集群为例,目前5000多台NodeManager所在的节点已完成了Amiya的部署。在Amiya开启后,为Yarn额外提供了约683TB的可申请Memory(见下图1)以及约137K的可申请VCore(见下图2)。


图1 Amiya为Yarn额外提供了约683TB的可申请Memory
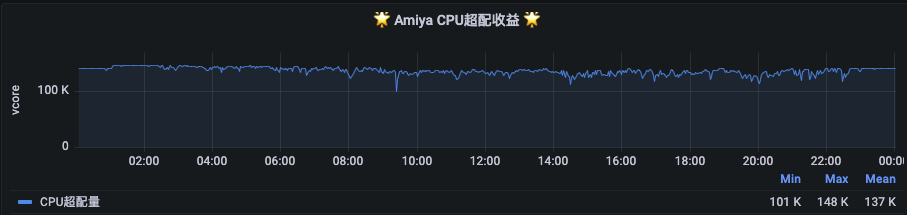
图2 Amiya为Yarn额外提供了约137K的可申请VCore
接下来,本文将对Amiya架构、功能模块、效果等方面进行详细阐述。
2.Amiya架构
超配组件所依赖的主要理论是“用户申请的资源量一般大于用户真实使用的资源量”。根据这个理论,实现超配组件的主要思路是,根据当前机器的实际负载情况,向调度组件虚报一定的资源量,使得更多的任务能够被调度到该台机器上运行。然而,这种做法也带来了一定的风险。在极端情况下,机器上运行的大部分任务的用户申请量会接近于用户真实使用的资源量。这种情况下,超配组件需要及时发现并响应,驱逐一定量的任务以保证机器整体的稳定运行。因此,超配组件必须具备智能管理的能力,能够根据机器实际的负载情况和任务的资源需求,动态调整超配量,以保证机器整体的稳定性和可靠性。同时,超配组件还应该具备良好的容错性和监控机制,能够及时发现和处理机器故障或异常情况,保障业务的连续性和稳定性。总之,超配组件虽然能够带来更高的资源利用率,但也需要合理使用和管理,以避免带来潜在的风险和损失。
由上述理论可知,对于超配组件来说,主要的北极星指标有两个:
1) 尽量提高节点的超配率
2) 在超配率处于高水位的情况下,尽量降低节点上任务的驱逐率
Amiya的主要功能为动态超配,为了更好的执行动态超配,Amiya又添加了节点信息收集管理、资源智能限制、跨Agent协同管理等一系列功能,这些功能的整合和实现旨在满足高超配率和低驱逐率的要求。
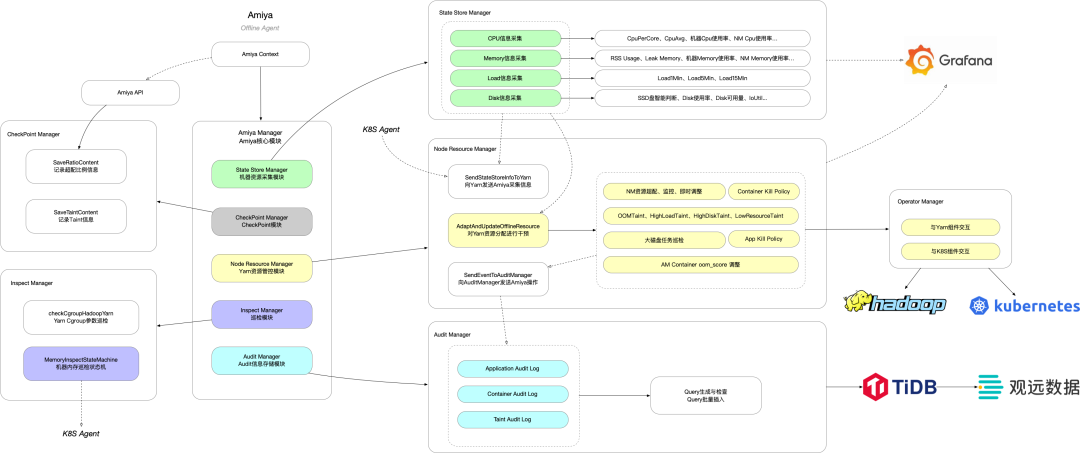
图3 Amiya v2整体架构图(清晰大图[1])
上图为Amiya v2的整体架构图,架构图自上而下的模块为AmiyaContext、StateStoreManager、CheckPointManager、NodeResourceManager、OperatorManager、InspectManager以及AuditManager。其中各组件的主要功能如下:
– AmiyaContext:当Amiya启动时,会自动探测当前节点的环境、当前NodeManager的状态等信息,并记录至AmiyaContext之中。各AmiyaManager会依据AmiyaContext中不同的状态做出不同的应对方案;
– StateStoreManager:StateStoreManager是Amiya的信息采集模块,它会定时探测机器的各项指标。首先,这些指标是Amiya超配决策所依赖的基础信息;其次,这些指标可以通过Grafana等工具记录下各时段机器的状态;最后,Amiya采集到的部分信息会通过OperatorManager传递给Yarn NodeManager与ResourceManager;
– CheckPointManager:CheckPointManager会将Amiya当前某些状态记录至硬盘,这些状态在Amiya重启后能够第一时间进行状态恢复。当前版本记录的状态主要包括当前Amiya的超配比例以及当前NodeManager所触发的Taint情况;
– NodeResourceManager:作为Amiya最核心的模块,NodeResourceManager掌管了Amiya的资源超配、Taint、大磁盘任务驱逐、特定Container指标调整等一系列逻辑。最主要的逻辑是资源超配,它从StateStoreManager获取当前节点信息并加以判断,能够做出资源提高(OverCommit)、资源降低(DropOff)、保持当前资源(Keep)三类判断,当判断为资源调整的OverCommit或DropOff后,还会根据一系列规则计算出当前Yarn NodeManager应该调整的具体资源量,并将其发送给OperatorManager,通过OperatorManager传递给NodeManager;
– OperatorManager:由上文NodeResourceManager的描述可知,OperatorManager是Amiya与其他组件互动的桥梁。目前的OperatorManager主要实现了与Yarn以及K8S的交互功能;
– InspectManager:机器层面的定期巡检节奏与任务巡检不一致,故将机器层面的巡检逻辑拆分开,通过InspectManager统一规范实现;
– AuditManager:Amiya会执行Container级别以及Application级别的的驱逐等操作,这类操作的审计信息会通过AuditManager批量插入至TiDB中,再通过观远形成各类前端报表以供查验。
3.关键实现
Amiya的关键实现主要分为三个部分,分别为超配逻辑实现、驱逐优化实现以及混部模式实现,其中前两项对应上述Amiya两个北极星指标,最后一项是Amiya在混部场景下的一些逻辑实现,这部分逻辑与离线场景相异。
3.1 超配逻辑实现
3.1.1 超配流程
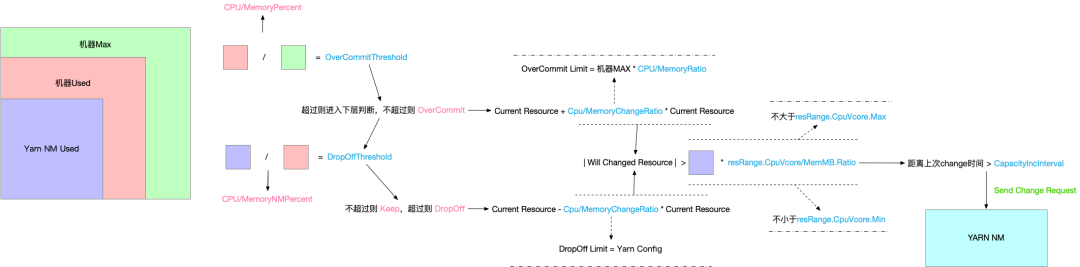
图4 Amiya在离线场景下的超配决策逻辑(清晰大图[2])
Amiya在离线场景下的超配决策逻辑如上图所示,这部分逻辑主要在Amiya的NodeResourceManager中实现。正如在架构中所介绍的,超配逻辑可以分为做出判断与资源计算两个步骤。与Yarn调度的资源相同,Amiya在超配过程中考虑的资源有Memory与CPU两类。
在做出判断的过程中,NodeResourceManager会从StateStoreManager内拿取Memory与CPU的两个使用率,一个是机器当前的使用率CPU/MemoryPercent,另一个是当前NodeManager占机器总使用量的比率CPU/MemoryNMPercent。首先判断当前机器的CPU/MemoryPercent是否低于阈值OverCommitThreshold,如果低于阈值则说明机器的剩余资源量较多,Amiya会给出资源提高(OverCommit)的判断;若当前机器CPU/MemoryPercent高于阈值OverCommitThreshold,则说明机器已经饱和,此时再考察CPU/MemoryNMPercent,若CPU/MemoryNMPercent高于阈值DropOffThreshold,则说明在资源饱和的机器内,NodeManager任务的资源占有量已经达到了预期之外,Amiya会给出资源降低(DropOff)的判断以抑制后续任务的提交,并且记录下具体超过阈值的资源为Memory或者CPU,这些信息在Container驱逐中会发挥作用。若CPU/MemoryNMPercent低于阈值DropOffThreshold,则说明NodeManager任务的资源占有量还在预期内,Amiya会给出保持当前资源(Keep)的判断,并持续观察机器资源的后续变化情况。
在得到判断的类型后,NodeResourceManager会通过OperatorManager获取到当前Yarn的资源量CurrentResource,并通过资源变化率CPU/MemoryChangeRatio与之相乘,得到本次所期待的资源变化量,其中OverCommit是正变化量,DropOff是负变化量。将变化量与CurrentResource相加,即为本次Amiya希望变更的Yarn资源量。
接着,这个资源量会接受三重检验。首先是资源量的变化不能超过Amiya所设的范围内,这个范围的上限是物理机总资源量的一个比率CPU/MemoryRatio,下限为NodeManager自身配置中的Memory及CPU的资源量。当前B站离线集群的CPURatio设置为2,MemoryRatio设置为1.5,即NodeManager能够通过Amiya得到的最大VCore为机器CPU核数的2倍,最大Memory为机器Memory的1.5倍;其次若资源变化量在一定的范围(resRange)内,Amiya会认为这个波动属于无效波动,并拒绝该次资源变化请求,旨在降低NodeManager资源的变化频率;最后Amiya会观测两次资源变化的时间间隔,只有在时间间隔大于CapacityIncInterval的情况下才会允许资源变更,达到减小NodeManager资源抖动的目的。
3.1.2 资源上限优化
在生产环境中,不同的机型采用相同的CPU/MemoryRatio计算得出的超配上限会导致资源分配不均衡。举例来说,在首次上线时,Amiya在机器上的超配上限为1倍物理机内存(Yarn可申请资源量由cgroup路径”/hadoop-yarn”下的213GB上升到了物理机内存256GB)、2倍物理机CPU,此时对于的机型,经过超配后CPU利用率能稳定在70%左右,而的机型CPU的利用率超配后的CPU使用率仅30%左右。根据经验,生产中用户申请的资源配比约为4GB:1VCore。对于48Core的节点来说,给到NodeManager的资源配比约为2.67GB:1Core;对96Core的节点来说,资源配比约为1.33GB:1Core。
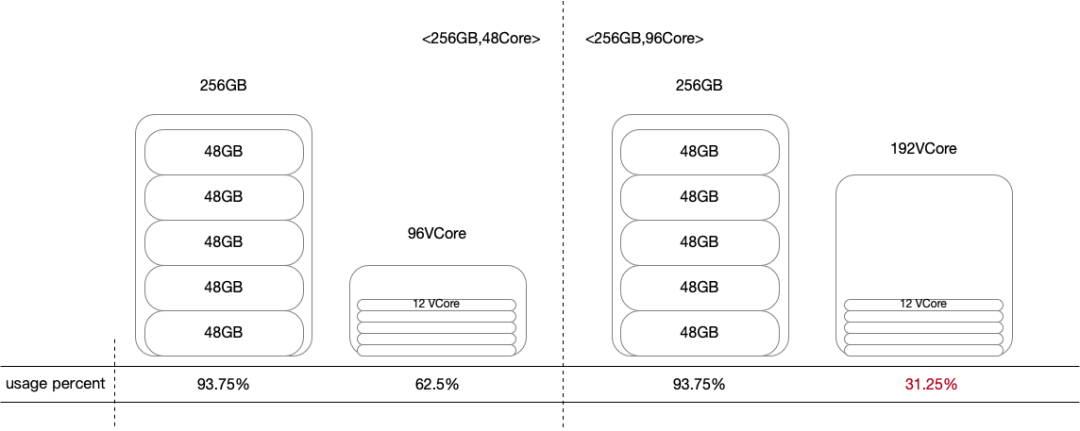
图5 首次上线时的资源分配模拟
如上图所示,我们假设有N个符合4GB:1VCore的Container向两种类型的机器提交任务,48Core的机器最终的CPU申请率为62.5%,而由于内存瓶颈,96Core机器的最终CPU申请率仅为31.25%。能够推断出,Memory与CPU的配比约接近4:1,两种资源的平均申请率越高,这也是我们日后调整资源上限的目标。
为了提升CPU的利用率,首先需要提高对内存的超配以降低内存瓶颈,在经过线上较长时间的验证后,我们发现对于256GB内存的机型,在内存超配为物理机内存的1.5倍(384GB)时,内存实际使用量与驱逐率能够达到我们可接受的平衡。此时48Core机器的配比为4GB:1VCore,96Core机器的配比为2GB:1VCore。对于48Core的机器,如下图所示,在夜间高峰2:30至10:00时段,机器级别的内存使用率均值在60%左右,其中NodeManager的Cgroup下内存使用率均值在65%左右,且基本未触发Amiya Container驱逐,CPU均值在80%左右,达到了超配的预期效果。
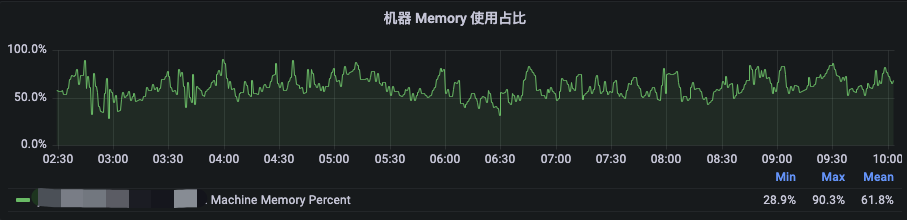
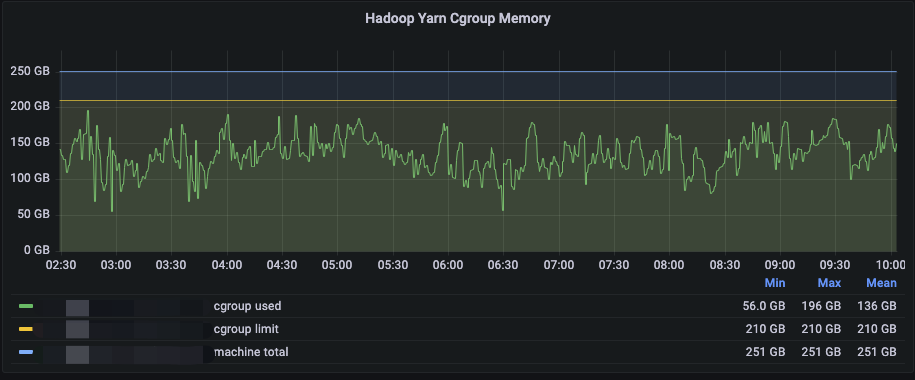
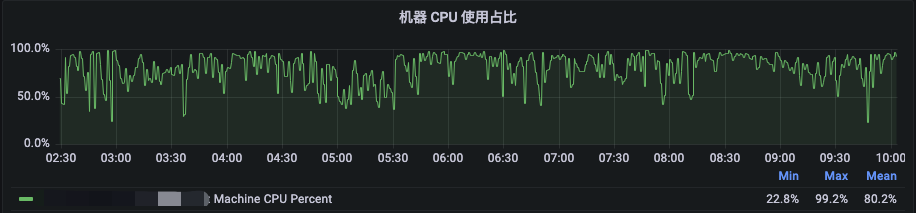
图6 48Core机型夜间高峰时段资源使用率
而对于96Core的机器来说,内存瓶颈的效应仍然较为明显,如下图所示,在夜间高峰2:30至10:00时段,机器级别的内存使用率均值在70%左右,其中NodeManager的Cgroup下内存使用率均值甚至达到了在81.5%左右,且多次触发了Amiya Container级别驱逐,但CPU均值仅为45%左右。此时再通过超配内存来拉升CPU使用率已意义不大。
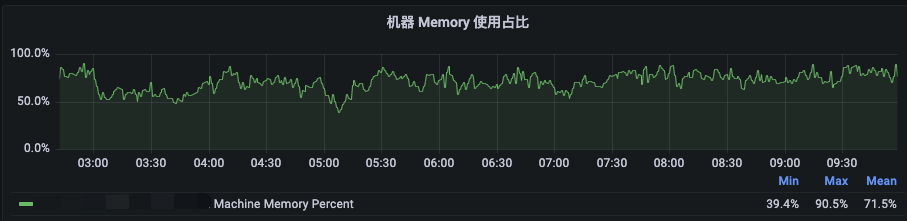

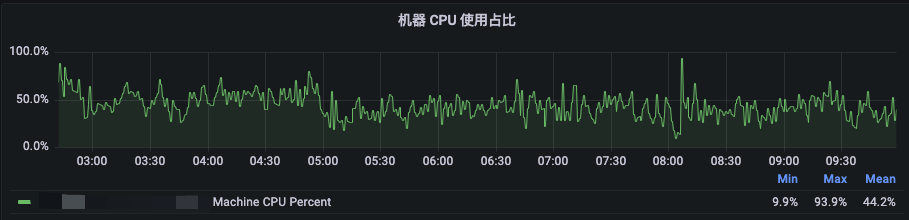
图7 96Core机型夜间高峰时段资源使用率
为了进一步提高96Core机型的CPU利用率,我们计算了当前内存的缺口。对于96Core的机器来说,CPU超配后的可申请量为96*2=192VCore。在内存超配1.5倍的情况下,添加一条128GB的内存条,能够使得当前的Memory可申请量提升到(256+128)*1.5=576GB,此时资源配比可以提升至3GB:1VCore,在内存用满的情况下同时拉高CPU的利用率。且在后续驱逐优化完成后,能够拉高384GB内存机型的Cgroup Memory Limit,将该批机器进一步提升至内存2倍超配,从而达到4GB:1VCore的资源配比。就目前1.5倍内存超配而言,如图所示,在夜间高峰2:30至10:00时段,机器级别的内存使用率均值在62%左右,NodeManager的Cgroup下内存使用率均值为在84%左右,与未添加内存时保持了一致的高使用率,但是CPU的使用率从45%提升至约70%,基本符合了超配预期。


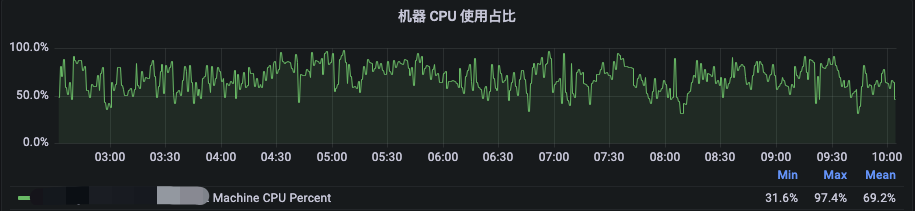
图8 96Core机型添加内存后夜间高峰时段资源使用率
3.2 驱逐优化实现
对于超配组件来说,驱逐逻辑关系着机器、任务、自身的稳定性,如何在保证高超配率的同时维持集群的稳定运行,是Amiya一直在探索的问题。目前Amiya的驱逐包含了Container驱逐、Application驱逐、Node驱逐三个维度,通过对三个维度的把控,保证集群在超配情况下处于较为稳定的状态。
3.2.1 Container驱逐
Container驱逐是Amiya在DropOff后触发的操作。由于Memory的短暂打满极有可能导致整机夯死,严重影响节点上所有组件的正常运行,而CPU的短暂打满是可以忍受的,故OperatorManager在向下调整NodeManager资源后,会检查DropOff的原因。如果是因为Memory达到阈值触发的DropOff,OperatorManager会在判断当前Memory的上升斜率是否达到阈值,若达到阈值则立即进入Container驱逐的逻辑;若是CPU触发的DropOff,OperatorManager会维护一个时间窗口,只有在窗口中多次CPU打满才会进入Container驱逐逻辑。通过这个优化能够极大的降低Container的驱逐率。
Container驱逐需要遵循一定的规则。进入驱逐逻辑后,Amiya会对当前”/hadoop-yarn”的Cgroup进行一次快照,获取各Container Memory或CPU的真实用量并进行排序,并根据使用量从大到小进行驱逐,直到真实使用量小于DropOff后的NodeManager资源量。在驱逐的过程中,Amiya会跳过一些特定的Container。当前Amiya支持跳过AM、根据Yarn的Priority跳过高优Container、跳过高优队列的Container、跳过特定队列中特定Priority的Container共四类Container强保设置。
在实际运行的过程中,我们发现在极端情况下,若大部分Container都命中了强保逻辑,则会导致Amiya驱逐效果不明显,高优的大内存Container仍然持续申请Memory,从而最终导致整机夯死。对于这种情况,我们做了两方面的优化。在Yarn层面,我们尽量打散了大内存Application的Container分布,不让单台节点上出现大量的高优大内存Container,抑制热点节点的形成;在Amiya层面,我们引入了极限驱逐(ExtremeKill)的概念,ExtremeKill仅在Memory DropOff时生效,当Amiya探测到无Container可驱逐且MemoryPercent达到危险水位时,会直接驱逐掉当前Memory占用最大的一个Container,并通过AuditManager进行风险操作记录。
通过Amiya驱逐的Container是因为节点资源压力的原因而被驱逐的,而非自身原因导致的失败,故不应算作运行失败的Container。我们在Yarn的NMWebService中添加了专供Amiya驱逐的API,并通过特殊的DiagnosticInfo与ExitCode进行标识。同时我们改造了Spark与Hive使之能够识别这些驱逐导致的task失败,跳过常规的失败次数累计逻辑,不计入真正的失败,直接进行重试,避免了因为task失败过多导致的作业失败。
3.2.2 Application驱逐
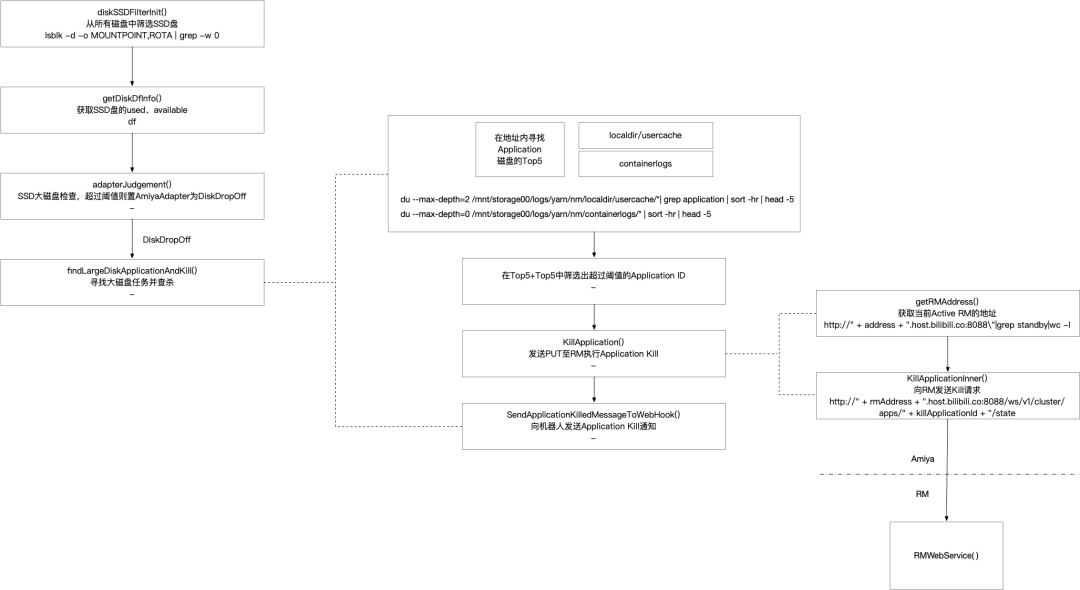
图9 Application驱逐逻辑
我们集群上经常有一些需要大量写本地盘的任务,比如大量shuffle spill导致磁盘容量占满进而打挂节点,为此amiya实现了Application驱逐功能,如上图所示,Application驱逐主要是对大磁盘任务的驱逐。Amiya通过StateStoreManager对SSD盘(任务的临时目录存放在SSD盘)进行监控,当SSD盘使用量达到预警阈值后,Amiya会对当前Application在本节点的磁盘占用量进行排序,查找是否存在占用量大于一定阈值的Application,若存在则对该Appliction进行驱逐,以保证较为健康的节点磁盘容量。
进一步地,Amiya会向RMProxy查询当前Application对应的JobID,并向作业画像组件标记该Job为大磁盘作业。之后该Job的Application再次提交时,会自动添加上大磁盘的Policy(如下图所示),使该Application的Container分配在磁盘剩余容量较多的节点上,同时会对Container进行打散,避免在一台机器上分配过多container

图10 被标记为大磁盘Policy的Application
3.2.3 Node驱逐
Amiya化用了K8S中Taint的语义,为需要驱逐的节点添加不同的Taint,以达到阻止ResourceManager对其继续分配的目的。目前Amiya支持的Taint包括:
– OOMTaint:节点触发了oom-killer后,Amiya会向NodeManager发送OOMTaint信号阻止新的任务向该节点分配,并持续监控节点MemoryPercent,直到小于阈值后解除OOMTaint,Node Manager可以继续分配;
– HighLoadTaint:节点Load5MinPerCore超过Taint触发阈值后,Amiya认为该节点的Load负载已经过高,向NodeManager发送HighLoadTaint阻止新的任务分配,直到Load5MinPerCore低于Taint后取消阈值。Taint触发阈值一般与Taint取消阈值保持一定差值,防止Taint频繁抖动触发;
– HighDiskTaint:由节点SSD盘使用量触发的Taint,可以设置MaxPolicy与MinPolicy。其中MaxPolicy指SSD盘中存在使用量超过90%的盘则触发Taint,将该节点过滤;MinPolicy指SSD盘中使用量最低的的盘的使用量超过90%则触发Taint,将该节点过滤;
– LowResourceTaint:在混部集群中,可能出现单台节点资源缩减过少的情况(比如缩减到单台1core 2GB),我们不希望这类节点承接任务后由于资源不足导致任务运行过慢,故在节点资源低于阈值时,Amiya会向NodeManager发送LowResourceTaint以阻止任务分配,待上报的资源量符合预期后再取消该Taint;
– NeedToStopTaint:仅通过API触发的Taint。在潮汐混部的场景中,大数据服务管理平台BMR会退避部分NodeManager节点给到在线应用,在退避前会向Amiya发送请求,触发NodeManager的优雅下线请求,此时Amiya会立即发送NeedToStopTaint给NodeManager阻止其继续接受任务,并在经过一段等待时长后对NodeManager进行优雅关闭。
Amiya信息与NodeManager信息互通,如下图所示,节点Taint信息可以直接在ResourceManager的WebUI上进行展示,方便管理员进行排查。

图11 Taint信息在ResourceManager Web UI上的展示
3.3 混部模式实现
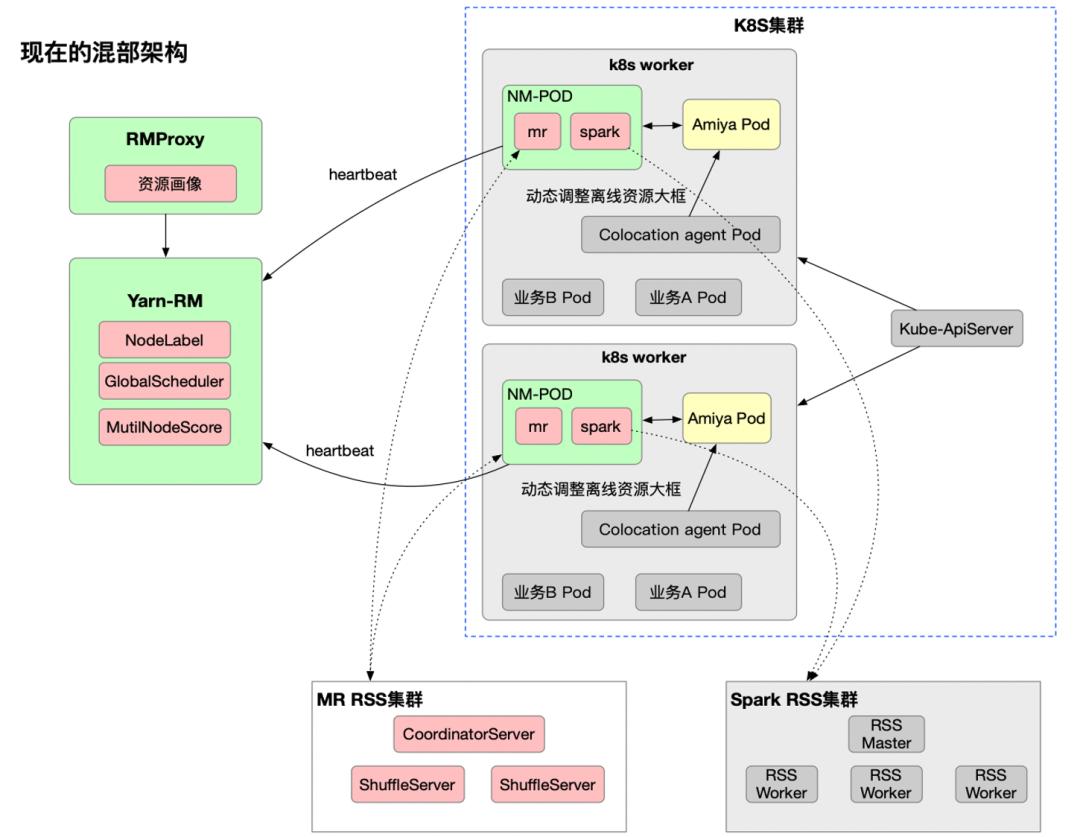
图12 在离线混部架构
如上图所示,混部集群是我们在公司的在线容器云上部署的一套Yarn On k8s,其中NM和Amiya在Pod内,我们基于任务和集群的资源画像通过RMProxy&Yarn Federation会路由一些低优先级作业到混部集群。Amiya在v2版本中支持了对混部集群中的NodeManager Pod的资源管控。在之前的混部集群里,NodeManager Pod的资源由K8S Agent进行统一比例超配后上报给ResourceManager,无法做到根据节点信息进行动态超配。如下图所示,Amiya v2将Amiya作为SideCar部署进NodeManager Pod中,从而辅助父应用NodeManager Container进行资源超配等一系列操作。
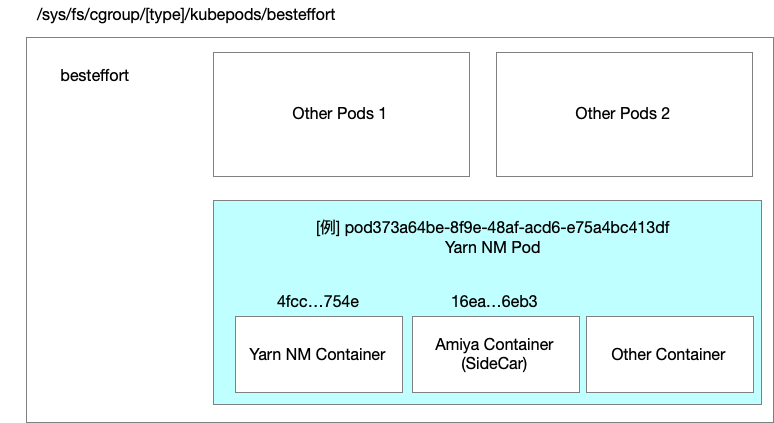
图13 Amiya作为SideCar部署进NodeManager Pod中
在部署的过程中,需要将Cgroup地址挂载进Amiya Container中,并且申明与NodeManager Container共享进程命名空间,使NodeManager的PID对Amiya可见。
在Amiya v2部署后,当前混部集群Yarn资源上报流程如下图所示。首先,K8S Agent不再负责统一比例的资源超配,而是将为NodeManager Pod预留的真实资源量通过Unix domain socket的方式传递给Amiya。其次,Amiya接受到这个值后会将其视为当前NodeManager Pod的物理资源上限,根据这个上限与从Cgroup中获取的当前资源使用量进行超配预期的计算,得到当前NodeManager的期待资源量。最终将这个期待量传输给NodeManager,改变其资源量,完成一次动态超配的调整。

图14 混部集群Yarn资源上报流程
4.超配效果
超配效果的评估主要有两个指标,一个是调度组件层面的资源可申请量的提升量,另一个是节点层面的资源真实使用量的提升量。在Amiya的场景下,调度组件层面的提升量是Yarn Memory与VCore的提升量,节点层面的提升量是Amiya真实超配量。
在离线主集群,Amiya部署在5000多台节点上,Amiya为Yarn带来了约的额外资源可申请量。
Amiya真实超配量的计算如下公式所示:

其中YarnUsed为当前Yarn的已申请量,YarnGuarantee是Yarn Config中申明的节点最大资源量,YarnGuarantee的值在Amiya启动后会被Amiya计算出的超配值所覆盖。从而
更进一步地,通过如下公式能够计算出Amiya超配等效增加的机器数量,其中分母为集群主力机型的memory.limit_in_bytes:
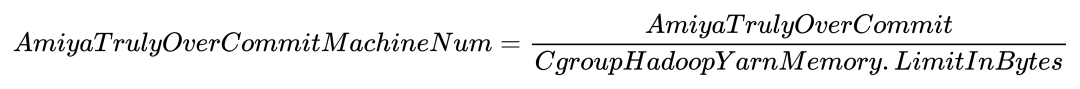
根据上述公式计算得出,这些可申请资源量最终转化为了186TB(夜间高峰2:30至10:00均值)~ 288TB(七日峰值)的直接内存收益,相当于添加了约 900~1400 台节点的算力。
其中某天的Amiya真实超配收益、真实收益台数的Grafana监控如下图所示。
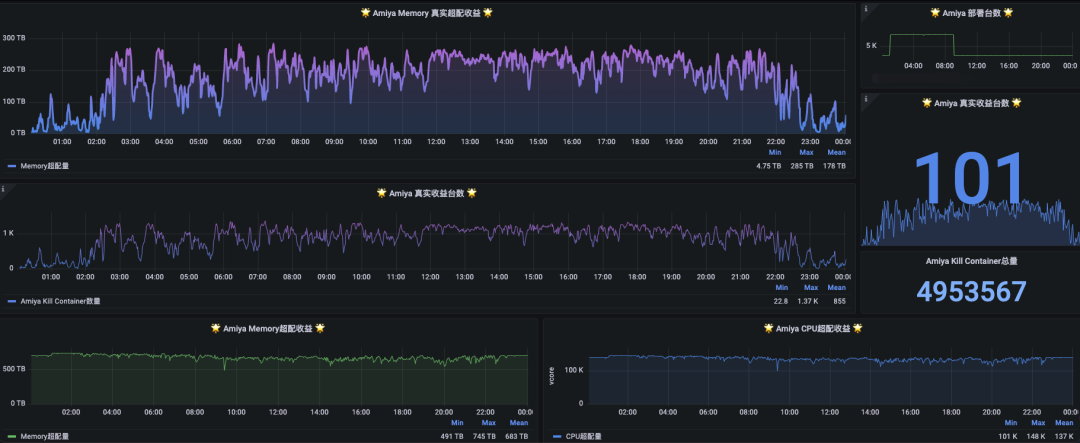
图15 某天Amiya真实超配收益监控
根据物理机内Cgroup获取的统计值,我们能够进一步统计出Amiya单台真实超配收益。对于Memory来说,部署Amiya后单台节点Memory使用量提升的每日均值为33.26GB,日均提升为15.62%;对于CPU来说,部署Amiya后单台节点的CPU使用率提升每日均值为18.56%,对于占据主集群超半数的主力配置来说,单台节点的CPU使用率每日均值的提升更是达到了22.04%。
在关注超配量的同时,驱逐率也是我们主要关注的指标。目前Amiya的驱逐率在 0.56%(夜间高峰2:30至10:00均值) ~ 2.73%(七日峰值)之间。其中某天的Amiya驱逐率的Grafana监控如下图所示。
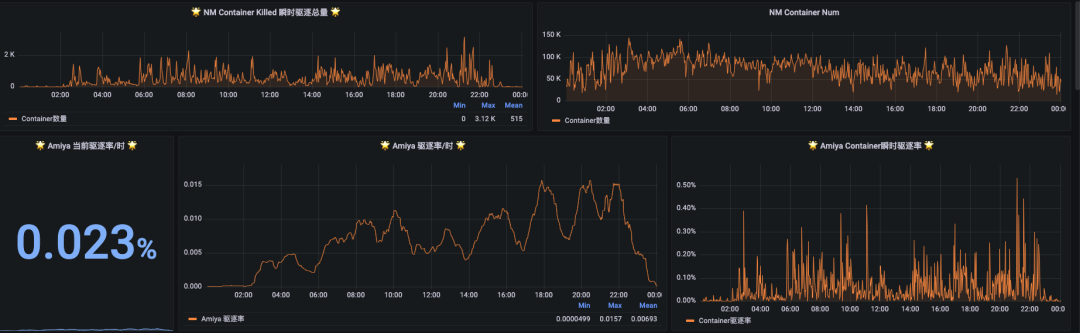
图16 某天Amiya驱逐率监控
Amiya严格遵守B站Yarn SLA规定,在驱逐时对高优先级的任务无影响,对中优先级的任务在极端情况下会出现ExtremeKill,主要被驱逐的是低优先级任务。
在混部集群,Amiya已上线了全量节点,上线后混部集群的机器CPU利用率约提升了10%左右,下图为上线后首日的利用率截图。
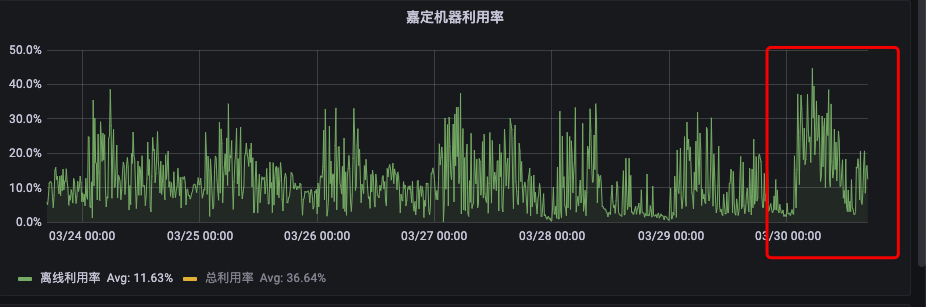
图17 上线首日嘉定机器利用率提升情况
5.总结与展望
目前Amiya已经能够较稳定的支持离线场景、混部场景的Yarn资源超配功能,且协助Yarn进行了一定的调度管理。目前Amiya正在进行的改造主要有三点:
1.在Yarn任务内存消耗极大极快的情况下,会导致系统来不及回收内存而直接夯住,影响节点上DataNode的正常运行。针对这个场景,Amiya正在与B站内核组合作,支持Group Identity、OOM Priority、Async Reclaim等一系列内核优化,以期彻底消除超配导致整机夯死的情况,降低NodeManager超配对DataNode和系统进程等高优组件的影响。
2.目前的驱逐策略对低优先级的大内存任务不甚友好,可能导致个别大内存任务频繁触发Container驱逐从而导致任务运行过慢,Amiya需要得知Application层级的驱逐情况,并对驱逐频繁的Application进行特殊处理。
3.正如上述第二点所说,Amiya目前和Nodemanager一起仅部署在worker节点上,只能探知当前节点的Container级别的信息,无法汇总成Application级别的作业资源画像,无法支持全局的资源把控、驱逐策略、更灵活的动态max_ratio超配等功能。目前正在开发的Amiya v3版本希望支持Amiya的Master-Worker架构。Amiya Worker部署在节点上,通过心跳发送节点信息给Amiya Master,Amiya Master再进行更高维度的决策。另外Amiya目前依赖Yarn ResourceManager WebUI来展示信息,Amiya Master建成后能够将Amiya信息展示迁移回Master,降低Amiya与Yarn的耦合。
在本篇文章中,我们主要介绍了B站大数据调度侧在“向内”超配所达到的阶段性效果,对于“向外”进行集群混部的进展,请关注后续文章《B站大数据集群混部实践(下)》。
高清图片链接:
[1] Amiya v2整体架构图:https://ibb.co/RPxjstc
[2] Amiya在离线场景下的超配决策逻辑:https://ibb.co/LrTbdLG
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,欢迎点个“在看”吧!
本文转载自 陈昱康卜凡吴剑亮 哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/ZNhoViur5nsfuH-r_yB3KA。