


分享嘉宾:张镎 亚马逊云科技
编辑整理:xiaomei zdph
出品平台:DataFunTalk
导读:本次演讲的主题是无服务技术赋能大数据分析。亚马逊云科技从2006年开始投入云计算,在Serverless也是有很长的演进历程,本次跟大家分享亚马逊云科技上的主要的数据分析Serverless组件,重点介绍在2022年6月发布的Amazon EMR Serverless。本次演讲主要分为以下五个部分:
-
智能湖仓——现代化数据架构概览
-
无服务技术演进
-
Amazon EMR Serverless的核心概念
-
Amazon EMR Serverless的常见使用场景
-
文档资料
01
客户希望从自己的数据中获得更多价值
在介绍Serverless产品之前,先简单回顾一下客户在数据分析领域遇到的一些挑战。

从关系数据库开始,数据已经呈现出爆炸性增长,特别随着互联网的快速增长,包括企业的数字化转型,我们的数据也在不断增长。有一个研究表明,每小时产生的数据比过去20年每年产生的数据还要多。从数据的来源来讲,过去更多是关系型数据库,数仓这类的结构化数据,支撑企业内BI、报表等业务,而互联网的普及催生了更多的数据来源,像点击流、IOT、图片、音视频等各种半结构化、非结构化的数据都在源源不断地产生。从用户场景来讲,分析场景更加多样化,除了常见的报表比如看DAU(Daily Active User,日活跃用户数量)、PV(Page View,页面浏览量)、UV(Unique Visitor,独立IP访客数)这样一些信息,现在还会跟机器学习的服务,像智能推荐、自动营销的场景。
02
智能湖仓——现代化数据架构
正是在这样的基础上,亚马逊云科技在2021年提出了一个智能湖仓——现代化的数据架构。

从智能湖仓的架构讲,它以中心化的数据湖支撑,在亚马逊云科技上就是S3对象存储,周边去构建具有极致性能的数据分析服务,包括本次重点讲的基于开源的Hadoop Spark打造的商业托管平台——Amazon EMR、云上的数仓服务——Redshift、NoSQL的服务——DynamoDB、日志分析和文本搜索服务——OpenSearch、关系型数据库的服务——Aurora、机器学习服务——SageMaker。
在数据湖和数据仓库之间,以及和周边专门构建的数据服务之间,数据都可以做到无缝流转,统一管控。同时,数据分析组件也可以将其能力进行拓展,比如在亚马逊云科技数仓服务Redshift有Redshift ML,一旦一个报表在数仓里便可以借助ML的能力达到如销售报表的预测等功能。
最后,这些组件具有很好的开放性,如亚马逊云科技核心组件像EMR、OpenSearch、像托管的Kafka等,其API都是跟开源组件API百分百兼容的,所以用户不管是自建还是从IDC环境迁移到亚马逊云科技的托管服务上,其迁移成本都很低。
03
无服务技术演进
简单回顾一下亚马逊云科技在Serverless的发展历程。
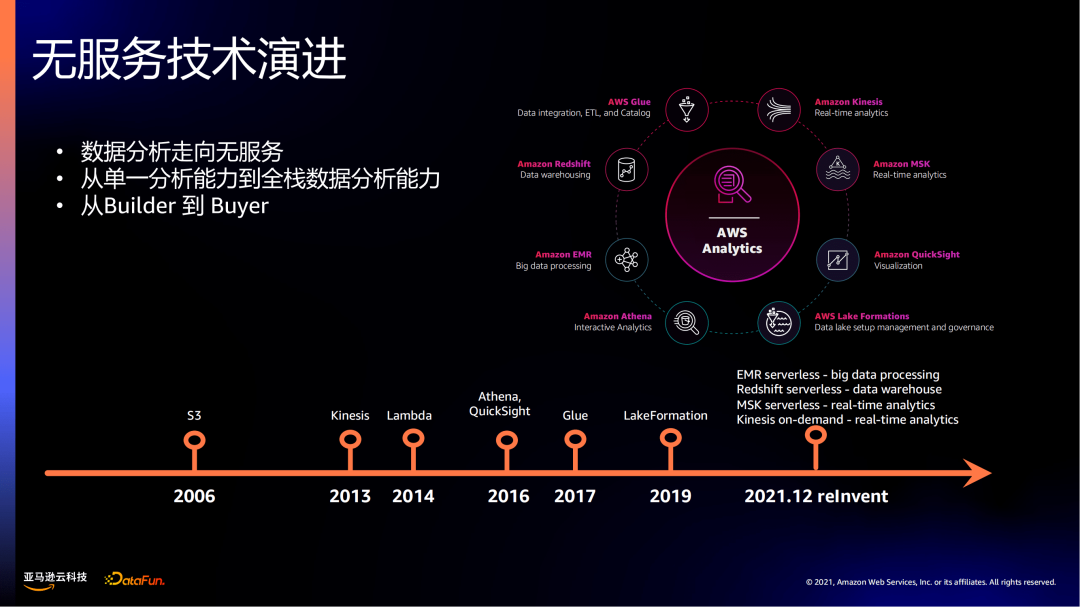
从2006年亚马逊云科技诞生开始,其第一个服务Amazon S3就是一个Serverless服务,是一个Serverless对象存储。Amazon S3发展到今天已经有丰富的功能,包括11个9的持久性、各种数据分层,作为一个有巨量用户和核心的服务,Amazon S3在支撑各种各样云计算的场景。
在2013年亚马逊云科技发布了消息流处理的Serverless服务——Kinesis,可以作为一个可扩展、伸缩的消息流服务去支撑流计算的场景。
在2014年亚马逊云科技发布了大家熟知的重磅的、基于函数的Serverless服务——Lambda,提出了一种事件驱动的场景,对于以前需要运行虚拟机来运行的代码,现在可以放到Lambda里面运行。
在2016年亚马逊云科技发布了Athena BI——QuickSight,去支持BI的场景。
在2017年亚马逊云科技发布了Glue,其是一个Serverless的ETL服务,可以在运行ETL任务的同时,不需要管理底层的基础设施。
在2019年亚马逊云科技发布了LakeFormation,该组件可帮助用户快速构建数据湖,同时对数据湖和数仓的数据进行权限管理。
在2021年12月relnvent发布了4个Serverless,将组件的数量推到了极致,包括EMR Serverless、Redshift Serverless、MSK Serverless、Kinesis on-demand,这4个服务将整个数据Serverless能力拓展到了全栈。
这里会看到一个趋势:
-
越来越多的数据分析服务,客户要求其易用性,要求不去管理底层的基础设施,越来越走向无服务化。
-
从单一数据分析能力走向全栈的数据分析能力。如之前数据分析服务只具备某些数据分析环节的能力,比如即时分析、ETL。到现在Serverless涵盖从数据的摄取、存储、大数据分析、数仓等,可以看到,Serverless已经演进到具备一个全栈数据分析的能力。
-
从应用人员来讲,我们之前面对的数据分析的用户更多是Bulider的角色(即要在数据分析之上构建自身的上层应用),到现在有越来越多的Buyer角色(更多的是业务团队),Serverless提供了良好的开箱即用的能力,像数据分析师、数据科学家等用户直接基于Serverless的数据分析产品,可以快速开展工作,如交互式查询、数据探索等。
从PPT右上这张图可以看出,在亚马逊云科技上具有广泛的serverless数据分析服务, 涵盖流处理、NoSQL、大数据处理、数仓、BI等Serverless能力。
04
Amazon EMR Serverless
本次重点讲一下Amazon EMR Serverless。

Amazon EMR是在亚马逊云科技上一个在云上的基于Hadoop生态的托管的数据分析平台。在Amazon EC2上,几分钟就可以拉起一个集群,支撑用户在上面部署需要的应用,包括主流的Hive、Spark、Presto、Flink、HBase等,支撑超过20种的开源组件。
-
在性能上,针对很多组件,如Spark、Hive等,做了很多的调优。
-
在成本收益上,Amazon EMR可以通过去预留实例,像Spot 实例的方式去节省用户成本。
-
在功能上,可以与Amazon EMR Studio、NoteBook等产品做集成,做自动化的工作调度或IDE相应的工具开发的功能。
而刚刚发布的Amazon EMR Serverless则是将之前基于EC2的部署方式转化为不需要管理任何集群的Serverless部署方式,对用户来讲更加简单易用。
下面就几个Amazon EMR Serverless的主要的几个收益展开来讲一下。
1. 简单易用

第一个:简单易用。
在以前运行EMR集群模式方式下需要勾选不同组件、选择集群的规模、实例的类型等,开启这个集群。那么在Serverless下就比较简单只需更轻松地运行开源框架,比如要运行Spark,只需要选择对应EMR版本,不需要再去选择集群的规模和类型,在做决策上来讲会更加简单,也不需要去配置、优化、运维、对集群做一些安全的工作,更不需要像OS一样做一些系统补丁相关的工作,非常简单易用。
2. 无需猜测集群规模

第二个:无需猜测集群的规模。
亚马逊云科技 Serverless 产品在后台可以支持自动的细粒度的扩展,以一个worker为单位来进行扩展,自动为处于不同Stage、不同工作阶段的负载轻松添加和删除工作节点。
数据发生变化后也不需要再根据数据量重新配置添加或减少相应的计算节点。
只需要为自己实际使用的资源付费,和以前IDC或托管的方式下如果有常跑的集群在空闲情况下还是要付费的模式相比,Serverless只需要在使用、计算的worker的时候才需要付费,也可以指定最小的worker和最大的worker所需的资源,让后台资源在最小和最大的资源区间来进行弹性扩缩,有效地控制成本。
3. 无需管理集群即可获得Amazon EMR的所有收益

第三个:无需管理集群即可获得Amazon EMR的所有收益。
Amazon EMR有一个很大的优势就是相较于开源框架来讲,性能的优化,一般较开源组件会有2-3倍性能提升。另外, Amazon EMR会和开源组件新版本的发布周期保持一致,一般在开源新版本发布的30天和60天内就会把新的版本合入到Amazon EMR组件中。同时Amazon EMR组件的API与开源社区的API是100%兼容的,所以不管是使用习惯还是现有的在开源组件上、在IDC、在自建上有用相应的负载,迁移到Amazon EMR组件上也没有任何的迁移成本的。
下面来看一下性能提升具体的效果:
-
Amazon EMR Spark Runtime v/s OSS Spark
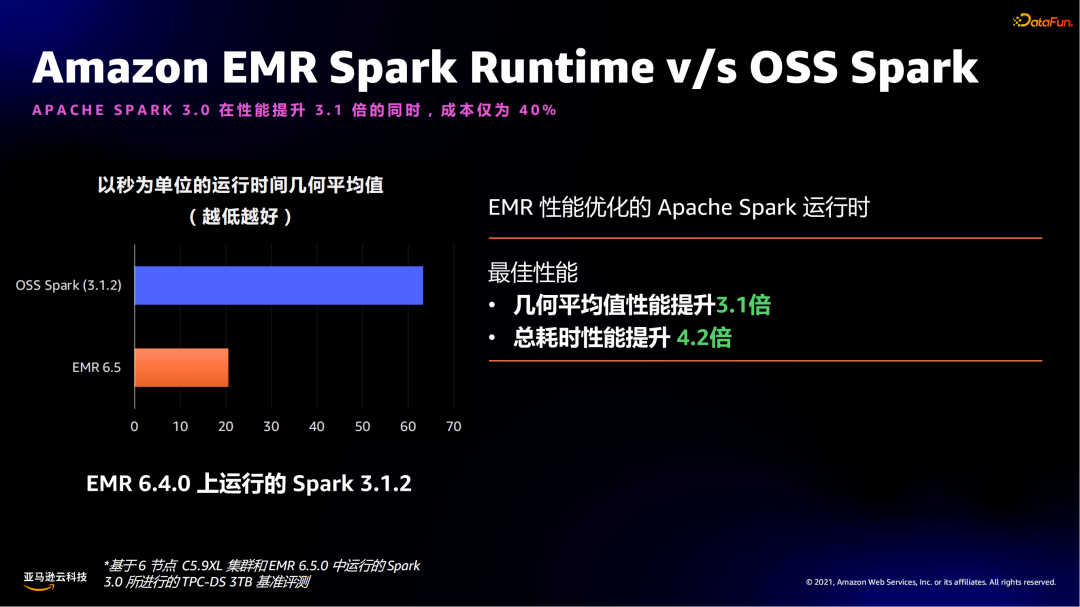
这个性能效果,亚马逊云科技有详细的基于业界知名的TPC-DS的权威的测试数据。不管在Spark3还是Spark2上,Amazon EMR都提供性能优化的Spark运行时。
以Spark3为例,Spark 3.1.2与开源社区对比,基于TPC-DS 6个节点C5.9XL集群 3TB的数据做了详细的测试,几何平均性能提升了3.1倍,总耗时性能提升4.2倍。
-
适用于Apache Hive的Amazon EMR运行时

在Hive上类似,几何平均值性能提升1.25倍,单个查询性能提升2倍。同时,API与开源社区API 100%兼容。另外,值得一提的是,最新 Hive版本,对S3读写做了优化,消除了之前开销较大的S3 re-name操作,更进一步提升了Hive处理的性能。
4. 通过细粒度扩缩节约成本
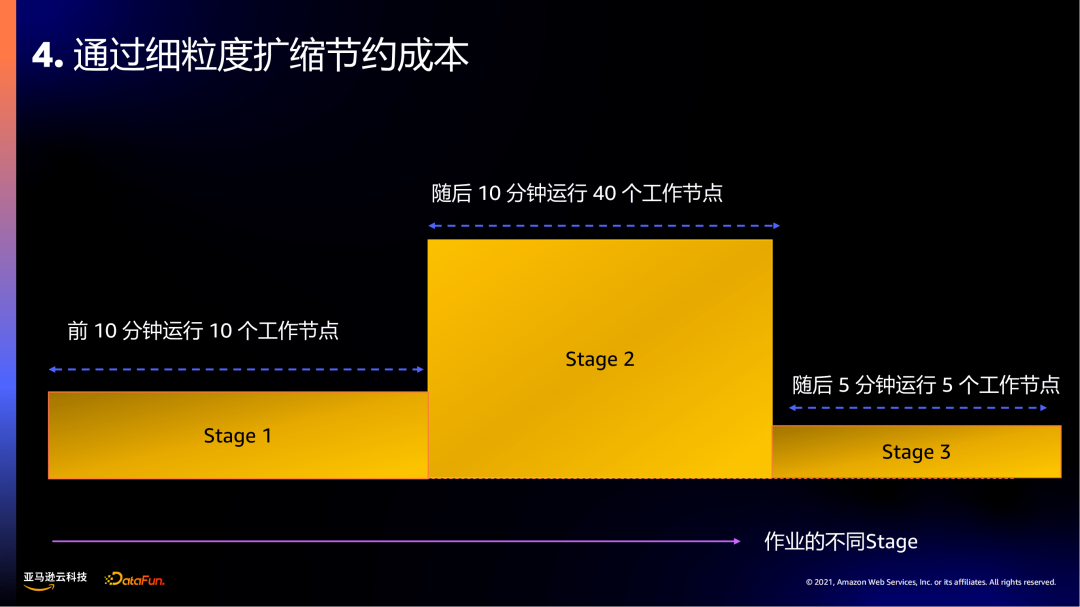
第四个:通过细粒度扩缩节约成本。
举例:在Spark或Hive里分为不同的阶段Stage,不同阶段对负载的需求是不一样的。虽然在Amazon EC2时可以支持不同负载需求的扩容,但它是EC2级别的,从响应时间讲,其依赖的一些指标、扩容的时效性相对较低。
Amazon EMR Serverless在扩容的颗粒度可以精确到worker级别,时效性比集群方式的好很多。例如:在运行Spark作业时,前期可能涉及在S3的目录读取,不需要消耗太多负载,前10分钟可能只需要10个工作节点;后面由于要涉及很多计算的工作,需要更多计算资源,这样在随后40分钟分配了40个工作节点;在之后涉及数据计算完成进行数据移动,也不需要更多的计算资源,在后面5分钟降到5个工作节点。以上可以看到在一个Spark作业中,可以针对不同的Stage所需的资源需求,去灵活地扩缩其工作节点,扩缩颗粒度相较于集群模式更加细粒度。
5. 可用区容错设计

第五个:可用区容错设计。
Amazon EMR Serverless是一个天然的Regional Service区域级服务,相较于集群模式,有更好的容错性设计。EMR serverless会管理作业可用区的分配,选择一个最佳可用区来运行作业,当某个可用区出现故障后,通过重试提交作业,可以把作业放到其他正常的可用区运行。因此,客户就不必担心单个可用区的故障造成业务中断。
6. 以安全的方式共享应用程序
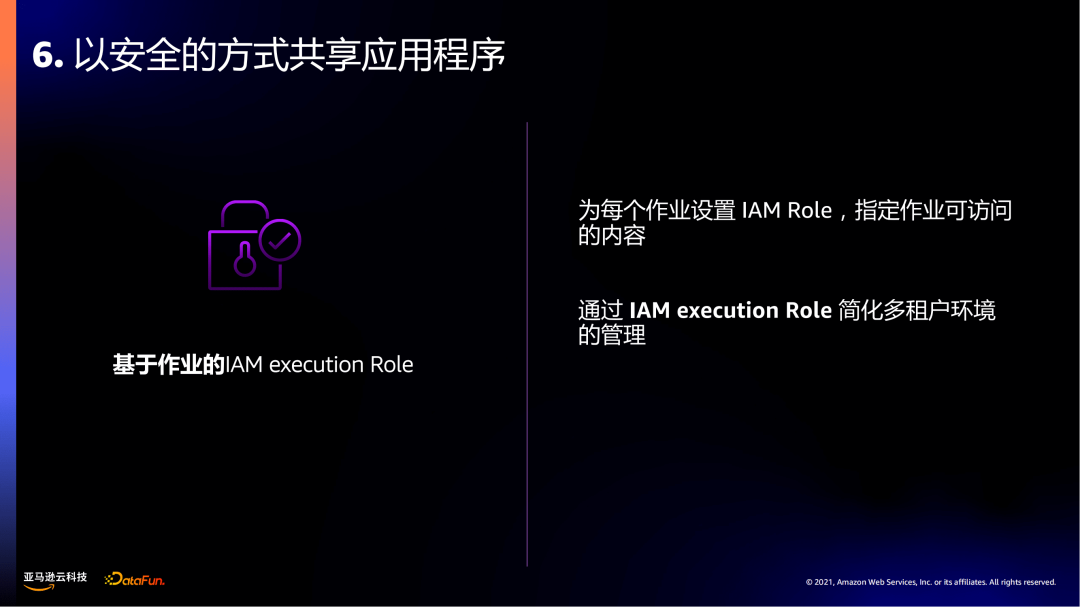
第六个:以安全的方式共享应用程序。
Amazon EMR Serverless可以为每个作业绑定独立的IAM execution Role来做到权限和资源的隔离,简化了多租户环境的管理和实现。
7. 实现交互式应用程序

第七个:实现交互式应用程序。
EMR serverless可以初始化工作节点池,来支撑对延迟敏感的业务,比如交互式查询。
8. 易于切换的部署模式

第八个:易于切换的部署模式。
Amazon EMR代码构建一次,在不同的EMR形态下都可以部署,包括EMR serverless, EMR on EC2, EMR on EKS等都可以去部署。
05
Amazon EMR Serverless的核心概念

下面看一些关于Amazon EMR Serverless的核心概念。
1. 应用程序(Application)

应用程序(Application)就是亚马逊云科技的开源框架,如Hive、Spark,后续也会支持Presto。在Amazon EMR Serverless上选择应用程序(Application)非常简单,基于应用程序版本选择相应的EMR版本,不同的应用程序可以对应不同的开源版本。这样做的好处是:第一,可以维护一些独立的逻辑环境,不同的应用程序之间不会出现资源的争抢,在进行版本升级或执行A/B测试时也很方便。第二,在客户侧做成本核算时,可通过应用程序方式区分不同的团队用的资源,在成本核算上可以独立成本控制和用量追踪。
2. 作业(Jobs)、工作节点(Workers)、初始化的工作节点(Pre-Initialized Workers)
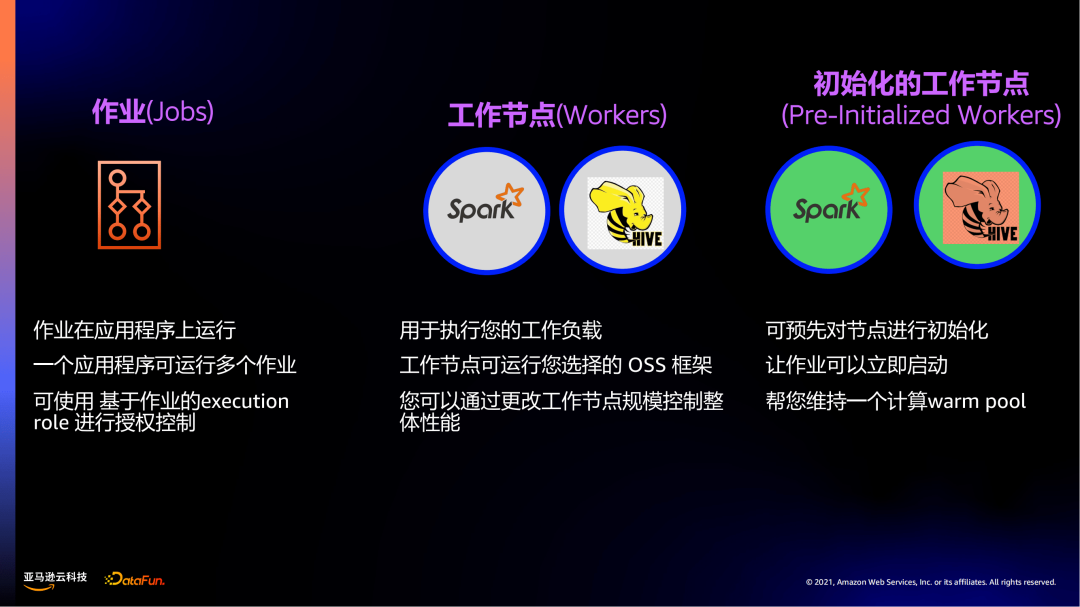
-
作业(Jobs),与大家熟知的Spark作业、Hive作业没有本质区别,只是在一个Serverless环境下运行,可以绑定相应的execution role来实现权限管控。
-
工作节点(Workers),是Amazon EMR Serverless的计算单位,所有的Spark、Hive组件都是基于工作节点来分配计算和存储资源的。
-
初始化的工作节点(Pre-Initialized Workers),对于对延迟要求比较高的交互式任务,可以在启动一个应用程序(Application)时,初始化一些工作节点,当作业提交过来时,任务可以立即执行,省去申请资源和预置资源的时间。相当于Amazon EMR Serverless帮助去维护一个warm pool,让资源在stand by来快速响应任务。
06
Amazon EMR Serverless的常见使用场景

快速看一下在Amazon EMR Serverless下几个常用的场景。
1. 场景1:数据管道

第一个场景是构建用户数据管道。
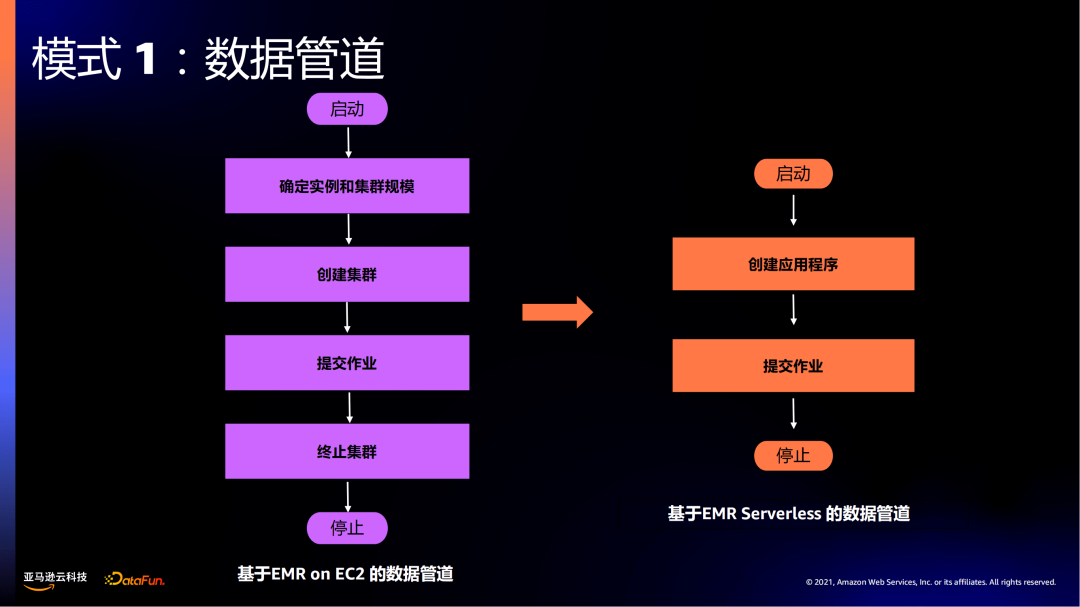
来看一下 EMR on EC2 与 EMR Serverless 构建数据管道的方式。
在EMR on EC2上需要经过比较多的步骤:首先需要选取相应的组件,如Spark、Hive等。然后需要确定实例和集群的规模,确定集群规模的节点数及节点类型。然后创建集群,集群创建可能需要几分钟时间,取决于选择的开源框架的类型、是否有自定义的启动脚本等。集群准备好后,提交作业。作业完成后,终止集群。最后是停止。这就是EMR on EC2上的数据管道。
EMR Serverless数据管道创建:首先创建应用程序,启动应用程序,提交作业,作业完成后自动停止。
通过对比EMR Serverless数据管道相较于EMR on EC2会简化很多。
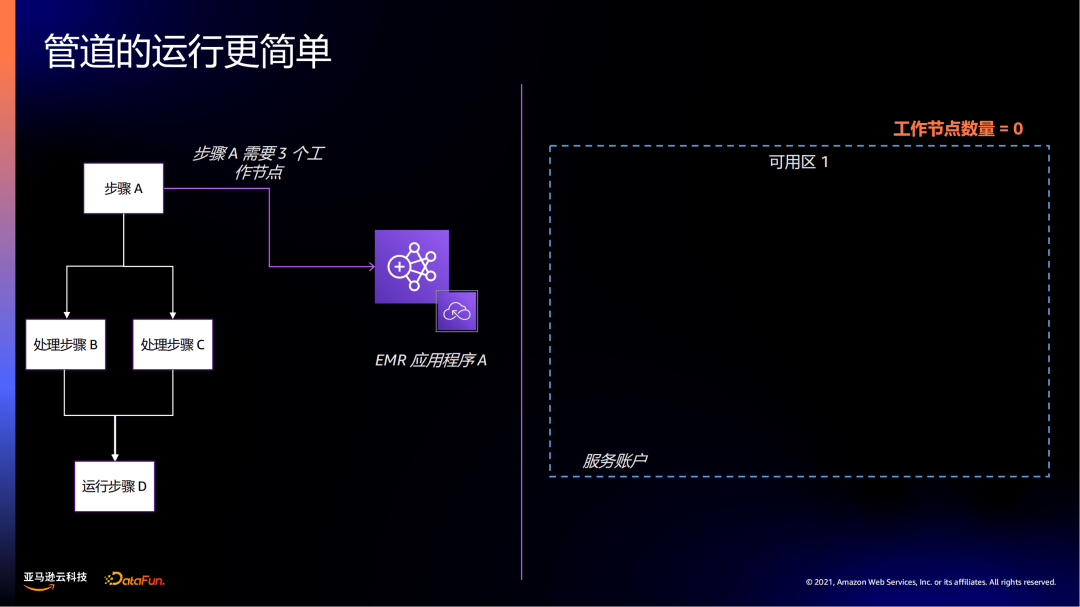
关于管道的扩缩容具体是怎么操作的?
例如:一个作业涉及不同的步骤,初始化工作节点是0,此时没有任何费用产生。当步骤A需要3个工作节点时,先启动3个工作节点。
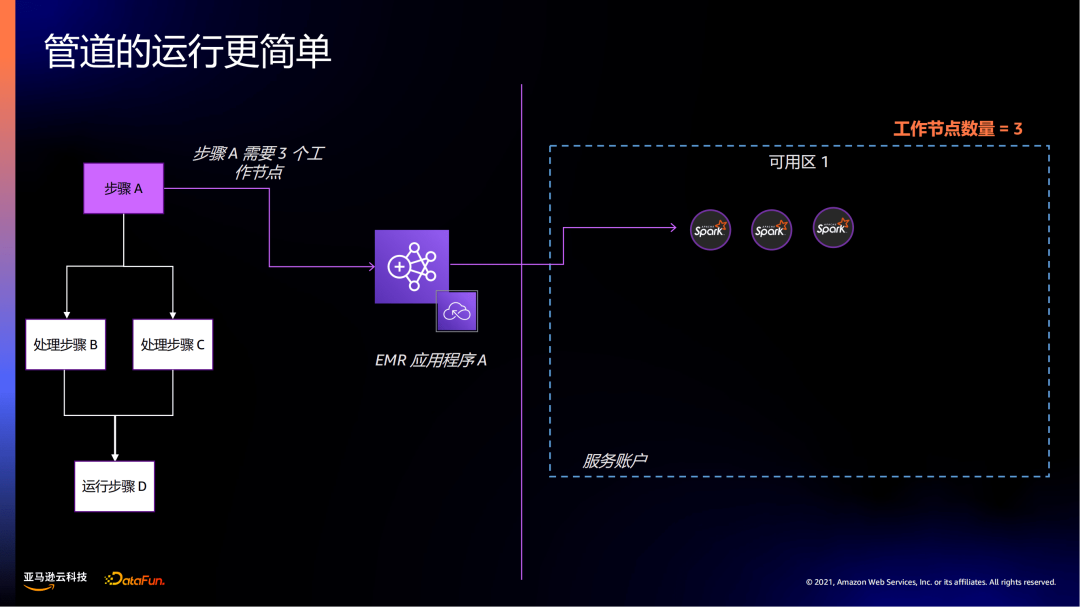
步骤A完成后,到处理步骤B和步骤C。
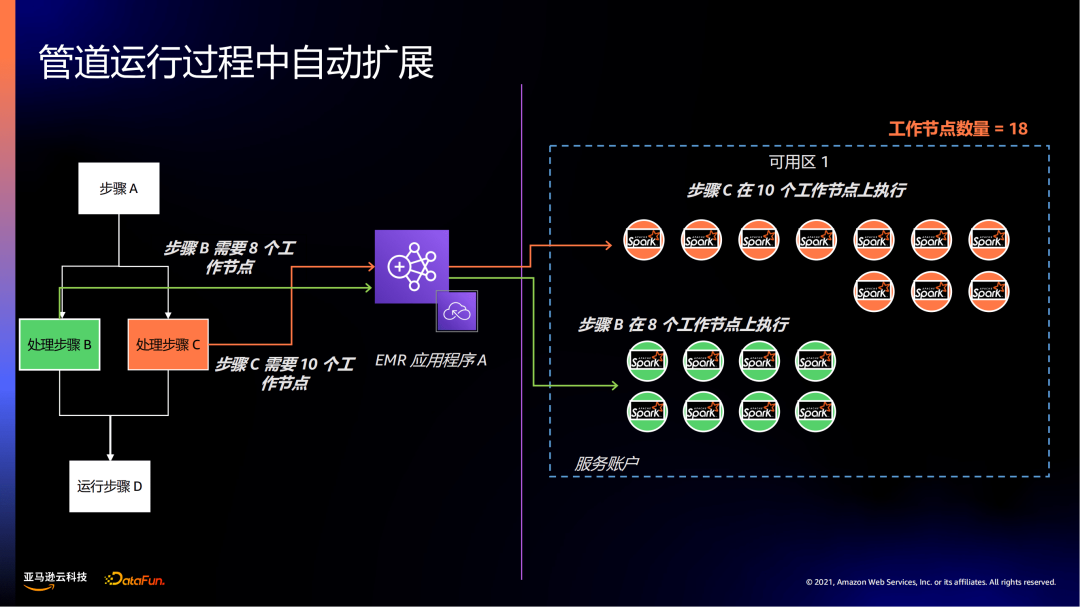
根据步骤B和步骤C的工作节点需要,再分配所需的18个工作节点。而在步骤A阶段的资源得以释放,不需要再产生费用。

在步骤D时,只需要10个工作节点,之前的工作节点就会被释放缩容。
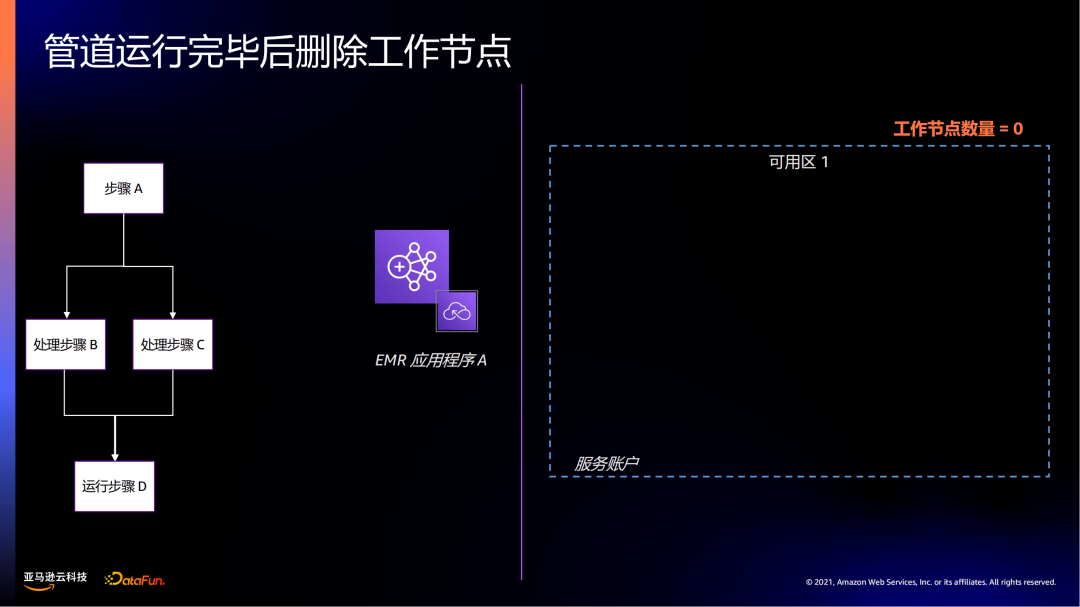
当整个工作任务停止时,工作节点全部释放变为0。
可以看到工作节点是根据业务负载能够灵活地、弹性地扩缩容。扩缩的颗粒度比在集群方式下更加细化。
2. 场景2:共享集群

第二个场景是共享集群。
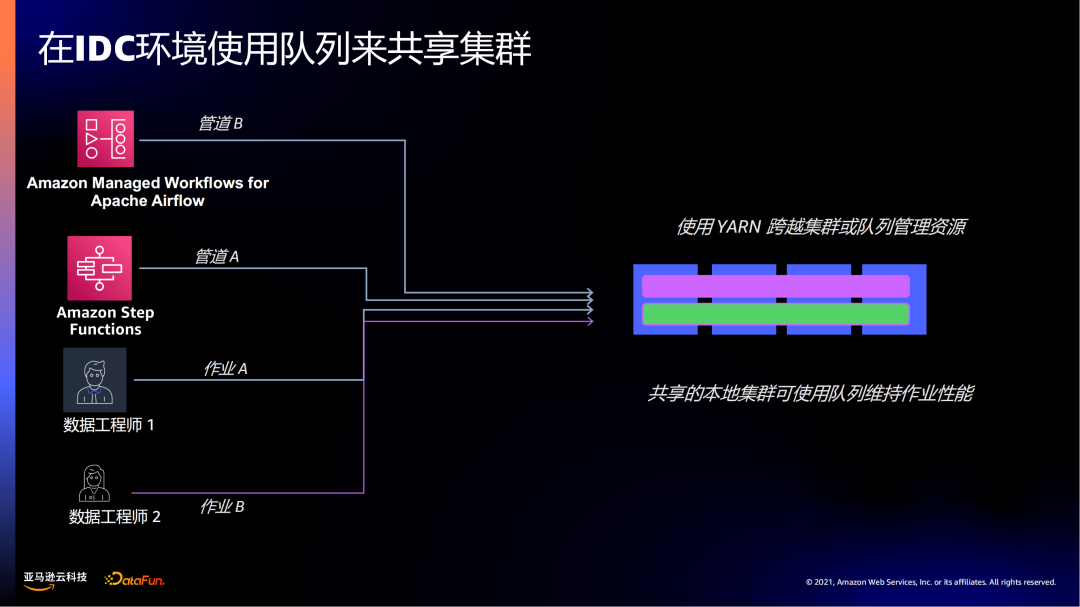
在IDC场景下,是通过队列的方式来共享,但还是会出现资源冲突或资源争抢的情况,比如在做一些成本核算时,很难说是哪些资源给到哪些团队。在这些问题上都存在一些挑战。
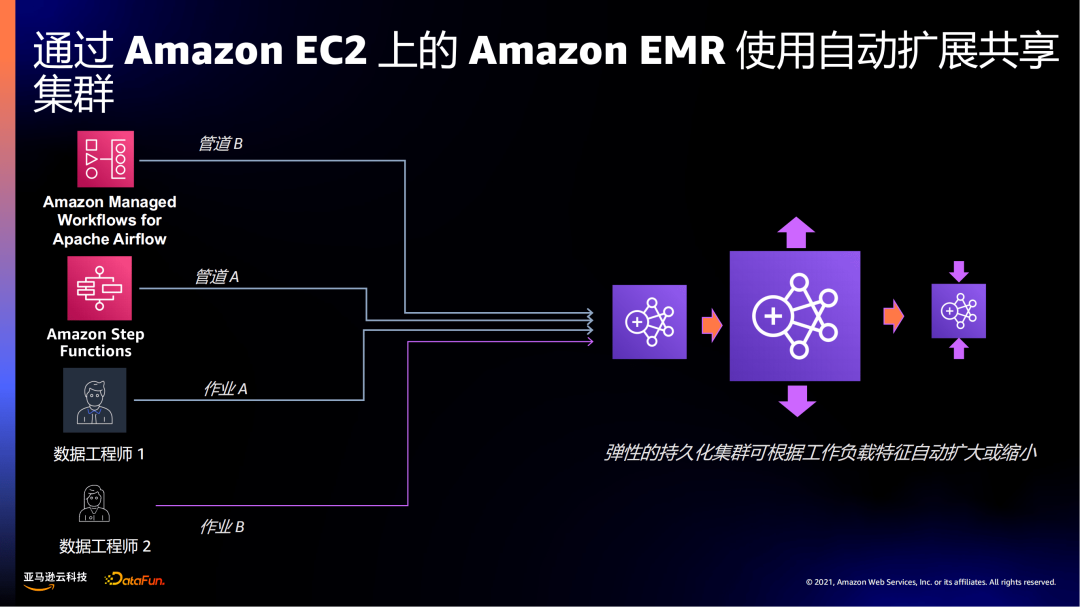
在EMR on EC2上可能会有多种任务提交方式,比如Airflow、Functions、数据工程师来提交作业等,在共享集群上,我们可以看到,是权限很难做有效的区分,另外是资源上也很难做到有效隔离。比如在运行一些交互式的任务时,突然有个很大的批量处理任务过来,可能会影响当前使用的资源。我们会建议用户对于不同的工作负载跑在不同的集群上,但因为集群模式基于虚机部署的方式,不可避免地会出现资源浪费的问题。
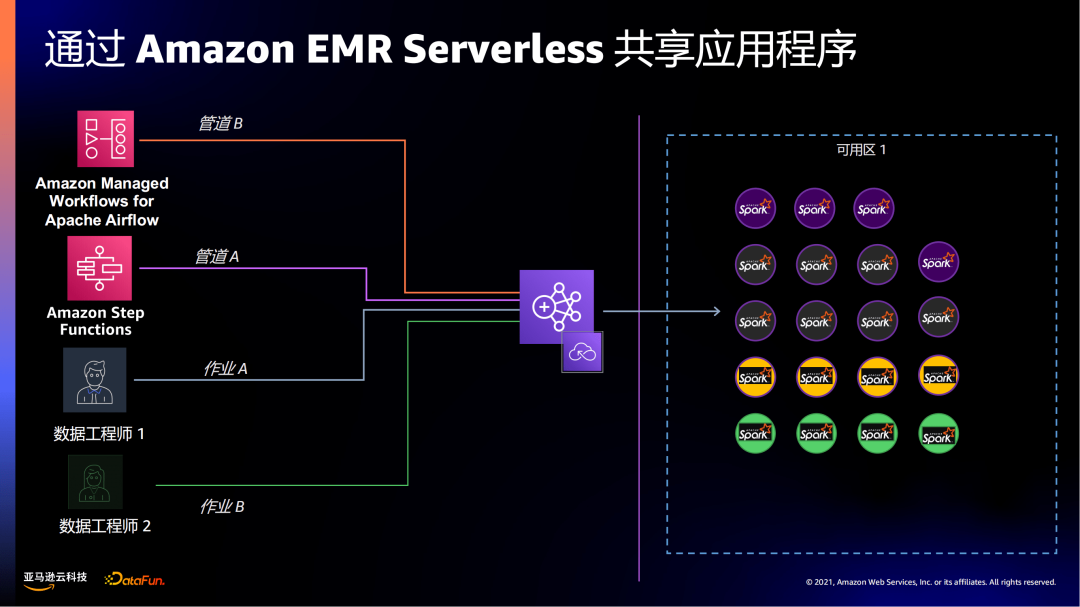
在EMR Serverless上,共享集群问题就会变得很简单。可以通过IAM execution Role方式进行资源的隔离,基于不同的作业分配相应的Workers资源。
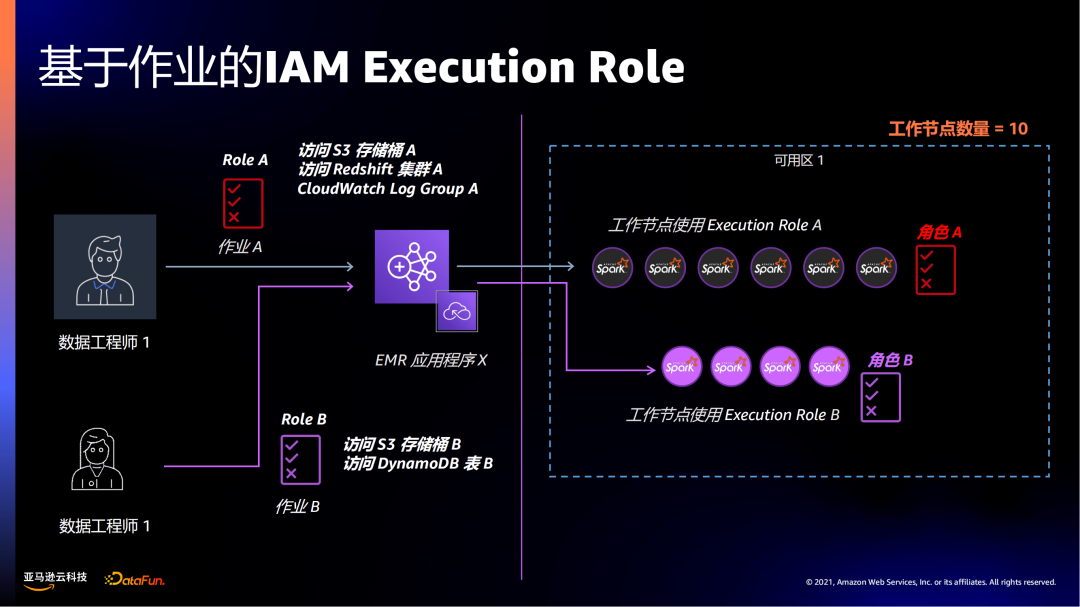
在EMR Serverless一个作业会赋予一个Execution Role,不同的作业可以分配不同的权限,比如图中作业A访问S3桶A和Redshift集群A,作业B访问S3桶B和DynamoDB表B。
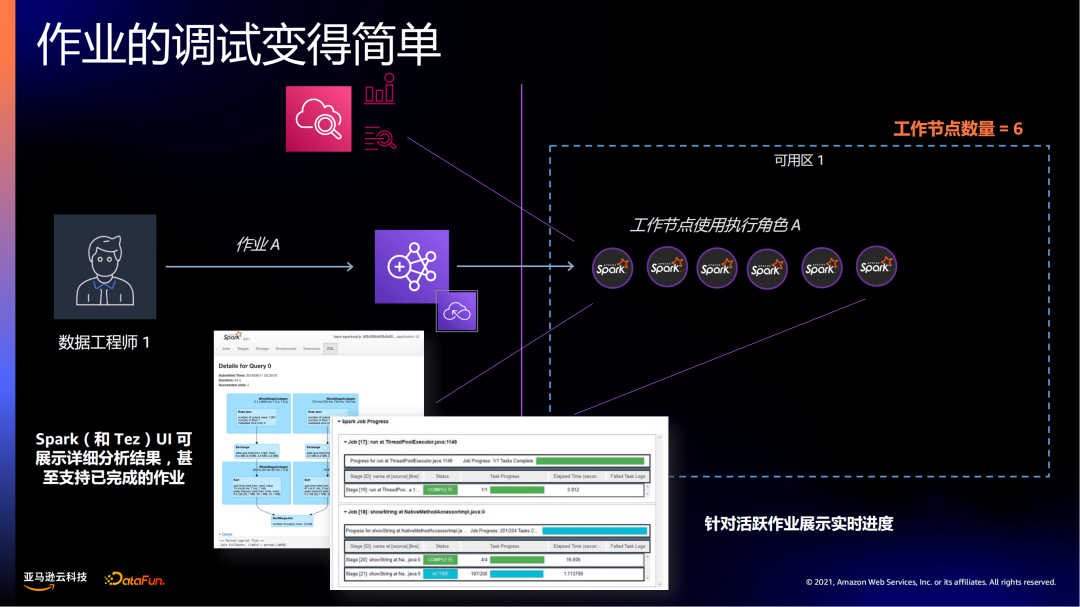
从作业的调试上来讲也会变得很简单。EMR serverless提供了Spark UI、Tez UI来简化调试工作。客户不需要像自建集群单独去host一个Spark History或Spark UI的服务或service。在EMR Serverless上,可以随时借助Spark UI,查看当前或之前的作业信息,快速开始debug和troubleshooting。
3. 场景3:交互式应用程序

第三种场景就是交互式场景。
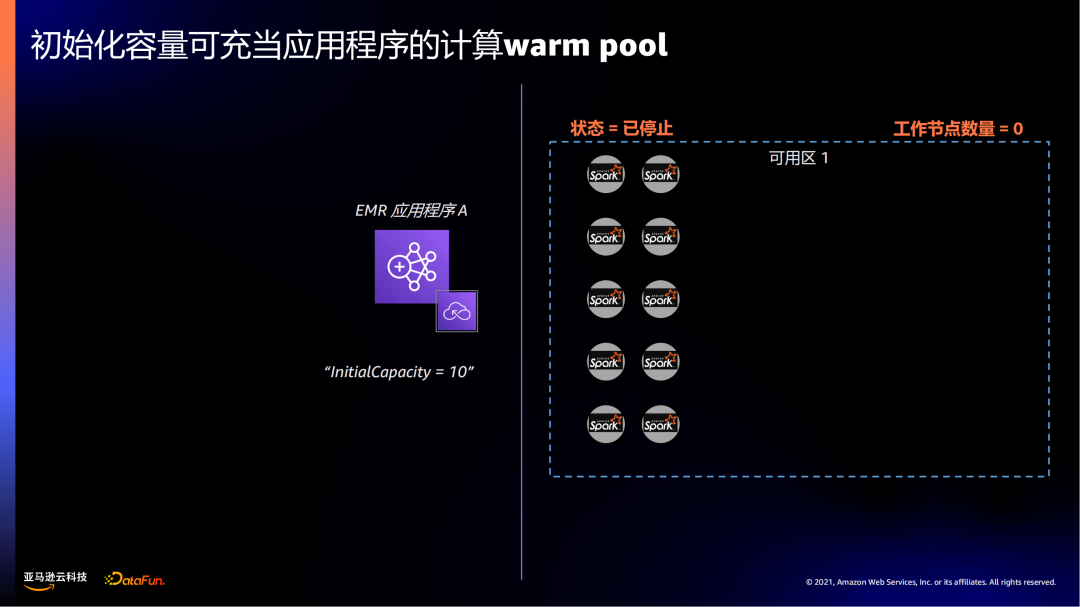
EMR serverless提供一个可选的初始化计算池。对于一些延迟要求高的任务,如交互式查询,可以借助初始化计算池提前预置好计算资源,来提供作业响应的时效性。
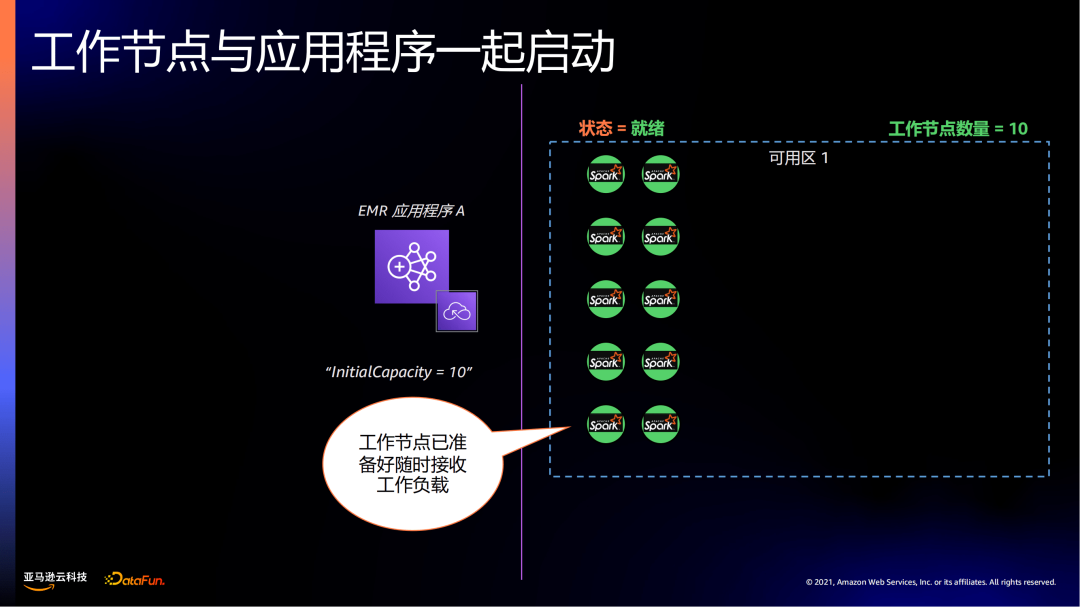
如示例中,在启动EMR 应用程序A时,设置InitialCapacity=10,先会有10个节点处于就绪状态。
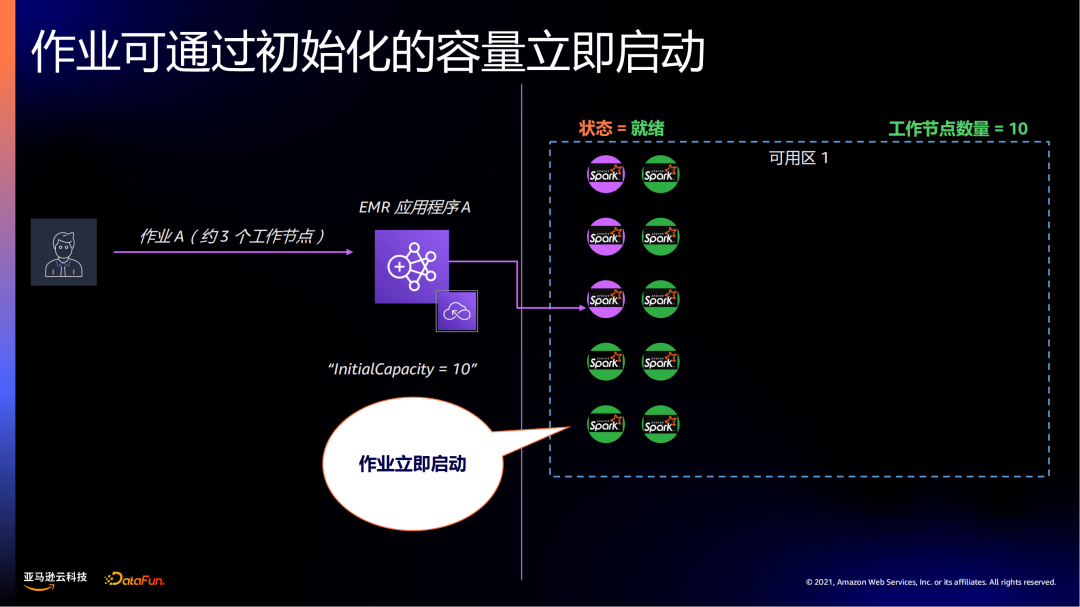
当作业需要3个节点,则从预先启动的10个节点分配资源,来快速响应作业。
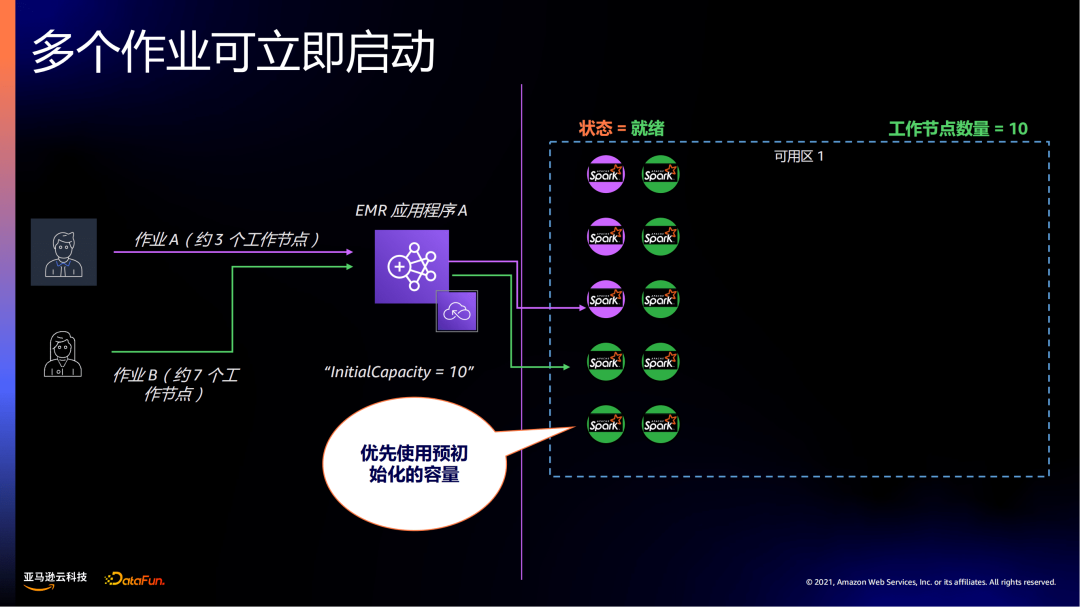
当有更多的作业提交时,比如作业B,EMR serverless优先使用预初始化的节点。
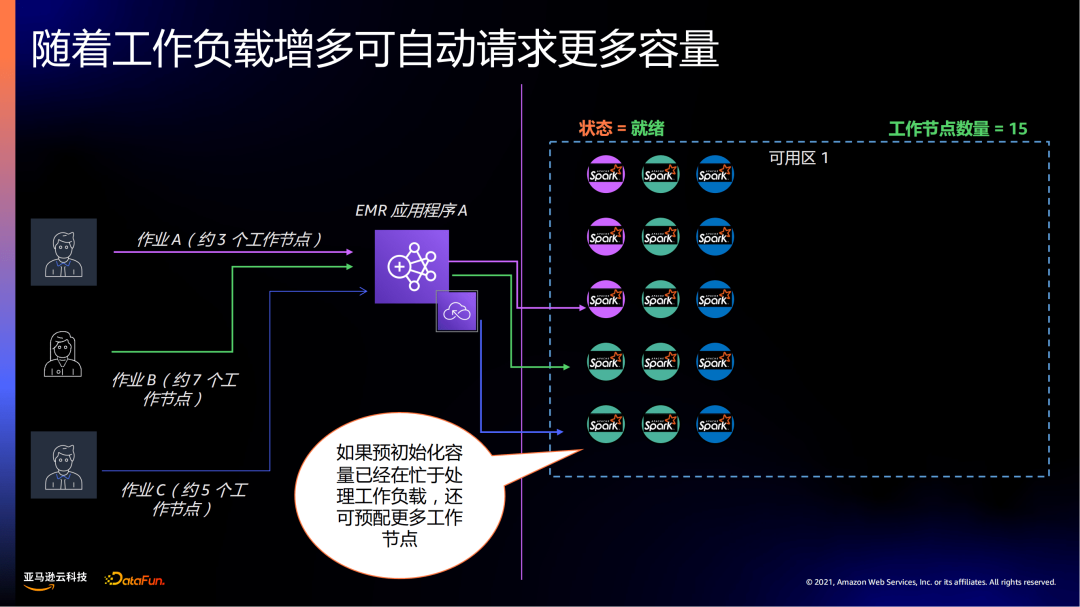
当作业超过预置的初始化节点资源时,EMR serverless会自动申请新节点资源。
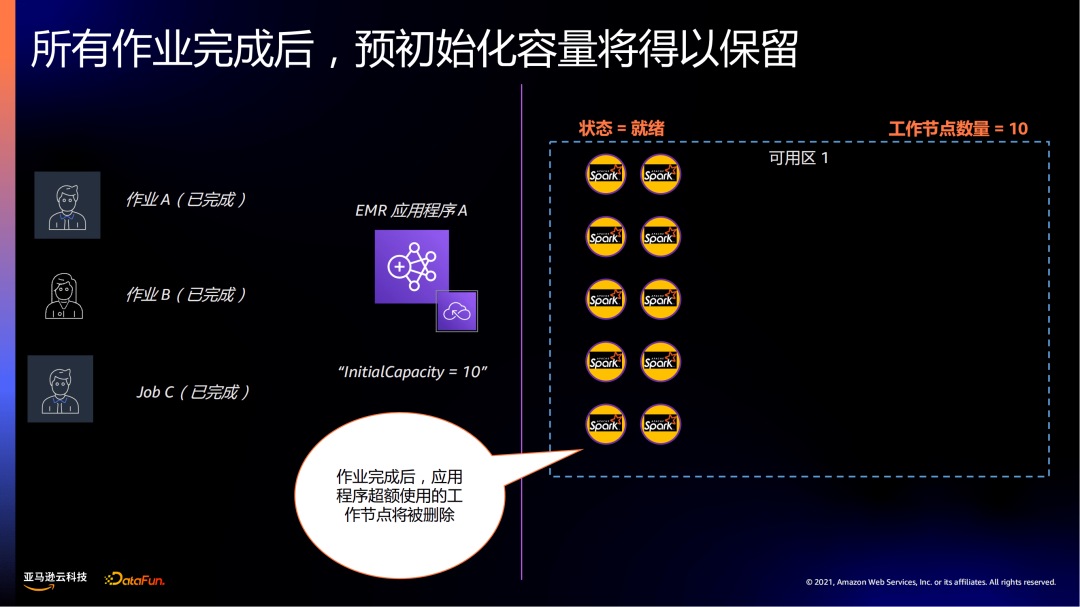
当所有作业完成后,warm pool恢复之前预初始化的容量,应用程序超额使用的工作节点将被删除。
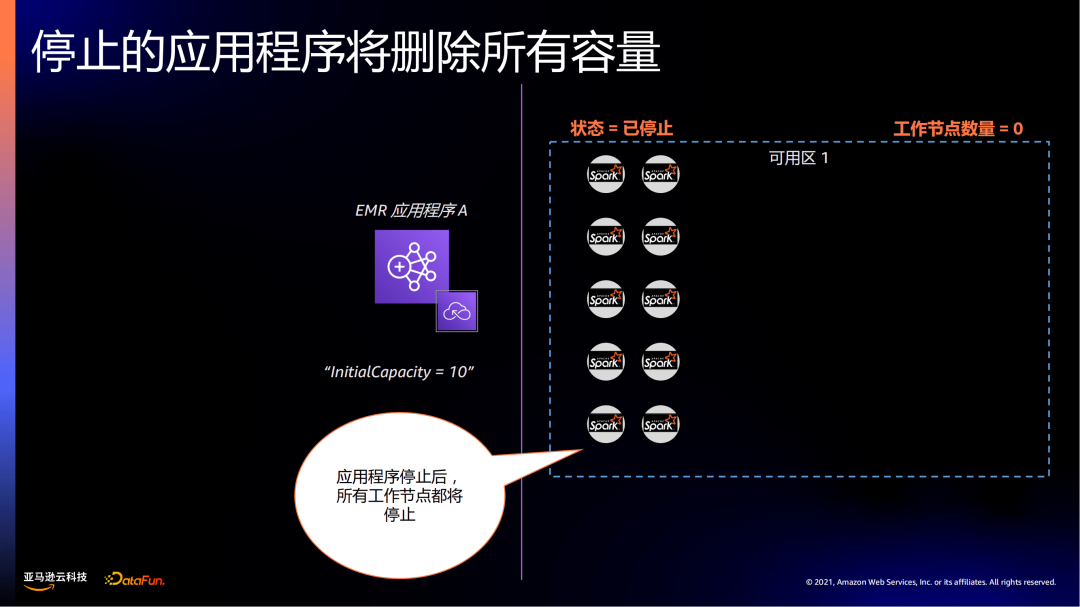
当所有作业完成,可以选择继续保留初始化的节点资源、还是释放,来控制成本。
07
文档资料
-
博客:
https://亚马逊云科技.amazon.com/blogs/亚马逊云科技/amazon-emr-serverless-now-generally-available-run-big-data-applications-without-managing-servers/
-
用户手册:
https://docs.亚马逊云科技.amazon.com/emr/latest/EMR-Serverless-UserGuide/emr-serverless.html
以上为Amazon EMR Serverless文档资源,后面也会在中国区发布,欢迎大家去试用。


扫描二维码即可申请AWS免费套餐
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

本文转载自张镎 DataFunTalk ,原文链接:https://mp.weixin.qq.com/s/A9xV5-azH3t9apT7LtK4nw。