
故事的开始是这样的,大数据开发删了几张表,过了2天才发现删错了,于是开发找我恢复表,我看了下数据还在回收站,问题不大。只需要建表,把所有的分区数据mv回去,然后msck分区就可
但是开发跟我说,他没有建表语句了,也忘了表结构长啥样了,多少个字段,他没有按照规范把生产的表结构同步到资产平台或者wiki上或者gitlab上,这个真是头疼,大家都知道,本质大数据集群中表元数据与数据的关系就是锁头和钥匙的关系,你现在锁头没有丢,但是钥匙不见了,即使有数据,你也解析不出来哇。
作为一个多年大数据运维老鸟的我,早已经预知了这种风险,还好我我每天自动备选归档hive元数据库,当然作为一个运维老鸟,我还默默做了很多风险防备的申请哈。


于是乎我解析hive备份的元数据,通过一顿元数据关联,得到关于表的如下元数据信息
dwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 apk 应用包名 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 app_name 应用名称 string day string 入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 app_url 平台详情页链接 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 cate 应用所属分类 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 other 其他 string day string 入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 region 平台名称 string day string入库日期 org.apache.hadoop.hive.ql.io.
于是乎我需要得到建表语句怎么办?一个个复制粘贴字段,那是不可能的,有些表还是struct格式,几百个字段,虽然可以这样搞,但是配不上我的身份,于是chatgpt深度用户的我打开了他
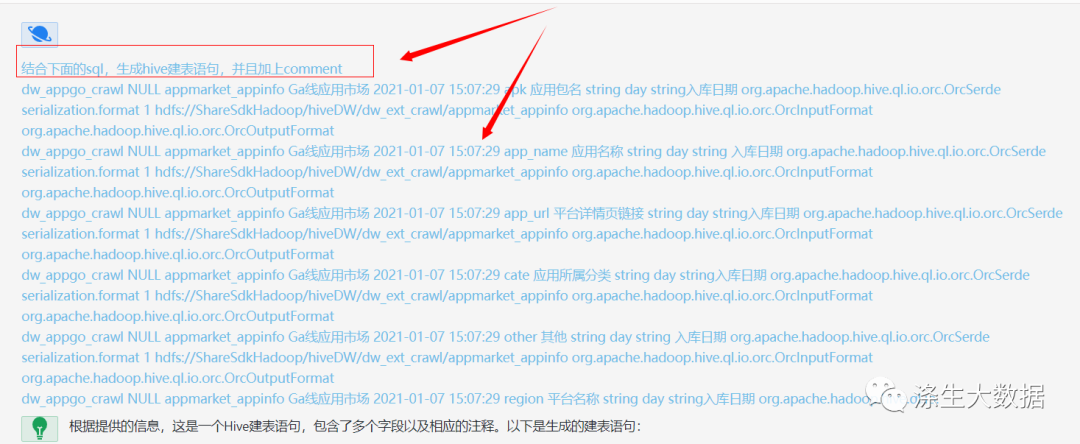
你别说还挺厉害的
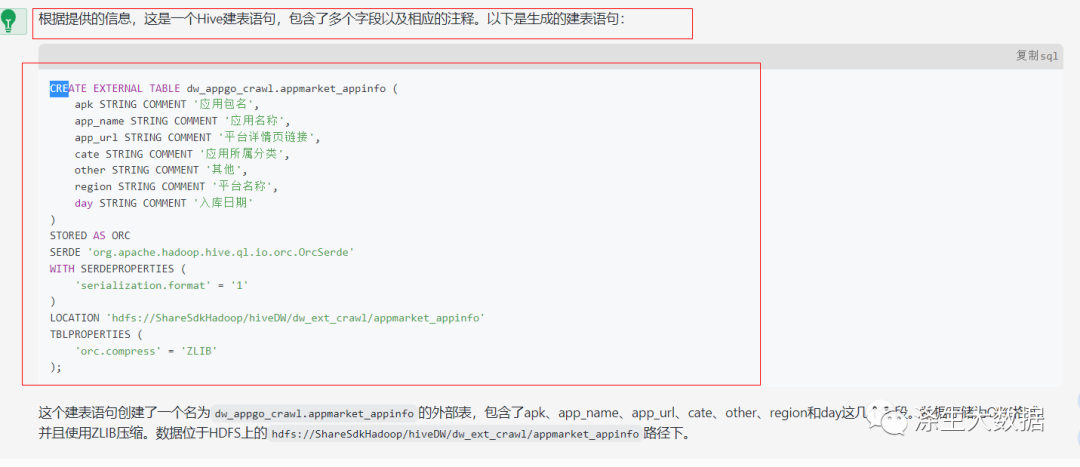
但是我要的是分区表哇,那我继续告诉他day是分区,看看他接下来的表现哈(结合下面的sql,生成hive建表语句,并且加上comment,注意day是分区…..)
根据提供的信息,这是一个Hive建表语句,包含了多个字段以及相应的注释。以下是生成的带有分区的建表语句:
CREATE EXTERNAL TABLE dwd_weibo_crawl.appmarket_appinfo (apk STRING COMMENT '应用包名',app_name STRING COMMENT '应用名称',app_url STRING COMMENT '平台详情页链接',cate STRING COMMENT '应用所属分类',other STRING COMMENT '其他',region STRING COMMENT '平台名称')PARTITIONED BY (day STRING COMMENT '入库日期')STORED AS ORCSERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'WITH SERDEPROPERTIES ('serialization.format' = '1')LOCATION 'hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo'TBLPROPERTIES ('orc.compress' = 'ZLIB');这个建表语句创建了一个名为dwd_weibo_crawl.appmarket_appinfo的外部表,包含了apk、app_name、app_url、cate、other、region这几个字段。数据存储为ORC格式,并且使用ZLIB压缩。数据位于HDFS上的hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo路径下。另外,这个表使用day字段作为分区。
大家注意了吗,虽然chatgpt把表的字段啥的解析出来了,但是表的实际结构依然是错误的,实际无法执行,当然我们直接复制表的上部分即可,这些是么问题的。但是我觉得这依然不够完美,看我继续盘他,我要直接可以复制粘贴来执行的语句。

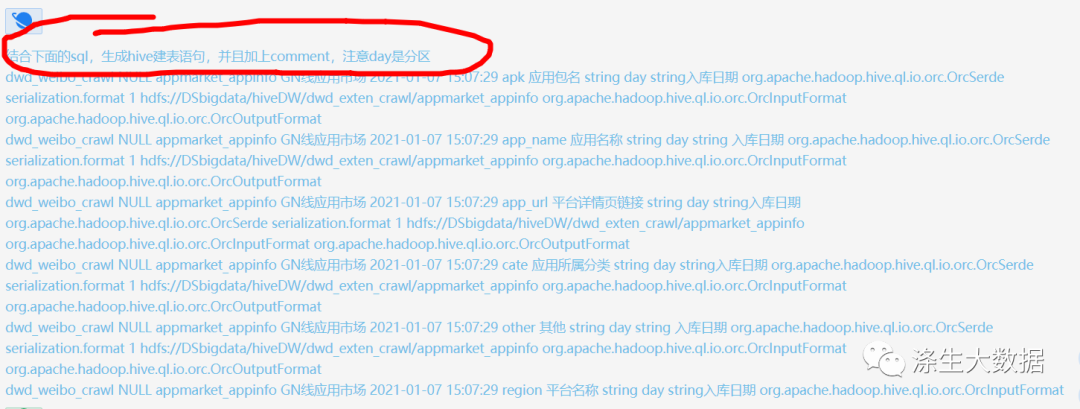
现在我给他个真实的建表语句参考下,看看gpt能否根据我给参考建表语句解析出来我需要的建表语句。

下面是标准的建表语句,给你参考CREATE TABLEpaas.tmp_fsimage_hive_02(usernamestring comment'用户名',groupnamestring comment'组名',ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION'hdfs://ShareSdkHadoop/user/hive/warehouse/paas_test.db/tmp_fsimage_hive_02'结合下面hive元数据信息,生成hive建表语句,并且加上comment,注意day是分区,语句要是可以执行的hive语句dwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 apk 应用包名 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 app_name 应用名称 string day string 入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 app_url 平台详情页链接 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 cate 应用所属分类 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 other 其他 string day string 入库日期 org.apache.hadoop.hive.ql.io.orc.OrcSerde serialization.format 1 hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo org.apache.hadoop.hive.ql.io.orc.OrcInputFormat org.apache.hadoop.hive.ql.io.orc.OrcOutputFormatdwd_weibo_crawl NULL appmarket_appinfo GN线应用市场 2021-01-07 15:07:29 region 平台名称 string day string入库日期 org.apache.hadoop.hive.ql.io.orc.OrcInputFormat根据提供的Hive元数据信息及参考的标准建表语句,以下是生成的带有分区的可执行的Hive建表语句:
我看下gpt的表现如何把:
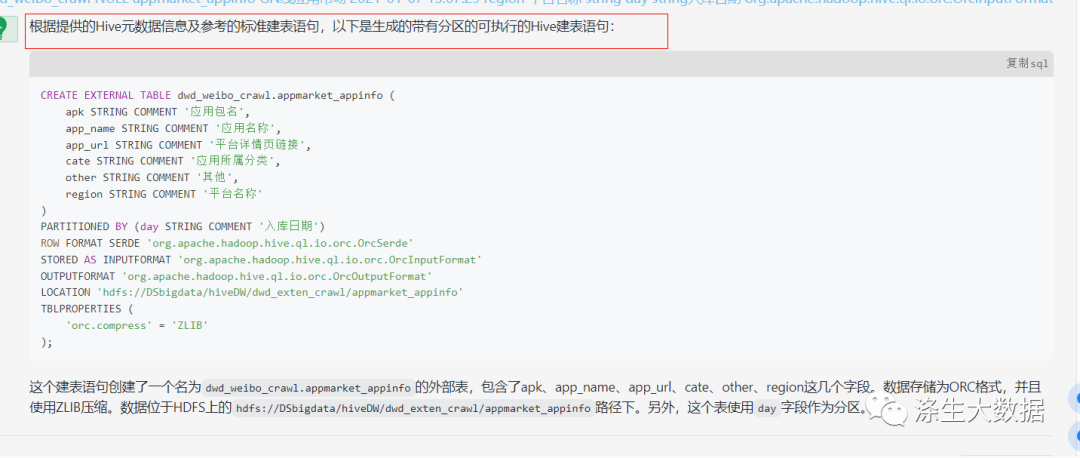
CREATE EXTERNAL TABLE dwd_weibo_crawl.appmarket_appinfo (apk STRING COMMENT '应用包名',app_name STRING COMMENT '应用名称',app_url STRING COMMENT '平台详情页链接',cate STRING COMMENT '应用所属分类',other STRING COMMENT '其他',region STRING COMMENT '平台名称')PARTITIONED BY (day STRING COMMENT '入库日期')ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION 'hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo'TBLPROPERTIES ('orc.compress' = 'ZLIB');这个建表语句创建了一个名为dwd_weibo_crawl.appmarket_appinfo的外部表,包含了apk、app_name、app_url、cate、other、region这几个字段。数据存储为ORC格式,并且使用ZLIB压缩。数据位于HDFS上的hdfs://DSbigdata/hiveDW/dwd_exten_crawl/appmarket_appinfo路径下。另外,这个表使用day字段作为分区。
执行下试试,bingo
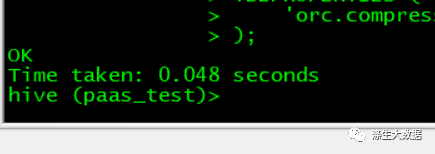
剩余的几张表我只需要按照这个模板套路进去,gpt就已经给我写好的模板,提升效率妥妥滴哈,再也不怕开发让我恢复表结构了哈

那让我来再试试我们百度的文心一言吧

本文转载自涤生-光哥 涤生大数据,原文链接:https://mp.weixin.qq.com/s/PmzP5YIX_JlbjelMs6ijRA。