


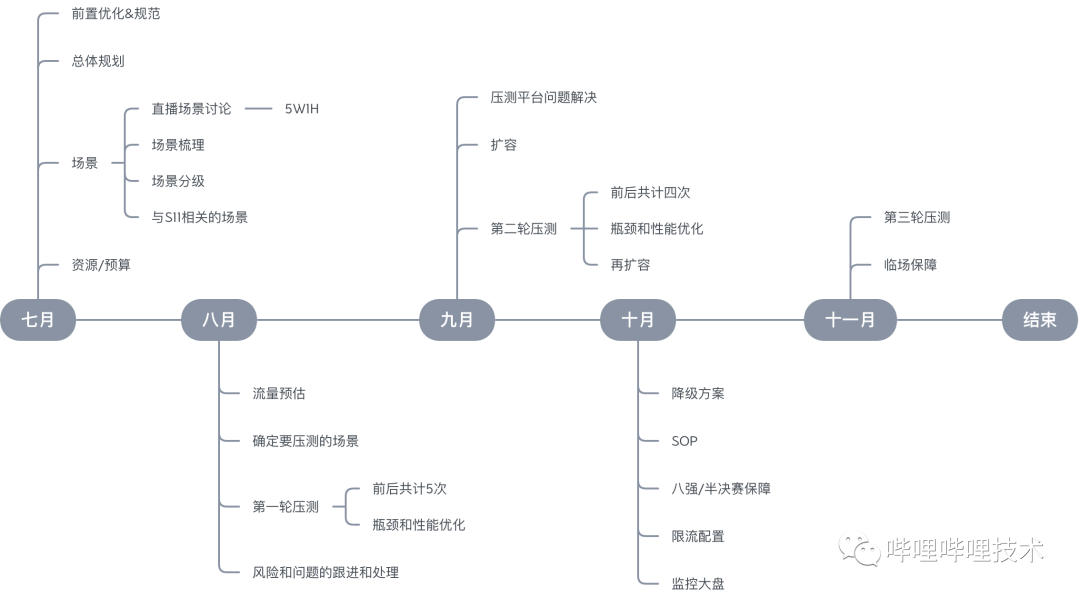
01
背景
02
大型活动的稳定性如何保障
-
场景名称 -
场景级别(P0、P1、P2、PX) -
设计终端(iOS、Android、Web、PC) -
场景描述(使用5W1H方法,即谁Who在什么时间段When在什么页面Where做什么事What,原因是什么Why,如何做How) -
场景交互(使用图来表征)
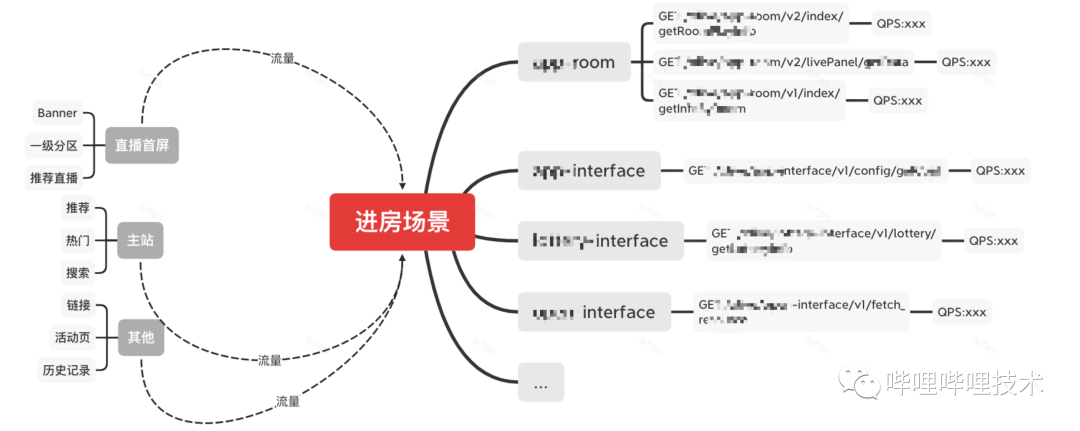
-
历史流量算法:根据当前&历年活动流量,计算整体业务体量同比增量模型。
-
业务量-流量转化算法(GMVDAU订单量):一般以业务预估总量(GMVDAU订单量)为输入,根据日常业务量-流量转化模型(比如经典漏斗模型)换算得到对应子域业务体量评估。
-
第一轮:先不扩容,压出系统的极限,找出瓶颈和优化点 -
第二轮:等系统优化和业务需求做完,扩容后,按照S11预计流量压测 -
第三轮:验证,回归,查漏补缺
-
确定场景下所有要压测的接口,如果有的接口不太容易压测(比如会产生脏数据)暂时先不压测,但是后期需要做预案(比如如何保障,出了问题怎么办,降级方案是什么) -
打开接口限流 -
压测信息周知到你依赖的服务的负责人,如果涉及Mysql,Tidb,Redis,MQ等同样需要周知到对应负责人 -
如果多个场景对同一个服务都依赖,那多个场景需要一起压测
-
开始要缓慢施压且控制压测时间(比如1分钟),以防止出现问题。 -
紧盯各项监控(服务的监控,Redis,Mysql,Tidb,MQ等),如有异常,立即停止压测 -
遇到日志报错增多,立即停止压测 -
遇到接口耗时明显增加,立即停止压测 -
资源(服务器,Redis,Mysql,Tidb,Databus等)逼近极限,需停止压测 -
多轮压测,步步提升QPS -
保证压测流量均衡 -
记录压测过程中不同压测QPS下各项资源(服务器,Redis,Mysql,Tidb,MQ等)压力情况,以供后续分析
-
查看各项监控,服务是否健康,QPS是否正常,保证服务没有问题 -
如果有临时数据,是否要清除
-
分布式系统有着各种相互依赖,可能出错的地方数不胜数,处理不好就会导致业务受损,或者是其他无法预期的异常行为[1][2]。 -
我们应该致力于在这些异常行为被触发之前,尽可能多地识别风险。然后,针对性地加固、防范,从而避免故障发生时所带来的严重后果。 -
混沌工程在生产分布式系统上进行实验,主动找出系统中的脆弱环节。通过实证的验证方法为我们打造更具弹性(弹性:系统应对故障、从故障中恢复的能力)的系统。
-
DB不可用/不稳定(超时,抖动等) -
Cache集群不可用/不稳定(超时,抖动等) -
依赖的RPC服务不可用/不稳定(超时,抖动等) -
网络抖动 -
宕机
-
梳理整个系统的部署架构图,如下所示:
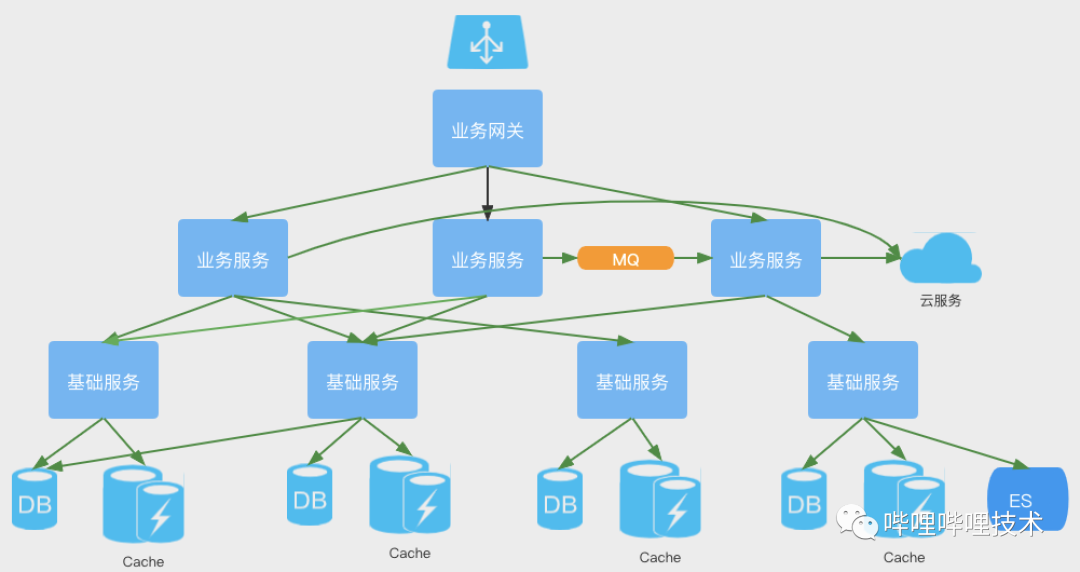
-
设置故障点
-
故障演练

-
页面降级:非核心页面模块,占用紧张资源,关停该页面,减少访问; -
服务降级:将功能分类,分为核心服务与非核心服务,将非核心服务进行关停; -
依赖降级:将依赖服务梳理分类,保证核心依赖的稳定,将非核心进行降级关停; -
读写降级:将直接读写数据库切换为读写缓存;对于缓存依旧可以进行备份冗余; -
延迟降级:页面的异步加载策略;数据写入异步消息队列等。
-
自动降级:
-
一般可以通过代码层面处理,比如调用接口返回了err,对于golang,我们可以判断err是否为nil,如果不为nil可以进行降级处理,如果是Java,出现Exception,可以在Catch中处理。 -
也可以通过熔断器进行自动降级,但是需要考虑好熔断的阈值。
-
P0 服务为主服务,是力保稳定性的对象,他们挂了整个业务也就崩溃了; -
P1 服务为与紧密主服务相关,但可以后续异步补偿来操作的服务,比如说,结算流水,订单统计; -
P2 服务与主服务有点相关,但关闭了对主服务任何业务逻辑没有影响,比如说,订单评价,商品推荐等; -
P3 服务与主服务没有相关,关闭之后对主服务没有任何影响,比如说,广告推荐,用户喜好,评论浏览等。
-
直播首屏场景,正常情况下,会走算法推荐,但是如果算法推荐出了问题,通过开关切到简单排序规则 -
用户心跳场景,正常情况下上报间隔是一分钟上报一次,如果出现资源问题,可以在配置中心,修改上报间隔到5分钟
-
我们需要确定每个场景的模块出现问题的表现; -
确定问题出现了,我们要确认该怎么做; -
谁来做; -
怎么做。
-
存储资源(Mysql,Redis等)问题:比如Mysql等资源出现不可用情况(比如,cpu跑满,大量超时或者大量慢sql)且没有恢复迹象 -
流量突增:在某些情况下,你认为流量导致的问题,比如流量突增 -
外部接口耗时增加:如果系统调用外部接口,外部接口突然出现耗时增加,导致系统服务器的cpu跑满,导致系统不可用
-
SLB限流配置 -
Ekango限流配置 -
WAF单IP限速
-
确定值班人员,明确其支持位置 -
现场保障与事故记录,现场保障的人员,需要时刻盯紧监控大盘,日志,和告警。如果出现了事故需要对应人员来记录处理状态,并且在群中上报处理进度。
03
总结展望
[2]https://sre.google/sre-book/table-of-contents/
本文转载自 直播技术团队 哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/j5x2rUnVTyy8ygcVU49YcQ。